这个就是好评和差评的一个分类。
这个输入一般\(h_0\)全为0.
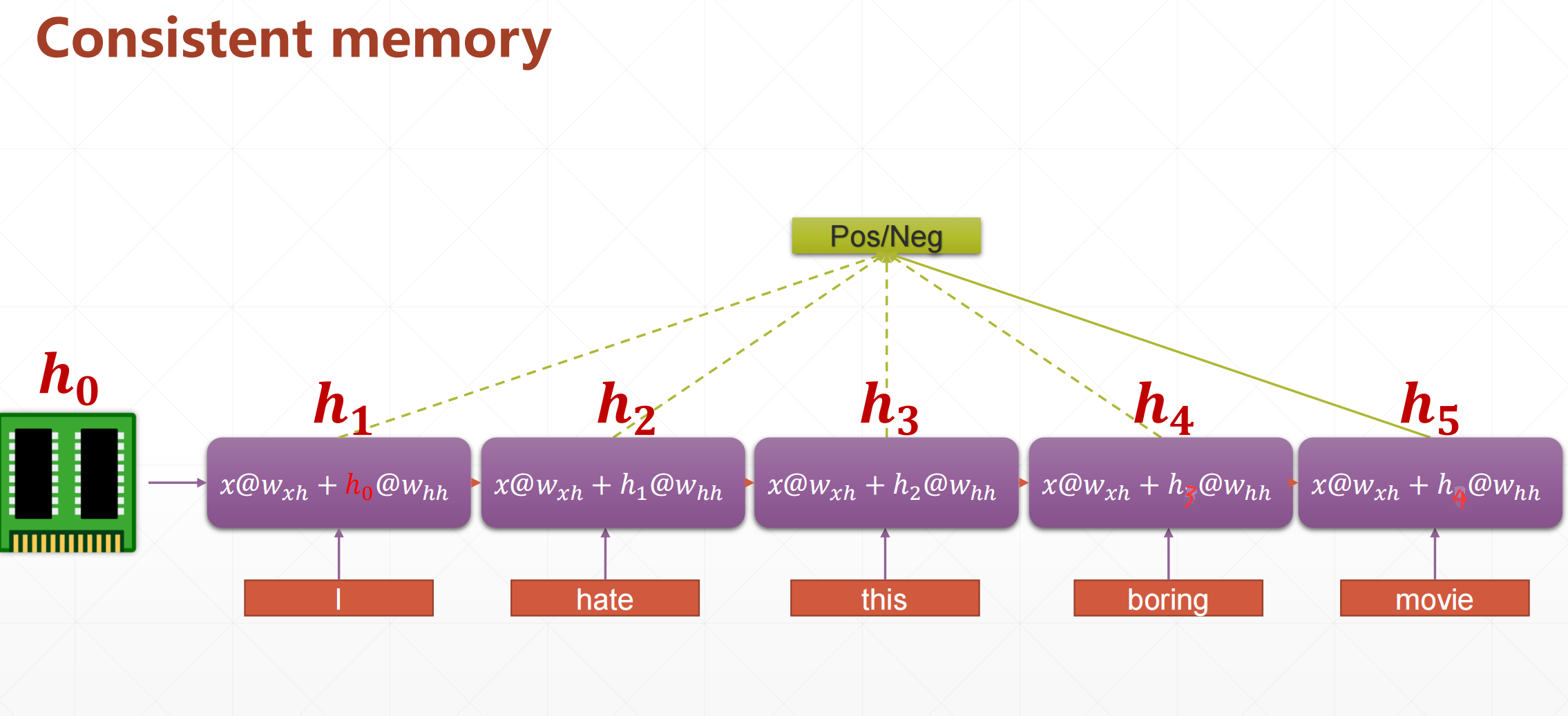
要想实现这个结构有两种方案:
SimpleRNNCell(这个更接近原理)
- single layer
- multi-layers
RNNCell(这个方便使用)
1.加载数据
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=1000)#
参数(num_words=10000)将数据限定为前10000个最常出现的单词,如果数据集中存在大于10000的单词,则令其为2。
要证明演示num_words=10000的作用,我找到了train_data中第1125条数据的第200个单词的单词编号为10003
print(train_data[1225][195:205])
输出1:[190, 2636, 8, 268, 1648, 10003, 3027, 24, 4, 294]
输出2:[190, 2636, 8, 268, 1648, 2, 3027, 24, 4, 294]
keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
这个函数就是把你个句子长度限制到80,如果小于80这补充0,大于这截断。
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
这里的drop_remainder=True的话就是最后那个不足128的batch就丢弃掉
