原生推理库Paddle Inference
https://www.paddlepaddle.org.cn/tutorials/projectdetail/3949123
深度学习一般分为训练和推理两个部分,训练是神经网络“学习”的过程,主要关注如何搜索和求解模型参数,发现训练数据中的规律,生成模型。有了训练好的模型,就要在线上环境中应用模型,实现对未知数据做出推理,这个过程在AI领域叫做推理部署。用户可以选择如下四种部署应用方式之一:
- 服务器端高性能部署:将模型部署在服务器上,利用服务器的高性能帮助用户处理推理业务。
- 模型服务化部署:将模型以线上服务的形式部署在服务器或者云端,用户通过客户端请求发送需要推理的输入内容,服务器或者云通过响应报文将推理结果返回给用户。
- 移动端部署:将模型部署在移动端上,例如手机或者物联网的嵌入式端。
- Web端部署:将模型部署在网页上,用户通过网页完成推理业务。
本节将会为大家讲解如何使有飞桨实现服务器端高性能部署。
在实际应用中,推理部署阶段会面临和训练时完全不一样的硬件环境,当然也对应着不一样的计算性能要求。因此上线部署可能会遇到各种问题,例如上线部署的硬件环境和训练时不同;推理计算耗时太长, 可能造成服务不可用;模型占用内存过高无法上线。但是在实际业务中,我们训练得到的模型,就是需要能在具体生产环境中正确、高效地实现推理功能,完成上线部署。 对工业级部署而言,要求的条件往往非常繁多而且苛刻,不是每个深度学习框架都对实际生产部署上能有良好的支持。一款对推理支持完善的的框架,会让你的模型上线工作事半功倍。
飞桨作为源于产业实践的深度学习框架,在推理部署能力上有特别深厚的积累和打磨,提供了性能强劲、上手简单的服务器端推理库Paddle Inference,帮助用户摆脱各种上线部署的烦恼。
Paddle Inference是什么
飞桨框架的推理部署能力经过多个版本的升级迭代,形成了完善的推理库Paddle Inference。Paddle Inference功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
- 主流软硬件环境兼容适配
支持服务器端X86 CPU、NVIDIA GPU芯片,兼容Linux/macOS/Windows系统。 - 支持飞桨所有模型
支持所有飞桨训练产出的模型,真正即训即用。 - 多语言环境丰富接口可灵活调用
支持C++, Python, C, Go和R语言API, 接口简单灵活,20行代码即可完成部署。可通过Python API,实现对性能要求不太高的场景快速支持;通过C++高性能接口,可与线上系统联编;通过基础的C API可扩展支持更多语言的生产环境。
【性能测一测】
通过比较ResNet50和BERT模型的训练前向耗时和推理耗时,可以观测到Paddle Inference有显著的加速效果。
| 模型 | CPU训练前向耗时/ms | CPU推理耗时/ms | GPU训练前向耗时/ms | GPU推理耗时/ms |
|---|---|---|---|---|
| bert(21M) | 54 | 23 | 43 | 1.5 |
| Resnet50 | 236.780 | 49.604 | 8.47 | 4.49 |
说明:测试耗时的方法,使用相同的输入数据先空跑1000次,循环运行1000次,每次记录模型运行的耗时,最后计算出模型运行的平均耗时。
基于Paddle Inference的单机推理部署,即在一台机器进行推理部署。相比Paddle Serving在多机多卡下进行推理部署,单机推理部署不产生多机通信与调度的时间成本,能够最大程度地利用机器的Paddle Inference算力来提高推理部署的性能。对于拥有高算力机器,已有线上业务系统服务,期望加入模型推理作为一个子模块,且对性能要求较高的用户,采用单机推理部署能够充分利用计算资源,加速部署过程。
Paddle Inference高性能实现
内存/显存复用提升服务吞吐量
在推理初始化阶段,对模型中的OP输出Tensor 进行依赖分析,将两两互不依赖的Tensor在内存/显存空间上进行复用,进而增大计算并行量,提升服务吞吐量。
细粒度OP横向纵向融合减少计算量
在推理初始化阶段,按照已有的融合模式将模型中的多个OP融合成一个OP,减少了模型的计算量的同时,也减少了 Kernel Launch的次数,从而能提升推理性能。目前Paddle Inference支持的融合模式多达几十个。
内置高性能的CPU/GPU Kernel
内置同Intel、Nvidia共同打造的高性能kernel,保证了模型推理高性能的执行。
子图集成TensorRT加快GPU推理速度
Paddle Inference采用子图的形式集成TensorRT,针对GPU推理场景,TensorRT可对一些子图进行优化,包括OP的横向和纵向融合,过滤冗余的OP,并为OP自动选择最优的kernel,加快推理速度。
子图集成Paddle Lite轻量化推理引擎
Paddle Lite 是飞桨深度学习框架的一款轻量级、低框架开销的推理引擎,除了在移动端应用外,还可以使用服务器进行 Paddle Lite 推理。Paddle Inference采用子图的形式集成 Paddle Lite,以方便用户在服务器推理原有方式上稍加改动,即可开启 Paddle Lite 的推理能力,得到更快的推理速度。并且,使用 Paddle Lite 可支持在百度昆仑等高性能AI芯片上执行推理计算。
支持加载PaddleSlim量化压缩后的模型
PaddleSlim是飞桨深度学习模型压缩工具,Paddle Inference可联动PaddleSlim,支持加载量化、裁剪和蒸馏后的模型并部署,由此减小模型存储空间、减少计算占用内存、加快模型推理速度。其中在模型量化方面,Paddle Inference在X86 CPU上做了深度优化,常见分类模型的单线程性能可提升近3倍,ERNIE模型的单线程性能可提升2.68倍。

推理部署实战
场景划分
Paddle Inference应用场景,按照API接口类型可以分C++, Python, C, Go和R。Python适合直接应用,可通过Python API实现性能要求不太高的场景的快速支持;C++接口属于高性能接口,可与线上系统联编;C接口是基于C++,用于支持更多语言的生产环境。
