GPU图形渲染分析
1 概述
高强度图形是当代计算机系统的标志。今天的计算机,从智能手机到高端台式机,都使用各种复杂的视觉效果来增强用户体验。此外,用户还可以使用计算机玩图形密集型游戏、观看高清视频,以及进行计算机辅助工程设计,所有这些应用程序都需要大量的图形处理。
在早期,计算机中的图形支持非常初级,程序员需要指定屏幕上绘制的每个形状的坐标,例如要绘制一条线,程序员需要明确提供该线的坐标,并指定其颜色。颜色的范围非常有限,而且几乎没有用于卸载图形密集型任务的硬件。由于在屏幕上绘制的每一条线或圆都需要几个汇编语句,因此创建和使用计算机图形的过程非常缓慢。渐渐地,需要在硬件中对图形进行一些支持。
由于GPU和CPU是为两种截然不同的应用程序而设计和优化的,因此它们的体系结构存在显著差异,可以通过比较两种处理器技术专用于高速缓存、控制逻辑和处理逻辑的管芯面积(晶体管计数)的相对数量来看出(下图)。
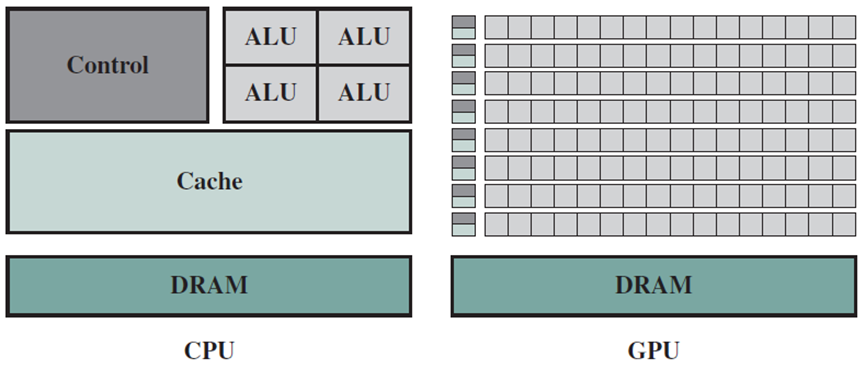
CPU和GPU在缓存、ALU、控制器等硬件单元的对比图。
1.1 图形应用
可以将现代图形应用程序分为两种类型。第一类是自动图像合成。例如考虑游戏中的一个复杂场景,其中一个角色在月明的夜晚拿着机枪奔跑。在这种情况下,程序员不是手动将每个像素的值设置为给定的颜色,此过程太慢且耗时。如果使用这种方法,互动游戏都不会起作用。相反,程序员在高级对象级别编写程序,例如他可以用道路、植物和障碍物等一组对象来定义场景,可以塑造一个角色,以及随身携带的诸如机关枪、小刀和斗篷等工艺品,程序员根据这些对象编写程序。此外,他还可指定了一组规则来定义这些对象的交互,例如,如果角色与墙发生碰撞,则该角色会转身并朝另一个方向运行。除了定义对象和对象的语义外,还必须定义场景中的光源。在这种情况下,程序员需要指定月光下夜晚的光线强度。然后,通过专用图形软件和硬件自动计算角色和背景的照度。
遗憾的是,图形硬件不理解复杂对象和字符的语言。因此,大多数图形工具包都有图形库来将复杂结构分解为一组基本形状,计算机图形应用程序中的大多数形状都被分解为一组三角形,所有操作(如对象碰撞、移动、照明、阴影和照明)都转换为三角形上的基本操作。然而,图形库不使用常规处理器来处理这些三角形,并最终创建要在计算机屏幕上显示的像素阵列。一旦程序员的意图转化为对基本形状的操作,图形库就会将代码发送到专用图形处理器,该处理器完成其余的处理。图形处理器根据用户提供的数据和规则生成复杂场景,对由边和顶点指定的形状进行操作。大多数时候,这些形状是二维空间中的三角形,或者三维空间中的四面体。图形处理器还在生成最终图像时计算照明、对象位置、深度和透视的效果,一旦图形处理器生成了最终图像,它就会将其发送到显示设备。如果在玩电脑游戏,那么这个过程需要每秒至少进行50-100次。
总之,由于生成复杂的图形场景既困难又缓慢,因此程序员对对象进行高级描述。随后,图形库将程序员的指令转换为对基本形状的操作,并将一组形状和对其进行操作的规则发送给图形处理器。图形处理器通过对基本形状进行操作,然后将其转换为像素阵列来生成最终场景。
图形处理器的第二个重要应用是显示视频等动画内容,高清晰度视频每个场景有数百万像素。为了减少存储需求,大多数高清晰度视频都经过了严格压缩(编码)。因此,计算机需要解码或解压缩视频,每秒计算50-100次像素阵列,并在屏幕上显示它们。这是一个非常计算密集的过程,可能占用CPU的资源。因此,视频解码通常也被加载到图形处理器,该处理器包含处理视频的专用单元。
几乎所有现代计算机系统都包含图形处理器,它被称为GPU(Graphics Processing Unit,图形处理单元)。现代GPU包含超过64-128个内核,因此设计用于广泛的并行处理。
1.2 图形管线
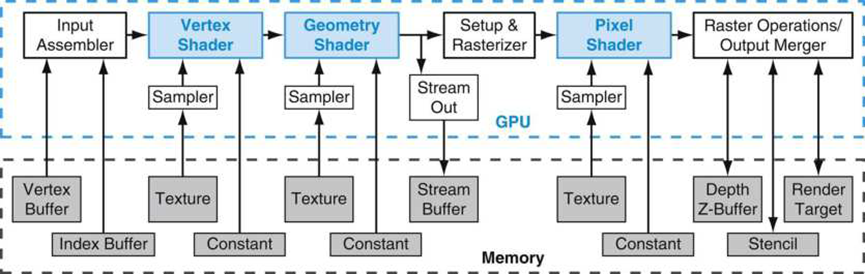
现在让看看下图中的典型图形处理器的流水线。

图形管线。
第一阶段称为顶点处理。在此阶段,将处理一组顶点、形状和三角形。GPU执行复杂的操作,例如对象旋转和平移。程序员可能会指定给定的对象以一定的速度朝向另一个对象移动,因此有必要以给定的速率平移形状的位置,这种操作也在这个阶段进行。此阶段的输出是2D平面中的一组简单三角形。
第二阶段称为光栅化。光栅化过程将每个三角形转换为一组像素,称为片元(或片段)。此外,它将片元中的每个像素与一组参数相关联,这些参数稍后用于插值颜色的值。
第三阶段是片元处理。该阶段使用前一阶段计算的中间结果根据一组固定规则对片元的像素进行着色,或者将给定纹理映射到片元。例如,如果一块片元代表一张木制桌子的表面,那么这个阶段将木材的纹理映射到像素的颜色。此阶段还用于合并阴影和照明等效果。
注意,到目前为止,已经计算了场景中所有对象的片元颜色。然而,一个对象可能位于另一个对象的前面,因此第二个对象的一部分可能被隐藏。
第四阶段聚合来自第三阶段的所有片元,并执行称为帧缓冲处理的操作。帧缓冲区是一个大数组,包含每个像素的颜色值,图形卡每秒向显示设备传送50-100次帧缓冲器。在此阶段执行的操作之一称为深度缓冲,它通过隐藏部分对象,以一定角度计算3D空间的2D视图。创建最终场景后,图形管线将图像传输到帧缓冲区。
以上就是图形处理器渲染复杂游戏,甚至是最小化或最大化窗口等标准操作的方式。渲染被定义为通过根据对象、规则和视觉效果处理场景的高级描述,以像素为单位生成场景的过程。渲染过程本质上涉及很多线性代数运算,包含对象旋转或平移都等矩阵运算。这些操作处理大量浮点值,并且本质上是并行的。
