之前一直在用CPU训练TensorFlow模型,现在来尝试一下GPU训练。
【1】安装GPU必要的软件环境
显卡:MX450(支持CUDA 11.7以下版本)
软件1:Visual Studio 2019 Community
软件3:cuDNN 8.0.5 for win10(x86)
环境:在Anacodna中专门建立tensorflow_gpu环境
Python 3.7.16
cudnn 7.6.5
tensorflow-gpu 2.2.0
keras 2.3.1
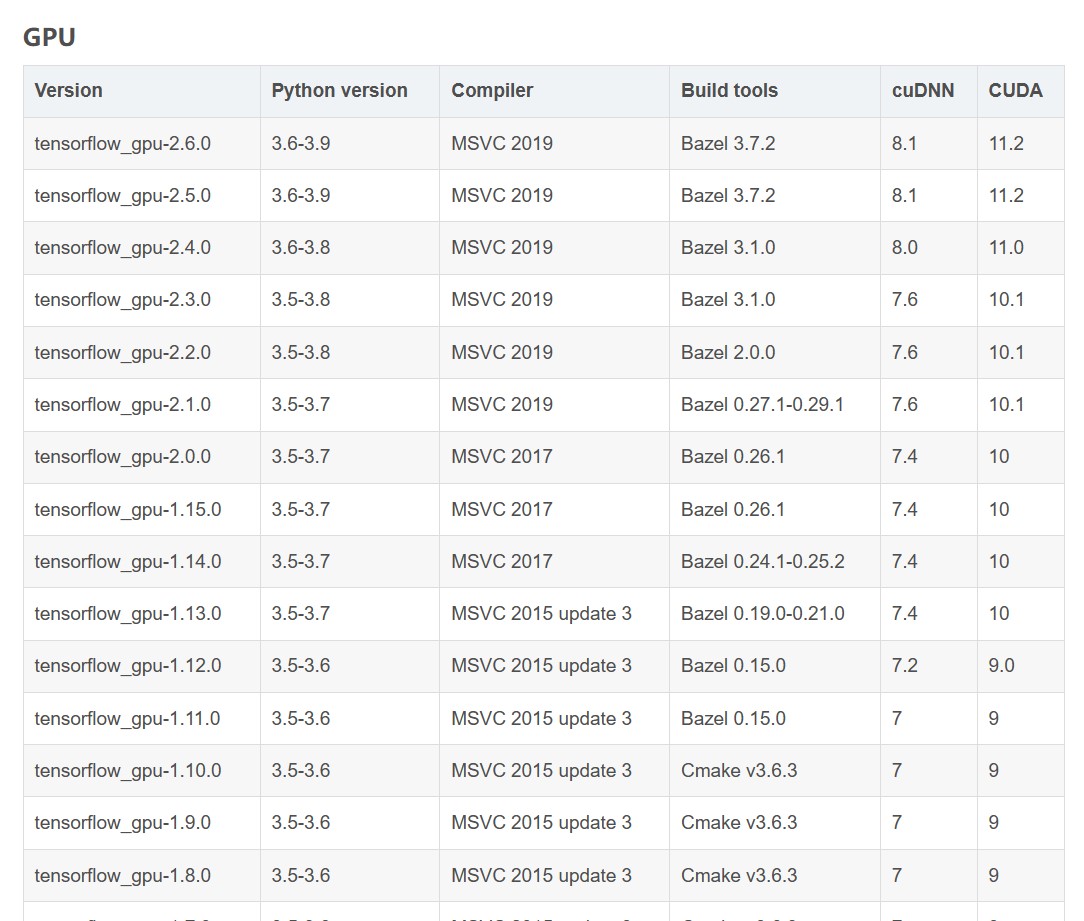
tensorflow-cuda-keras版本对应如下:

参考文章:cuda安装https://blog.csdn.net/chen565884393/article/details/127905428
【2】TensorFlow开启GPU加速
import tensorflow as tf
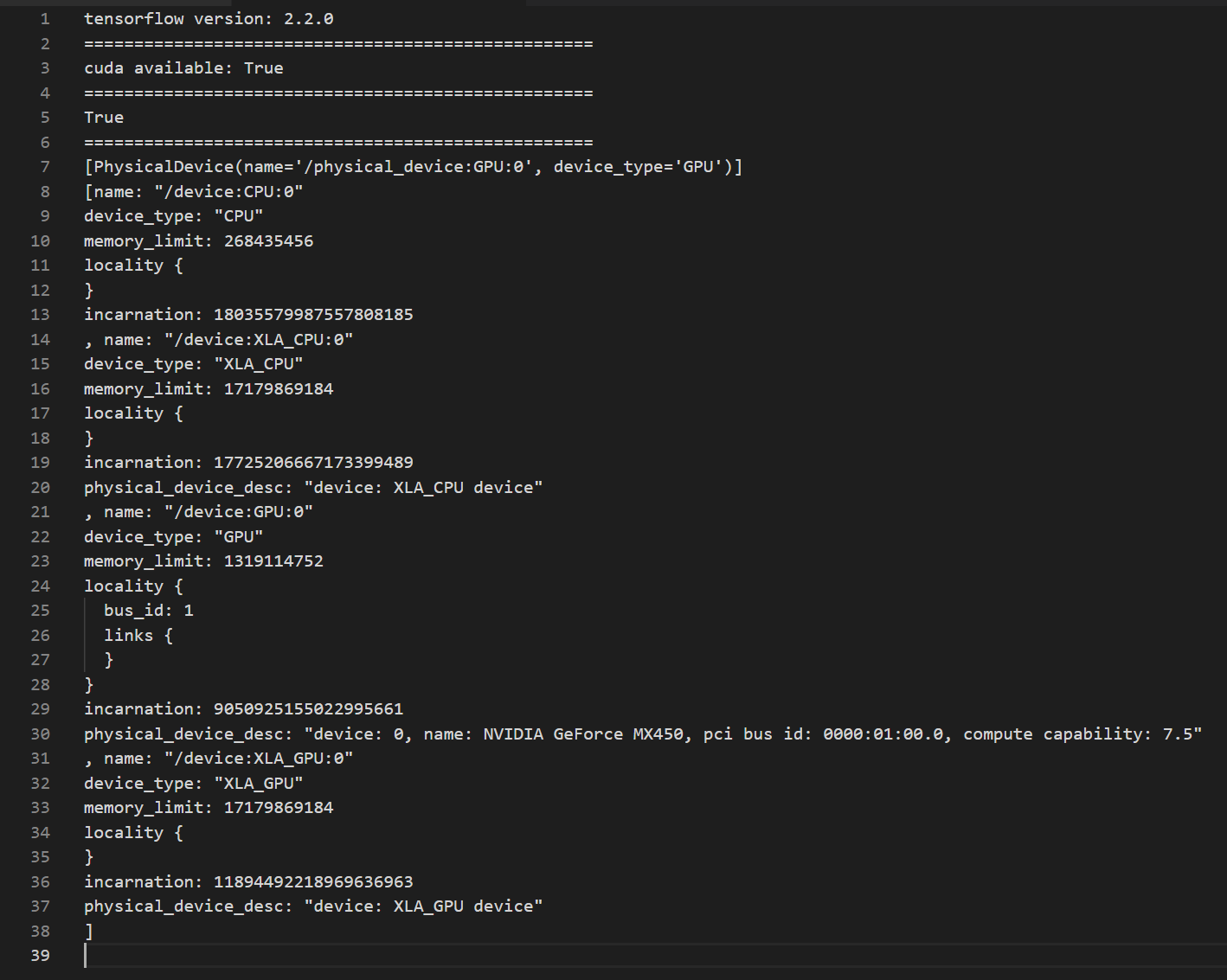
print('tensorflow version:',tf.__version__) # 查看TensorFlow的版本
print('===================================================')
