Mixtral 8x7B 的推出在开放 AI 领域引发了广泛关注,特别是混合专家(Mixture-of-Experts:MoEs)这一概念被大家所认知。混合专家(MoE)概念是协作智能的象征,体现了“整体大于部分之和”的说法。MoE模型汇集了各种专家模型的优势,以提供更好的预测。它是围绕一个门控网络和一组专家网络构建的,每个专家网络都擅长特定任务的不同方面
在本文中,我将使用Pytorch来实现一个MoE模型。在具体代码之前,让我们先简单介绍一下混合专家的体系结构。
MoE架构
MoE由两种类型的网络组成:(1)专家网络和(2)门控网络。
专家网络:专家网络是专有模型,每个模型都经过训练,在数据的一个子集中表现出色。MoE的理念是拥有多名优势互补的专家,确保对问题空间的全面覆盖。
门控网络:门控网络充当指挥,协调或管理个别专家的贡献。它学习(或权衡)哪个网络擅长处理哪种类型的输入。经过训练的门控网络可以评估新的输入向量,并根据专家的熟练程度将处理责任分配给最合适的专家或专家组合。门控网络根据专家的输出与当前输入的相关性动态调整其权重,确保定制响应。
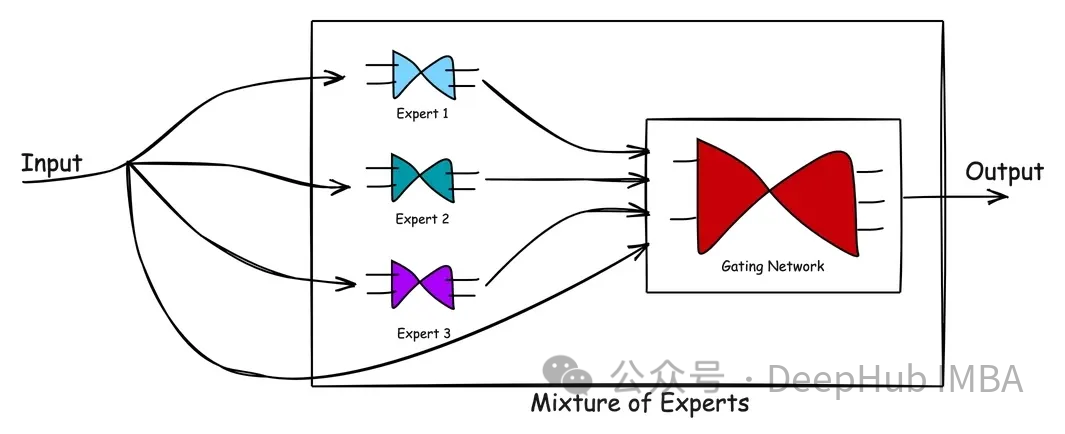
上图显示了MoE中的处理流程。混合专家模型的优点在于它的简单。通过学习复杂的问题空间以及专家在解决问题时的反应,MoE模型有助于产生比单个专家更好的解决方案。门控网络作为一个有效的管理者,评估情景并将任务传递给最佳专家。当新数据输入时,模型可以通过重新评估专家对新输入的优势来适应,从而产生灵活的学习方法。
MoE为部署机器学习模型提供了巨大的好处。以下是两个显著的好处。
https://avoid.overfit.cn/post/d5c5a12aac9e48c296cace247b460b02