GLoRA:One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
O、Abstract
本文在 LoRA 的基础上,提出一种广义 LoRA (GLoRA,Generalized LoRA)。与 LoRA 相比,GLoRA 的理论更加通用,它采用一个通用的 prompt 模块,来优化预训练的模型权重。
一、Motivation
| name | formula | theory | weakness |
|---|---|---|---|
| VPT | \([x_1,Z_1,E_1]=L_1([x_0,P,E_0])\\ [x_i,Z_i,E_i]=L_i([x_{i-1},Z_{i-1},E_{i-1}])\) | \(p-tunning\) | 增加了 inference 的成本,prompt的设计困难,增加超参数 |
| AdaptFormer | \(x_l=MLP(LN(x'))+s\cdot \tilde{x}_l+x_l'\\\tilde{x}_l=MLP(LN(x_l')\cdot W_{down})\cdot W_{up}\) | \(bottleneck\ \ adapter\) | 引入推理延迟 |
| LoRA | \(f(x)=W_0x+\Delta Wx+b_0=W_{LoRA}x+b_0\) | 累积更新 \(\Delta W\) 低秩分解 | 未考虑 feature 空间的变化 \(\Delta H\). |
| SSF | \(y=\gamma \cdot x+\beta\) | 对下游任务的 feature 线性变换到上游任务的空间 | 未考虑 weights 空间的变化 \(\Delta W\). |
| RepAdapter | 如下 | 未考虑 weights 空间的变化 \(\Delta W\). |
GLoRA结合上述工作的 weakness,提出想法: \(\Delta H\ tuning\) , \(\Delta W\ tuning\) 以及二者的缩放与偏移的学习。
VPT: 为不同的任务调整提示的数量,这引入了一个与任务相关的可学习参数空间。微调的性能对每个任务的提示数量很敏感,需要仔细设计。太少或太多的提示可能会降低微调的准确性或增加计算的冗余度(例如,在 Clevr/count 上有 200 个提示,但是 Flowers102 上有 1 个提示)。
SSF:上下游数据分布不同,很难将上游任务学习到的权重应用于下游,通过简单的线性变换 \(\gamma \cdot x+\beta\) 使得下游任务的特征能够映射到相对于上游任务的一个鉴别性空间。
