一. Motivation
1. transformer的工作主要集中在设计transformer块以获得全局信息,而忽略了合并高频先验的潜力
2. 关于频率对性能的影响的详细分析有限(Additionally, there is limited detailed analysis of the impact of frequency on performance.)
注:
(1)
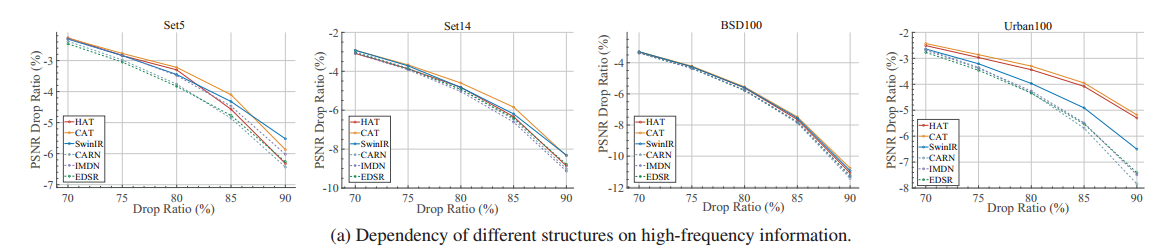
图说明:随着高频信息的丢失(高频Drop Ratio越来越大),虚线CNN明显下降,实线Transformer下降相对比CNN小,所以Transformer对低频信息的捕获能力强,对高频信息的捕获能力弱。
PSNR Drop Ratio: 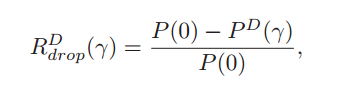
P(0)代表原始PSNR(without Dropping)
(2)PSNR 高频信息是怎么下降的

二. Contribution
1. 从频率的角度研究了CNN和transformer对性能影响,发现transformer善于捕获低频信息,不善于捕获高频信息
2. 设计了平行结构,HFERB分支捕捉高频信息,SRAWB分支捕获全局信息
3. HFERB作为高频先验Q,SRAWB作为transformer的K,V进行注意力融合
三. Network
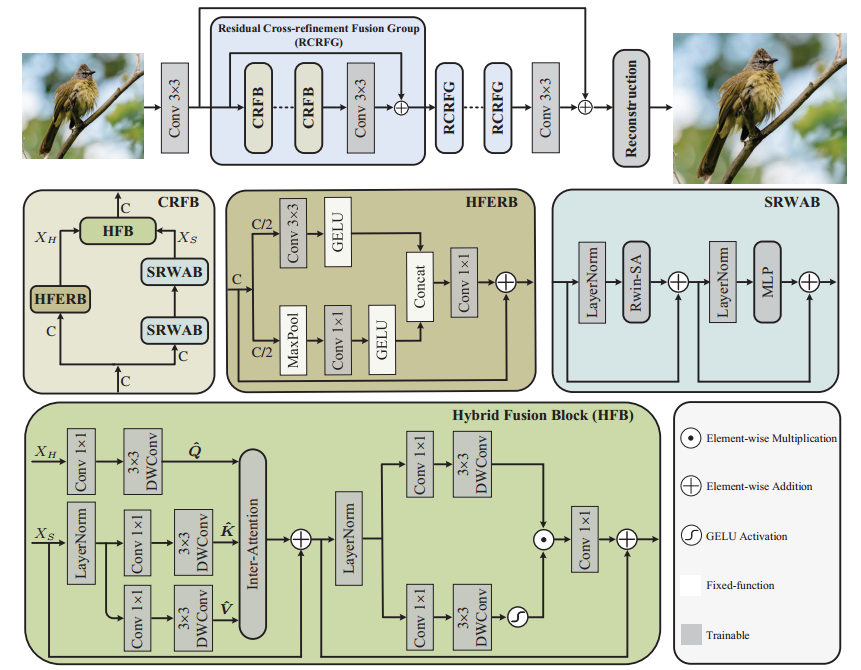
1. 总结构:首先通过Conv 3×3进行浅层特征提取,送入多个串行的RCRFG中,最后经过Conv 3×3和跳连接进行重建
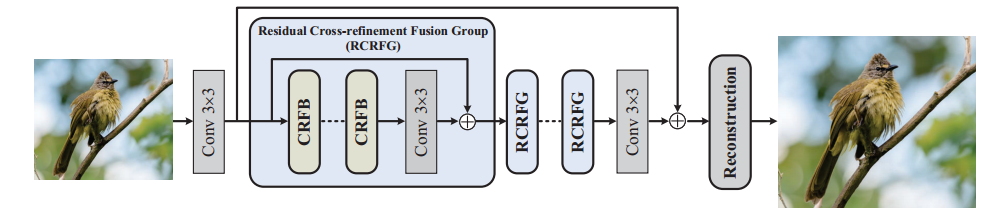
2. 每个RCRFG包括三个CRFB和一个卷积Conv 3×3残差
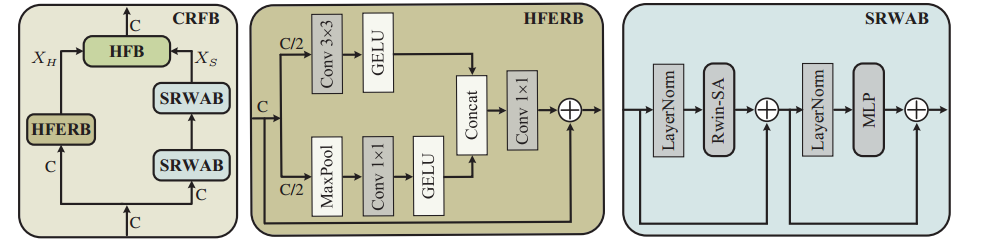
HFERB是高频先验:


class HFERB(nn.Module): def __init__(self, dim) -> None: super().__init__() self.mid_dim = dim//2 self.dim = dim self.act = nn.GELU() self.last_fc = nn.Conv2d(self.dim, self.dim, 1) # High-frequency enhancement branch self.fc = nn.Conv2d(self.mid_dim, self.mid_dim, 1) self.max_pool = nn.MaxPool2d(3, 1, 1) # Local feature extraction branch self.conv = nn.Conv2d(self.mid_dim, self.mid_dim, 3, 1, 1) def forward(self, x): self.h, self.w = x.shape[2:] short = x # Local feature extraction branch lfe = self.act(self.conv(x[:,:self.mid_dim,:,:])) # High-frequency enhancement branch hfe = self.act(self.fc(self.max_pool(x[:,self.mid_dim:,:,:]))) x = torch.cat([lfe, hfe], dim=1) x = short + self.last_fc(x) return x
HFERB模块的核心是高频增强分支,它使用了最大池化层来提取特征图的高频信息。最大池化层的作用是在一个局部区域内选取最大的像素值,这样可以突出特征图中的边缘和纹理等细节特征,也就是高频信息。同时,最大池化层也可以起到降低特征图的空间分辨率的作用,这样可以减少计算量和内存消耗
SRWAB:
class SRWAB(nn.Module): r""" Shift Rectangle Window Attention Block. Args: dim (int): Number of input channels. num_heads (int): Number of attention heads. split_size (int): Define the window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set. act_layer (nn.Module, optional): Activation layer. Default: nn.GELU norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__(self, dim, num_heads, split_size=(2,2), shift_size=(0,0), mlp_ratio=2., qkv_bias=True, qk_scale=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm): super().