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
batchsz = 128
# the most frequest words
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)#
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len) #这里就是强行将句子变成80长度,小于80的补0,大于的截取
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)#就是最后那个不足128的batch就丢弃掉
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
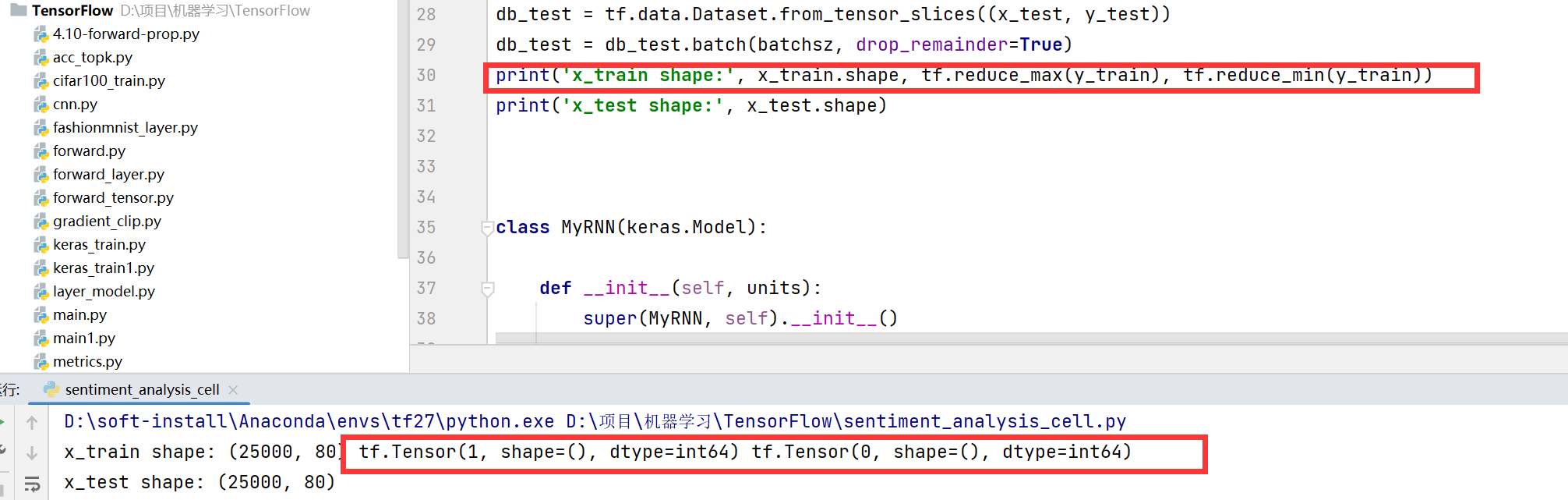
我们发现这个地方y=1的时候是好评,y=0的时候是差评。
2 单层RNN-cell的建立
tf.keras.layers.SimpleRNN(
units,#正整数,输出空间的维数
activation='tanh',#激活函数
use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros',
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,# dropout层的比例
recurrent_dropout=0.0,
return_sequences=False,#布尔值。是否返回输出序列中的最后一个输出或完整序列。默认值:False.