RepAdapter:一种较为特殊的 Adapter 设计,第一次提出结构重参数化——舍弃 adapter 中的非线性层不会影响性能,从而可以避免引入推理延迟。通过设计多个 upsample 的矩阵合并为一个稀疏矩阵来减少参数量。
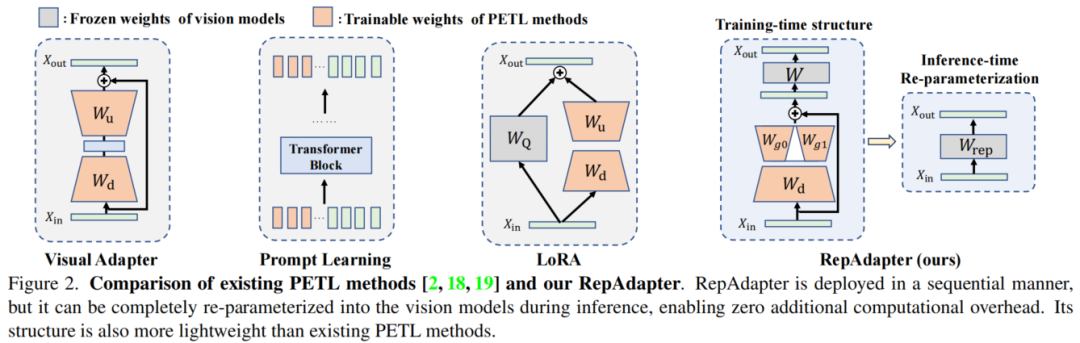
二、GLoRA
1、Formula
- A, B:\(W_0\) 的 scale 矩阵和 shift 矩阵
- C:提供 \(prompt\) 的功能
- D,E:\(b_0\) 的 scale 和 shift 矩阵
其中,各个参数的形式可以有多种模式:
单独为 \(A\sim E\) 设置单独的 adapter 模块,从而参与训练
由于 A-E 是以层为单位的,需要为每一层的 \(A\sim E\) 矩阵都设置一个合适的模式,这个过程通过一个进化算法完成。
我们首先选择 K 个随机结构,并将其中性能最好的 K 个结构作为亲本,通过交叉和突变产生下一代。对于交叉,随机选择两个候选结构并交叉以产生“子”结构。对于突变,以一个概率改变其模块结构。循环这个过程。
2、Re-parameterization
在 inference 阶段中,为了不引入推理延迟,需要实现(结构)重新参数化,在 RepAdapter 中提到,去除 adapter 模块中的非线性层,在参数量较少的情况下不会对网络性能产生不利影响
三、Experiment
NOAH:Adapter,LoRA 和 VPT 集成到12层超网的每个Transformer块中,通过神经架构搜索(NAS)学习最适合数据集的子网结构
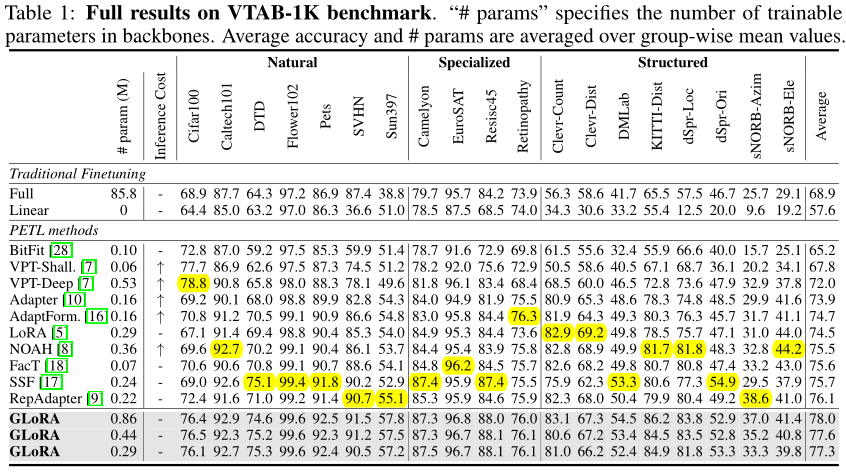
1、VTAB-1K:19 image classification tasks
设置 GLoRA 为三种参数数量,与对照 tuning 算法一同在 VTAB-1K 图像分类数据集上进行测试。三种不同的 GLoRA 的配置区别,只是搜索空间中 LoRA 矩阵的维度,最大模型中的维度为 8 和 4,中间模型维度为 4 和 2,最小模型中的维度为 2.
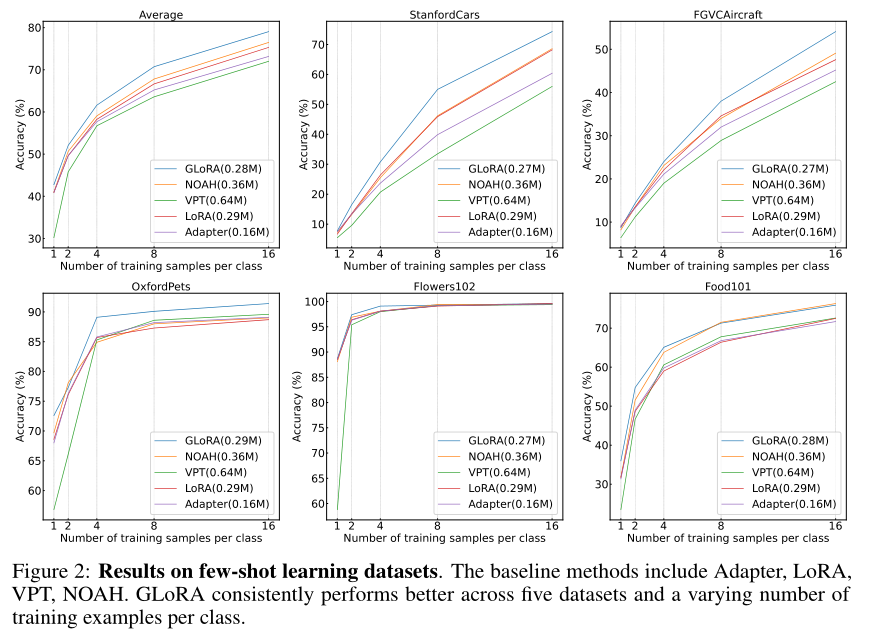
2、few-shot datasets
在五个 few-shot 图像识别数据集上,分别设置样本数为 1,2,4,8 和 16。
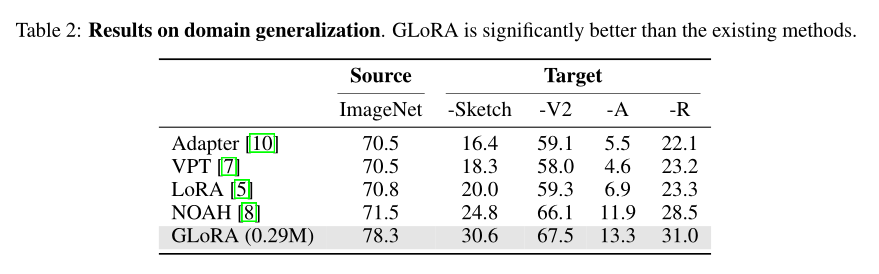
3、Domain Generalization
