pytorch图像变换和增强
总览
# 使用数据增强技术可以增加数据集中图像的多样性,从而提高模型的性能和泛化能力。
1.尺寸变换
transforms.Resize() #尺寸变换
transforms.Normalize() #标准化
transforms.Pad() #边界填充
2.色彩和色域
transforms.Grayscale() #转灰度图
transforms.RandomGrayscale() #依概率p转为灰度图
transforms.ColorJitter() #随机修改亮度对比度和饱和度
3.裁剪
transforms.CenterCrop(size) #中心裁剪
transforms.RandomCrop(size) #随机裁剪
transforms.RandomResizedCrop() #随机大小、长宽比裁剪
transforms.FiveCrop() #上下左右中心裁剪,裁剪图像的四个角和中心
transforms.TenCrop() #上下左右中心裁剪后翻转,5张图像
4.翻转和旋转
transforms.RandomHorizontalFlip(p=0.5) #依概率p水平翻转
transforms.RandomVerticalFlip(p=0.5) #依概率p垂直翻转
transforms.RandomRotation(degrees, resample=False, expand=False, center=None) #随机旋转
#degrees:旋转角度,当为一个数a时,在(-a,a)之间随机旋转
#resample:重采样方法
#expand:旋转时是否保持图片完整,只针对中心旋转
#center:设置旋转中心点
5.随机遮挡
transforms.RandomErasing #对图像进行随机遮挡
6.图像变换
transforms.LinearTransformation() #线性变换
transforms.RandomAffine() #随机仿射变换
transforms.RandomPerspective() #随机透视变换
transforms.GaussianBlur() #高斯滤波器进行图像模糊
transforms.RandomInvert() #随机地插入给定图像的颜色
transforms.RandomEqualize() #直方图均衡化
7.格式变换
transforms.ToPILImage(mode=None) #图像转换为 PIL图像
transforms.ToTensor() #转换为 torch.tensor
8.数据选择
transforms.RandomChoice(transforms列表) #从给定的一系列transforms中选一个进行操作
transforms.RandomApply(transforms列表, p=0.5) #给一个transform加上概率,依概率进行选择操作
transforms.RandomOrder(transforms列表) #将transforms中的操作随机打乱。
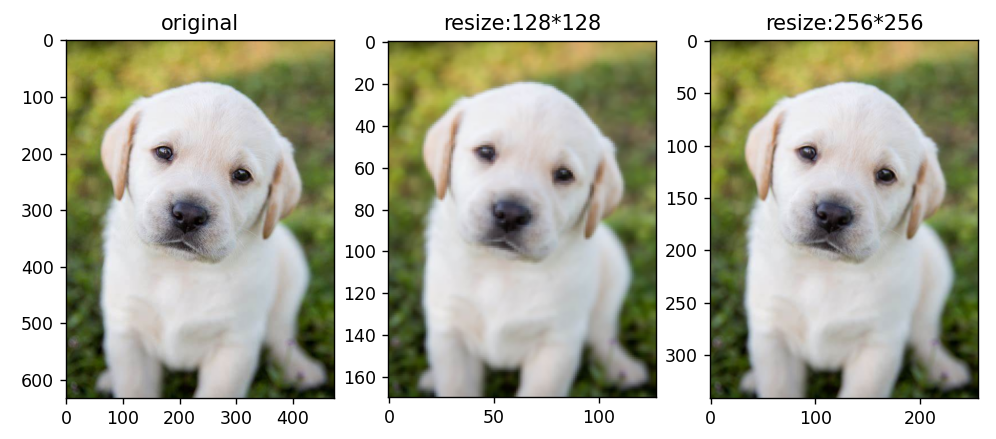
调整大小
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
torch.manual_seed(0) # 设置 CPU 生成随机数的 种子 ,方便下次复现实验结果
print(np.asarray(orig_img).shape) #(800, 800, 3)
#图像大小的调整
resized_imgs128 = T.Resize(size=128)(orig_img)
resized_imgs256 = T.Resize(size=256)(orig_img)
# plt.figure('resize:128*128')
ax1 = plt.subplot(1,3,1)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(1,3,2)
ax2.set_title('resize:128*128')
ax2.imshow(resized_imgs128)
ax3 = plt.subplot(1,3,3)
ax3.set_title('resize:256*256')
ax3.imshow(resized_imgs256)
plt.show()
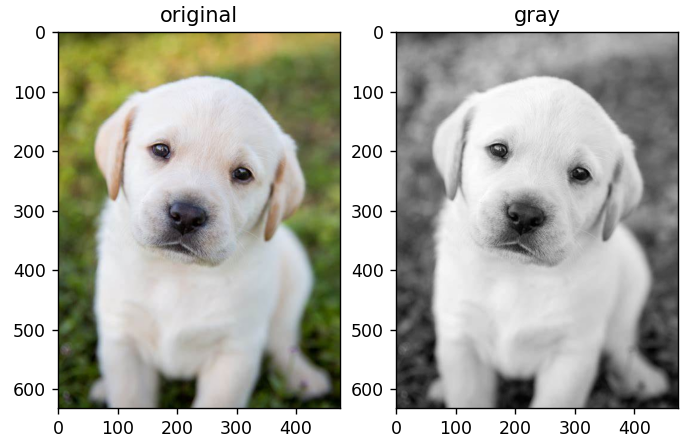
灰度变换
from pathlib import Path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
orig_img = Image.open(Path('assets/images/1.jpg'))
gray_img = T.Grayscale()(orig_img)
# plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('gray')
ax2.imshow(gray_img,cmap='gray')
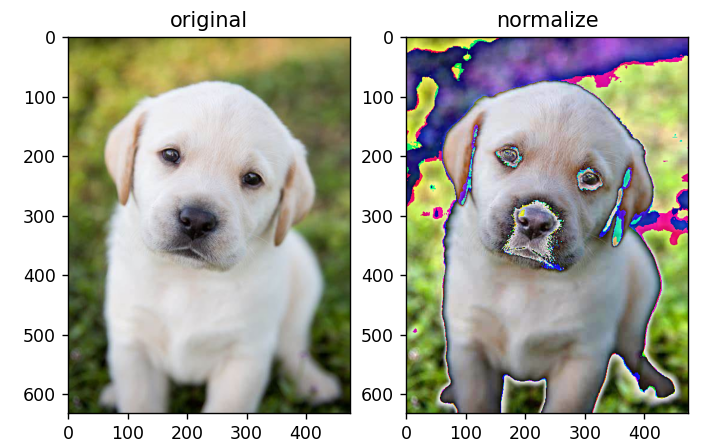
标准化
标准化可以加快基于神经网络结构的模型的计算速度,加快学习速度。
- 从每个输入通道中减去通道平均值
- 将其除以通道标准差。
from pathlib import Path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
orig_img = Image.open(Path('assets/images/1.jpg'))
normalized_img = T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))(T.ToTensor()(orig_img))
normalized_img = [T.ToPILImage()(normalized_img)]
# plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('normalize')
ax2.imshow(normalized_img[0])
plt.show()
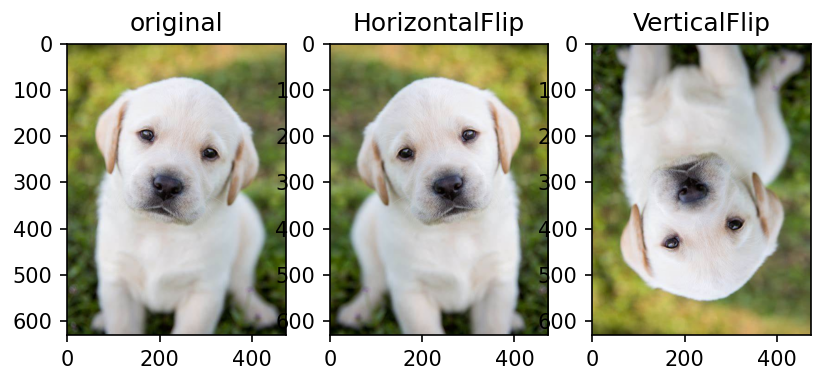
水平垂直翻转
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
HorizontalFlip_VerticalFlip_img = [T.RandomHorizontalFlip(p=1)(orig_img),
T.RandomVerticalFlip(p=1)(orig_img)
]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('HorizontalFlip')
ax2.imshow(np.array(HorizontalFlip_VerticalFlip_img[0]))
ax3 = plt.subplot(133)
ax3.set_title('VerticalFlip')
ax3.imshow(np.array(HorizontalFlip_VerticalFlip_img[1]))
plt.show()
随机旋转
from pathlib import Path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import torchvision.transforms as T
# 设计角度旋转图像
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
rotated_imgs = [T.RandomRotation(degrees=90)(orig_img)] # (min, max)
print(rotated_imgs)
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('90°')
ax2.imshow(np.array(rotated_imgs[0]))
plt.show()
中心裁剪
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
# 剪切图像的中心区域
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
center_crops = [T.CenterCrop(size=size)(orig_img) for size in (256,128)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('256*256°')
ax2.imshow(np.array(center_crops[0]))
ax3 = plt.subplot(133)
ax3.set_title('128*128')
ax3.imshow(np.array(center_crops[1]))
plt.show()
随机裁剪
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
# 随机剪切图像的某一部分
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
random_crops = [T.RandomCrop(size=size)(orig_img) for size in (400,300)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('400*400')
ax2.imshow(np.array(random_crops[0]))
ax3 = plt.subplot(133)
ax3.set_title('300*300')
ax3.imshow(np.array(random_crops[1]))
plt.show()
亮度对比度饱和度
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
# random_crops = [T.RandomCrop(size=size)(orig_img) for size in (832,704, 256)]
colorjitter_img = [T.ColorJitter(brightness=(2,2), contrast=(0.5,0.5), saturation=(0.5,0.5))(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('colorjitter_img')
ax2.imshow(np.array(colorjitter_img[0]))
plt.show()
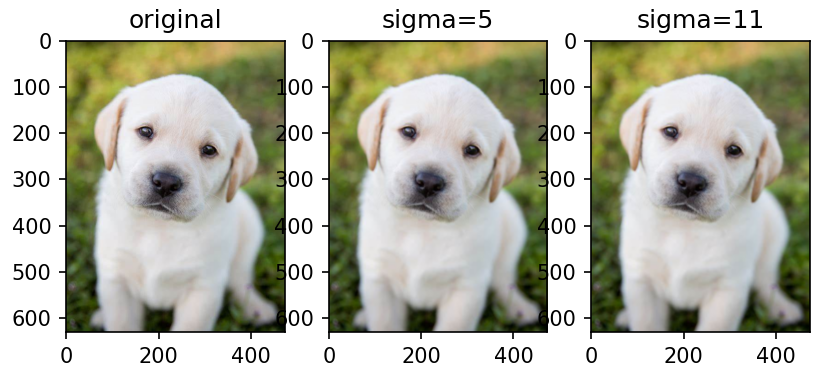
高斯模糊
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