不同接口的使用流程一致,但个别操作细节存在差异。其中,比较常见的场景是C++和Python。因此本教程以这两类接口为例,介绍如何使用Pdddle Inference API进行单机服务器的推理预测部署。
推理部署流程
使用Paddle Inference进行推理部署的流程如下所示。详细API文档请参考API文档
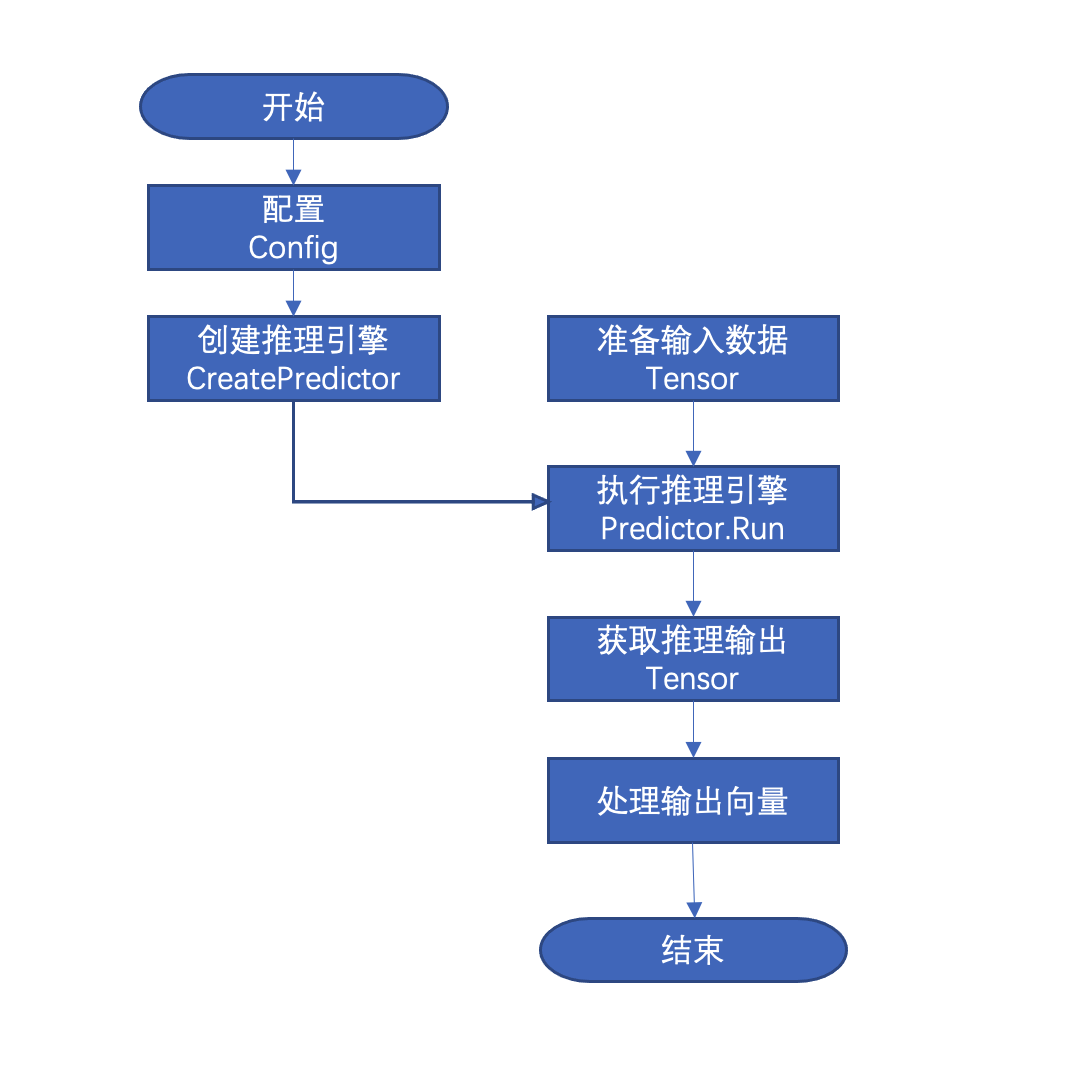
- 配置推理选项。
Config是飞桨提供的配置管理器API。在使用Paddle Inference进行推理部署过程中,需要使用Config详细地配置推理引擎参数,包括但不限于在何种设备(CPU/GPU)上部署、加载模型路径、开启/关闭计算图分析优化、使用MKLDNN/TensorRT进行部署的加速等。参数的具体设置需要根据实际需求来定。 - 创建
Predictor。Predictor是飞桨提供的推理引擎API。根据设定好的推理配置Config创建推理引擎Predictor,也就是推理引擎的一个实例。创建期间会进行模型加载、分析和优化等工作。 - 准备输入数据。准备好待输入推理引擎的数据,首先获得模型中每个输入的名称以及指向该数据块(CPU或GPU上)的指针,再根据名称将对应的数据块拷贝进
Tensor。飞桨采用Tensor作为输入/输出数据结构,可以减少额外的拷贝,提升推理性能。 - 调用Predictor.Run()执行推理。
- 获取推理输出。与输入数据类似,根据输出名称将输出的数据(矩阵向量)由
Tensor拷贝至(CPU或GPU上)以进行后续的处理。 - 最后,获取输出并不意味着预测过程的结束,在一些特别的场景中,单纯的矩阵向量不能让使用者明白它有什么意义。进一步地,我们需要根据向量本身的意义,解析数据,获取实际的输出。举个例子,transformer 翻译模型,我们将字词变成向量输入到预测引擎中,而预测引擎反馈给我们的,仍然是矩阵向量。但是这些矩阵向量是有意义的,我们利用这些向量去找翻译结果所对应的句子,就完成了使用 transformer 翻译的过程。
以上操作的具体使用方法和示例会在下文给出。
前提准备
-
安装或源码编译推理库
使用飞桨进行推理部署,需要使用与当前部署环境一致的Paddle推理库。
如果使用Python API,只需本地电脑成功安装Paddle,安装方法请参考快速安装。
如果使用C++/C API,需要下载或编译推理库。推荐先从飞桨官网下载推理库,下载请点击推理库。如果官网提供的推理库版本无法满足需求,或想要对代码进行自定义修改,可以采用源码编译的方式获取推理库,推理库的编译请参考前文“源码编译”。 -
导出模型文件
模型部署首先要有部署的模型文件。模型部署首先要有部署的模型文件。在动态图模型训练过程中或者模型训练结束后,可以通过paddle.jit.save 接口来导出用于部署的标准化模型文件。而对于静态图模型,则可以使用paddle.static.save_inference_model保存模型。两种方式都可以根据推理需要的输入和输出, 对训练模型进行剪枝, 去除和推理无关部分, 得到的模型相比训练时更加精简, 适合进一步优化和部署。
我们用一个简单的例子来展示下导出模型文件的这一过程。
-
我们用一个简单的例子来展示下导出模型文件的这一过程。
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
@paddle.jit.to_static
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
# save
path = "example.model/linear"
paddle.jit.save(layer, path)W0511 10:17:34.233616 117 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0511 10:17:34.238706 117 gpu_context.cc:272] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) andEpoch 0 batch 0: loss = 2.361412286758423
Epoch 0 batch 1: loss = 2.555819511413574
Epoch 0 batch 2: loss = 2.3603224754333496
Epoch 0 batch 3: loss = 2.3046326637268066
Epoch 1 batch 0: loss = 2.0856692790985107
Epoch 1 batch 1: loss = 2.229004144668579
Epoch 1 batch 2: loss = 2.0080854892730713
Epoch 1 batch 3: loss = 2.091014862060547
Epoch 2 batch 0: loss = 2.35357666015625
Epoch 2 batch 1: loss = 2.4300479888916016
Epoch 2 batch 2: loss = 2.3404417037963867
Epoch 2 batch 3: loss = 2.212562084197998
Epoch 3 batch 0: loss = 2.0857276916503906
Epoch 3 batch 1: loss = 2.3606109619140625
Epoch 3 batch 2: loss = 2.3114867210388184
Epoch 3 batch 3: loss = 2.0755224227905273该程序运行结束后,会在本目录中生成一个example.model目录,目录中包含linear.pdmodel, linear.pdiparams 两个文件,linear.pdmodel文件表示模型的结构文件,linear.pdiparams表示所有参数的融合文件。
