1. Pre
title: Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
accepted: arXiv 2023 (ICLR 2024 Submission)
paper: https://arxiv.org/abs/2303.01469
code: https://github.com/openai/consistency_models
ref: https://mp.weixin.qq.com/s/7xa7VXm6lz1dkAK3IJtekQ (prime)
ref: https://zhuanlan.zhihu.com/p/623402026 (prime)
ref: https://zhuanlan.zhihu.com/p/621673283
ref: https://zhuanlan.zhihu.com/p/622444022
关键词: Consistency Models, Diffusion, latent space, Tsinghua University
阅读理由: 了解前沿
2. Idea
将一致性模型按照LDM的方式用到图片潜空间上,同时加入 classifier-free guidance 来实现条件生成,并使用跳步法加快模型收敛
3. Motivation&Solution
- 当前扩散模型依赖于迭代生成过程,这导致此类方法采样速度缓慢 —— 一致性模型+跳步(SKIPPING-STEP)策略
- 当前的一致性模型仅限于像素空间图像生成任务,且不能做文本到图像的合成 —— 模拟LDM学习图片潜空间
4. Background
4.1. Diffusion Models from SDE
前向过程中,扩散模型将原始数据分布 \(p_{data}(x)\) 转换为边缘分布 \(q_t(x_t)\) 。该过程基于 transition kernel \(q_{0t}(x_{t}\mid x_{0}) = \mathcal{N}(x_{t} \mid \alpha(t)x_{0},\sigma^{2}(t)I)\) 进行,看起来是描述了从 \(x_0\) 到 \(x_t\) 所需施加的噪声。
一步步看,数据 \(x_0\) 通过 \(x_i=\sqrt {1-\beta_i} x_{i-1}+\sqrt \beta_i\mathcal \epsilon_i,\ \ i=1,\ldots N\) 实现加噪,\(\epsilon_i\) 即是每步加入的噪声,将上述公式连续化得到 \(x_t\) 的SDE: \(d x=-{1\over 2}\beta(t) x_tdt+\sqrt{\beta(t)} d w(t),\ \ t\in[0,T]\),数据x的变化情况?可记为 \(d x= f(x)x_t dt+g(t) d w_t\),其中\(w_t\)是 standard Brownian motion,其中
考虑逆向时间 SDE,边缘分布 \(q_t(x_t)\) 满足下面的常微分方程(ODE, ordinary differential equation),名为 概率流 ODE (PF-ODE, Probability Flow ODE):
按论文的表述,公式2也能记成:
总之公式2、公式3描述了 \(x_t\) 的变化,能通过它将噪声变回图片,扩散模型通过一个噪声预测模型 \(s_\theta(x_t,t)\) 来拟合 \(\nabla_x\log q_t(x_t)\)(称作 score function)。
公式4描述了逆向时间SDE,它具有与正向过程SDE相同的联合分布
按论文的说法,公式3用参考文献[21]的噪声预测模型带入可得:
如果是类别条件(class-conditioned)扩散模型需要用到 Classifier-Free Guidance (CFG) ,通过 CFG scale \(\omega\) 将原始的噪声预测替换为条件和非条件噪声预测的线性组合,举个例子(但不是这里的式子): \(\tilde{\epsilon}_{\theta}(z_{t},\omega,c,t) = (1+\omega)\epsilon_{\theta}(z_{t},c,t) - \omega\epsilon_{\theta}(z,\emptyset,t).\)
4.2. Diffusion Models from ODE
公式4、5用一个SDE(逆向随机过程)来描述扩散过程的逆过程,但也存在一个ODE(确定性过程)可描述该逆向过程
这个ODE称为概率流ODE(probability flow ODE, PF ODE),它沿着概率流的轨迹(也就是ODE的解函数)建立了从噪声分布中的点 \(x_T \sim q_T(x_T)\) 到数据分布中的点 \(x_0\sim p_{data}(x)\) 的映射,因此能确定性地解出一条从 \(x_T\) 到 \(x_0\) 的轨迹。
4.3. Consistency Models
PF ODE 虽然能将采样的高斯噪声映射到数据,但求解ODE仍然需要多次迭代,多次计算 \(s_\theta(x_t,t)\) 而Consistency models(一致性模型)希望直接学习ODE的解:任给某个轨迹上的点 \(x_t\),一步得到 \(x_0\)
复杂的公式就算了,只记结论:
一致性函数定义为: \(f:(x_t,t) \mapsto x_\epsilon,\ t\in[\epsilon,T]\) ,其中 \(\epsilon\) 是一个固定的、足够小的正数,之所以不直接用0作为边界条件,是为了数值稳定性,因为t=0处的score function值可能非常大
一致性函数应当满足自一致性属性:
它表示 \([\epsilon,T]\) 范围内的任意两个点的函数值应该是相同的。
一致性函数用模型来实现的话,其实可以有很多种,可以考虑skip connection结构:
其中 \(c_{skip}(t),\; c_{out}(t)\) 是可微函数,并且满足 \(c_{skip}(\epsilon)=1,\;c_{out}(\epsilon)=0\) ,而 \(F_\theta(x,t)\) 是深度神经网络。(感觉当 \(t \neq \epsilon\) 时就得靠 \(F_\theta(x,t)\) 将结果拖向 \(x_0\)
CM可以由预训练的扩散模型蒸馏(CD, Consistency Distillation),也可以从头开始单独训练(CT, Consistency Training)。
4.4. Consistency Distillation
如果 score function 已知(有一个预训练模型 \(s_\theta(x_t,t)\) ),则公式6的PF ODE确定,用它求出 \(\hat{x}(\epsilon)\),直接优化 \(\Vert f_\theta(x_t,t)-\hat{x}(\epsilon)\Vert^2\) 即可。但这样对每个样本 \((x_t, t)\) 都得先解一遍ODE才有 \(\hat{x}(\epsilon)\),效率较低。
还有个办法是监督轨迹上相邻两点输出一致,首先采样 \(x_{t_{n+1}}\) 再由其近似估计PF ODE轨迹上的点 \(\hat{x}^\phi_{t_n}\) (这里没看懂为啥不能直接采样出 \(x_{t_{n}}\)):
