**
摘要
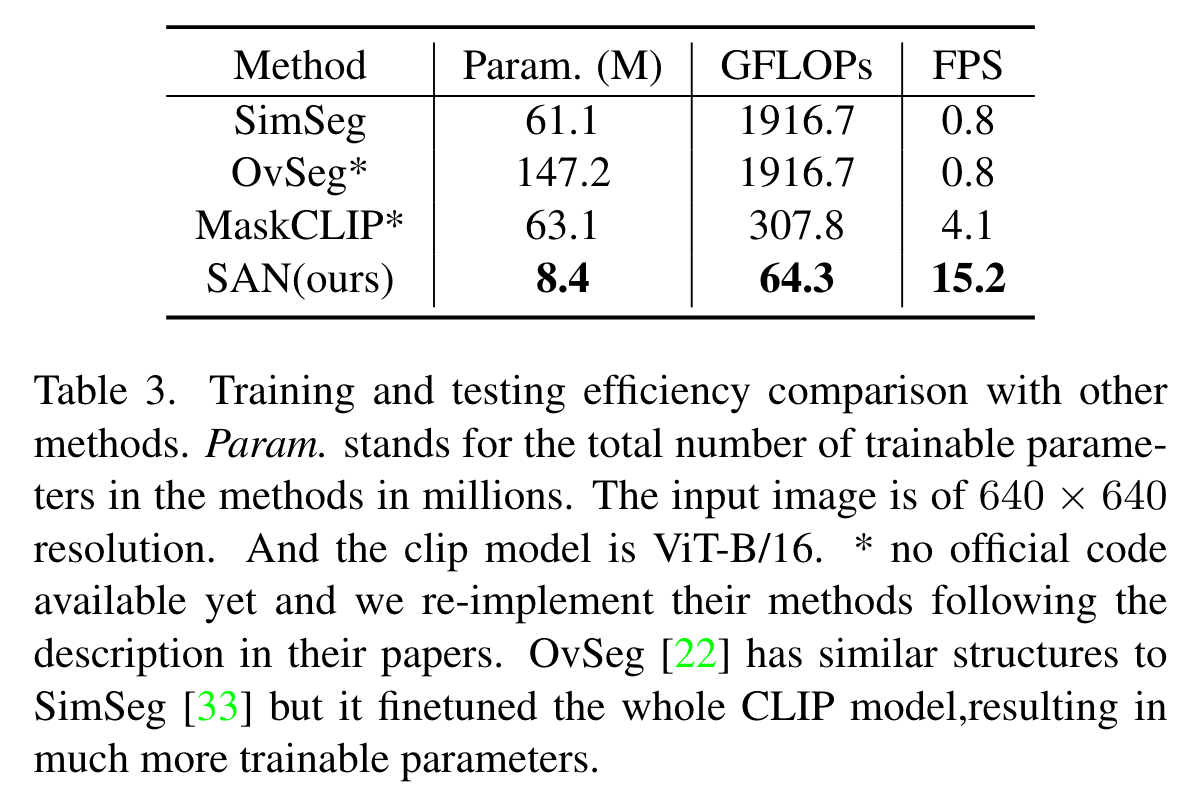
本文提出了一个用于开放词汇语义分割的新框架SAN,将语义分割任务建模为区域识别问题,提取mask proposals并使用CLIP对mask进行识别。SAN可以重新利用CLIP的特征,因此其本身可以非常轻量;同时网络可以端到端地进行训练,从而使SAN适应冻结的CLIP模型。本文方法需要很少的参数量,且速度非常快,能够达到每秒15帧的速度。
引言
CLIP可以在图像级别做到开放词汇图像分类,但用其进行语义分割难度较大,因为CLIP本身是在图像级别进行对比学习的,缺少像素级别的辨别能力。目前有如下几种解决方案:
1.在分割数据集上微调。这样做分割数据集较小,会导致模型失去泛化性(如LSeg等方法)。
2.首先训练一个单独的模型生成mask propusals,之后使用CLIP对根据mask裁剪得到的局部图片进行识别。然而,生成mask的模型完全独立于CLIP,生成的mask可能不适合识别,而且会带来较大的计算开销(如Decoupling Zero-Shot Semantic Segmentation,OPEN-VOCABULARY SEMANTIC SEGMENTATION WITH MASK-ADAPTED CLIP等)。