1.3 高性能计算与图形计算的融合
到了90年代末,计算机图形学领域迅速发展。计算机游戏、桌面视觉效果和先进的工程软件激增,需要复杂的计算机图形硬件加速器。因此,设计师越来越需要创造更生动的场景和更逼真的物体。可以比较80年代后期制作的动画电影和今天的好莱坞电影,今天的动画电影有非常逼真的人物,面部表情非常细致。多亏了图形硬件,所有这些都成为可能。为了创造这种身临其境的体验,有必要在图形处理器中增加很大程度的灵活性,以结合不同类型的视觉效果。因此,图形处理器设计者将处理器的许多内部部件暴露给低级软件,并允许程序员更灵活地使用处理器。一组名为着色器的程序诞生于2000年初,它们允许程序员创建灵活的片段和像素处理例程。
到2006年,主要GPU供应商已经认识到图形管道也可以用于通用计算,例如大量数值化的科学代码在概念上类似于片元或像素处理操作。如果允许常规用户程序访问图形处理器以执行其任务,就可以在图形处理器上运行大量科学程序。为了响应这一要求,NVIDIA发布了CUDA API,允许C程序员用C语言编写代码,并在图形处理器上运行,GPGPU(通用GPU)一词就此诞生了。
GPGPU代表通用图形处理单元,本质上是一个图形处理器,允许普通用户在其上编写和运行代码。用户通常使用专用语言或标准语言的扩展来生成与GPGPU兼容的代码。
后面将讨论NVIDIA Tesla GPU架构的设计,具体来说,将讨论GeForce 8800 GPU的设计。GPU最快的部分(核心)通常工作在1.5GHz或更高,其他部件的工作频率为600 MHz、750 MHz或以上。
2 GPU系统架构
当今常用的GPU系统架构有几种,下面将阐述它们的系统配置、GPU功能和服务、标准编程接口以及基本的GPU内部架构。
2.1 异构CPU–GPU系统架构
使用GPU和CPU的异构计算机系统架构可以通过两个主要特征在高层次上描述:第一,使用了多少功能子系统和/或芯片,以及它们的互连技术和拓扑结构;第二,哪些内存子系统可用于这些功能子系统。
下图显示了大约1990年遗留PC的高级结构图。北桥包含连接CPU、内存和PCI总线的高带宽接口,南桥包含传统的接口和设备:ISA总线(音频、LAN)、中断控制器;DMA控制器;时间/计数器。在该系统中,显示器由一个简单的帧缓冲子系统驱动,该子系统被称为VGA(视频图形阵列),它连接到PCI总线。具有内置处理元件(GPU)的图形子系统在1990年的PC环境中并不存在。
下图说明了目前常用的两种配置。它们的特点是具有各自存储器子系统的独立GPU(离散GPU)和CPU。在图a中,对于Intel CPU,GPU通过16通道PCI Express 2.0链路连接,以提供峰值16 GB/s传输速率(每个方向的峰值为8 GB/s)。类似地,在图b中,对于AMD CPU,GPU也通过具有相同可用带宽的PCI Express连接到芯片组。在这两种情况下,GPU和CPU可以访问彼此的内存,尽管可用带宽比它们访问更直接连接的内存的带宽要少。在AMD系统的情况下,北桥或存储器控制器与CPU集成在同一芯片中。

PCI Express(PCIe):使用点对点链路的标准系统I/O互连,链路具有可配置的通道数和带宽。
统一内存架构(unified memory architecture,UMA):CPU和GPU共享公共系统内存的系统架构。
这些系统上的一种低成本变体,即统一内存架构系统,仅使用CPU系统内存,而省略了系统中的GPU内存。这些系统具有相对较低的性能GPU,因为它们实现的性能受到可用系统内存带宽和增加的内存访问延迟的限制,而专用GPU内存提供高带宽和低延迟。
高性能系统变体使用多个连接的GPU,通常两到四个并行工作,其显示器呈菊花链,如NVIDIA SLI(可扩展链接互连)多GPU系统,专为高性能游戏和工作站而设计。
下一个系统类别将GPU与北桥(Intel)或芯片组(AMD)集成在一起,无论有无专用图形内存。
前述章节解释了缓存如何在共享地址空间中保持一致性。对于CPU和GPU,有多个地址空间,GPU可以使用由GPU上的MMU转换的虚拟地址访问自己的物理本地内存和CPU系统的物理内存。操作系统内核管理GPU的页表,可以使用一致或非一致的PCI Express事务访问系统物理页面,取决于GPU页面表中的属性。CPU可以通过PCI Express地址空间中的地址范围(也称为开口,aperture)访问GPU的本地内存。
诸如Sony PlayStation 3和Microsoft Xbox 360的控制台系统类似于前面描述的PC系统架构,控制台系统设计为在使用寿命长达五年或更长的时间内提供相同的性能和功能。在此期间,可以多次重新实现系统以开发更先进的硅制造工艺,从而以更低的成本提供恒定的能力。控制台系统不需要像PC系统那样扩展和升级其子系统,因此主要的内部系统总线倾向于定制而非标准化。
在如今的PC中,GPU通过PCI Express连接到CPU,前几代使用AGP。图形应用程序调用OpenGL或Direct3DAPI函数,将GPU用作协处理器,API通过为特定GPU优化的图形设备驱动程序向GPU发送命令、程序和数据。
AGP:原始PCI I/O总线的扩展版本,为单个卡插槽提供了高达原始PCI总线八倍的带宽。其主要目的是将图形子系统连接到PC系统中。
2.2 基础统一GPU架构
统一GPU架构基于许多可编程处理器的并行阵列。它们将顶点、几何体和像素着色器处理和并行计算统一在同一处理器上,与早期GPU不同,早期GPU具有专用于每种处理类型的单独处理器。可编程处理器阵列与固定功能处理器紧密集成,用于纹理过滤、光栅化、光栅操作、抗锯齿、压缩、解压缩、显示、视频解码和高清视频处理。尽管固定功能处理器在受面积、成本或功率预算限制的绝对性能方面明显优于更一般的可编程处理器,本小节重点介绍可编程处理器。
与多核CPU相比,多核GPU具有不同的架构设计点,其重点是在多个处理器核上高效地执行多个并行线程。通过使用许多更简单的内核并优化线程组之间的数据并行行为,每个芯片的晶体管预算更多地用于计算,而更少地用于片上缓存和开销。
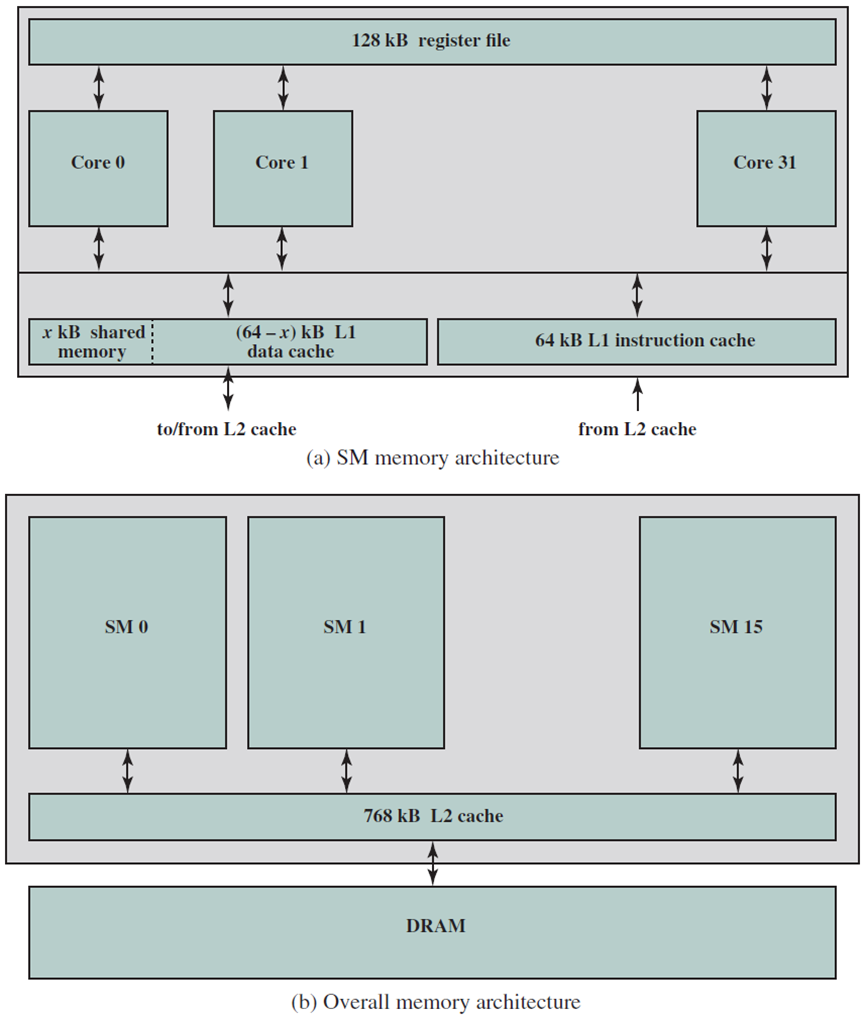
统一的GPU处理器阵列包含许多处理器核心,通常组织为多线程多处理器。下图显示了具有112个流处理器(SP)核心阵列的GPU,这些核心被组织为14个多线程流多处理器(SM)。每个SP核心都是高度多线程的,在硬件中管理96个并发线程及其状态。处理器通过互连网络与四个64位宽的DRAM分区连接,每个SM有八个SP核、两个特殊功能单元(SFU)、指令和常量缓存、一个多线程指令单元和一个共享内存。这是NVIDIA GeForce 8800实现的基本Tesla架构,具有统一的架构,其中用于顶点、几何和像素着色的传统图形程序在统一的SM及其SP内核上运行,计算程序在相同的处理器上运行。
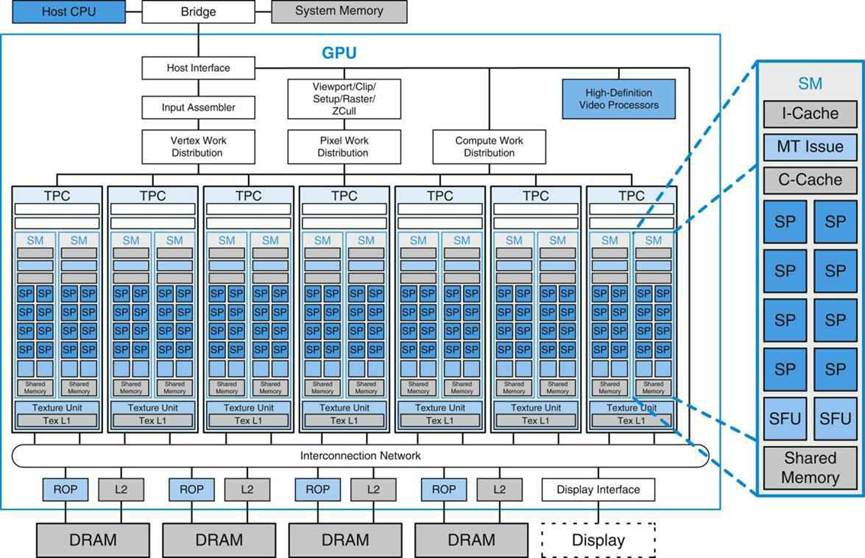
通过缩放多处理器的数量和内存分区的数量,处理器阵列架构可扩展到更小和更大的GPU配置。上图显示了共享纹理单元和纹理L1缓存的两个SM的七个集群,纹理单元将过滤后的结果传递给SM,并将一组坐标转换为纹理图。由于连续纹理请求的支持过滤器区域经常重叠,因此小型流式L1纹理缓存可有效减少对内存系统的请求数量。处理器阵列通过GPU范围的互连网络与光栅操作处理器(ROP)、二级纹理缓存、外部DRAM存储器和系统存储器连接。处理器的数量和内存的数量可以进行扩展,以针对不同的性能和市场细分设计平衡的GPU系统。
下图显示了NVIDIA Fermi架构GPU的总体布局。如图所示,L2缓存位于16个SM(上下8个SM)的中心,每个SM由2个相邻列和16行矩形(GPU处理器核心)以及一列16个加载/存储单元和一列4个特殊功能单元(SFU)表示。SM模块的更详细图示如下下图所示。下图中SM头部和底部的矩形是寄存器和L1/共享内存所在的位置,6个DRAM I/O接口中的每一个都具有64位存储器接口(DRAM接口电路在最外侧的左侧和右侧以深蓝色矩形显示)。因此,总体而言,GPU的GDDR5(图形双倍数据速率,专为图形处理而设计的DDR存储器)DRAM具有384位接口,允许支持总计6 GB的SM片外存储器(即全局、固定、纹理和局部)。此外,下图所示为主机接口,可在GPU布局图的左侧找到,主机接口允许GPU和CPU之间的PCIe连接。最后,GigaThread全局调度器(位于主机接口旁边)负责将线程块分配给所有SM的warp调度器。

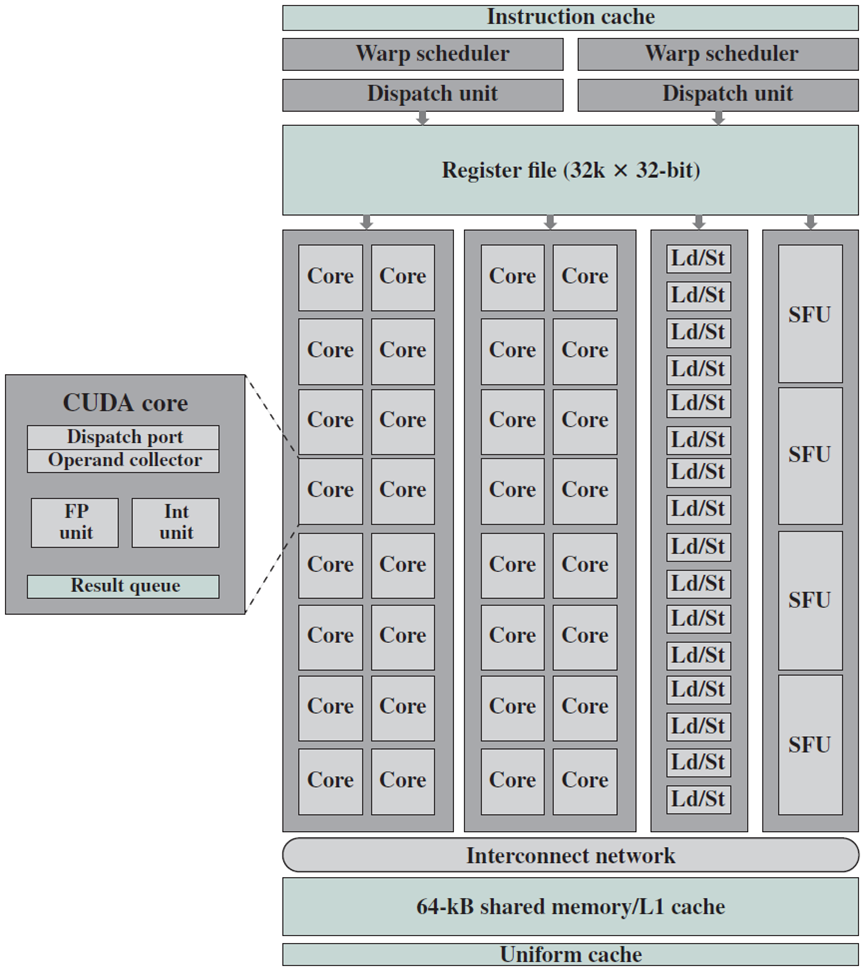
3 多线程多处理器架构
为了解决不同的市场细分,GPU实现了可扩展的多处理器数量,实际上GPU是由多处理器组成的多处理器,此外,每个多处理器都是高度多线程的,可以高效地执行许多细粒度顶点和像素着色器线程。一个高质量的基本GPU有两到四个多处理器,而游戏爱好者的GPU或计算平台有几十个。将介绍一个这样的多线程多处理器的架构,是前面描述的NVIDIA Tesla流式多处理器(SM)的简化版本。
为什么要使用多处理器,而不是几个独立的处理器?每个多处理器内的并行性提供了本地化的高性能,并支持细粒度并行编程模型的广泛多线程,线程块的各个线程在多处理器内一起执行以共享数据。这里描述的多线程多处理器设计在紧密耦合的架构中有八个标量处理器内核,最多执行512个线程。为了提高面积和功率效率,多处理器在八个处理器内核中共享大型复杂单元,包括指令缓存、多线程指令单元和共享内存RAM。
GPU处理器高度多线程,可实现以下几个目标:
- 覆盖DRAM内存加载和纹理提取的延迟
- 支持细粒度并行图形着色器编程模型
- 支持细粒度并行计算编程模型
- 将物理处理器虚拟化为线程和线程块,以提供透明的可扩展性
- 将并行编程模型简化为为一个线程编写串行程序
内存和纹理提取延迟可能需要数百个处理器时钟,因为GPU通常具有小型流缓存,而不像CPU这样的大型工作集缓存,提取请求通常需要完整的DRAM访问延迟加上互连和缓冲延迟。当一个线程等待加载或纹理获取完成时,多线程有助于利用有用的计算来覆盖延迟,处理器可以执行另一个线程。细粒度并行编程模型提供了数千个独立的线程,尽管单个线程的内存延迟很长,但这些线程仍能让许多处理器保持忙碌。
图形顶点或像素着色器程序是用于处理顶点或像素的单个线程的程序,类似地,CUDA程序是用于计算结果的单个线程的C程序。图形和计算程序实例化许多并行线程,以渲染复杂图像并计算大型结果数组。为了动态平衡移动顶点和像素着色器线程工作负载,每个多处理器同时执行多个不同的线程程序和不同类型的着色器程序。