__init__() self.dim = dim self.shift_size = shift_size self.mlp_ratio = mlp_ratio self.norm1 = norm_layer(dim) self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.proj = nn.Linear(dim, dim) self.branch_num = 2 self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1,groups=dim) # DW Conv self.attns = nn.ModuleList([ Attention_regular( dim//2, idx = i, split_size=split_size, num_heads=num_heads//2, dim_out=dim//2, qk_scale=qk_scale, position_bias=True) for i in range(self.branch_num)]) self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer) def forward(self, x, x_size, params, attn_mask=NotImplementedError): h, w = x_size self.h,self.w = x_size b, l, c = x.shape shortcut = x x = self.norm1(x) qkv = self.qkv(x).reshape(b, -1, 3, c).permute(2, 0, 1, 3) # 3, B, HW, C v = qkv[2].transpose(-2,-1).contiguous().view(b, c, h, w) # cyclic shift if self.shift_size[0] > 0 or self.shift_size[1] > 0: qkv = qkv.view(3, b, h, w, c) # H-Shift qkv_0 = torch.roll(qkv[:,:,:,:,:c//2], shifts=(-self.shift_size[0], -self.shift_size[1]), dims=(2, 3)) qkv_0 = qkv_0.view(3, b, h*w, c//2) # V-Shift qkv_1 = torch.roll(qkv[:,:,:,:,c//2:], shifts=(-self.shift_size[1], -self.shift_size[0]), dims=(2, 3)) qkv_1 = qkv_1.view(3, b, h*w, c//2) # H-Rwin x1_shift = self.attns[0](qkv_0, h, w, mask=attn_mask[0], rpi=params['rpi_sa_h'], rpe_biases=params['biases_h']) # V-Rwin x2_shift = self.attns[1](qkv_1, h, w, mask=attn_mask[1], rpi=params['rpi_sa_v'], rpe_biases=params['biases_v']) x1 = torch.roll(x1_shift, shifts=(self.shift_size[0], self.shift_size[1]), dims=(1, 2)) x2 = torch.roll(x2_shift, shifts=(self.shift_size[1], self.shift_size[0]), dims=(1, 2)) # Concat attened_x = torch.cat([x1,x2], dim=-1) else: # H-Rwin x1 = self.attns[0](qkv[:,:,:,:c//2], h, w, rpi=params['rpi_sa_h'], rpe_biases=params['biases_h']) # V-Rwin x2 = self.attns[1](qkv[:,:,:,c//2:], h, w, rpi=params['rpi_sa_v'], rpe_biases=params['biases_v']) # Concat attened_x = torch.cat([x1,x2], dim=-1) attened_x = attened_x.view(b, -1, c).contiguous() # Locality Complementary Module lcm = self.get_v(v) lcm = lcm.permute(0, 2, 3, 1).contiguous().view(b, -1, c) attened_x = attened_x + lcm attened_x = self.proj(attened_x) # FFN x = shortcut + attened_x x = x + self.mlp(self.norm2(x)) return x
3. HFERB的输出作为高频Xh,SRWAB作为低频Xs
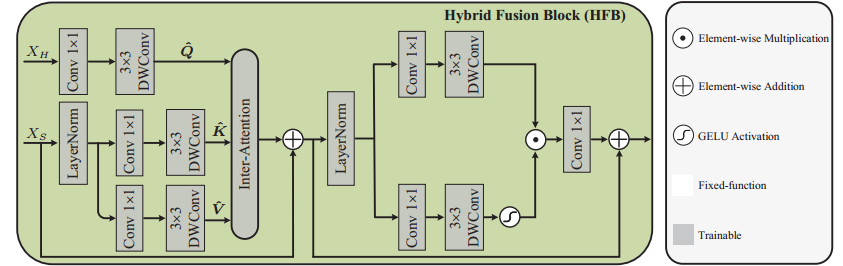