然后约束这两点距离接近就能得到一致性模型的损失:
其中 \(d(\cdot, \cdot)\) 是测量两样本间距离的指标函数,例如L2距离。 \(f_{\theta^-}\) 是通过指数滑动平均(EMA)更新的模型, \(\theta^-\leftarrow \mathrm {stopgrad}(\mu\theta^-+(1-\mu)\theta)\)
4.5. Consistency Training
如果没有现成的 \(s_\theta(x_t,t)\) 就需要从数据中估计 score function \(\nabla_x\log q_t(x_t)\)。
放弃思考:
可以推导出估计score function的公式
其中 \(x\sim p_{data},x_t|x\sim \mathcal N(x,t^2I)\) ,通过蒙特卡洛采样法可估计损失:
假定有一个真值 score function: \(s_{\phi^*}(x,t)=\nabla\log p_t(x_t)\),通过泰勒展开能够证明: \(\mathcal L_{CD}^N(\theta,\theta^-;\phi^*) - \mathcal L_{CT}^N(\theta,\theta^-)=o(\Delta t)\)
4.6. others
提高扩散模型的生成速度一般有两种方法:
- 增强ODE solver来加速降噪过程,只需10~20step即可生成图片
- 将预训练的扩散模型蒸馏为少步推理的模型
一致性模型允许单步生成,但有两个缺点:
- 仅限于像素空间(对应潜空间图像生成,Latent Diffusion Models那样?)图像生成任务(constrained to pixel space image),因此不适合合成高分辨率图像。
- 还没有探索条件扩散模型的应用和无分类器引导的结合,因此他们的方法不适合文本到图像的合成。
5. Method(Model)
LATENT CONSISTENCY MODELS 作者在文章中提到,尽管之前的一致性模型 (CMs) 专注于 ImageNet 64×64 和 LSUN 256×256 的图像生成任务,但它们在高分辨率的文本到图像任务上的潜力仍未被探索。为了解决这更具挑战性的任务,作者提出了“潜在一致性模型” (LCMs)。与 LDMs 类似,LCMs 在图像潜在空间中采用一致性模型,并选择了强大的 Stable Diffusion 作为底层的扩散模型进行蒸馏。此外,作者还提出了简化的单阶段引导蒸馏方法和"SKIPPING-STEP"技术来加速 LCMs 的收敛。
5.1. consistency distillation in the latent space
像LDM一样,搞个自编码器得到图片的潜空间,然后在潜空间上进行一致性蒸馏(好像没啥新东西)。作者的重点放在了条件生成上,对照公式5给出了反向扩散过程的 PF-ODE:
其中 \(z_t\) 是图像潜向量,\(c\) 是给定的条件,如文本。之后步骤差不多,同样引入了一致性函数,用上自一致性属性来约束相邻两点接近,得到一致性蒸馏损失...
5.2. one-stage guided distillation by solving augmented pf-ode
Classifier-free guidance (CFG) 对于SD合成高质量文本对齐的图片很重要,通常需要 CFG scale w 大于6,因此,将 CFG 整合到蒸馏方法中是不可或缺的。之前的 Guided-Distill 方法引入了两阶段蒸馏以支持从引导扩散模型中进行少步采样,但这种方法在计算上非常密集(2步推理需要45个 A100 GPUs 天)。相比之下,LCM 仅需要32个 A100 GPUs 小时的训练时间,如图1所示。
