在异构联邦学习中博采众长做自己
代码:https://paperswithcode.com/paper/learn-from-others-and-be-yourself-in
摘要
联邦学习中有异质性问题和灾难性遗忘。首先,由于非I.I.D(相同独立分布)数据和异构体系结构,模型在其他领域的性能下降,并且与参与者模型之间存在通信障碍。其次,在局部更新时,模型对私有数据单独进行优化,这容易过度拟合当前数据分布并遗忘先前获取的知识,导致灾难性遗忘。在这项论文中,我们提出了FCCL(联邦互相关和连续学习)。对于异质性问题,FCCL利用未标记的公共数据进行通信,并构造交叉相关矩阵来学习域移位下的可推广表示。同时,对于灾难性遗忘,FCCL利用知识提取进行局部更新,在不泄露隐私的前提下提供域内和域间信息。在各种图像分类任务上的实验结果证明了该方法的有效性和模块的效率。
介绍
联邦学习的异质性问题:
- 数据非iiD,导致数据异构。许多方法都在标签分布中加入了额外的近端项来处理数据,而忽略了存在域偏移(相同标签,不同特征)的事实。
- 模型异质性,参与者需要定制模型。
解决这一问题的主流方案是标记数据、共享模型或群体操作来利用知识转移。但这些方法有不同的局限性。具体来说,带标签的数据需要服务器收集与私有数据分布相似的数据,这将导致昂贵的人工论文,并需要特殊的领域专业知识。对于共享模型,增加了计算量,需要在参与者方增加模型结构。组操作利用未标记的公共数据来衡量分布差异。然而,这些方法主要关注标签分布偏度,并考虑单个域上的性能。
在考虑数据和模型的异构性的同时,一个重要的问题一直被忽视:(a)如何在异构联邦学习中学习可泛化表示?
联邦学习的另一个问题来自其范式,它可以被看作是一个两步循环的过程:协同更新和局部更新。 在协作更新中,参与者向他人学习。 在局部更新中,模型是在私有数据上优化的,容易过度拟合当前知识而忘记以前的知识,导致灾难性遗忘。目前流行的解决方案主要是通过计算参数刚度来调整模型,不能明确地描述不同参与者对模型的影响程度。 因此,一个自然的问题出现了:(b)如何平衡多种知识以减少灾难性遗忘?

(a)在协同更新中,如何处理异构模型的通信问题,学习异构数据下的可泛化表示(域移位)?
(b)在局部更新中,如何减轻灾难性的遗忘,表现出稳定和满意的性能?
对于异构问题,利用未标记的公共数据进行联邦互相关学习,试图最大化Logits输出之间的相似性,并在未标记的公共数据上最小化Logits输出中的冗余。 通过对\(logits\)输出的同维关联和异维去关联,模型可以学习类的不变性,鼓励不同类的多样性。
这项论文提出了一种新的联邦学习方法,称为FCCL(联邦互相关和连续学习):
- 提出了一种的异构联邦学习方法。利用未标记的公共数据,采用自监督学习,异构模型实现了通信并学习了可推广的表示。
- 在联邦学习中减轻灾难性遗忘。通过更新和预先训练的模型对领域内和领域间的知识进行提炼,平衡来自他人和自身的知识。
- 在两个图像分类任务上(例如数字和OfficeHome)进行实验,这些任务带有未标记的公共数据。
相关论文