基于C++ API的推理部署
为了简单方便地进行推理部署,飞桨提供了一套高度优化的C++ API推理接口。下面对各主要API使用方法进行详细介绍。
API详细介绍
在上述的推理部署流程中,我们了解到Paddle Inference预测包含了以下几个方面:
- 配置推理选项
- 创建predictor
- 准备模型输入
- 模型推理
- 获取模型输出
那我们先用一个简单的程序介绍这一过程:
std::unique_ptr<paddle_infer::Predictor> CreatePredictor() {
// 通过Config配置推理选项
paddle_infer::Config config;
config.SetModel("./model/resnet50.pdmodel",
"./model/resnet50.pdiparams");
config.EnableUseGpu(100, 0);
config.EnableMKLDNN();
config.EnableMemoryOptim();
// 创建Predictor
return paddle_infer::CreatePredictor(config);
}
void Run(paddle_infer::Predictor *predictor,
const std::vector<float>& input,
const std::vector<int>& input_shape,
std::vector<float> *out_data) {
// 准备模型的输入
int input_num = std::accumulate(input_shape.begin(), input_shape.end(), 1, std::multiplies<int>());
auto input_names = predictor->GetInputNames();
auto input_t = predictor->GetInputHandle(input_names[0]);
input_t->Reshape(input_shape);
input_t->CopyFromCpu(input.data());
// 模型推理
CHECK(predictor->Run());
// 获取模型的输出
auto output_names = predictor->GetOutputNames();
// there is only one output of Resnet50
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1, std::multiplies<int>());
out_data->resize(out_num);
output_t->CopyToCpu(out_data->data());
}以上的程序中CreatePredictor函数对推理过程进行了配置以及创建了Predictor。 Run函数进行了输入数据的准备,模型推理以及输出数据的获取过程。
接下来我们依次对程序中出现的Config、模型输入输出和Predictor做一个详细的介绍。
使用Config管理推理配置
Config管理Predictor的推理配置,提供了模型路径设置、推理引擎运行设备选择以及多种优化推理流程的选项。配置中包括了必选配置以及可选配置。
1. 必选配置
1-1 设置模型和参数路径
- 从文件加载:模型文件夹
model_dir下有一个模型文件my.pdmodel和一个参数文件my.pdiparams时,传入模型文件和参数文件路径。使用方式为:config->SetModel("./model_dir/my.pdmodel", "./model_dir/my.pdiparams");。 - 内存加载模式:如果模型是从内存加载,可以使用
config->SetModelBuffer(model.data(), model.size(), params.data(), params.size())。
2. 可选配置
2-1 加速CPU推理
// 开启MKLDNN,可加速CPU推理,要求预测库带MKLDNN功能。
config->EnableMKLDNN();
// 可以设置CPU数学库线程数math_threads,可加速推理。
// 注意:math_threads * 外部线程数 需要小于总的CPU的核心数目,否则会影响预测性能。
config->SetCpuMathLibraryNumThreads(10); 2-2 使用GPU推理
// EnableUseGpu后,模型将运行在GPU上。
// 第一个参数表示预先分配显存数目,第二个参数表示设备的ID。
config->EnableUseGpu(100, 0); 如果使用的预测lib带Paddle-TRT子图功能,可以打开TRT选项进行加速:
// 开启TensorRT推理,可提升GPU推理性能,需要使用带TensorRT的推理库
config->EnableTensorRtEngine(1 << 30 /*workspace_size*/,
batch_size /*max_batch_size*/,
3 /*min_subgraph_size*/,
paddle_infer::PrecisionType::kFloat32 /*precision*/,
false /*use_static*/,
false /*use_calib_mode*/);通过计算图分析,Paddle可以自动将计算图中部分子图融合,并调用NVIDIA的 TensorRT 来进行加速。
2-3 内存/显存优化
config->EnableMemoryOptim(); // 开启内存/显存复用该配置设置后,在模型图分析阶段会对图中的变量进行依赖分类,两两互不依赖的变量会使用同一块内存/显存空间,缩减了运行时的内存/显存占用(模型较大或batch较大时效果显著)。
2-4 debug开关
// 该配置设置后,会关闭模型图分析阶段的任何图优化,预测期间运行同训练前向代码一致。
config->SwitchIrOptim(false);// 该配置设置后,会在模型图分析的每个阶段后保存图的拓扑信息到.dot文件中,该文件可用graphviz可视化。