为了支持图形着色语言的独立顶点、图元和像素编程模型以及CUDA C/C++的单线程编程模型,每个GPU线程都有自己的专用寄存器、专用每线程内存、程序计数器和线程执行状态,并且可以执行独立的代码路径。为了有效地执行数百个并发轻量级线程,GPU多处理器是硬件多线程的,在硬件中管理和执行数百个并行线程,而无需调度开销。线程块中的并发线程可以在一个屏障处与单个指令同步,轻量级线程创建、零开销线程调度和快速屏障同步有效地支持非常细粒度的并行性。
3.1 海量线程
GPU处理器高度多线程化,可实现以下几个目标:
- 覆盖DRAM内存加载和纹理提取的延迟。
- 支持细粒度并行图形着色器编程模型。
- 支持细粒度并行计算编程模型。
- 将物理处理器虚拟化为线程和线程块,以提供透明的可扩展性。
- 将并行编程模型简化为为一个线程编写串行程序。
内存和纹理提取延迟可能需要数百个处理器时钟,因为GPU通常具有小型流缓存,而不像CPU的大型工作集缓存。提取请求通常需要完整的DRAM访问延迟加上互连和缓冲延迟,当一个线程等待加载或纹理获取完成时,多线程有助于利用有用的计算来覆盖延迟,处理器可以执行另一个线程(下图)。细粒度并行编程模型提供了数千个独立的线程,尽管单个线程的内存延迟很长,但这些线程仍能让许多处理器保持忙碌。
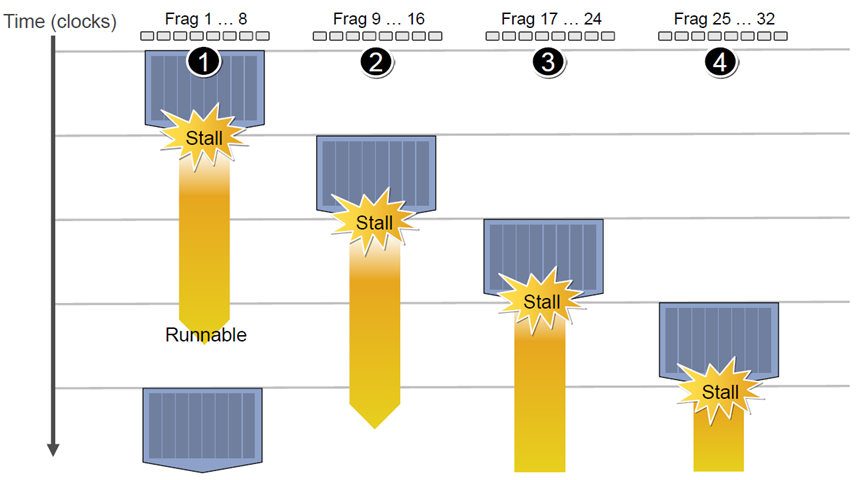
GPU利用多个Context切换来覆盖内存访问延迟。
图形顶点或像素着色器程序是用于处理顶点或像素的单个线程的程序,类似地,CUDA程序是用于计算结果的单个线程的C程序,图形和计算程序实例化许多并行线程以渲染复杂的图像并计算大型结果数组。为了动态平衡移动顶点和像素着色器线程工作负载,每个多处理器同时执行多个不同的线程程序和不同类型的着色器程序。
为了支持图形着色语言的独立顶点、图元和像素编程模型以及CUDA C/C++的单线程编程模型,每个GPU线程都有自己的专用寄存器、专用逐线程内存、程序计数器和线程执行状态,并且可以执行独立的代码路径。为了有效地执行数百个并发轻量级线程,GPU多处理器是硬件多线程的,它在硬件中管理和执行数百个并行线程,而无需调度开销。线程块中的并发线程可以在一个屏障处与单个指令同步,轻量级线程创建、零开销线程调度和快速屏障同步有效地支持非常细粒度的并行性。
3.2 多处理器架构
统一的图形和计算多处理器执行顶点、几何体和像素片段着色器程序以及并行计算程序。如下图所示,示例多处理器由八个标量处理器(SP)内核组成,每个内核具有一个大型多线程寄存器文件(RF)、两个特殊功能单元(SFU)、一个多线程指令单元、一个指令缓存、一个只读常量缓存和一个共享内存。
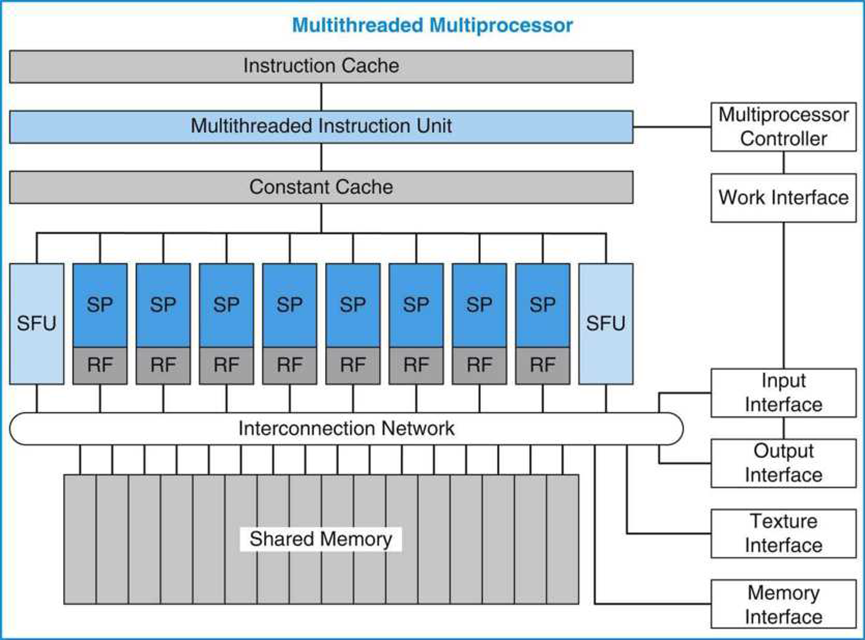
具有八个标量处理器(SP)核的多线程多处理器。八个SP核每个都有一个大型多线程寄存器文件(RF),并共享一个指令缓存、多线程指令发布单元、常量缓存、两个特殊功能单元(SFU)、互连网络和一个多组共享内存。
16KB的共享内存保存图形数据缓冲区和共享计算数据,声明为__shared__的CUDA变量驻留在共享内存中。为了通过多处理器多次映射逻辑图形管道工作负载,顶点、几何体和像素线程具有独立的输入和输出缓冲区,工作负载的到达和离开与线程执行无关。
每个SP核心包含执行大多数指令的标量整数和浮点算术单元。SP是硬件多线程的,最多支持64个线程。每个流水线SP内核每时钟每个线程执行一个标量指令,在不同的GPU产品中,其范围从1.2 GHz到1.6 GHz。每个SP核心都有一个1024个通用32位寄存器的大RF,在其分配的线程之间进行分区。程序声明其寄存器需求,通常每个线程16到64个标量32位寄存器。SP可以同时运行使用少量寄存器的多个线程或使用更多寄存器的更少线程,编译器优化寄存器分配,以平衡溢出寄存器的成本与更少线程的成本。像素着色器程序通常使用16个或更少的寄存器,使每个SP能够运行多达64个像素着色器线程,以覆盖长延迟纹理提取。编译的CUDA程序通常每个线程需要32个寄存器,将每个SP限制为32个线程,限制了该示例多处理器上的内核程序每个线程块只能有256个线程,而不是最多512个线程。
流水线SFU执行线程指令,这些指令计算特殊函数,并从原始顶点属性插值像素属性,可以与SP上的指令同时执行。
多处理器通过纹理接口在纹理单元上执行纹理提取指令,并使用内存接口执行外部内存加载、存储和原子访问指令,这些指令可以与SP上的指令同时执行。共享内存访问使用SP处理器和共享内存组之间的低延迟互连网络。
3.3 单指令多线程(SIMT)
为了高效地管理和执行运行多个不同程序的数百个线程,多处理器采用了单指令多线程(SIMT)架构,它在称为warp的并行线程组中创建、管理、调度和执行并发线程。“warp”一词起源于第一种平行线技术——编织,下图中的照片显示了织机上出现的平行线的warp,此示例多处理器使用32个线程的SIMT warp大小,在四个时钟上在八个SP核中的每一个中执行四个线程。Tesla SM多处理器还使用32个并行线程的warp大小,每个SP内核执行四个线程,以提高大量像素线程和计算线程的效率。线程块由一个或多个warp组成。
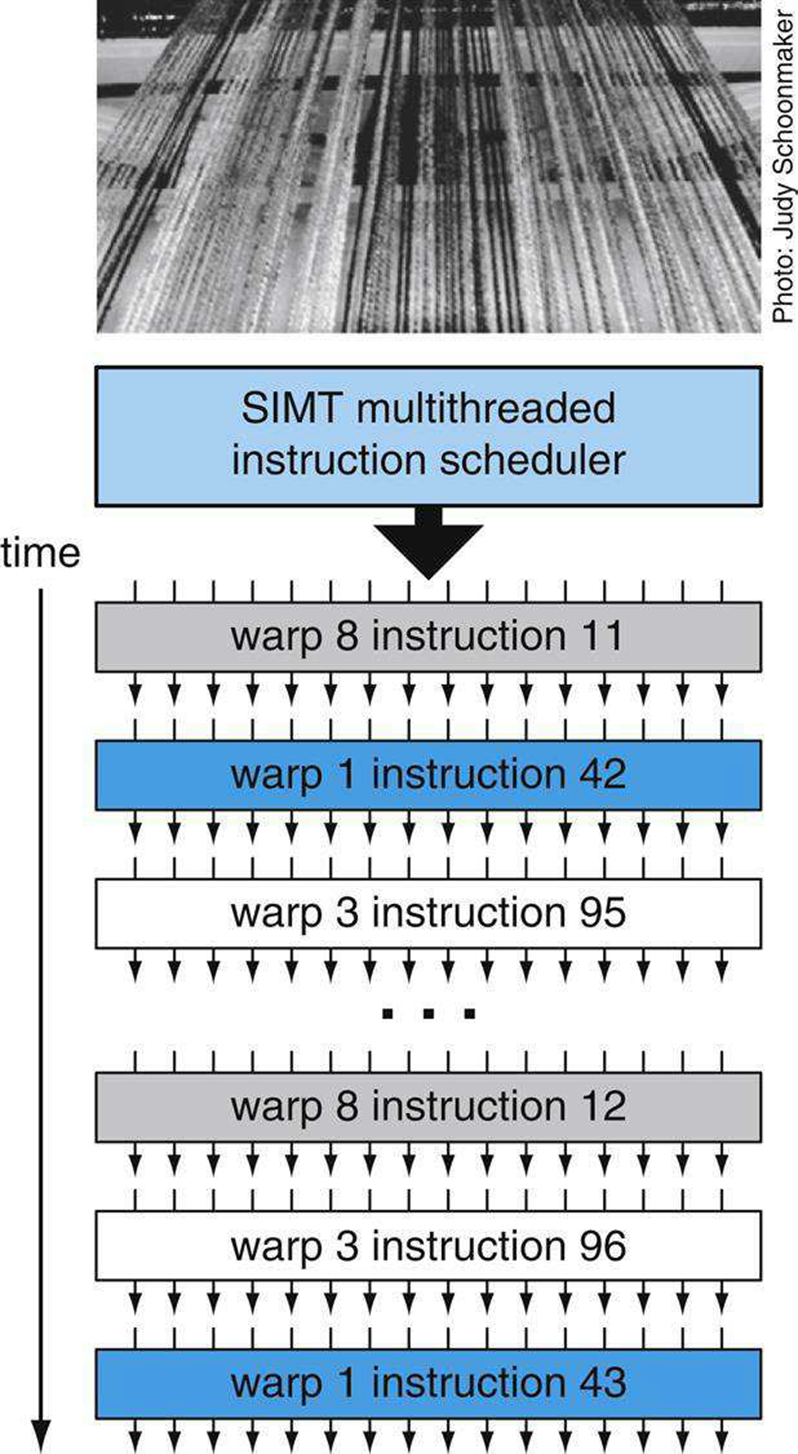
SIMT多线程warp调度。调度器选择一个准备好的warp,并向组成warp的并行线程同步发出指令。因为warp是独立的,所以调度器每次都可以选择不同的warp。