数据异构性联邦
FEDAVG在非I.I.D数据(数据异构)下性能会下降。对非I.I.D.数据进行的研究主要集中在标签分布偏斜上,通过基于有限域移位的标签空间对现有数据进行分区。 然而,当私有数据从不同的数据域中采样时,先前的论文没有考虑域间的性能,而只关注于学习一个内部模型。 最新的研究已经对目标域的无监督域自适应和未见域的域泛化等相关问题进行了研究。 然而,在目标域中收集数据耗时大且不切实际。现实情况下的参与者可能更感兴趣的是在其他领域的表现。因此本文着重研究在域移位下域间性能的提高。
模型异构性联邦
FEDMD,CRONUS和CFD通过知识蒸馏对标记的公共数据(分布相似)进行操作。这些方法严重依赖于标记数据的质量。最近的论文(如Feddf,Fedkt和Fedgen)证明了对未标记数据或合成数据进行蒸馏的可行性,然而利用未标记的公共数据,通过各种度量指标来达到语义信息的一致性,会导致域间性能较差。 另一个方向是引入共享额外模型,如FML和LGFEDAVG,会增加额外的计算开销和昂贵的通信成本。
自监督学习
自监督学习极大地缩小了监督模型在各种下游视觉任务上的性能差距。 许多相关的方法依赖于对比学习(例如,SIMCLR,MOCO),它将正对与负对进行对比,并使正对之间的差异最小化,以避免折叠解。 最近,另一个研究领域(如Byol,Simsiam)采用学习更新的非对称性(停止梯度操作)来避免简单的解。 此外,一些方法(如W-MSE,BarlowTwins)基于Cholesky分解和信息瓶颈研究了特征解相关的可能性。 有几个研究将联邦学习与自监督学习结合起来(例如,Furl,Moon)。 它们分别针对模型同质性下的无监督学习设置和标签分布偏斜问题进行了研究。 FCCL与上述自监督学习方法的主要区别在于,我们的自监督学习方法是为联邦设置而设计。受自监督学习的启发,FCCL构建了联邦学习中不同模型之间的比较。
灾难性的遗忘
灾难性遗忘的挑战在于每个任务的类分布不断变化。现有的关于应对灾难遗忘的持续学习论文可以大致分为三个分支:重放方法、基于正则化的方法和参数隔离方法。对于联邦学习,数据是分布式的,而不是像连续学习那样的顺序学习。但除了这些差异之外,持续学习和联邦学习都面临一个共同的挑战——如何平衡来自不同数据分布的知识。与持续学习方法不同,我们关注的是如何减轻分布式数据中的灾难性遗忘,而不是时间序列数据来平衡和提高域内和域内的性能。
方法
问题设置和符号。 按照标准的联邦学习设置,共有\(K\)个参与者(以\(i\)为索引)。每个参与者都有一个局部模型\(θ_i\)和私有数据\(D_i = \{(X_i,Y_i)|X_i \in \mathbb{R}^{N_i×D},Y_i \in \mathbb{R}^{N_i×C}\}\),其中\(N_i\)表示私有数据的数量,\(D\)表示输入大小,\(C\)定义为分类的类数。私有数据分布记为\(P_i(X,Y)\),可改写为\(P_i(X|Y)P_i(Y)\)。此外,在异构联邦学习中,数据异构和模型异构的定义如下:
-