config->SwitchIrDebug();使用Tensor管理输入/输出
1. 准备输入
1-1 获取模型所有输入的tensor名字
std::vector<std::string> input_names = predictor->GetInputNames();1-2 获取对应名字下的tensor
// 获取第0个输入
auto input_t = predictor->GetInputHandle(input_names[0]);1-3 将数据copy到tensor中
// 在copy前需要设置tensor的shape
input_t->Reshape({batch_size, channels, height, width});
// tensor会根据上述设置的shape从input_data中拷贝对应数目的数据到tensor中。
input_t->CopyFromCpu<float>(input_data /*数据指针*/);当然我们也可以用mutable_data获取tensor的数据指针:
// 参数可为paddle_infer::PlaceType::kGPU, paddle_infer::PlaceType::kCPU
float *input_d = input_t->mutable_data<float>(paddle_infer::PlaceType::kGPU);2. 获取输出
2-1 获取模型所有输出的tensor名字
std::vector<std::string> out_names = predictor->GetOutputNames();2-2 获取对应名字下的tensor
// 获取第0个输出
auto output_t = predictor->GetOutputHandle(out_names[0]);2-3 将数据copy到tensor中
std::vector<float> out_data;
// 获取输出的shpae
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1, std::multiplies<int>());
out_data->resize(out_num);
output_t->CopyToCpu(out_data->data());我们可以用data接口获取tensor的数据指针:
// 参数可为paddle_infer::PlaceType::kGPU, paddle_infer::PlaceType::kCPU
int output_size;
float *output_d = output_t->data<float>(paddle_infer::PlaceType::kGPU, &output_size);使用Predictor进行高性能推理
Predictor是在模型上执行推理的预测器,根据Config中的配置进行创建。
auto predictor = paddle_infer::CreatePredictor(config);paddle_infer::CreatePredictor期间首先对模型进行加载,并且将模型转换为由变量和运算节点组成的计算图。接下来将进行一系列的图优化,包括OP的横向纵向融合,删除无用节点,内存/显存优化,以及子图(Paddle-TRT)的分析,加速推理性能,提高吞吐。
C++ API使用示例
本节提供一个使用飞桨 C++ 预测库和ResNet50模型进行图像分类预测的代码示例,展示预测库使用的完整流程。示例代码地址
一:获取Resnet50模型
点击链接下载模型, 该模型在imagenet 数据集训练得到的,如果你想获取更多的模型训练信息,请访问这里。
二:样例编译
文件resnet50_test.cc 为预测的样例程序(程序中的输入为固定值,如果您有opencv或其他方式进行数据读取的需求,需要对程序进行一定的修改)。
脚本compile.sh 包含了第三方库、预编译库的信息配置。
编译Resnet50样例,我们首先需要对脚本compile.sh 文件中的配置进行修改。
1)修改compile.sh
打开compile.sh,我们对以下的几处信息进行修改:
# 根据预编译库中的version.txt信息判断是否将以下三个标记打开
WITH_MKL=ON
WITH_GPU=ON
USE_TENSORRT=OFF
# 配置预测库的根目录
LIB_DIR=${YOUR_LIB_DIR}/paddle_inference_install_dir
# 如果上述的WITH_GPU 或 USE_TENSORRT设为ON,请设置对应的CUDA, CUDNN, TENSORRT的路径。
CUDNN_LIB=/paddle/nvidia-downloads/cudnn_v7.5_cuda10.1/lib64
CUDA_LIB=/paddle/nvidia-downloads/cuda-10.1/lib64
# TENSORRT_ROOT=/paddle/nvidia-downloads/TensorRT-6.0.1.5运行 sh compile.sh, 会在目录下产生build目录。
2) 运行样例
bash run.sh
# 或者
bash compile.sh
./build/resnet50_test -model_file resnet50/inference.pdmodel --params_file resnet50/inference.pdiparams运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
C++ API性能调优
在前面预测接口的介绍中,我们了解到,通过使用Config可以对Predictor进行配置模型运行的信息。
在本节中,我们会对Config中的优化配置进行详细的介绍。
优化原理
预测主要存在两个方面的优化,一是预测期间内存/显存的占用,二是预测花费的时间。
