RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation
* Authors: [[Guosheng Lin]], [[Anton Milan]], [[Chunhua Shen]], [[Ian Reid]]
初读印象
comment:: (RefineNet)一种多路径的用于高分辨率语义分割的网络,用来解决池化和卷积导致的图片分辨率下降问题。
摘要
- 背景
However, repeated subsampling operations like pooling orconvolution striding in deep CNNs lead to a significant de-crease in the initial image resolution.
CNN的池化和卷积导致图片分辨率下降 - RefineNet:a generic multi-path refinement network
- 用残差结构将浅层精细特征传递给深层语义特征
- 可以端到端训练
- 用链式残差池获得丰富的背景上下文
- 结果
- 在七个数据集上成为了state of art
- PASCAL VOC 2012上的IOU为83.4
Motivation
-
核心问题背景
- 语义分割是图片理解中的重要一环
- 深度网络在分类任务中大放光彩(VGG,ResNet)
- 缺点:“This low-resolution feature map loses important visual details captured by early low-level filters” (Lin 等。, 2017, p. 3) (pdf)用以语义分割时图片维度下降太快,丢失精细信息
-
分辨率下降的解决方案
- FCN转置卷积:不能恢复低层特征
- DeepLab空洞卷积可以在缩减图片尺寸的情况下增大感受野
- 需要在很多高维特征映射上做很多次卷积
- 大量高维特征映射需要大量显存
- 膨胀卷积是对特征的粗采样,丢失细节
- FCN method in [36] and Hypercolumns in [22]用中间层的特征映射来生成高清晰的的预测
- 中间层信息和底层信息(空间特征)、高层信息(语义特征)都是互补的
-
出发点:features from all levels are helpful for se-mantic segmentation
- 高层:分类信息
- 低层:空间、形状信息
- 如何利用中层信息来产生高解析度的预测?
-
语义分割方法的演化
- region-proposal-based methods
- fully convolution network (FCNNs):文中说FCN是stage-wise训练的,可能是因为8s,16s,32s都是在前一个模型的基础上训练的?
- The atrous convolution basedapproach DeepLab-CRF
- CRF-RNN
- “Seg-Net and U-Net”(pdf):跳跃结构
Input and Output
Input:
- 训练:random scaling (ranging from 0.7 to 1.3), random cropping and horizontal flipping of the images后的图片和对应的ground truth