class HFB(nn.Module): r""" Hybrid Fusion Block. Args: dim (int): Number of input channels. num_heads (int): Number of attention heads. ffn_expansion_factor (int): Define the window size. bias (int): Shift size for SW-MSA. LayerNorm_type (float): Ratio of mlp hidden dim to embedding dim. """ def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type): super(HFB, self).__init__() self.norm1 = LayerNorm(dim, LayerNorm_type) self.attn = Attention(dim, num_heads, bias) self.norm2 = LayerNorm(dim, LayerNorm_type) self.ffn = FeedForward(dim, ffn_expansion_factor, bias) self.dim = dim def forward(self, low, high): self.h, self.w = low.shape[2:] x = low + self.attn(self.norm1(low), high) x = x + self.ffn(self.norm2(x))
## High-frequency prior query inter attention layer class Attention(nn.Module): def __init__(self, dim, num_heads, bias, train_size=(1, 3, 48, 48), base_size=(int(48 * 1.5), int(48 * 1.5))): super(Attention, self).__init__() self.num_heads = num_heads self.train_size = train_size self.base_size = base_size self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1)) self.dim = dim self.softmax = nn.Softmax(dim=-1) self.q = nn.Conv2d(dim, dim, kernel_size=1, bias=bias) self.q_dwconv = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim, bias=bias) self.kv = nn.Conv2d(dim, dim*2, kernel_size=1, bias=bias) self.kv_dwconv = nn.Conv2d(dim*2, dim*2, kernel_size=3, stride=1, padding=1, groups=dim*2, bias=bias) self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias) def _forward(self, q, kv): k,v = kv.chunk(2, dim=1) q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads) k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads) v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads) q = torch.nn.functional.normalize(q, dim=-1) k = torch.nn.functional.normalize(k, dim=-1) attn = (q @ k.transpose(-2, -1)) * self.temperature attn = self.softmax(attn) out = (attn @ v) return out def forward(self, low, high): self.h, self.w = low.shape[2:] q = self.q_dwconv(self.q(high)) kv = self.kv_dwconv(self.kv(low)) out = self._forward(q, kv) out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=kv.shape[-2], w=kv.shape[-1]) out = self.project_out(out) return out
- Cross-Refinement Super-Resolution High-Frequency Representation ICCV_Featurecross-refinement super-resolution high-frequency iccv_feature high-frequency cross-refinement super-resolution super-resolution convolutional resolution real-time super-resolution scale-arbitrary resolution cvpr_spatial-frequency super-resolution resolution super-resolution vdsr-accurate convolutional super-resolution continuous resolution diffusion