- 预测期间内存/显存的占用决定了一个模型在机器上的并行的数量,如果一个任务是包含了多个模型串行执行的过程,内存/显存的占用也会决定任务是否能够正常执行(尤其对GPU的显存来说)。内存/显存优化增大了模型的并行量,提升了服务吞吐量,同时也保证了任务的正常执行,因此显的极为重要。
- 预测的一个重要的指标是模型预测的时间,通过对 kernel 的优化,以及加速库的使用,能够充份利用机器资源,使得预测任务高性能运行。
1. 内存/显存优化
在预测初始化阶段,飞桨预测引擎会对模型中的 OP 输出 Tensor 进行依赖分析,将两两互不依赖的 Tensor 在内存/显存空间上进行复用。
可以通过调用以下接口方式打开内存/显存优化。
Config config;
config.EnableMemoryOptim();运行过推理之后,如果想回收推理引擎使用的临时内存/显存,降低内存/显存的使用,可以通过以下接口。
config.TryShrinkMemory();内存/显存优化效果
| 模型 | 关闭优化 | 打开优化 |
|---|---|---|
| MobileNetv1(batch_size=128 ) | 3915MB | 1820MB |
| ResNet50(batch_size=128) | 6794MB | 2204MB |
2. 性能优化
在模型预测期间,飞将预测引擎会对模型中进行一系列的 OP 融合,比如 Conv 和 BN 的融合,Conv 和 Bias、Relu 的融合等。OP 融合不仅能够减少模型的计算量,同时可以减少 Kernel Launch 的次数,从而能提升模型的性能。
可以通过调用以下接口方式打开 OP 融合优化:
Config config;
config.SwitchIrOptim(true); // 默认打开除了通用的 OP 融合优化外,飞桨预测引擎有针对性的对 CPU 以及 GPU 进行了性能优化。
CPU 性能优化
1.对矩阵库设置多线程
模型在CPU预测期间,大量的运算依托于矩阵库,如 OpenBlas,MKL。 通过设置矩阵库内部多线程,能够充分利用 CPU 的计算资源,加速运算性能。
可以通过调用以下接口方式设置矩阵库内部多线程。
Config config;
// 通常情况下,矩阵内部多线程(num) * 外部线程数量 <= CPU核心数
config->SetCpuMathLibraryNumThreads(num); 2.使用 MKLDNN 加速
MKLDNN是Intel发布的开源的深度学习软件包。目前飞桨预测引擎中已经有大量的OP使用MKLDNN加速,包括:Conv,Batch Norm,Activation,Elementwise,Mul,Transpose,Pool2d,Softmax 等。
可以通过调用以下接口方式打开MKLDNN优化。
Config config;
config.EnableMKLDNN(); 开关打开后,飞桨预测引擎会使用 MKLDNN 加速的 Kernel 运行,从而加速 CPU 的运行性能。
GPU 性能优化
使用 TensorRT 子图性能优化
TensorRT 是 NVIDIA 发布的一个高性能的深度学习预测库,飞桨预测引擎采用子图的形式对 TensorRT 进行了集成。在预测初始化阶段,通过对模型分析,将模型中可以使用 TensorRT 运行的 OP 进行标注,同时把这些标记过的且互相连接的 OP 融合成子图并转换成一个 TRT OP 。在预测期间,如果遇到 TRT OP ,则调用 TensorRT 库对该 OP 进行优化加速。
可以通过调用以下接口的方式打开 TensorRT 子图性能优化:
config->EnableTensorRtEngine(1 << 30 /* workspace_size*/,
batch_size /* max_batch_size*/,
3 /* min_subgraph_size*/,
paddle_infer::PrecisionType::kFloat32 /* precision*/,
false /* use_static*/,
false /* use_calib_mode*/);该接口中的参数的详细介绍如下:
- workspace_size,类型:int,默认值为1 << 20。指定TensorRT使用的工作空间大小,TensorRT会在该大小限制下筛选合适的kernel执行预测运算,一般可以设置为几百兆(如1 << 29, 512M)。
- max_batch_size,类型:int,默认值为1。需要提前设置最大的batch大小,运行时batch大小不得超过此限定值。
- min_subgraph_size,类型:int,默认值为3。Paddle-TRT 是以子图的形式运行,为了避免性能损失,当子图内部节点个数大于min_subgraph_size的时候,才会使用Paddle-TRT运行。
- precision,类型:enum class Precision {kFloat32 = 0, kHalf, kInt8,};, 默认值为PrecisionType::kFloat32。指定使用TRT的精度,支持FP32(kFloat32),FP16(kHalf),Int8(kInt8)。若需要使用Paddle-TRT int8离线量化校准,需设定precision为 - PrecisionType::kInt8, 且设置use_calib_mode 为true。
- use_static,类型:bool, 默认值为 false 。如果指定为 true ,在初次运行程序的时候会将 TRT 的优化信息进行序列化到磁盘上,下次运行时直接加载优化的序列化信息而不需要重新生成。
- use_calib_mode,类型:bool, 默认值为false。若要运行 Paddle-TRT int8 离线量化校准,需要将此选项设置为 true 。
目前 TensorRT 子图对图像模型有很好的支持,支持的模型如下
- 分类:Mobilenetv1/2, ResNet, NasNet, VGG, ResNext, Inception, DPN,ShuffleNet
- 检测:SSD,YOLOv3,FasterRCNN,RetinaNet
- 分割:ICNET,UNET,DeepLabV3,MaskRCNN
基于Python API的推理部署