数据异构:\(P_i(X|Y) \neq P_j(X|Y)\)。私有数据之间存在域转移,即共享\(P(Y)\),私有数据的条件分布\(P(X|Y)\)也会因参与者的不同而不同,即相同的标签\(Y\)在不同的域中具有不同的特征\(X\)。
-
模型异构:\(Shape(θ_i) \neq Shape(θ_j)\)。参与者独立自定义模型,即对于分类任务,所选择的骨干(如ResNet、EfficientNet和MobileNet)与差分分类器模型不同。
利用未标记的公共数据\(D_0 = \{X_0|X_0 \in \mathbb{R}^{N_0×D}\}\)实现通信。在真实场景中,公共数据相对容易获取。第\(i\)个参与者的目标是实现通信并学习可泛化表示的模型\(θ_i\)。考虑到遗忘问题,\(θ_k\)需要具有更高、更稳定的畴间和畴内性能。
框架概述。 如图2所示。在协同更新中,度量未标记公共数据的logit输出之间的互相关矩阵,以获得相似度和减少冗余。同时,在局部更新中,通过知识蒸馏不断平衡多领域信息。

(a)通过联邦互相关学习和联邦持续学习,简化了解决异质性问题和灾难性遗忘的方法。
(b)联邦互相关§3.1:构造互相关矩阵$M_i$到目标矩阵,$M_T =2×eye(C)−ones(C)$,主对角线上元素为1,非对角线为−1。
(c)联邦持续§3.2:通过更新和预先训练的模型进行蒸馏,可以在不泄露隐私的情况下提供领域间和领域内的知识。
渐变色比例反映了其他参与者的影响程度。
联邦互相关学习
维级操作的动机。 由于不同领域中存在相同标签Y但是特征X不同。因此,\(logits\)输出在不同领域上沿着批次维度的分布是不相同的。因此,需要鼓励相同维度的不变性和不同维度的多样性。私有数据承载着特定领域的信息,处于隐私保护之下,不适合也不可行进行自监督学习,因此,我们利用未标记的公共数据,通过要求\(logits\)输出不变性域失真和去相关的不同维度的\(logits\),输出未标记的公共数据优化私人模型。
互相关矩阵的构造。 具体来说,得到第\(i\)个参与者的\(logits\)输出:\(Z_i = f(θ_i,X_0) \in \mathbb{R}^{N_0×C}\)。对于第\(i\)个和第\(j\)个参与者,未标记公共数据上的\(logits\)输出为\(Z_i\)和\(Z_j\)。考虑到服务器端的计算负担,平均\(logits\)输出:\(\overline{Z} = \frac{1}{K} \sum_i Z_i\)。然后,计算第\(i\)个参与者的互相关矩阵\(\mathcal{M}_i\),其中平均\(logits\)输出为:
-
\(b\):批样本
-
\(u、v\):\(logits\)输出的维度
-
\(||·||\):沿着批处理维度的归一化操作
-
\(\mathcal{M}_i\):维度的大小为\(C\)的矩阵,其值在-1(即,相异性)和1(即,相似性)之间。
第\(i\)个参与者的对比损失定义为:
- \(λ_{Col}\):权衡第一和第二损失项重要性的正常数。当互相关矩阵的对角项取值+1时,它鼓励来自不同参与者的\(logits\)输出是相似的,当互相关矩阵的非对角项取值-1时,由于这些\(logits\)输出的不同维度将彼此不相关,因此它促进了\(logits\)输出的多样性。
与类似方法的比较。 FedMD依赖于最小化注释数据的均方误差。FedDF在未标记的公共数据上达到\(logits\)输出分布一致性。本文希望在未标记的公共数据上实现相同维度的相关性,但不同维度的去相关性。此外,沿着批次维度进行操作意味着将未标记的公共数据视为整体而不是单个样本。这有利于消除异常样本干扰。
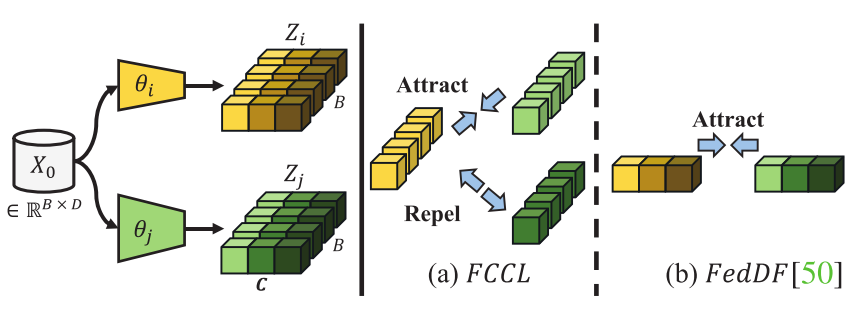
具有批量大小B和输入大小D的未标记公共数据$X_0$被馈送到不同的模型中。$logits$输出具有C维度。
(a)FCCL:学习相同维度中的不变性,并对等式中的分批归一化$logits$输出的不同维度对进行去相关。
(b)FedDF:计算分布散度,其中在批次内比较实例归一化$logits$输出。
联邦持续学习
典型的监督缺失。 对于联邦学习中的局部更新,当前方法通常将此过程视为监督分类问题。在第\(t\)个通信轮,在协作更新之后,第\(i\)个私有模型被定义为\(\theta_i^{t,{im}}\)。针对固定时期,在私有数据\(D_i(X_i,Y_i)\)上优化\(\theta_i^{t,{im}}\)。给定私有数据\(X_i\)相对于其基础真值标签\(Y_i\)的\(logits\)输出\(Z_{i,{put}}^{t,{im}}=f(\theta^{t,{im}}_i,X_i)\),使用\(softmax\)优化交叉熵损失:
- \(1_{Y_i}\)表示\(Y_i\)的独热编码
- \(softmax(Z_{i,{pvt}}^{t,{im}})= \frac{{exp}(Z_{i,{pvt}}^{t,{im}})}{\sum^C_{c'=1}exp(Z_{i,{pvt}}^{t,{im},c'})}\)。
这种训练目标设计将遭受灾难性遗忘:
-
在局部更新中,没有来自其他参与者的监督的情况下,模型容易过拟合当前数据分布并且呈现差的域间性能。
-
仅利用先验概率独立地惩罚预测,这提供了有限且硬的帧内域信息。
\(\sigma\)表示softmax函数。如下公式的目的是在保护隐私的同时不断地向其他人学习,以保证域间性能并处理联邦学习中的灾难性遗忘。此外,对于第\(i\)个参与者,可以在私有数据上预训练模型\(\theta^*_i\)。我们在私有数据上测量\(logits\)输出:\(Z^*_{i,pvt}=f(\theta^*_i,X_i)\),域内知识蒸馏损失如下所示:
使用预训练模型的知识蒸馏提供丰富的域内信息。上述两种模型(更新模型\(θ^{t−1}_i\)和预训练模型\(θ^*_i\))分别表示帧间和帧内“教师”模型。通过知识蒸馏,平衡来自他人和自身的知识同时提高域间和域内性能。双域知识蒸馏计算如下:
式(3)中的典型监督损失与式(6)中的双域知识精馏损失是互补的。前者要求模型学习对分类任务有意义的区别表示,而后者帮助正则化模型,在域内和域间都具有软而丰富的信息。因此,总体训练目标为:
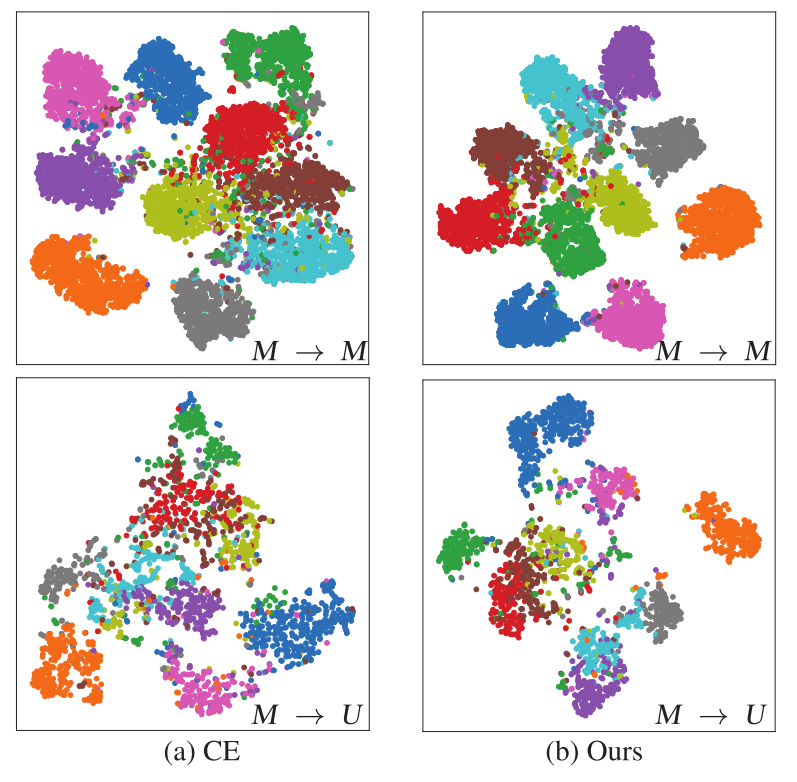
- \(\lambda_{Loc}>0\)是系数。如图4所示,通过享受典型监督损失和双域知识蒸馏损失的优势,\(\mathcal{L}^{Dual}_i\)学习的特征在域内和域间都更加紧凑和分离,模型显示出更好的判别特征,产生了有前途的域内和域间性能。
讨论和限制

FCCL算法适用于大规模的联邦学习,服务器端的计算复杂度为\(O(K)\)。此外,联邦互相关学习对\(logit\)输出进行操作,而不考虑具体的模型结构。因此,当参与者具有相同的模型结构时,FCCL仍然具有效力。假设分布式数据之间不存在数据异构性,公式(1)中\(L^{Col}_i\)的第一项将接近于零,但第二项在\(logit\)输出上仍将不同维数解离。在此基础上,FCCL是模型不可知的方法,能够处理不同程度的域转移。然而,我们也注意到任务一致性要求的局限性。对于多任务设置,logits输出可能不仅有不同的维度,而且对相同的维度包含不同的含义。
实验
数据和模型。 我们用三个公共数据(如CIFAR-100、ImageNet和Fashion-MNIST)对两个分类任务(如Digits和Office-Home)进行评估。 具体来说,Digits任务包括四个域(即MNIST(M)、USPS(U)、SVHN(SV)和SYN(SY))共10个类别。 Office-Home任务也有四个域(即艺术(A)、剪贴画(C)、产品(P)和真实世界(R))。 请注意,对于这两个任务,从不同域获取的数据都存在域移位(数据异构)。
对于这两个分类任务,参与者定制的模型可以不同于区分的主干和分类器(模型异构)。我们将这四个领域的模型分别设置为ResNet、EfficientNet、MobileNet和GoogleNet。
比较方法。 我们将FCCL与包括FEDDF、FML、FEDMD、RCFL和FEDMatch在内的最先进的方法进行了比较。 我们还比较了Solo,在Solo中,参与者在没有联邦学习的情况下在私有数据上训练模型。 由于具体的实验设置并不完全一致,我们保留方法的关键特征进行比较。
评价指标。 精确度,定义为配对的样本数除以样本数。具体来说,对于评估域内和域间性能,我们定义如下:
对于方法的整体性能评价,我们采用了平均精度作为衡量指标。 此外,对于这两个分类任务,Digits和Office-Home分别包含10个和65个类别。 这两个任务分别采用Top-1和Top-5精度。
实施细节。 在联邦学习过程中,所有参与者都采用相同的超参数设置。 模型使用ADAM优化器进行训练,批量大小为512,所有方法的协同更新和局部更新学习率为0.001。 在数据规模方面,在Digits任务中,MNIST、USPS、SVHN和SYN被分配给四个参与者。相应私有数据的大小分别设置为150、80、5000和1800。 对于OfficeHome任务,每个参与者分别被分配了艺术、剪贴画、产品和真实世界,相应的私有数据大小为1400、2000、2500、2000。 对于这两个任务,未标记的公共数据的数量为5000。为了预处理,将所有输入图像调整为32×32的三通道,以实现兼容性。我们在t=40轮的情况下进行通信,所有的方法在更多的通信轮中几乎没有或根本没有精度增益。另外,对于SOLO模型,在私有数据上进行了50个周期的训练,这也是联邦学习过程的初始模型。