单指令多线程(single-instruction multiple-thread,SIMT):一种并行地将一条指令应用于多个独立线程的处理器架构。
经线(warp):在SIMT体系结构中一起执行同一指令的一组并行线程。
此示例SIMT多处理器管理一个包含16个warp的池,总共512个线程。组成warp的单个并行线程是相同的类型,并在相同的程序地址一起开始,但在其他情况下可以自由分支并独立执行。在每次指令发出时,SIMT多线程指令单元选择一个准备好执行其下一条指令的warp,然后将该指令发出给该warp的活动线程。SIMT指令被同步广播到warp的活动并行线程,由于独立的分支或预测,各个线程可能处于非活动状态。在该多处理器中,每个SP标量处理器内核使用四个时钟为一个warp的四个单独线程执行一条指令,反映了warp线程与内核的4:1比率。
SIMT处理器架构类似于单指令多数据(SIMD)设计,它将一条指令应用于多个数据通道,但不同之处在于,SIMT将一条命令并行应用于多条独立线程,而不仅仅是多条数据通道。用于SIMD处理器的指令一起控制多个数据通道的向量,而用于SIMT处理器的指令控制单个线程,并且SIMT指令单元向独立并行线程的warp发出指令以提高效率。SIMT处理器在运行时发现线程之间的数据级并行性,类似于超标量处理器在运行时间发现指令之间的指令级并行性。
当warp的所有线程采用相同的执行路径时,SIMT处理器实现了充分的效率和性能。如果warp的线程通过依赖于数据的条件分支分叉,则执行会对所采用的每个分支路径进行串行化,并且当所有路径完成时,线程会汇聚到同一执行路径。对于等长路径,发散的if-else代码块的效率为50%,多处理器使用分支同步堆栈来管理发散和聚合的独立线程。不同的warp以全速独立执行,而不管它们是执行公共的还是不相交的代码路径。因此,与早期GPU相比,SIMT GPU在分支代码上的效率和灵活性显著提高,因为它们的warp比现有GPU的SIMD宽度窄得多。
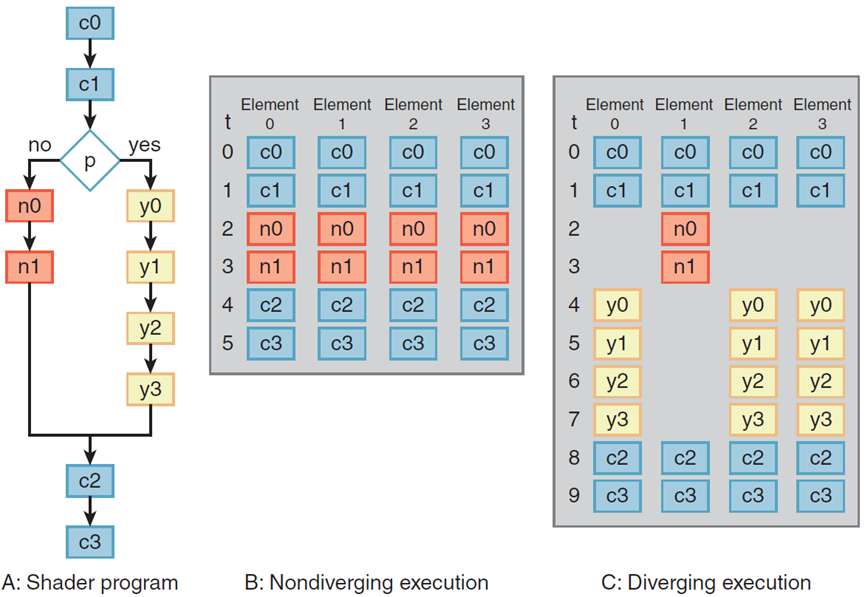
四元素预测向量核上的分支和非分支执行。每个元素执行在判断p上分支的十个操作着色器A。在情况B中,所有四个元素都采用无分支,没有发散,只需要六个执行步骤。在情况C中,元素1采用no分支,但其他三个元素采用yes分支。判断通过分别执行no和yes操作来处理这种差异,因此需要所有十个执行步骤。
与SIMD向量架构相比,SIMT使程序员能够为单个独立线程编写线程级并行代码,以及为许多协调线程编写数据并行代码。对于程序的正确性,程序员基本上可以忽略warp的SIMT执行属性,但通过注意代码很少需要warp中的线程来发散,可以实现显著的性能改进。实际上,这与传统代码中缓存线的作用类似:在设计正确性时可以安全地忽略缓存行大小,但在设计峰值性能时必须在代码结构中考虑缓存行大小。
3.4 SIMT Warp执行和发散
调度独立warp的SIMT方法比先前GPU架构的调度更灵活。warp包含相同类型的并行线程:顶点、几何体、像素或计算。像素片段着色器处理的基本单元是实现为四个像素着色器线程的2*2像素四边形,多处理器控制器将像素四边形打包为warp,它类似地将顶点和图元分组为warp,并将计算线程打包为warp,线程块包括一个或多个warp。SIMT设计在一个warp的并行线程之间有效地共享指令获取和发出单元,但需要一个完整的活动线程warp来获得充分的性能效率。
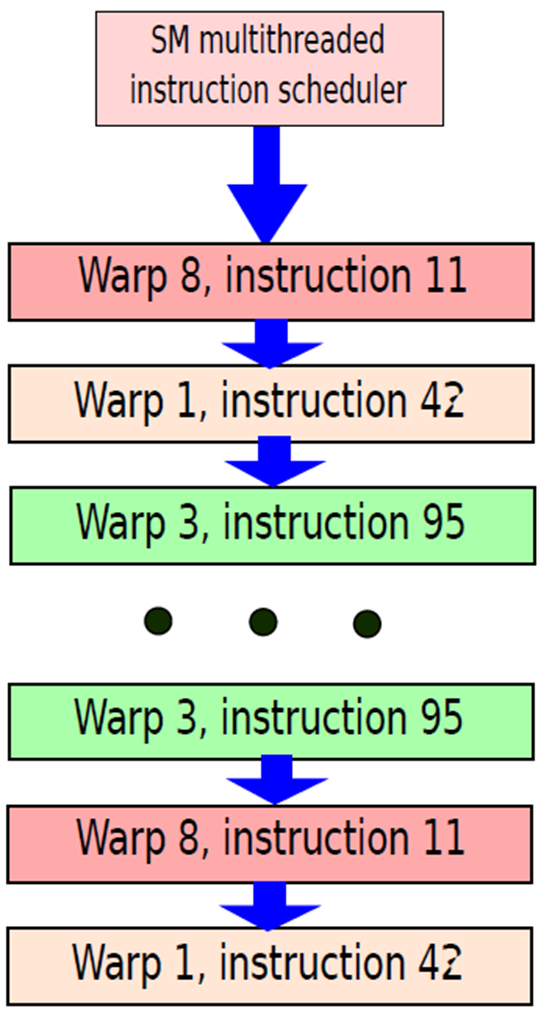
这种统一的多处理器同时调度和执行多个warp类型,允许它同时执行顶点和像素warp。它的warp调度器以低于处理器时钟速率的速度运行,因为每个处理器内核有四个线程通道。在每个调度周期中,它选择一个warp来执行SIMT warp指令,如上图所示。发出的warp指令在四个处理器吞吐量周期内作为四组八个线程执行,处理器流水线使用几个延迟时钟来完成每个指令。如果活动warp次数乘以每个warp的时钟数超过了管线延迟,程序员可以忽略管线延迟。对于该多处理器,八个warp的循环调度在同一个warp的连续指令之间有32个周期。如果程序可以保持每个多处理器256个线程处于活动状态,那么单个连续线程可以隐藏多达32个周期的指令延迟。然而,由于很少有活动warp,处理器管线深度变得可见,可能会导致处理器停滞。
一个具有挑战性的设计问题是为不同warp程序和程序类型的动态混合实现零开销warp调度。指令调度程序必须每四个时钟选择一个warp,以便每个线程每个时钟发出一条指令,相当于每个处理器内核1.0的IPC。因为warp是独立的,所以唯一的依赖关系是来自同一warp的顺序指令。调度器使用寄存器相关性记分板来限定活动线程准备好执行指令的warp,它会优先考虑所有这些准备好的warp,并为问题选择最高优先级的warp。优先级必须考虑warp类型、指令类型以及对所有活动warp公平的愿望。
3.5 管理线程和线程块
多处理器控制器和指令单元管理线程和线程块。控制器接受工作请求和输入数据,并仲裁对共享资源的访问,包括纹理单元、内存访问路径和I/O路径。对于图形工作负载,它同时创建和管理三种类型的图形线程:顶点、几何体和像素。每种图形工作类型都有独立的输入和输出路径。它将这些输入工作类型中的每一种累积并打包为执行同一线程程序的并行线程的SIMT warp,它分配一个自由的warp,为warp线程分配寄存器,并在多处理器中开始warp执行。每个程序都声明其每线程寄存器需求,只有当控制器可以为warp分配请求的寄存器计数时,控制器才启动warp。当warp的所有线程退出时,控制器将解开打包结果并释放warp寄存器和资源。