飞桨提供了高度优化的C++测库,为了方便使用,我们也提供了与C++预测库对应的Python接口。使用Python预测API与C++预测API相似,主要包括Tensor, Config和Predictor,分别对应于C++ API中同名的数据类型。接下来给出更为详细的介绍。
使用Config管理推理配置
paddle.inference.Config是创建预测引擎的配置,提供了模型路径设置、预测引擎运行设备选择以及多种优化预测流程的选项。通过Config,可以指定,预测引擎执行的方式。举几个例子,如果我们希望预测引擎在 CPU 上运行,那么,我们可以设置disable_gpu()的选项配置,那么在实际执行的时候,预测引擎会在 CPU 上执行。同样,如果设置switch_ir_optim()为True或是False,则决定了预测引擎是否会自动进行优化。
使用之前,我们需要创建一个Config的实例,用于完成这些选项的设置。
config = paddle.inference.Config()Config可以设置的选项,具体如下:
-
set_model(): 设置模型的路径,model_filename:模型文件名,params_filename:参数文件名。config.set_model(model_filename, params_filename)
既然模型的文件已经配置好了,那么我们还需要指定我们的预测引擎是在什么设备上执行的,就是说,需要指定在 CPU 上或是在 GPU 的哪一张卡上预测。
-
enable_use_gpu(): 启用使用 GPU 的预测方式,并且设置 GPU 初始分配的显存(单位M)和 Device ID,即是在哪一张 GPU 的卡上执行预测。 需要另外注意的是,Device ID,假设,我们现在有一台8张显卡的机器,我们设定环境变量如下:export CUDA_VISIBLE_DEVICES=1,3,5那么,在使用
enable_use_gpu()设置 Device ID 的时候,可以设置的卡的编号是:0,1,2。0号卡实际代表的是机器上的编号为1的显卡,而1号卡实际代表的是机器上编号为3的显卡,同理,2号卡实际代表的是机器上的编号为5的显卡。 -
gpu_device_id(): 返回使用的 GPU 的 Device ID。 -
disable_gpu(): 该方法从字面上理解是禁用 GPU,即,是使用 CPU 进行预测。
完成了模型的配置,执行预测引擎的设备的设定,我们还可以进行一些其他的配置。比如:
-
switch_ir_optim(): 打开或是关闭预测引擎的优化,默认是开启的。设置的方式如下:config.switch_ir_optim(True) -
enable_tensorrt_engine(): 启用TensorRT的引擎进行预测优化。具体的参数信息和上文使用TensorRT子图性能优化是一样的。这里提供一个简单的设置示例。config.enable_tensorrt_engine(precision_mode=paddle.inference.PrecisionType.Float32, use_calib_mode=True) -
enable_mkldnn(): 开启 MKLDNN 加速选项,一般是使用 CPU 进行预测的时候,如果机器支持 MKLDNN 可以开启。config.enable_mkldnn() -
disable_glog_info(): 禁用预测中所有的日志信息。
在完成了Config的设置之后,我们可以通过配置的Config,创建一个用于执行预测引擎的实例,这个实例是基于数据结构Predictor,创建的方式是直接调用paddle.inference.create_predictor()方法。如下:
predictor = paddle.inference.create_predictor(config)Config示例
首先,如前文所说,设置模型和参数路径:
config = paddle.inference.Config("./model/resnet50.pdmodel", "./model/resnet50.pdiparams")使用set_model()方法设置模型和参数路径方式同上。
其他预测引擎配置选项示例如下:
config.enable_use_gpu(100, 0) # 初始化100M显存,使用gpu id为0
config.gpu_device_id() # 返回正在使用的gpu device id
config.disable_gpu() # 禁用gpu,使用cpu进行预测
config.switch_ir_optim(True) # 开启IR优化
config.enable_tensorrt_engine(precision_mode=paddle.inference.PrecisionType.Float32,
use_calib_mode=True) # 开启TensorRT预测,精度为fp32,开启int8离线量化
config.enable_mkldnn() # 开启MKLDNN最后,根据config得到预测引擎的实例predictor:
predictor = paddle.inference.create_predictor(config)使用Tensor管理输入/输出
Tensor是Predictor的一种输入/输出数据结构,下面我们将用详细的例子加以讲解。
首先,我们配置好了Config的一个实例config,接下来,需要使用这个config创建一个predictor。
# 创建predictor
predictor = paddle.inference.create_predictor(config)因为config里面包含了模型的信息,在这里,我们创建好了predictor之后,实际上已经可以获取模型的输入的名称了。因此,可以通过
input_names = predictor.get_input_names()获取模型输入的名称。需要注意的是,这里的input_names是一个List[str],存储着模型所有输入的名称。进而,可以通过每一个输入的名称,得到Tensor的一个实例,此时,输入数据的名称已经和对应的Tensor关联起来了,无需再另外设置数据的名称。