与最新方法的比较
我们用三个公开数据(CIFAR-100、ImageNet和Fashion-MNIST)对两个图像分类任务(即数字图像和Office-Home图像)进行了比较,并给出了比较结果。
域间分析。 我们在表1中展现域间性能。在域间转移下,Solo在这两个任务中表现最差。观察到FCCL明显优于其他。 图5表明FCCL实现了参与者之间相似的logits输出和logits输出中的冗余,证实了FCCL在公共数据和私有数据上成功地实现了相同维度的相关性和不同维度的去相关性。
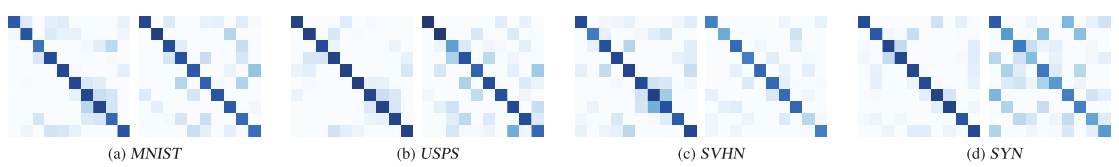
我们分别对公共数据(左)和私有数据(右)与其他模型的互相关矩阵(方程(1))进行了可视化。
每个子图中的左、右图分别表示在公开数据(即CIFAR-100)和私有数据上与其他模型的互相关矩阵。
矩阵为10×10。 颜色越深,$\mathcal{M}_i^{uv}$(等式(1))越接近1。
域内分析。 为了比较缓解灾难性遗忘的有效性,我们在TAB中给出了域内性能。 2. 以CIFAR-100的Digits任务为例,该方法比RCFL强2.30%。 此外,在图中,通过增加通信轮数来提高域内精度 6A与图优化目标值 6b表明FCCL受到的周期性性能冲击较小,不容易对当前数据分布过度拟合(L loc=0.0225),说明FCCL是平衡多种知识的电缆,缓解了灾难性遗忘。
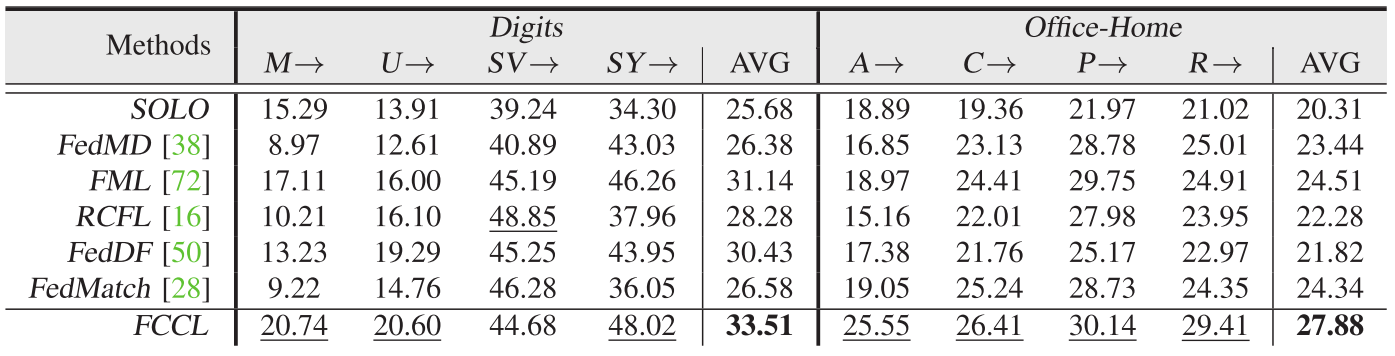
M→:表示私有数据是MNIST,并且在EQ中的其他域上对各自的模型进行测试
AVG:表示从每个域计算的平均精度
(粗体:最好的平均准确度。下划线:每个领域的最佳条目。)
模型同质性分析。 在模型均匀性下,我们进一步将FCCL与其他方法进行了比较。 我们将共享模型设置为Resnet-18,并在协同更新和局部更新之间增加了平均参数操作。 标签。 3展示了CIFAR-100在Office-Home任务中域间和域内的性能。
- Heterogeneous Federated Learning Yourself Othersheterogeneous federated learning yourself recommendation heterogeneous preference learning federated learning 005 healthcare federated learning会议 yourself others programming yourself teach years building_something_for_others_whi heterogeneous others lvs