https://www.tensorflow.org/text/guide/word_embeddings
将文本表示为数字
机器学习模型将向量(数字数组)作为输入。处理文本时,您必须做的第一件事是想出一种策略,将字符串转换为数字(或“矢量化”文本),然后再将其输入模型。
1独热编码
作为第一个想法,您可能会对词汇表中的每个单词进行“one-hot”编码。考虑一下“猫坐在垫子上”这句话。这句话中的词汇(或独特的单词)是(cat、mat、on、sat、the)。为了表示每个单词,您将创建一个长度等于词汇表的零向量,然后在与该单词对应的索引中放置一个 1。这种方法如下图所示。
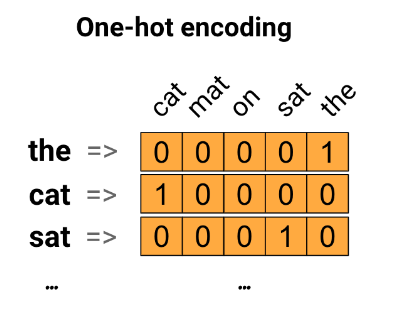
要点:这种方法效率低下。one-hot 编码向量是稀疏的(意味着大多数索引为零)。想象一下您的词汇表中有 10,000 个单词。要对每个单词进行 one-hot 编码,您需要创建一个 99.99% 的元素为零的向量。
2用唯一的数字对每个单词进行编码
您可以尝试的第二种方法是使用唯一的数字对每个单词进行编码。继续上面的示例,您可以将 1 分配给“cat”,2 分配给“mat”,依此类推。然后,您可以将句子“The cat sat on the mat”编码为密集向量,如 [5, 1, 4, 3, 5, 2]。这种方法是有效的。现在您拥有一个密集向量(其中所有元素都已满),而不是稀疏向量。
然而,这种方法有两个缺点:
-
整数编码是任意的(它不捕获单词之间的任何关系)。
-
整数编码对于模型的解释来说可能具有挑战性。例如,线性分类器学习每个特征的单个权重。因为任意两个单词的相似度与其编码的相似度之间没有关系,所以这种特征权重组合是没有意义的。
3词嵌入
词嵌入为我们提供了一种使用高效、密集表示的方法,其中相似的词具有相似的编码。重要的是,您不必手动指定此编码。
嵌入是浮点值的密集向量(向量的长度是您指定的参数)。
它们不是手动指定嵌入的值,而是可训练参数(模型在训练期间学习的权重,就像模型学习密集层的权重一样)。
通常会看到 8 维的词嵌入(对于小型数据集),在处理大型数据集时最多可达 1024 维。更高维度的嵌入可以捕获单词之间的细粒度关系,但需要更多数据来学习。

上图是词嵌入的图。每个单词都表示为浮点值的 4 维向量。考虑嵌入的另一种方式是“查找表”。学习了这些权重后,您可以通过在表中查找其对应的密集向量来对每个单词进行编码。
https://zh.d2l.ai/chapter_recurrent-modern/seq2seq.html
嵌入层的权重是一个矩阵, 其行数等于输入词表的大小(vocab_size), 其列数等于特征向量的维度(embed_size)。
对于任意输入词元的索引i, 嵌入层获取权重矩阵的第i行(从0开始)以返回其特征向量。