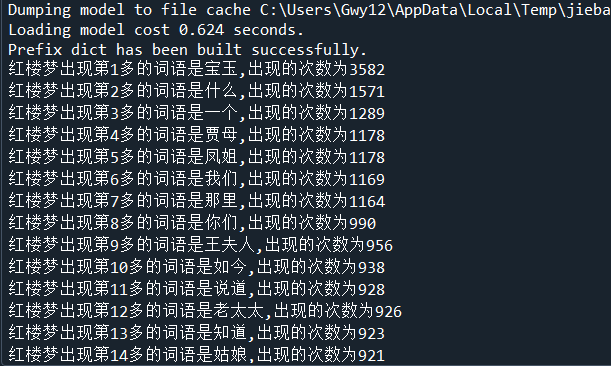
import jieba with open('红楼梦.txt','r',encoding='utf-8')as f: txt = f.read() words = jieba.lcut(txt) counts={} for word in words: if len(word) == 1: continue else: counts[word]=counts.get(word,0)+1 list = list(counts.items()) list.sort(key=lambda x:x[1],reverse=True) for i in range(20): print("红楼梦出现第{}多的词语是{},出现的次数为{}".format(i+1,list[i][0],list[i][1]))