控制器创建协作线程阵列(cooperative thread array,CTA),将CUDA线程块实现为一个或多个并行线程warp,当它可以创建所有CTA warp并分配所有CTA资源时,它会创建CTA。除了线程和寄存器,CTA还需要分配共享内存和障碍。程序声明所需的容量,控制器等待,直到可以分配这些容量,然后启动CTA。随后,它以warp调度速率创建CTA warp,从而使CTA程序立即以完全的多处理器性能开始执行。控制器监控CTA的所有线程何时退出,并释放CTA共享资源及其warp资源。
协同线程阵列(cooperative thread array,CTA):一组并发线程,它们执行相同的线程程序,并可以协作计算结果。GPU CTA实现CUDA线程块。
3.6 线程指令
SP线程处理器为单个线程执行标量指令,与早期的GPU矢量指令架构不同,后者为每个顶点或像素着色器程序执行四个分量矢量指令。顶点程序通常计算(x,y,z,w)位置向量,而像素着色器程序计算(红、绿、蓝、Alpha)颜色向量。然而,着色器程序变得越来越长,越来越标量化,甚至很难完全占据传统GPU四分量矢量架构的两个组件。实际上,SIMT架构跨32个独立的像素线程进行并行化,而不是并行化一个像素内的四个矢量组件。CUDA C/C++程序主要具有每个线程的标量代码,以前的GPU使用向量打包(例如,组合工作的子向量以获得效率),但会使得调度硬件和编译器复杂化。标量指令更简单且编译器友好,纹理指令仍然基于向量,获取源坐标向量并返回过滤后的颜色向量。
为了支持具有不同二进制微指令格式的多个GPU,高级图形和计算语言编译器生成中间汇编程序级指令(例如Direct3D矢量指令或PTX标量指令),然后将其优化并转换为二进制GPU微指令。NVIDIA PTX(并行线程执行)指令集定义为编译器提供了稳定的目标ISA,并提供了几代GPU与不断发展的二进制微指令集架构的兼容性,优化器很容易将Direct3D矢量指令扩展为多个标量二进制微指令。尽管一些PTX指令扩展为多个二进制微指令,并且多个PTX指令可以折叠成一个二进制微命令,但PTX标量指令几乎可以用标量二进制微指令进行一对一转换。由于中间汇编程序级指令使用虚拟寄存器,优化器分析数据相关性并分配实际寄存器。优化器消除了死代码,在可行时将指令折叠在一起,并优化了SIMT分支的分叉点和聚合点。
指令集体系结构(ISA)
这里描述的线程ISA是Tesla架构PTX ISA的简化版本,是一个基于寄存器的标量指令集,包括浮点、整数、逻辑、转换、特殊函数、流控制、内存访问和纹理操作。下图列出了基本的PTX GPU线程指令,有关详细信息,请参阅NVIDIA PTX规范。
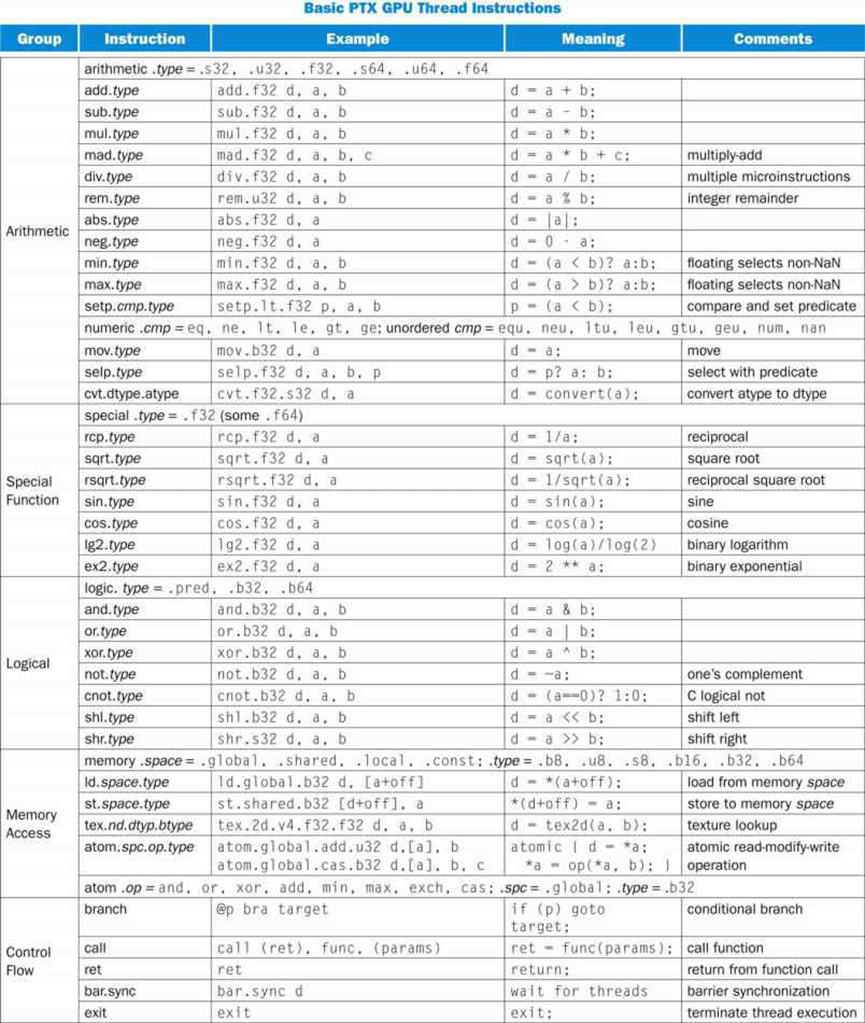
其指令格式为:
opcode.type d, a, b, c;
其中d是目标操作数,a、b、c是源操作数,.type是以下之一:
|
类型 |
.type特定值 |
|
无类型的位8、16、32和64位 |
.b8、.b16、.b32、.b64 |
|
无符号整数8、16、32和64位 |
.u8、.u16、.u22、.u64 |
|
有符号整数8、16、32和64位 |
.s8、.s16、.s32、.s64 |
|
浮点16、32和64位 |
.16、.f32、.f64 |
源操作数是寄存器中的标量32位或64位值、立即数或常量,判断操作数是1位布尔值。目的地是寄存器,存储到内存除外。指令是通过在它们前面加上@p或@!p、 其中p是判断寄存器。内存和纹理指令传输两到四个分量的标量或向量,总计最多128位。PTX指令指定一个线程的行为。
PTX算术指令对32位和64位浮点、有符号整数和无符号整数类型进行操作。当前GPU支持64位双精度浮点,PTX 64位整数和逻辑指令被转换为两个或多个执行32位操作的二进制微指令,GPU特殊功能指令仅限于32位浮点。线程控制流指令包括条件分支、函数调用和返回、线程退出和bar.sync(屏障同步)。条件分支指令@p bra target使用判断寄存器p(或!p)来确定线程是否执行分支,该判断寄存器p先前由比较和设置判断setp指令设置,其他指令也可以基于判断寄存器为真或假。
3.7 内存访问指令
tex指令通过纹理子系统从内存中的1D、2D和3D纹理阵列中提取并过滤纹理样本。纹理提取通常使用插值浮点坐标来处理纹理。一旦图形像素着色器线程计算其像素片段颜色,光栅操作处理器将其与指定(x,y)像素位置的像素颜色混合,并将最终颜色写入内存。
为了支持计算和C/C++语言需求,Tesla PTX ISA实现了内存加载/存储指令。它使用整数字节寻址和寄存器加偏移地址算法,以促进常规编译器代码优化。内存加载/存储指令在处理器中很常见,但在Tesla架构GPU中是一项重要的新功能,因为以前的GPU只提供图形API所需的纹理和像素访问。
对于计算,加载/存储指令访问实现第B.3节中相应CUDA存储空间的三个读/写存储空间:
- 逐线程专用可寻址临时数据的局部内存(在外部DRAM中实现)。