而且两阶段引导蒸馏可能导致累积误差,LCMs通过解增强的PF-ODE实现高效的单阶段引导蒸馏,像之前反向扩散过程用CFG一样:
其中 \(\omega\) 就是引导系数,解下列增强PF-ODE就能从引导反向过程中采样:
给出纳入 \(\omega\) 后对应的蒸馏损失。
5.3. accelerating distillation with skipping time steps
作者提到,离散扩散模型通常使用一个长时间步进度表(time-step schedule)(也称为离散化进度表或时间进度表,将生成分成多少份?)来达到高质量的生成效果。Stable Diffusion 的时间进度表长度为1,000,但 Latent Consistency Distillation (LCD) 由于用一致性损失,如果进度表也用1000,相邻两个点 \(t_n - t_{n+1}\) 就很小, 导致 \(z_{t_n} - z_{t_{n+1}}\) 原本就接近,这样算出来的损失就很小,收敛速度慢。
因此作者引入跳步方法(SKIPPING-STEP),缩短了时间进度表的长度,改为确保当前时间步与后面 k 步之间的一致性, \(t_{n+k} - t_n\),实验中k设置为20。

算法1
算法1是使用CFG和跳步技术的LCD伪代码,蓝色部分是修改自原始 Consistency Distillation (CD) 算法的部分
5.4. latent consistency fine-tuning for customized dataset
Stable Diffusion 这种基础生成模型在多种文本到图像的生成任务中表现出色,但通常需要针对定制的数据集进行微调,以满足下游任务的需求。作者提出了一种名为 Latent Consistency Fine-tuning (LCF) 的预训练LCM的微调方法。受到Consistency Training (CT)的启发,LCF能够在定制数据集上进行高效的少步推理,而无需依赖在这些数据上训练的教师扩散模型。这种方法为扩散模型的传统微调方法提供了一个可行的替代方案。
6. Experiment
6.1. Settings
教师模型用的预训练 Stable Diffusion-V2.1 ,学习率 8e-6,EMA率 μ=0.999943,DDIM-Solver,跳步k=20,引导系数范围 \(\omega_{min},\omega_{max} = [2,14]\)
6.2. Dataset
用了 LAION-5B 的两个子集: LAION-Aesthetics-6+ (12M) 和 LAION-Aesthetics-6.5+ (650K)
6.3. Results

图1 Latent Consistency Models (LCMs) 生成的图片,CFG scale w=8.0 LCMs可以从任何预训练SD模型蒸馏而来,仅需4000训练步数(约32 A100GPU小时),就能在2~4步甚至单步中生成768x768分辨率的图片。作者用LCM蒸馏了SD的Dreamer-V7。
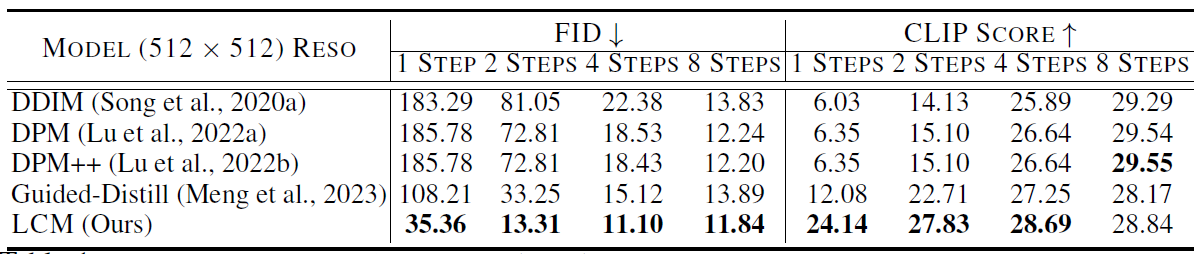
表1 w=8时512x512分辨率的定量结果 LCM在1-4步生成上大幅超越了基线,使用了DDIM-Solver,跳步k=20,数据集LAION-Aesthetic-6+
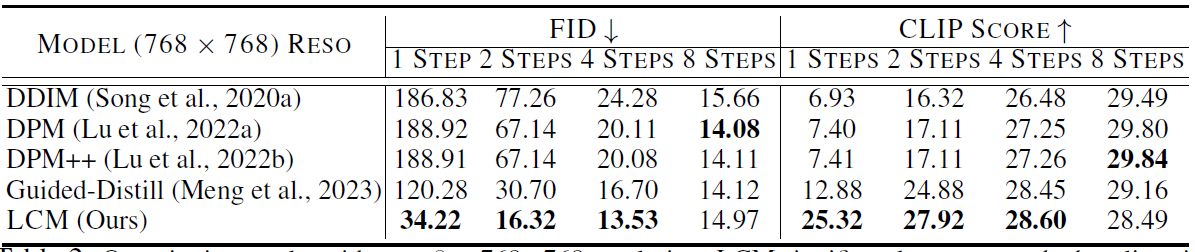
表2 w=8时768x768分辨率的定量结果 数据集LAION-Aesthetic-6.5+ 其他同表1