- 测试:test-time multi-scale evaluation——每张图片有多个不同的尺寸,每个epoch选随机取一个不同的尺寸
Output:深度学习高质量pixel-wise预测矩阵
Assumption
Framework
Multi-Path Refinement
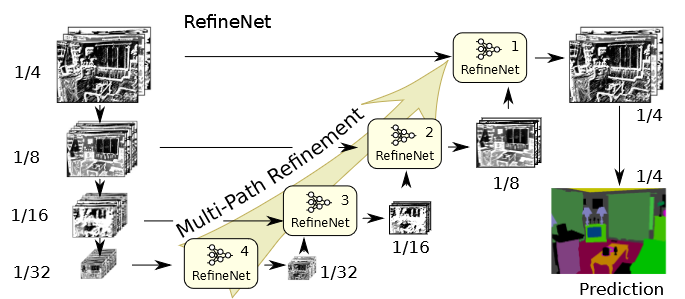
(pdf)
- 左边从上往下的一列是预训练好的ResNet(encoder-ResNet block-m代表第m个ResNet块),图片的缩小比例是ResNet自身结构决定的[image] (详见ResNet各块维度的输出pdf)
- 右边的RefineNet用来让ResNet适应语义分割的任务(Decoder:RefineNet-m同理)
- RefineNet-m接收ResNet block-m(long-range residual connetction)和RefineNet-m+1的输出(如果有的话)
- RefineNet-1的输出经过soft-max和双线性插值得到最终结果(pdf)
RefineNet
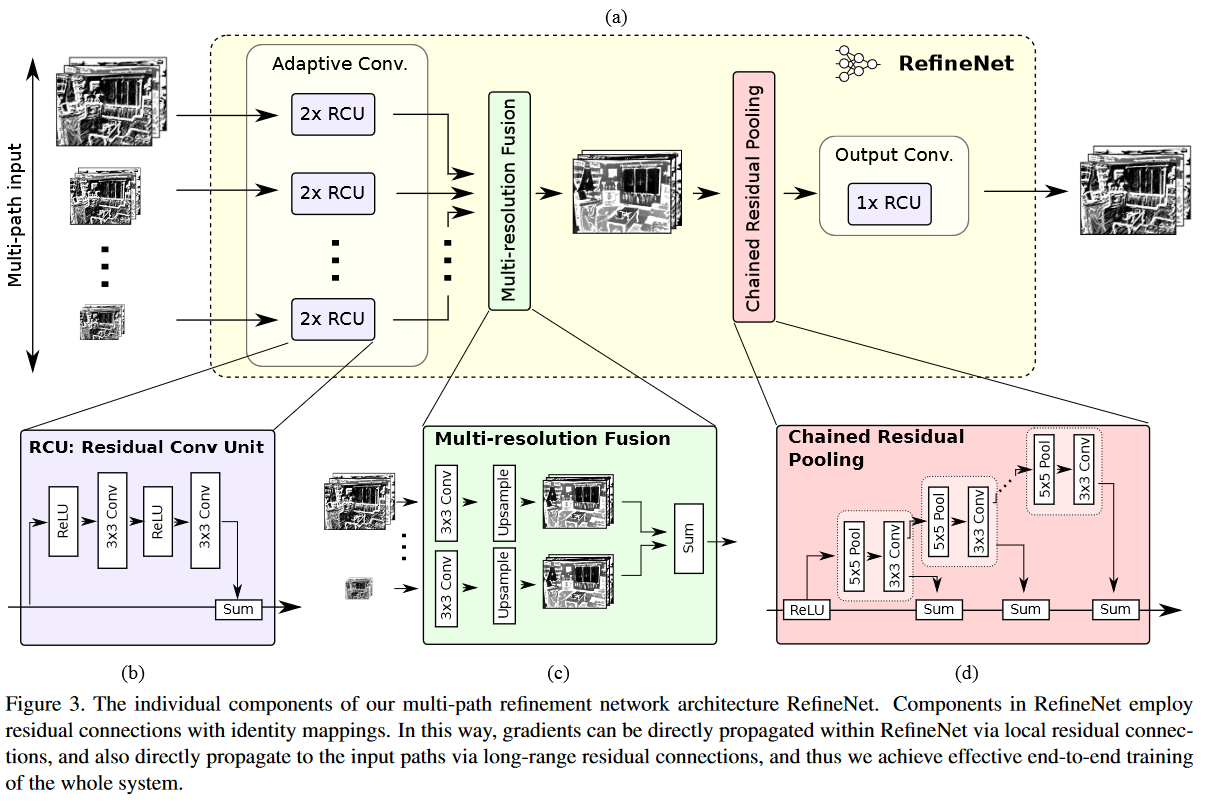
输入:任意个数的任意分辨率和通道数的特征映射(pdf)
输出:
组成:
- RCU×2:“Residual convolution unit” (pdf):使用预训练的ResNet块的权重,可微调,每条输入都会分别经过。filter的数量(output-channel)是256(除了RefineNet-4是512)。
- “Multi-resolution fusion” (pdf):汇聚所有输入,先都卷积成与最小映射矩阵相同的维度(这不是又压缩了吗?),再上采样成与最大的特征映射相同维度。相加所有特征映射。
- “Chained residual pooling”(pdf)
- 目的:“The proposed chained residual pooling aims to capture background context from a large image region.” (Lin 等。, 2017, p. 5) (pdf) 在大块图片区域获得背景上下文
- 多个pooling blocks串联组成,每个块包含一个汇聚层和卷积。每个块都以前一个块的输出为输入。每个块的输出都会和原始输入进行相加。
- 实验中默认使用两个pooling blocks,步长为1。
- “Output convolutions” (pdf):一个RCU,特征维度不变。
- “To reflect this behavior in the last RefineNet-1 block, we place two additional RCUs before the final softmax prediction step.” (Lin 等。, 2017, p. 5) (pdf)???
- CRP没有经过Relu,加这个层就是为了加一个非线性运算。
Identity Mapping in RefineNet
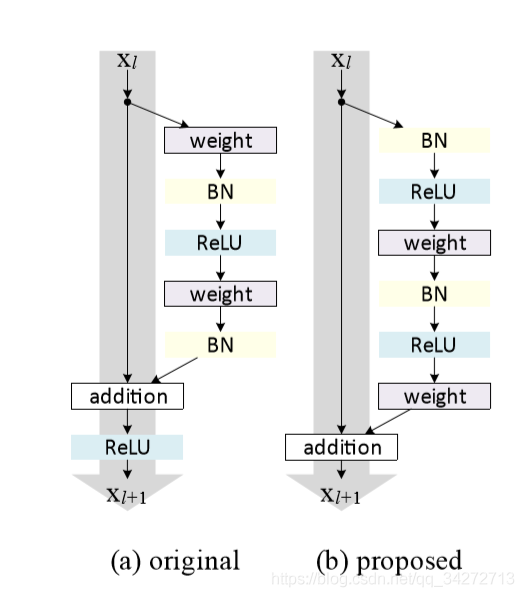
恒等映射:能使得前向和反向的信号能直接在模块之间传播。(pdf)