print('cuda available:',tf.test.is_built_with_cuda()) # 判断CUDA是否可用
print('===================================================')
print(tf.test.is_gpu_available()) # 查看cuda、TensorFlow_GPU和cudnn(选择下载,cuda对深度学习的补充)版本是否对应
print('===================================================')
gpus = tf.config.experimental.list_physical_devices(device_type='GPU') # 查看可用GPU
print(gpus)
import os
#选择使用某一块或多块GPU
#os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" # =右边"0,1",代表使用标号为0,和1的GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # =右边"0",代表使用标号为0的GPU
# 查看可用GPU的详细信息
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
# 这时候在运行相应的代码,就可以看到在GPU上运行了。可以通过任务管理器-性能处查看GPU使用率。
【3】用Keras训练一个卷积神经网络
[CPU测试] tensorflow 3.9.16 Keras 2.11.0
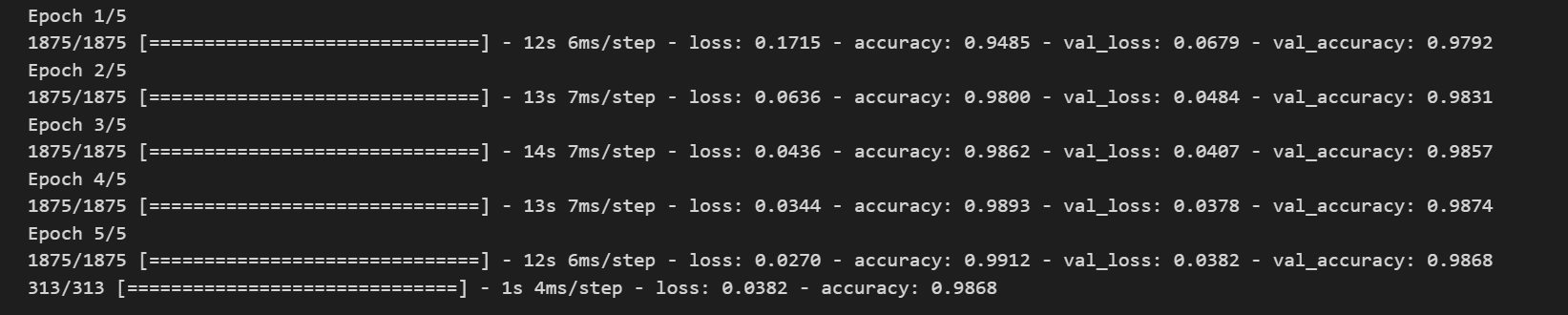
迭代训练5次,每次消耗实践为12s、13s、14s、14s、12s,加上最后一步的1s,总共耗时66s。
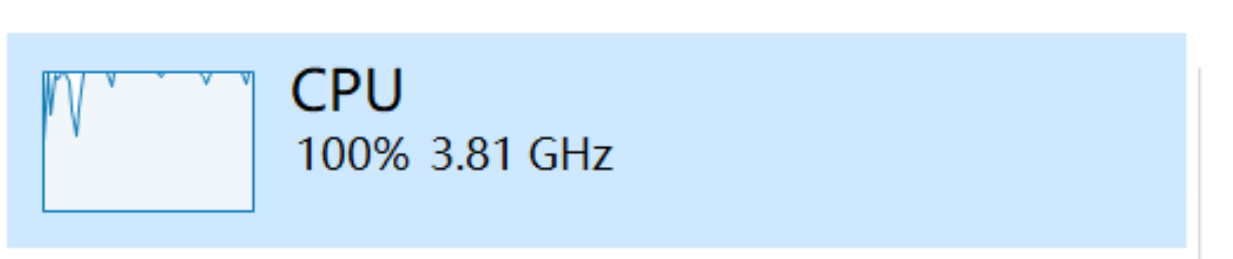
打开任务管理器查看性能:CPU占满100%;用上了一些核显性能(可能是其他设备,不一定是训练消耗的);独显0%完全不用。

[GPU测试]
开始训练,但是报错了
ValueError: Error when checking input: expected input_1 to have 3 dimensions, but got array with shape (60000, 28, 28, 1)
![]()
将输入层维度修改一下,从
![]()
改为
![]()
奇怪的是,使用CPU训练时并不需要修改这里的维度。可能是Keras与TensorFlow的版本与现在不同?
修改后进行训练,结果如下:

迭代训练5次,每次消耗实践为8s、6s、6s、6s、5s,加上最后一步的1s,总共耗时32s,比CPU耗时减少约50%,GPU加速确实成功了。
系统性能如下。可见,CPU占用仅42%;独显使用率一般在7%、8%,有时会突然跳到14%左右;核显虽有使用,但关系应该不大(其他程序占用)。
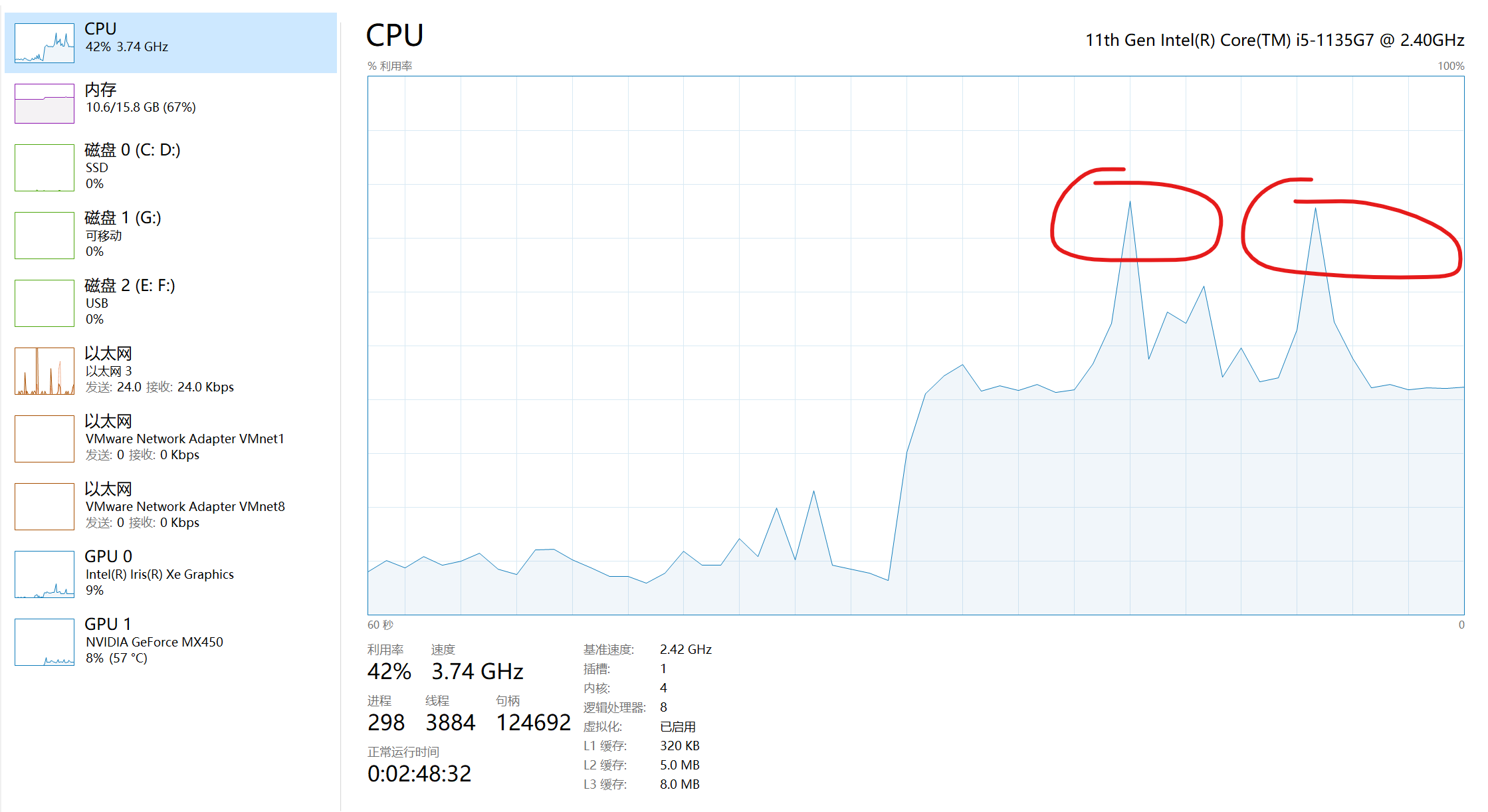
只是用到了如此少的GPU资源,就能获得几乎100%的速度提升,GPU加速还是太强了。可能是我的架构或者代码问题,GPU使用率还是偏低,如果进行相关优化、训练更大的模型,GPU使用率应该是可以更高。