在 imageet 上将每类训练样本的数量限制为 16 个进行训练,然后在 imageNet-Sketch/-V2/-A/-R 上测试性能。
ImageNet-1K full fine-tuning的性能为83.97%。
4、推理延迟
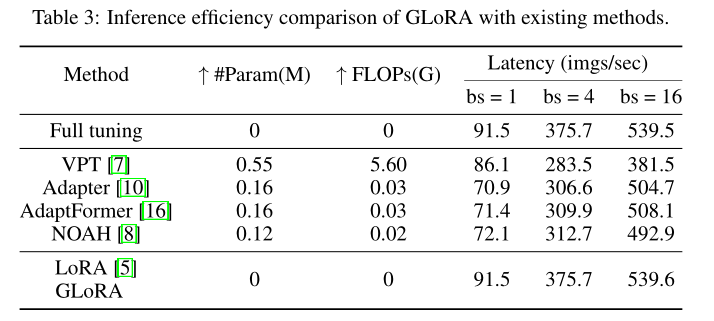
5、参数分配以及各层 \(A\sim E\) 模式配置
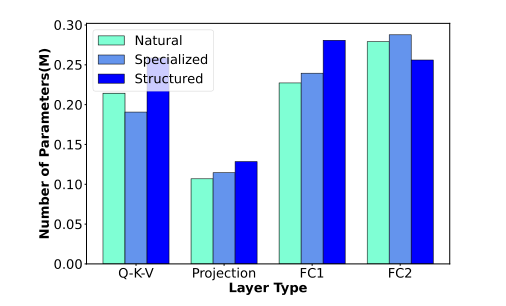
每层的可训练参数是通过各层 \(A\sim E\) 由启发式算法确定了结构之后算得得。投影层 \(W_o\) 的参数最少,而 FC 层参数最多,这说明原模型对 \(ImageNet-1K\) 数据集有明显得域偏移,需要更多参数来适应。
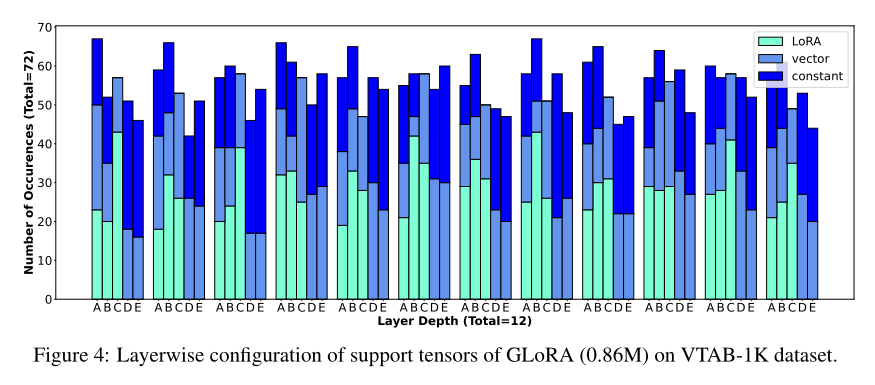
A 和 B 表现出更多的适应,而 C 和 E 表现出更少数的适应。可以看出,不少的矩阵模式被设置为 constant。
四、conclusion
1、advantages
-
它同时考虑了多个维度,以增强微调期间的能力和灵活性,包括权重、特征和 prompt。
-
我们的结果直接来自超级网络的模型权重,而不需要额外的训练。因为与NOAH和PFT相比,在对理想子网或配置进行进化搜索过程之后,不需要重新训练子网。(虽然 NOAH 论文提到训不训练效果相近,如下)

-
它进行隐式搜索,不需要任何手动超参数调优,从而证明增加的训练时间是合理的。
-
结构重参数化,不会产生额外的推理延迟
2、limitation
- 进化搜索超参数的过程,过于耗时,虽然这十分合理(不需要手动调优超参数)
- 本文没有对 GLoRA 在 CV 和 NLP 领域进行下游任务研究
- 本文没有涉及 GLoRA 对 CNN 的适应。
- Parameter-Efficient Fine-tuning One-for-All Generalized Efficientparameter-efficient fine-tuning one-for-all parameter-efficient one-for-all generalized iccv_generalized iccv_generalized normalization generalized adaptation generalized distributed detection qualified co-alignment generalized adaptation alignment fine-tuning fine-tuning openai tuning model