input_tensor = predictor.get_input_handle(input_names[0])得到数据之后,就可以完成对数据的设置了。
fake_input = numpy.random.randn(1, 3, 224, 224).astype("float32")
input_tensor.copy_from_cpu(fake_input)使用一个copy_from_cpu()方法即可完成设置,数据类型,通过numpy来保证。 在实际的使用过程中,有的用户会问到,”如果我想将预测引擎在 GPU 上执行怎么办呢?是否有一个copy_from_gpu()的方法?“ 回答也很简单,没有copy_from_gpu()的方法,无论是在 CPU 上执行预测引擎,还是在 GPU 上执行预测引擎,copy_from_cpu()就够了。
接着,执行预测引擎:
# 运行predictor
predictor.run()完成预测引擎的执行之后,我们需要获得预测的输出。与设置输入类似 首先,我们获取输出的名称 其次,根据输出的名称得到Tensor的实例,用来关联输出的Tensor。 最后,使用copy_to_cpu()得到输出的矩阵向量。
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu() # numpy.ndarray类型使用Predictor进行高性能推理
class paddle.inference.Predictor
Predictor是运行预测的引擎,由paddle.inference.create_predictor(config)创建。
Predictor示例
import numpy
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./model/resnet50.pdmodel", "./model/resnet50.pdiparams")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
# 获取输入 Tensor
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
# 从 CPU 获取数据,设置到 Tensor 内部
fake_input = numpy.random.randn(1, 3, 224, 224).astype("float32")
input_tensor.copy_from_cpu(fake_input)
# 执行预测
predictor.run()支持方法列表
在这里,我们先做一个总结。总结下前文介绍的使用预测库的 Python API 都有哪些方法。
- Tensor
copy_from_cpu(input: numpy.ndarray) -> Nonecopy_to_cpu() -> numpy.ndarrayreshape(input: numpy.ndarray|List[int]) -> Noneshape() -> List[int]set_lod(input: numpy.ndarray|List[List[int]]) -> Nonelod() -> List[List[int]]type() -> PaddleDType
- Config
set_model(prog_file: str, params_file: str) -> Noneprog_file() -> strparams_file() -> strenable_use_gpu(memory_pool_init_size_mb: int, device_id: int) -> Nonegpu_device_id() -> intswitch_ir_optim(x: bool = True) -> Noneenable_tensorrt_engine(workspace_size: int = 1 << 20, max_batch_size: int, min_subgraph_size: int, precision_mode: PrecisionType, use_static: bool, use_calib_mode: bool) -> Noneenable_mkldnn() -> Nonedisable_glog_info() -> Nonedelete_pass(pass_name: str) -> None
- Predictor
run() -> Noneget_input_names() -> List[str]get_input_handle(input_name: str) -> Tensorget_output_names() -> List[str]get_output_handle(output_name: str) -> Tensor
Python API使用示例
下面是使用Python API进行推理的一个完整示例。
使用前文提前准备生成的模型example.model,在该路径下即可找到预测需要的模型文件linear.pdmodel和参数文件linear.pdiparams。
我们可以ls查看一下对应的路径下面内容:
ls example.model linear.pdiparams linear.pdiparams.info linear.pdmodel模型文件准备好了,接下来,可以直接运行下面的代码得到预测的结果,预测的结果。
最后的output_data就是预测程序返回的结果,output_data是一个numpy.ndarray类型的数组,可以直接获取其数据的值。output_data作为一个numpy.ndarray,大家需要自定义不同的后处理方式也更为方便。以下的代码就是使用Python预测API全部的部分。
如下的实例中,我们打印出了前10个数据。输出的数据的形状是[1, 1000],其中1代表的是batch_size的大小,1000是这唯一一个样本的输出,有1000个数据。
import numpy as np