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,#布尔值(默认 False)。如果为 True,则网络将展开,否则将使用符号循环。展开可以加速 RNN,尽管它往往更需要内存。展开仅适用于短序列。
**kwargs
)

这是官网上的参数
然后还有一个全连接层的:
tf.keras.layers.Dense(
units,#正整数,输出空间的维数
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
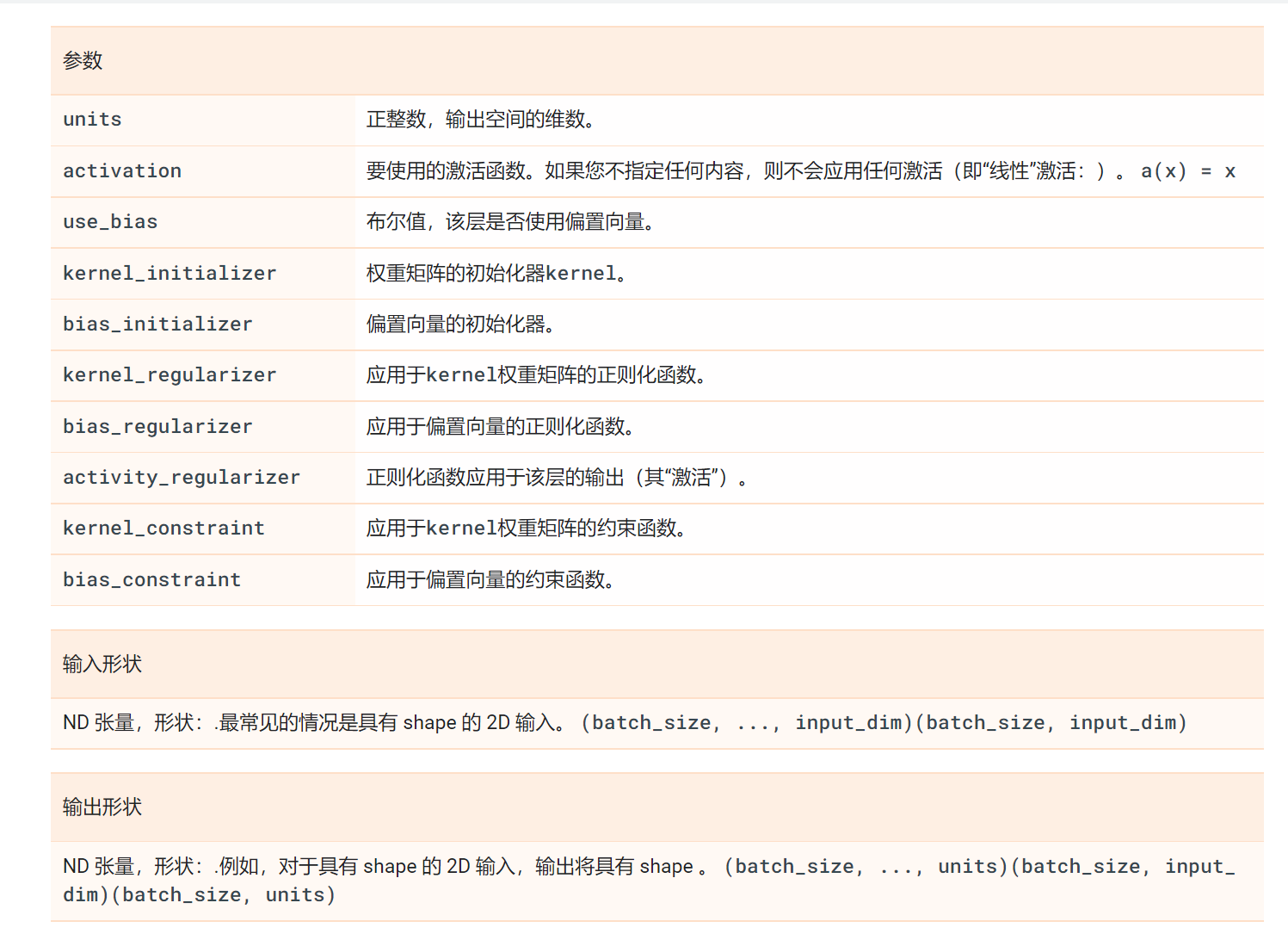
tf.keras.layers.Embedding(
input_dim,
output_dim,
embeddings_initializer='uniform',
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None,
sparse=False,
**kwargs
)

class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# transform text to embedding representation
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
self.rnn = keras.Sequential([
layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
layers.SimpleRNN(units, dropout=0.5, unroll=True)
])
# fc, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)# 全连接层
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# x: [b, 80, 100] => [b, 64]
x = self.rnn(x,training=training)
# out: [b, 64] => [b, 1]
x = self.outlayer(x)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# model.build(input_shape=(4,80))
# model.summary()
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
if __name__ == '__main__':
main()