# 使用高斯核对图像进行模糊变换
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
blurred_imgs = [T.GaussianBlur(kernel_size=(3, 3), sigma=sigma)(orig_img) for sigma in (5,11)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('sigma=5')
ax2.imshow(np.array(blurred_imgs[0]))
ax3 = plt.subplot(133)
ax3.set_title('sigma=11')
ax3.imshow(np.array(blurred_imgs[1]))
plt.show()
高斯噪声
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
# 向图像中加入高斯噪声。通过设置噪声因子,噪声因子越高,图像的噪声越大。
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_noise(inputs, noise_factor=0.3):
noisy = inputs + torch.randn_like(inputs) * noise_factor
noisy = torch.clip(noisy, 0., 1.)
return noisy
noise_imgs = [add_noise(T.ToTensor()(orig_img), noise_factor) for noise_factor in (0.3, 0.6)]
noise_imgs = [T.ToPILImage()(noise_img) for noise_img in noise_imgs]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('noise_factor=0.3')
ax2.imshow(np.array(noise_imgs[0]))
ax3 = plt.subplot(133)
ax3.set_title('noise_factor=0.6')
ax3.imshow(np.array(noise_imgs[1]))
plt.show()

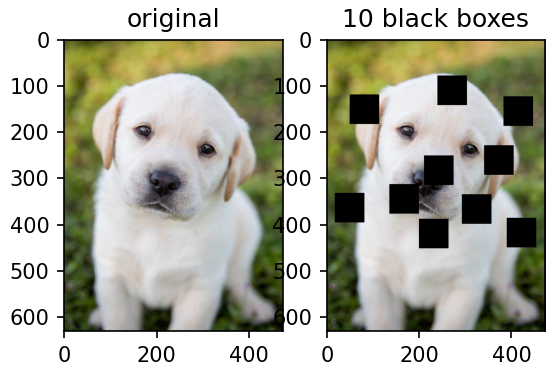
随机块
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
# 正方形补丁随机应用在图像中。这些补丁的数量越多,神经网络解决问题的难度就越大。
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
def add_random_boxes(img,n_k,size=64):
h,w = size,size
img = np.asarray(img).copy()
img_size = img.shape[1]
boxes = []
for k in range(n_k):
y,x = np.random.randint(0,img_size-w,(2,))
img[y:y+h,x:x+w] = 0
boxes.append((x,y,h,w))
img = Image.fromarray(img.astype('uint8'), 'RGB')
return img
blocks_imgs = [add_random_boxes(orig_img,n_k=10)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('10 black boxes')
ax2.imshow(np.array(blocks_imgs[0]))
plt.show()
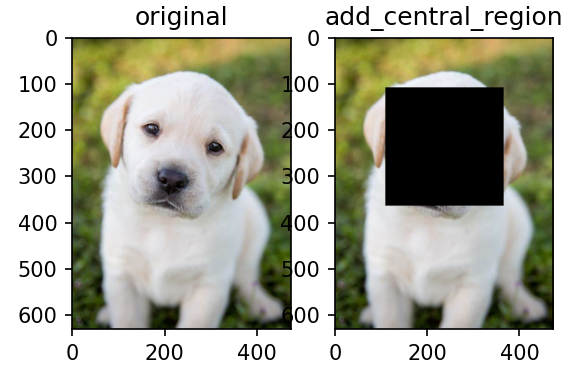
中心区域
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
# 和随机块类似,只不过在图像的中心加入补丁
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('assets/images/1.jpg'))
def add_central_region(img, size=32):
h, w = size, size
img = np.asarray(img).copy()
img_size = img.shape[1]
img[int(img_size / 2 - h):int(img_size / 2 + h), int(img_size / 2 - w):int(img_size / 2 + w)] = 0
img = Image.fromarray(img.astype('uint8'), 'RGB')
return img
central_imgs = [add_central_region(orig_img, size=128)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('add_central_region')
ax2.imshow(np.array(central_imgs[0]))
plt.show()
参考资料
https://blog.csdn.net/maizousidemao/article/details/109413113