- 共享内存,用于低延迟访问同一个CTA/线程块中协作线程共享的数据(在片上SRAM中实现)。
- 由计算应用程序的所有线程共享的大型数据集的全局存储器(在外部DRAM中实现)。
内存加载/存储指令ld.global、st.global、ld.shared、st.shared、ld.local和st.local分别访问全局、共享和局部内存空间。计算程序使用快速屏障同步指令bar.sync以同步CTA/线程块内通过共享和全局内存彼此通信的线程。
为了提高内存带宽并减少开销,当地址落在同一块中并满足对齐标准时,局部和全局加载/存储指令将来自同一SIMT warp的单个并行线程请求合并为单个内存块请求。与来自单个线程的单独请求相比,合并内存请求可显著提高性能。多处理器的大量线程数,加上对许多未完成的负载请求的支持,有助于覆盖负载,从而使用外部DRAM中实现的局部和全局内存的延迟。
Tesla架构GPU还通过atom.op.u32指令在内存上提供高效的原子内存操作,包括整数操作add、min、max、and、or、xor、exchange和cas(比较和交换)操作,有助于并行缩减和并行数据结构管理。
3.8 线程通信的屏障同步
快速屏障同步允许CUDA程序通过简单调用__syncthreads(),通过共享内存和全局内存频繁通信,作为每个线程间通信步骤的一部分。同步内建函数生成单个bar.sync指令,但在每个CUDA线程块最多512个线程之间实现快速屏障同步是一个挑战。
将线程分组为32个线程的SIMT warp将同步难度降低了32倍。线程在SIMT线程调度程序中的一个屏障处等待,因此它们在等待时不会消耗任何处理器周期。当线程执行一条bar.sync指令,它递增屏障的线程到达计数器,调度器将线程标记为在屏障处等待。一旦所有CTA线程到达,屏障计数器与预期的终端计数相匹配,调度器释放在屏障处等待的所有线程并恢复执行线程。
3.9 流式多处理器(SM)
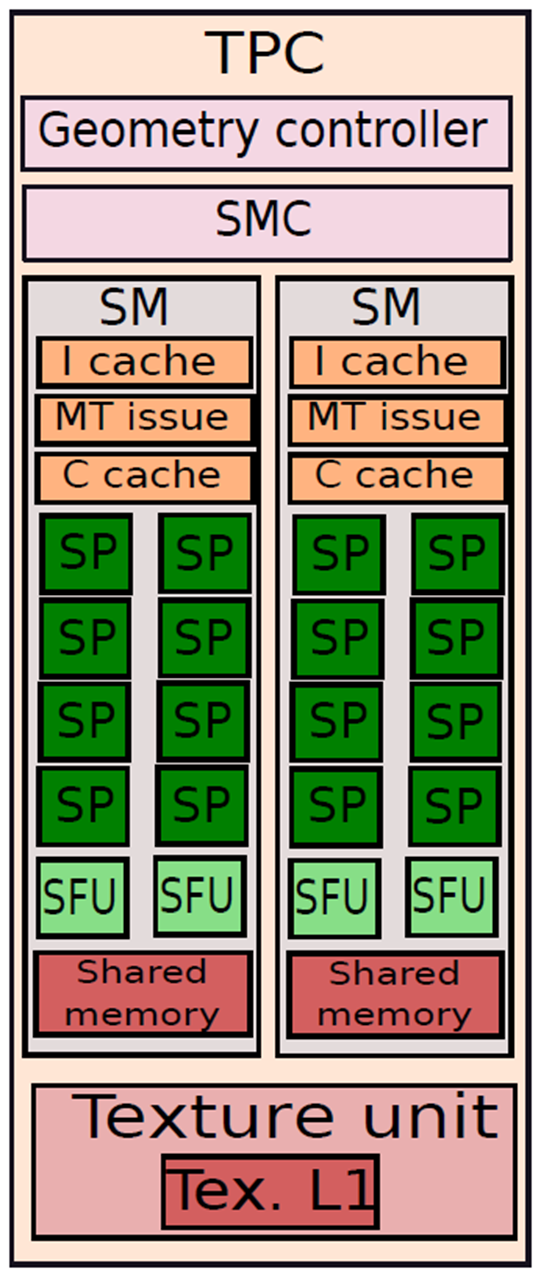
纹理/处理器集群。
上图显示了具有两个SM的TPC的结构。几何控制器在单个核上协调顶点和形状处理,它从内存层次结构中引入顶点数据,指导内核处理它们,然后协调将输出存储到内存层次结构的过程。此外,它还有助于将输出转发到下一个处理阶段。SMC(SM控制器)调度对外部资源的请求,例如,SM中的多个内核可能希望写入DRAM内存或访问纹理单元。在这种情况下,SMC对请求进行仲裁。
现在看看SM的结构。每个SM都有一个I缓存(指令缓存)、一个C缓存(常量缓存)和一个用于多线程工作负载的内置线程调度器(MT Issue Unit)。8个SP核可以访问嵌入在SM中的共享存储器单元,以便在它们之间进行通信。SP核心具有符合IEEE 754的浮点ALU,可以执行常规浮点运算,如加法、减法和乘法。它还支持称为乘法加法的特殊指令,这在图形计算中是非常常见的,此指令计算表达式的值:a*b+c。与FP ALU一起,每个SP都有一个整数ALU,可以执行常规整数指令和逻辑指令,此外,SP核心可以执行内存指令和分支指令。与向量处理器类似,SP核心实现预测指令,意味着他们将执行槽专用于错误路径中的指令,尽管它们被nop指令取代。SP针对速度进行了优化,是整个GPU中速度最快的单元,因为它们实现了一个非常简单的类似RISC的指令集,它主要由基本指令组成。
为了计算更复杂的数学函数,例如超越函数或三角函数,每个SM中有两个特殊的函数单元(SFU)。SFU还具有专门的单元,用于插值片元内的颜色值,GPU使用此功能为每个三角形片段的内部着色。除了专用单元外,SFU还具有用于运行通用代码的常规整数/浮点ALU。
TPC中的两个SM共享一个纹理单元,纹理单元可以同时处理四个线程,并将光栅化后生成的所有三角形与与三角形关联的曲面纹理进行处理。纹理信息存储在纹理单元内的小缓存中,在缓存未命中时,纹理单元可以从相关的二级缓存或从主DRAM存储器获取数据。
现在讨论如何在GPU上执行计算。SM中的每个线程(映射到SP)可以访问逐线程局部内存(保存在外部DRAM上)、共享内存(在SM中的所有线程之间共享,并保存在芯片上)或全局DRAM内存。程序员可以明确指示GPU使用某种内存。
更详细的单个SM结构如下图所示。
单个SM架构。
上图右侧将NVIDIA费米体系结构分解为单个SM的基本组件,这些组件是:
- GPU处理器内核(共32个CUDA内核)。
- Warp调度程序和调度端口。
- 16个加载/存储单元。
- 四个SFU。
- 32k*32位寄存器。
- 共享内存和一级缓存(共64 kB)。
下面详细阐述SM内的各个部件。先阐述双warp调度器(dual warp scheduler)。
如前所述,GPU芯片上的GigaThread全局调度器单元将线程块分配给SM,然后双warp调度器将其处理的每个线程块分解为warp,其中warp是由32个线程组成的束,这些线程从相同的起始地址开始,其线程ID是连续的。一旦发出warp,每个线程都会有自己的指令地址计数器和寄存器集,以允许SM中每个线程的独立分支和执行。
GPU在处理尽可能多的warp以最大限度地利用CUDA内核时效率最高。如下图所示,当双warp调度器和指令调度单元能够每两个时钟周期发出两次warp(Fermi架构)时,SM硬件利用率将达到最大值。如下文所述,结构冲突是SM无法达到最大处理速率的主要原因,而片外内存访问延迟则更容易隐藏。