图2 LAION-Aesthetic-6.5+上2/4步文生图结果。
表1表2显示了LCM在两种分辨率设置下的优势,而且不像 DDIM, DPM, DPM++ 每个采样步需要更多的峰值显存(memory)来跑CFG,LCM只需要一次前向,既省了时间又省了显存。而且它只需要一阶段的引导蒸馏,更简单更实在。图2的定性结果展示了它在2、4步推理时的优越性。
6.4. ABLATION STUDY
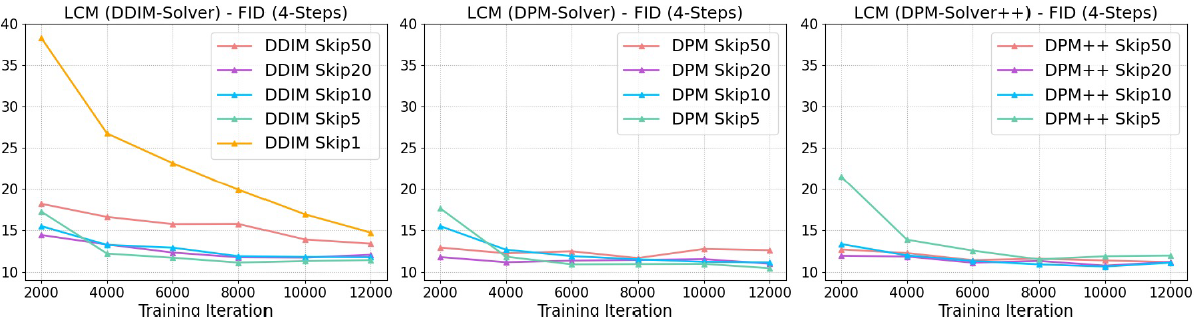
图3 不同ODE solver和跳步k的消融研究。恰当的k能有效加速收敛并在相同训练步数下取得更好的FID。
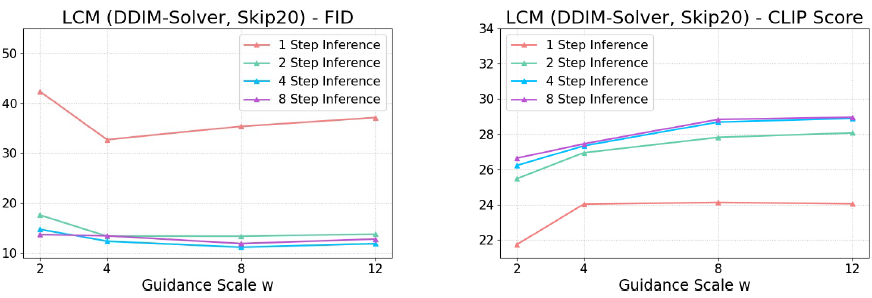
图4 不同引导系数w的消融,更大的w有更好的采样质量(CLIP分数),而2、4、8步的差距很小,显示了LCM的有效性。

图5 4步LCM生成结果,更大的w能增强图片质量。
图3能看出 DPM/DPM++ solver 在大跳步时表现好于DDIM,因为DDIM在k值大的时候ODE近似误差会增大,综合来说k=20最合适。而\(\omega\)一般用于权衡采样质量和多样性,更大的值会提高采样质量(CLIP分数高),但导致多样性差(FID高),如图4,其中单步生成质量明显不足,后续还有改进空间。图5可视化了不同\(\omega\)的结果,验证了单阶段引导蒸馏方法的有效性。
6.5. DOWNSTREAM CONSISTENCY FINE-TUNING RESULTS

图6 4步LCM在两个定制数据集进行LCF:宝可梦数据集(左),辛普森数据集(右)
7. Conclusion
提出了 Latent Consistency Models (LCMs),高效的单阶段引导蒸馏方法,可以在预训练LDM上实现少步或单步推理。并且提出了 consistency fine-tuning (LCF) 在定制数据集上微调LCM做少步推理。将来的工作可以扩展该方法去做更多的图片生成任务,如文本引导的图片编辑、修补和超分辨率。
8. Critique
感觉有用的句子:"We admit that longer training and more computational resources can lead
to better results as reported in (Meng et al., 2023). However, LCM achieves faster convergence and
superior results under the same computation cost."
这一篇看下来好像就是把之前一些成熟的想法缝在一起,创新性是否有些不足,不过从扩散模型到一致性模型的知识讲得还挺清晰的。同样宣称单步生成,一眼就想到了之前那个 Rectified Flow。
- High-Resolution Synthesizing Consistency Resolution Inferencehigh-resolution synthesizing consistency resolution high-resolution high-resolution segmentation multi-path refinement high-resolution resolution improving diffusion high-resolution segmentation注意力deformable synthesizing consistency inference self-consistency group_replication_consistency