为此,作者充分挖掘CLIP的潜力,提出了side adapter network (SAN),通过端到端的训练使mask预测、识别等操作与CLIP更好的适应。为了减少计算开销,作者将CLIP浅层block的特征送入SAN进行融合,深层block将结合attention biases识别mask。作者特别提到,CLIP使用\(224\times 224\)大小的图像进行训练的,而分割图像的尺寸一般比较大,因此训练时作者将低分辨率的图像送入CLIP,高分辨率的图像送入SAN。
方法
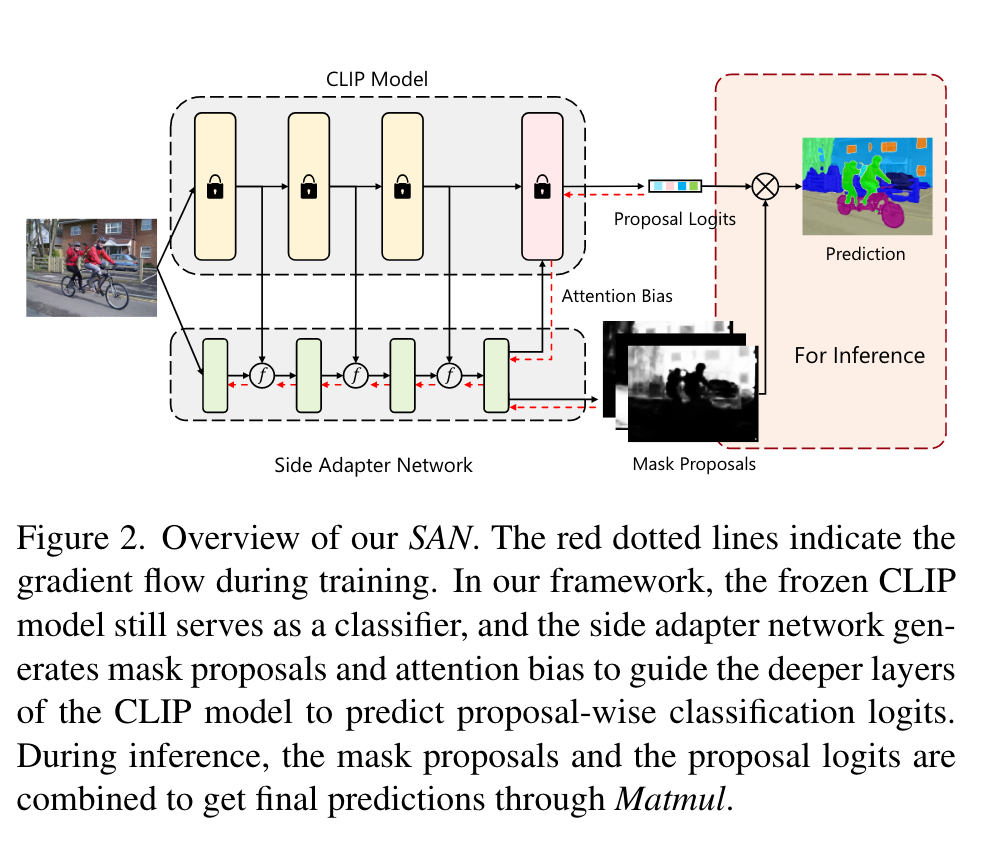
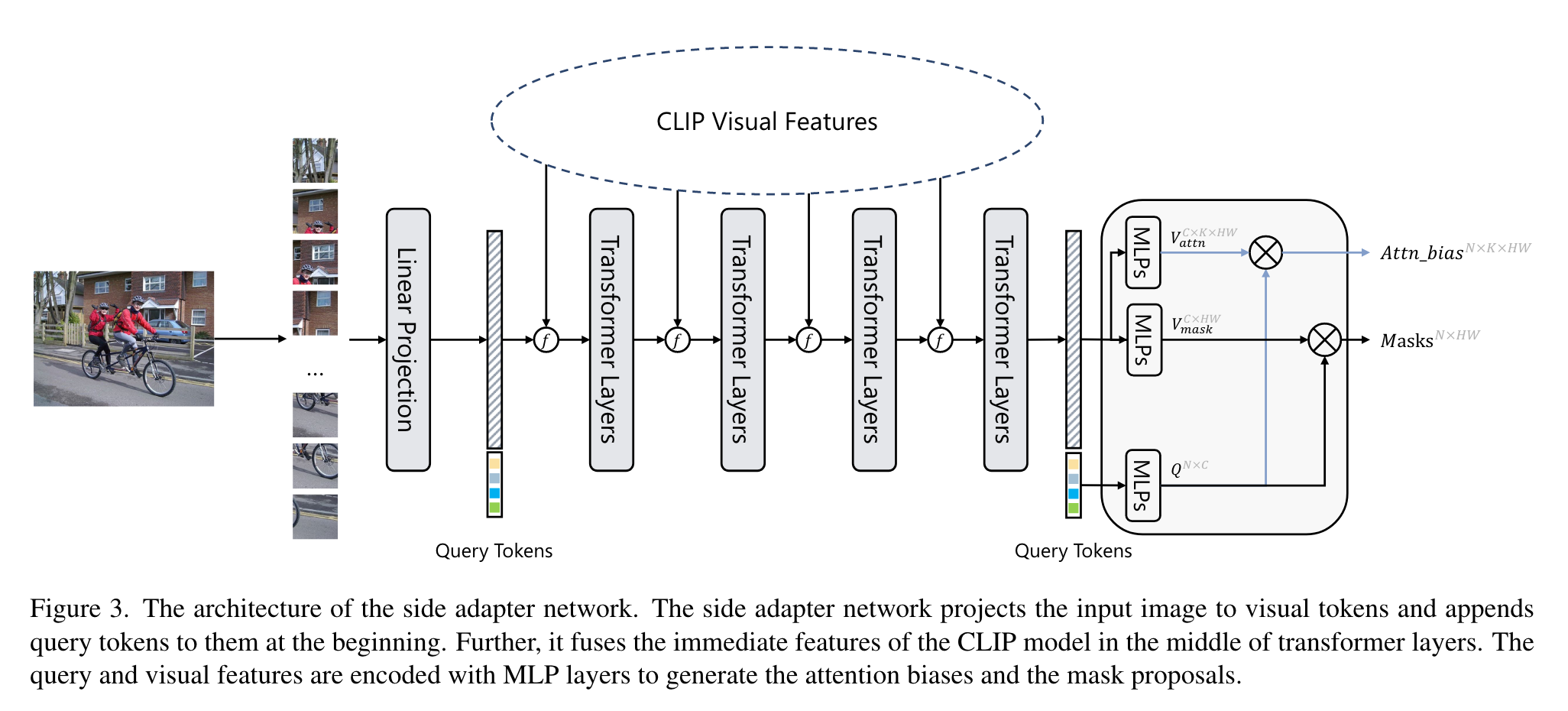
SAN整体结构如上图所示,输入图像被分成\(16\times 16\)的patch,之后被投影成一系列token,与长度为N的query序列拼接后送入Transformer层。SAN包含两个输出:mask proposals以及用于识别mask的attention biases。在预测mask时,query token和visual token首先被3层mlp投影到大小为256的向量空间,投影后的query tokens记为\(Q_{mask}\in \mathbb{R}^{N\times 256}\),visual tokens记为\(V_{mask}\in \mathbb{R}^{\frac{H}{16}\times \frac{W}{16}\times 256}\),mask通过这两者做内积而得:
attention biases与之相似,同样通过mlp生成\(V_{attn}\in\mathbb{R}^{\frac{H}{16}\times \frac{W}{16}\times K\times 256}\)和\(Q_{attn}\in\mathbb{R}^{N\times 256}\),之后进行内积:
其中K是CLIP ViT模型的注意力头数(本文仅使用了ViT版的CLIP)。实验中\(Q_{attn}\)和\(Q_{mask}\)是可以共享的,且attention biases可以用于CLIP的多个自注意力层。
Feature fusion on visual tokens
CLIP ViT模型的输出包括visual tokens和cls token,这里作者仅把visual tokens与SAN进行融合。CLIP和SAN的visual tokens的维度可能不同,作者将CLIP的输出重排为特征图,之后使用\(1\times 1\)卷积对其进行处理,再与SAN的特征图进行逐元素相加。作者这里说这里的融合方式可以进一步设计,从而提升方法的性能。
Mask recognition with attention bias
作者通过引导cls token的注意力图到感兴趣区域来实现精准的mask识别。为此,作者创建了一系列cls token的副本,称作sls。sls可以被visual token和cls token单向更新,但反之不成立。更新sls时需要用到attention bias \(B_k\in \mathbb{R}^{h\times w\times N}\),公式如下:
其中l表示层的编号,k表示第k个注意力头,\(Q_{[SLS]}=W_qX_{[SLS]}\),\(V_{[SLS]}=W_vX_{[SLS]}\),\(K_{visual}=W_kX_{visual}\)。(2023.5.29,代码实现和公式描述不太一样,代码用visual embedding计算v,作者说公式有一个typo,但个人感觉公式是对的,本身就应该用sls去得到v,https://github.com/MendelXu/SAN/issues/10)
借助attention Bias可以改变原始cls token的关注区域,从而实现对mask proposals的高效与精准识别。需要注意的是,sls tokens是加在CLIP的这个分支的,与side adapter network中用于生成mask的query是对应的。
之后作者进行了复杂度分析,借助上面的公式以及下图右半部分可以更好的理解:
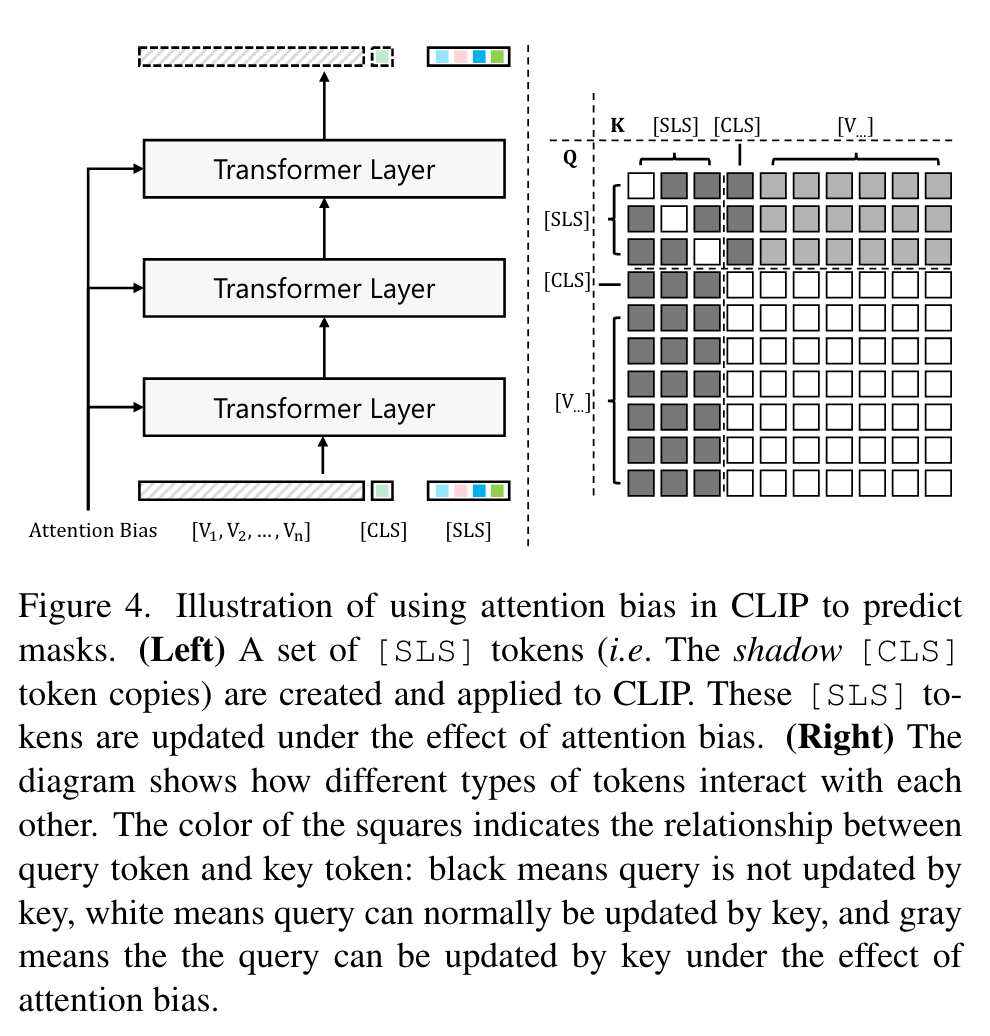