在h(x) = x的shortcut上不要设置任何非线性层(如Relu),非线性层放在其他分支上。
“Note that we include one non-linear activation layer (ReLU) in the chained residual pooling block. We observed that this ReLU is important for the effectiveness of subsequent pooling operations and it also makes the model less sensitive to changes in the learning rate.” (Lin 等。, 2017, p. 6) (pdf) CRP的第一层就是Relu。这个Relu完后后面就没有Relu了。
short-range是块内的残差连接;long-range是ResNet和RefineNet之间的,能够直接把梯度传递到浅层。
训练
- 数据增强:“random scaling (ranging from 0.7 to 1.3), random cropping and horizontal flipping of the images” (pdf)
- “test-time multi-scale evaluation” (pdf):输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。多尺度训练对全卷积网络有效,一般设置几种不同尺度的图片,训练时每隔一定iterations随机选取一种尺度训练。这样训练出来的模型鲁棒性强,其可以接受任意大小的图片作为输入,使用尺度小的图片测试速度会快些,但准确度低,用尺度大的图片测试速度慢,但是准确度高。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。
变体
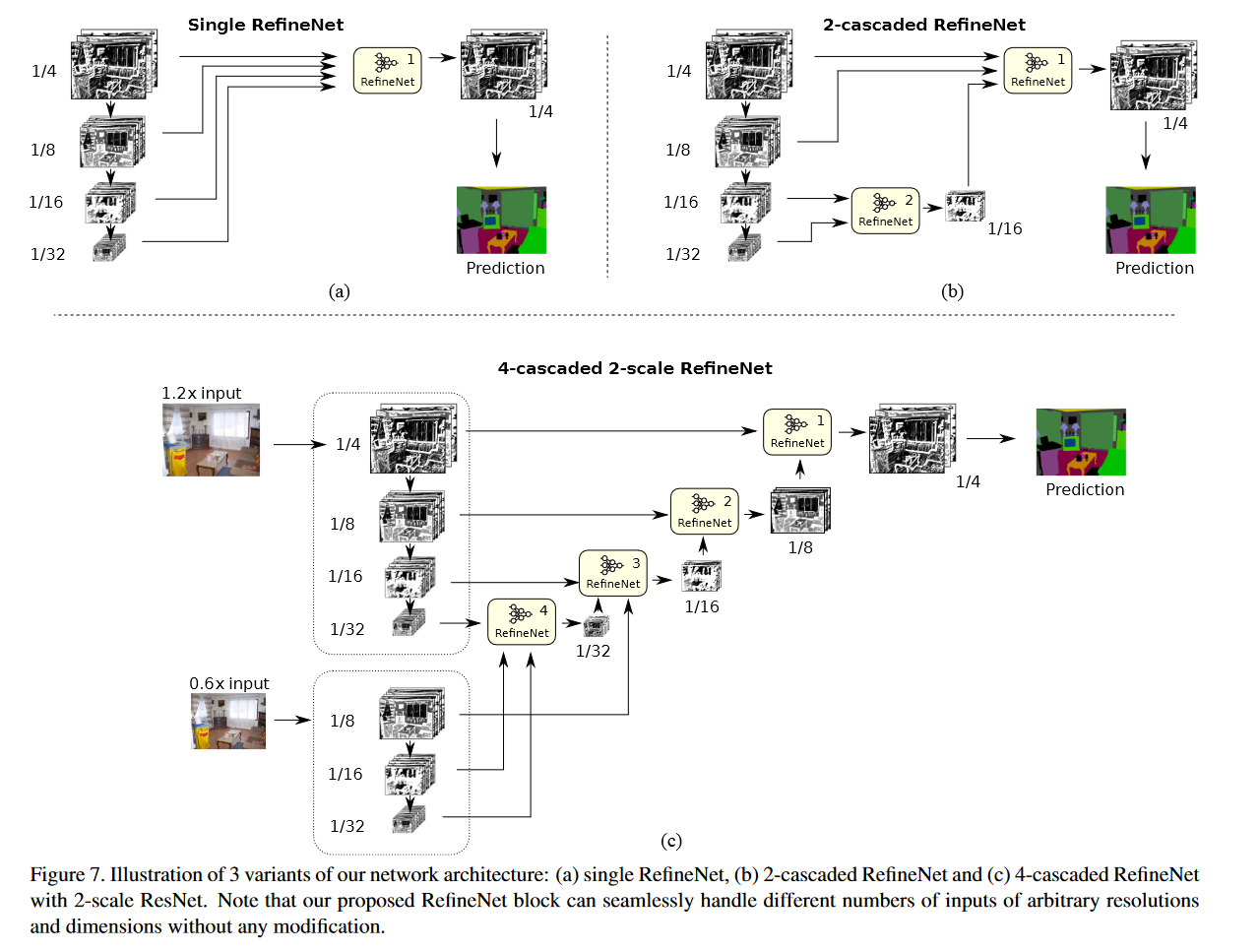
“we present the architectures of using a single RefineNet, a 2-cascaded RefineNet and a 4-cascaded RefineNet with 2-scale ResNet.” (pdf)
局限
- 模型太大了(参数多+保留的特征映射多)
- RefineNet的Multi-resolution fusion先下采样再上采样是不是又损失精度了?
- High-Resolution Segmentation Multi-path Refinement Resolutionhigh-resolution segmentation multi-path refinement high-resolution segmentation注意力deformable high-resolution high-resolution synthesizing consistency resolution cross-refinement super-resolution high-frequency high-resolution resolution improving diffusion multi-path refinement cross-refinement reqirement refinement需求