前言
VictoriaMetrics是一个快速、高效和可扩展的时序数据库,可作为Prometheus的长期存储。查询promsql,使用grafana看图时,可以直接用VictoriaMetrics源替换掉prometheus源。
架构
这里介绍集群版本的架构:
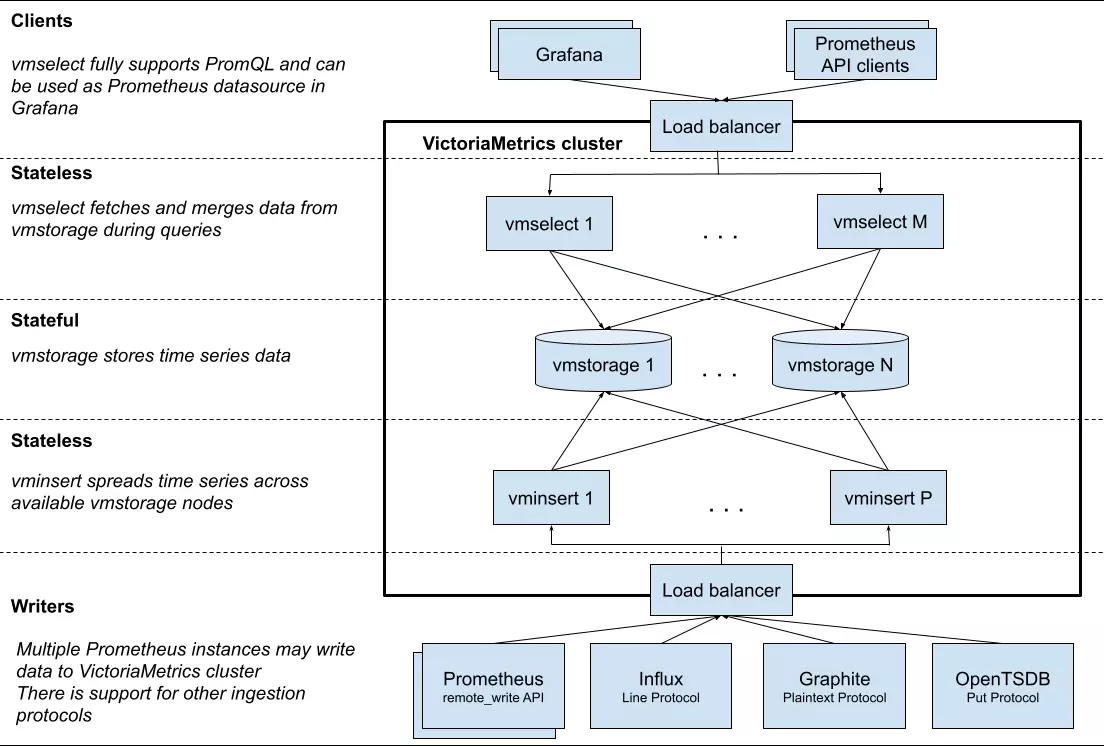
主要有3个模块:
- vmstorage: 数据存储节点,负责存储时序数据;
- vmselect: 数据查询节点,负责接收用户查询请求,向vmstorage查询时序数据;
- vminsert: 数据插入节点,负责接收用户插入请求,向vmstorage写入时序数据;
数据复制
为了保证集群的高可用,说白了就是保证数据的高可用,常用的方法无外乎两种,第一种是写入时同时写入多个节点,第二种是存储节点之间自动进行数据的同步,比如etcd使用raft协议来进行数据同步,mysql使用binlog来进行数据同步。
VictoriaMetrics采用第一种方式,vminsert模块支持参数-replicationFactor=N,其中N表示的是同步的节点数,如当N=3时,vminsert在收到写入请求后,通过一致性哈希计算需要将数据发送到4号节点,同时也会发送到6号和7号节点,代码如下:
// https://github.com/VictoriaMetrics/VictoriaMetrics/tree/cluster/app/vminsert/netstorage/netstorage.go
func sendBufToReplicasNonblocking(br *bufRows, snIdx, replicas int) bool {
usedStorageNodes := make(map[*storageNode]bool, replicas)
for i := 0; i < replicas; i++ { //多个副本,发送至多个storageNode
idx := snIdx + i
attempts := 0
for {
attempts++
if attempts > len(storageNodes) { //已尝试了所有节点
if i == 0 {
return false //第一个副本就失败了,返回false
}
return true
}
sn := storageNodes[idx]
idx++
//发送
if !sn.sendBufRowsNonblocking(br) {
continue //若失败,则尝试下一个节点idx++
}
break //成功就返回
}
}
return true
}
基于此特点,集群最多有N-1个节点不可用,也可以理解为至少有node个数-N+1个节点可用,那node个数定为多少个合适呢?
官方给出的建议是至少有2*N-1个,参考文档,这样能保证数据分散的更均匀,且不会有太多的资源消耗。
查询
查询期间可能有些节点会发生故障,因此vmselect会根据查询结果来判断数据的一致性,代码如下:
// https://github.com/VictoriaMetrics/VictoriaMetrics/tree/cluster/app/vmselect/netstorage/netstorage.go
func (snr *storageNodesRequest) collectResults(partialResultsCounter *metrics.Counter, f func(result interface{}) error) (bool, error) {
var errors []error
resultsCollected := 0
for i := 0; i < len(storageNodes); i++ {
result := <-snr.resultsCh //返回结果
if err := f(result); err != nil {
errors = append(errors, err)
continue
}
resultsCollected++
// 判定为数据完整且没有错误,直接返回
if resultsCollected > len(storageNodes)-*replicationFactor {
return false, nil
}
}
isPartial := false
if len(errors) > 0 {
// 所有结果都出错了,返回第一个错误
if len(errors) == len(storageNodes) {
return false, errors[0]
}
isPartial = true
}
return isPartial, nil
}
最终结果的判断原则:
- 最完美的情况:
所有节点都正常返回且没有错误,则认为结果是完整且没有错误的: - 若正常返回的结果 > len(storageNode) - replicaFactor,即至少有
node个数-N+1个节点可用:
则被判定为数据完整且没有错误,直接返回; - 若所有节点都出错了:
则认为结果是错误的,并返回第1个错误 - 若部分节点返回错误:
则认为结果是不完整的:
- VictoriaMetricsvictoriametrics项目 relabel configs metric_relabel_configs victoriametrics victoriametrics force merge victoriametrics prometheus victoriametrics原理 技术tsdb victoriametrics变量 局部 做法 denypartialresponse victoriametrics vmselect victoriametrics实战 大规模 victoriametrics victorialogs 单机版victoriametrics prometheus单机