首先根据之前的设定,Q的cls token和visual tokens都不能被K的sls tokens更新,只能被K的cls token和visual tokens更新,因此右下角的这一部分是白色的;其次根据公式,Q的sls tokens与K的visual tokens进行了矩阵乘法,之后与attention bias相加,此右上角是灰色的;最后左上角对角线部分表示Q的sls tokens只能被对应的K的sls tokens更新而不能被其它sls tokens更新。这个图的描述个人感觉比较奇怪,没太理解query能/不能被key更新这种说法。看了一下代码,作者的本意实际上就是在做attention的时候加了一个mask,保证CLIP得到的visual tokens和cls token不受添加的sls tokens的干扰;同时,对于每个sls token,在使用attention score进行加权时,需要把除了自己之外的其余的sls token的分数掩蔽,之后对于visual tokens的分数加上之前得到的attention biases(引入来自side adapter network的信息),再对sls tokens进行加权,类似Openvocabulary panoptic segmentation with maskclip这篇文章的方式。具体实现时,作者使用nn.MultiheadAttention,传入的mask是一个float类型的tensor,每个黑色位置的值是-100,灰色位置的值是对应的attention bias的值,白色位置的值为0,代码在https://github.com/MendelXu/SAN/blob/main/san/model/clip_utils/visual.py的_build_attn_biases函数。这里的图和公式也不太对应,对于图中左上角这部分,作者的解释是最初,所有的 sls_token 值都是一样的(都是通过cls进行初始化),互相关注类似于多关注自己,让sls token相互关注的话性能会略有下降,而第三章的公式(3)在描述更新sls tokens的过程时没有自己关注自己这一项。
因此,总的复杂度就是\(\mathcal{O}((T_{visual} + T_{[CLS]]} + T_{[SLS]})^2)\),其中\(T_{visual}\)表示visual tokens的数量,其它同理。然而,因为mask的存在,可以将求self-attention的过程转化为求cross attention的过程,总的复杂度变为\(\mathcal{O}((T_{visual}+T_{[CLS]})^2+T_{[SLS]}(T_{visual}+T_{[CLS]}))\)。
通过引入attention bias,sls tokens能够逐渐适应mask,对mask的分类就可以通过直接比较对应mask的sls token与类别text embedding的相似度进行了,得到的结果为\(P\in \mathbb{R}^{C\times N}\),代码如下:
mask_logits = [
torch.einsum("bqc,nc->bqn", mask_emb, ov_classifier_weight)
for mask_emb in mask_embs
]
Segmentation map generation
分割图的生成非常简单,假设mask proposals为\(M\in \mathbb{R}^{\frac{H}{16}\times \frac{W}{16}\times N}\),则分割图可以直接通过M与上面的P计算得到:\(S=M\times P^{\top}\)。如此得到的分割图就是标准的语义分割结果。
所有模型的训练都是在COCO Stuff数据集上进行的,对于N个prediction mask与N个gt mask(通过空类别补全)寻找一组最大匹配(损失最小),每一对损失记为\(L_{seg}\):
\(L_{seg} = λ_1L_{mask_dice} + λ_2L_{mask_bce} + λ_3L_{cls}\)
即通过dice loss与bce loss监督mask的生成,通过ce loss监督mask的识别。
实验
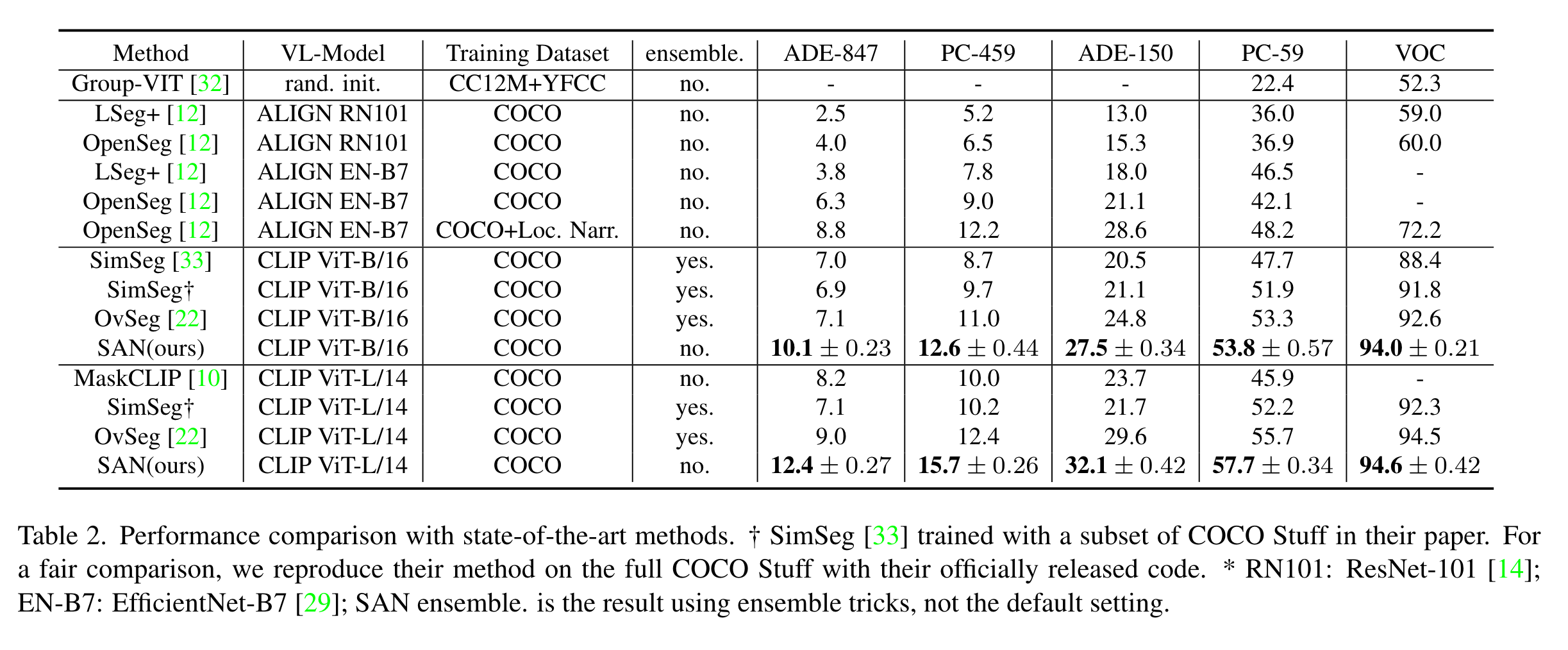
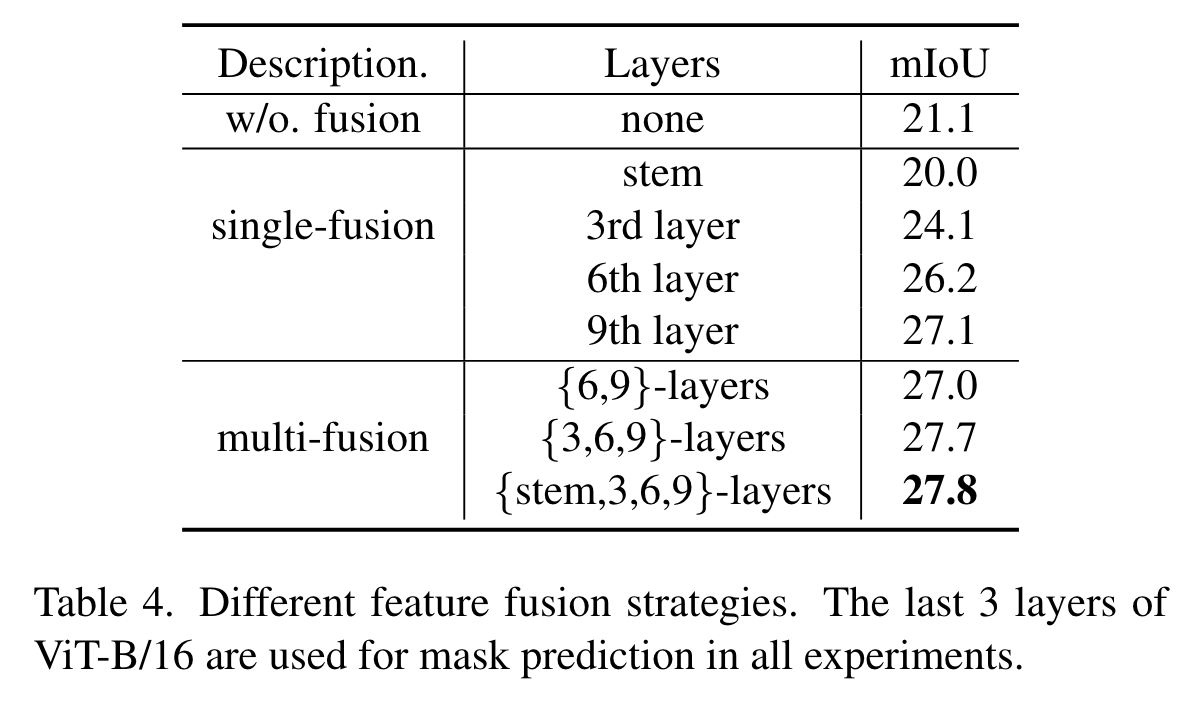
在多个层进行特征融合效果更佳:


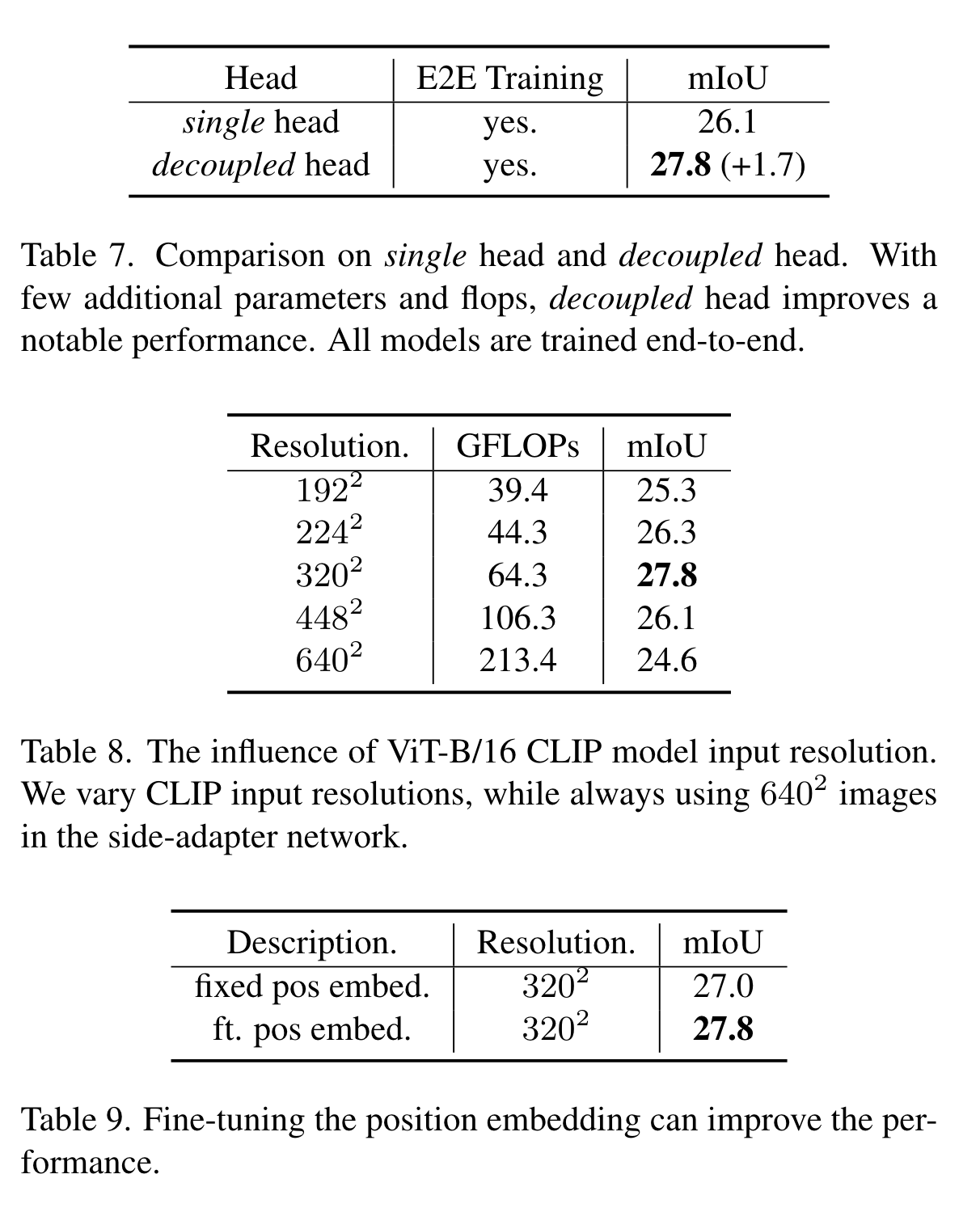
**
- Open-Vocabulary Segmentation Vocabulary Highlight Semanticopen-vocabulary segmentation vocabulary highlight open-vocabulary segmentation vocabulary maskclip open-vocabulary convolutional segmentation networks semantic segmentation criss-cross attention semantic segmentation generative gaussian semantic segmentation attentional semantic network segmentation transformers semantic segvit vocabulary highlight