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
def main():
# 设置Config
config = set_config()
# 创建Predictor
predictor = paddle_infer.create_predictor(config)
# 获取输入的名称
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
# 设置输入
fake_input = np.random.randn(1,784).astype("float32")
input_tensor.copy_from_cpu(fake_input)
# 运行predictor
predictor.run()
# 获取输出
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu() # numpy.ndarray类型
print("输出的形状如下: ")
print(output_data.shape)
print("输出前10个的数据如下: ")
print(output_data[:10])
def set_config():
config = paddle_infer.Config("./example.model/linear.pdmodel", "./example.model/linear.pdiparams")
config.disable_gpu()
return config
if __name__ == "__main__":
main() 输出的形状如下:
(1, 10)
输出前10个的数据如下:
[[ 1.392835 -2.1492589 -1.244189 -0.5736715 1.6074656 2.109792
-0.04553057 1.1988349 1.3468434 -0.6586081 ]]--- Running analysis [ir_graph_build_pass]--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [layer_norm_fuse_pass]
--- Fused 0 subgraphs into layer_norm op.
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- fused 0 pairs of fc gru patterns
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [gpu_cpu_squeeze2_matmul_fuse_pass]
--- Running IR pass [gpu_cpu_reshape2_matmul_fuse_pass]
--- Running IR pass [gpu_cpu_flatten2_matmul_fuse_pass]
--- Running IR pass [matmul_v2_scale_fuse_pass]
--- Running IR pass [gpu_cpu_map_matmul_v2_to_mul_pass]
I0511 10:18:07.135977 117 fuse_pass_base.cc:57] --- detected 1 subgraphs
--- Running IR pass [gpu_cpu_map_matmul_v2_to_matmul_pass]
--- Running IR pass [matmul_scale_fuse_pass]
--- Running IR pass [gpu_cpu_map_matmul_to_mul_pass]
--- Running IR pass [fc_fuse_pass]
I0511 10:18:07.136333 117 fuse_pass_base.cc:57] --- detected 1 subgraphs
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [conv_transpose_bn_fuse_pass]
--- Running IR pass [conv_transpose_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I0511 10:18:07.138321 117 analysis_predictor.cc:1006] ======= optimize end =======
I0511 10:18:07.138358 117 naive_executor.cc:102] --- skip [feed], feed -> generated_var_0
I0511 10:18:07.138401 117 naive_executor.cc:102] --- skip [linear_1.tmp_1], fetch -> fetchPython API性能调优
Python 预测 API 的优化与 C++ 预测 API 的优化方法完全一样。大家在使用的时候,可以参照 C++ 预测 API 的优化说明。唯一存在不同的是,调用的方法的名称,在这里,我们做了一个对应的表格供大家查阅。
| C++预测API函数名称 | Python预测API函数名称 |
|---|---|
EnableMemoryOptim() |
enable_memory_optim() |
SwitchIrOptim(true) |
switch_ir_optim(True) |
EnableMKLDNN() |
enable_mkldnn() |
SetCpuMathLibraryNumThreads(num) |
set_cpu_math_library_num_threads(num) |
EnableTensorRtEngine() |
enable_tensorrt_engine() |
以上方法在使用 Python 预测 API 的时候,都可以直接使用
config.methods_name()完成调用与配置。