1. 阅读"Variational Continual Learning"论文及代码
关于Continual Learning(CL)的认识:这是一个贝叶斯推断过程,这里是gpt给出的贝叶斯推断概念和例子:


即先确定一个先验分布,需要求的未知参数是θ(当然也可以添加其他类似α,β)的超参数之类的)。接下来我们进行实验获得数据,或者搜集先前数据,根据这些数据可以计算出似然函数。最后,基于先验分布和似然函数,我们可以获得后验分布,这个后验分布要比先验分布更加精确。之后我们将得到的后验分布作为下一阶段的先验分布,如此循环往复,θ便会收敛到真实的值。
其中涉及了几个概念:
①贝塔分布
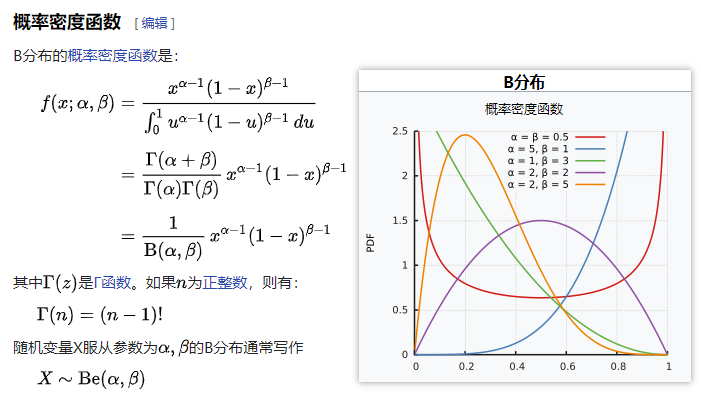
②似然函数:
似然性代表某个参数为特定值的可能性,wikipedia给出了一个非常清晰的例子:

后面还引入了KL散度,是用来判断两个概率函数的近似程度的,KL散度越小,代表两个概率函数越接近。


最后是算法的全过程:
