Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning
2023 ICCV
*Siming Yan, Zhenpei Yang, Haoxiang Li, Chen Song, Li Guan, Hao Kang, Gang Hua, Qixing Huang*; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 14530-14542
- paper: [2201.00785] Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning (arxiv.org)
- code: [SimingYan/IAE: ICCV 2023] "Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning" (github.com)
Abstract
总结 :本文专注于autoencoder框架下的点云表示模型的性能优化,提出了sample-variant issue ,即不同采样(采样是因为网络处理体量限制,需要先对数据集中的数据进行降采样)引入的噪声不同,普通的autoencoder点云表示学习方法,例如Point-MAE拟合输入和重建点云保持完全一致,导致采样中的噪声一定程度上也影响到的了encoder输出的latent code,降低了对同一目标的不同点云的语义表示一致性,换句话说: limiting the model's ability to extract valuable information about the true 3D geometry。作者基于这一点提出了对于decoder的优化,decoder原来是重建点云数据,作者换为重建输入点云的隐式表示 (SDF、UDF、occupancy grid),并且原来的Loss函数(Chamfer Distance Loss,Earth Mover`s Distance)替换为:将重建的隐式表示,和输入点云计算得到的隐式表示之间的L1 distance(for SDF,UDF),或者cross entropy(for occupancy grid)。Loss替换还有一个好处在于大大降低了计算复杂度,使得输入点云的点数能够大大增多,论文中表明点数能从1k左右 -> 40k,在tesla V100的GPU加持下?。
Sample Variation Issue
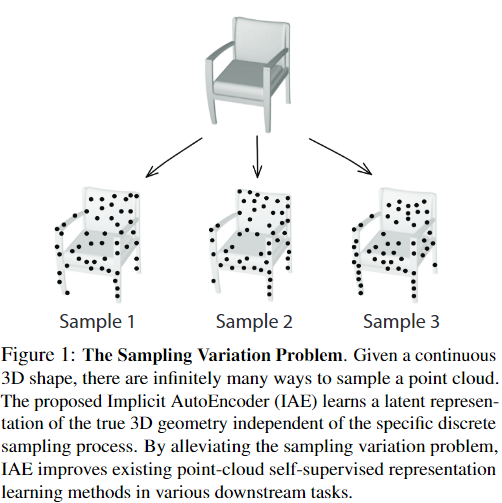
从图中不同的采样在不同位置的点云密度不同,密度大的自然网络容易学习,密度小的网络学习较为困难,但确实原来直接重建点云的方法,使得latent code不得不带有不同sample distinctive的特征描述,本文就意在解决这一问题,促使网络学习到更加generalize的特征)(for one 3D object)。
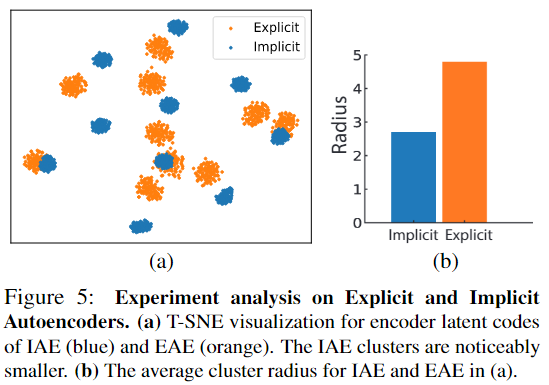
实验中显示了IAE思想的有效性,在分类任务中观察同类样本和非同类样本的特征描述相互之间的距离,可以看到IAE同类样本的聚类半径远小于显示重建点云:
Pipeline
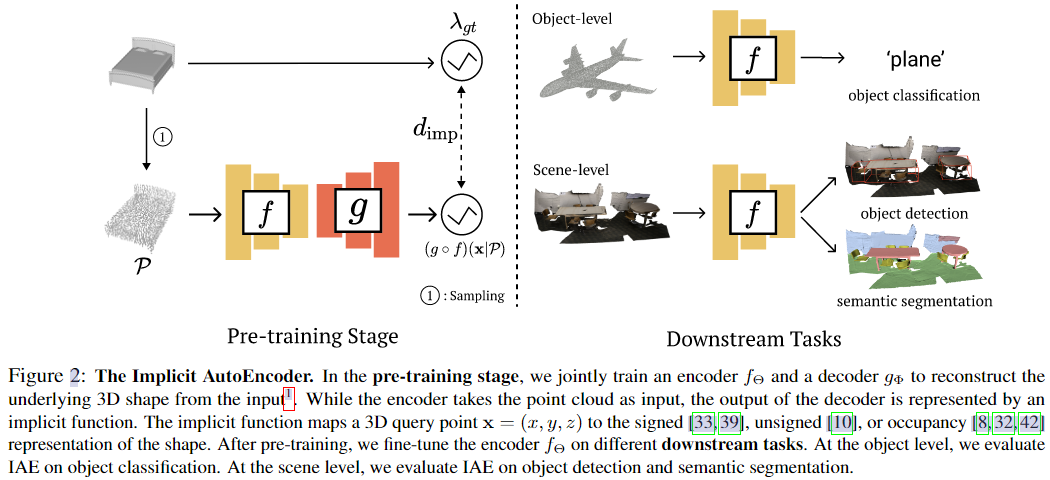
这里主要说的pretrain阶段的decoder的输出,本文主要改进的也是他,这里的 \((g \circ f)(x | \mathcal{P})\) 表示这个autoencoder-decoder架构在 \(\mathcal{P}\) 采样输入样本下的重建出来的隐式表示, \(\lambda_{gt}\) 表示使用ground truth(数据集中的数据)计算出来的隐式表示,例如SDF、UDF、occupancy grid三种:
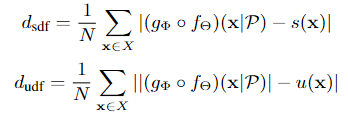
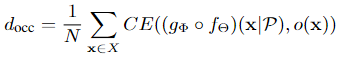
Experiment
看论文就行了,全SOTA,确实有效,并且替换其他encoder,与其他基于其encoder的方法作比较也是SOTA。
在隐式表示是occupancy grid用的decoder:

- Self-Supervised Representation Autoencoder Point-Cloud Supervisedself-supervised representation autoencoder point-cloud self-supervised self-supervised exploration generative supervised self-supervised transformers lightweight supervised self-supervised interpretable adversarial generative self-supervised bidirectional supervised learning self-supervised transformers supervised empirical language-guided self-supervised segmentation self-supervised recommendation session-based self-supervised recommendation convolutional