如果组件列不存在结构冲突,则每个划分的列由16个CUDA核心(*2)、16个加载/存储单元和4个SFU(上图)组成,每个时钟周期可以从两个warp调度器/调度单元中的每一个分配半个warp(16个线程)进行处理。结构冲突由有限的SFU、双精度乘法和分支引起,但是,warp调度程序有一个内置的记分板(scoreboard)来跟踪可用于执行的warp以及结构冲突,使得SM既能避免结构冲突,又能尽可能地隐藏芯片外内存访问延迟。
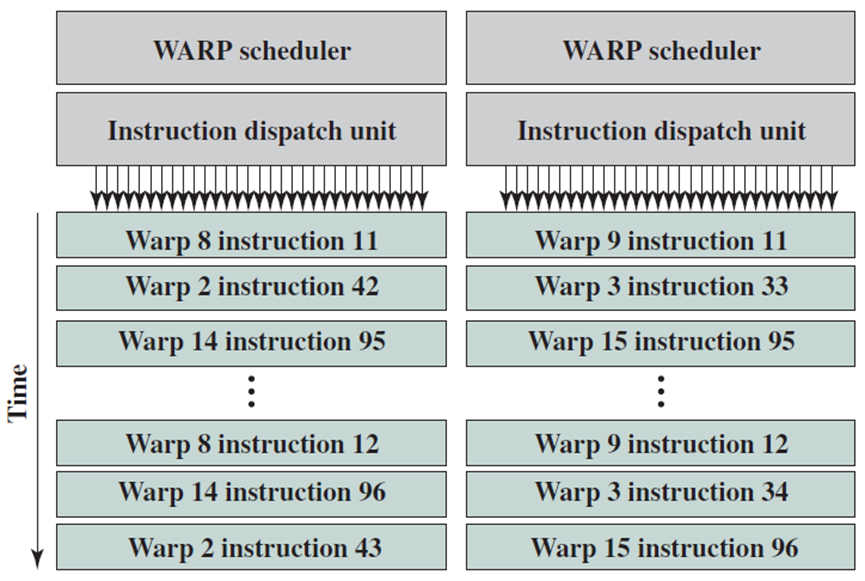
双warp调度器和指令调度单元运行示例。
因此,程序员必须将线程块大小设置为大于SM中CUDA内核的总数,但小于每个块允许的最大线程数,并确保线程块大小(在x和/或y维度)为32的倍数(warp大小),以实现SM的接近最佳利用率。
阐述完双warp调度器,再阐述CUDA核心。
NVIDIA GPU处理器内核也称为CUDA内核,在Fermi架构中,共有32个CUDA核专用于每个SM。每个CUDA核心都有两个独立的管线或数据路径:一个整数(INT)单元管线和一个浮点(FP)单元管线(见上上图),在一个时钟周期内只能使用这些数据路径中的一个。INT单元能够进行32位、64位和扩展精度的整数和逻辑/位运算,FP单元可以执行单精度FP运算,而双精度FP运算需要两个CUDA核。因此,与单精度FP线程相比,仅执行双精度FP操作的线程运行所需的时间是其两倍。通过在每个SM中包含专用的双精度单元以及大多数单精度单元,Kepler架构解决了双精度FP算法的性能影响。幸运的是,CUDA程序员隐藏了线程级FP单精度和双精度操作的管理,但程序员应该意识到使用基于所用GPU的两种精度类型之间可能产生的潜在性能影响。
Fermi架构为CUDA核心的FP单元增加了一项改进,从IEEE 754-1985浮点算术标准升级为IEEE 754-2008标准,是通过使用融合乘法加法(FMA)指令提高乘法加法指令(MAD)的精度来实现的。FMA指令对单精度和双精度算术都有效,Fermi架构仅在FMA指令末尾执行一次舍入,此举不仅提高了结果的准确性,而且执行FMA指令也被压缩到单处理器时钟周期中。因此,每个SM在一个处理器时钟周期内可以进行32次单精度或16次双精度FMA操作。
其它部件说明如下:
- 特殊函数单元(special function unit):每个SM有四个SFU。SFU在一个时钟周期内执行超越运算,如余弦、正弦、倒数和平方根。由于一个SM中只有4个SFU,而一个warp中只有一条指令的32个并行线程,因此完成一个需要SFU的warp需要8个时钟周期,但CUDA处理器以及加载和存储单元仍然可以同时使用。
- 加载和存储单位:SM的16个加载和存储单元中的每一个计算每个时钟周期单个线程的源地址和目标地址,这些地址用于线程希望写入数据或从中读取数据的缓存或DRAM。
- 寄存器、共享内存和L1缓存:每个SM都有自己的(片上)专用寄存器集和共享内存/l1缓存块。关于低延迟片上内存的详细信息和优点如下表。
|
内存类型 |
相对访问时间 |
访问类型 |
范围 |
数据生存期 |
|
寄存器 |
最快,芯片内 |
R/W |
单线程 |
线程 |
|
共享 |
快,芯片内 |
R/W |
块上的所有线程 |
块 |
|
局部 |
比共享和寄存器慢100到150倍,芯片外 |
R/W |
单线程 |
线程 |
|
全局 |
比共享和寄存器慢100到150倍,芯片外 |
R/W |
所有线程和主机 |
应用程序 |
|
固定 |
比共享和寄存器慢100到150倍,芯片外 |
R |
所有线程和主机 |
应用程序 |
|
纹理 |
比共享和寄存器慢100到150倍,芯片外 |
R |
所有线程和主机 |
应用程序 |
尽管Fermi架构每个SM有一个令人印象深刻的32k x 32位寄存器,但每个线程最多分配64x32位的寄存器,如CUDA计算能力2.x版所定义的,这是每个SM允许的最大活动warp数以及每个SM的寄存器数的函数。如上表所示,寄存器和共享内存的最快访问时间只有几纳秒(ns)。如果有任何临时寄存器溢出,数据将首先移动到L1缓存,然后再发送到L2缓存,然后是长访问延迟本地内存(见下图a)。使用一级缓存有助于防止发生数据读/写冲突,因此分配给线程的寄存器中的数据的寿命仅与线程的寿命相同。
Fermi内存架构。
与当代多核微处理器(如CPU)相比,专用于SM的GPU处理器核心的可寻址片上共享内存是一种独特的配置,这些当代架构具有专用的片上L1缓存和每个内核一组寄存器,但它们通常没有片上可寻址内存。相反,专用内存管理硬件在没有程序员控制的情况下调节高速缓存和主内存之间的数据移动,与GPU架构有很大不同。
共享内存被添加到GPU架构中,专门用于辅助GPGPU应用程序。优化共享内存的使用可以通过消除对片外内存的不必要的长延迟访问,显著提高GPGPU应用程序的速度和性能。尽管每个SM的共享内存大小很小(最大配置为48 kB),但它的访问延迟非常低,比全局内存少100到150倍(见上表)。因此,共享内存可以通过三种主要方式加速并行处理任务:
- 块的所有线程多次重复使用共享内存数据(如用于矩阵-矩阵乘法的数据块)。
- 使用块的选择线程(基于特定ID)将数据从全局内存传输到共享内存,从而消除了对相同内存位置的冗余读取和写入。
- 如果可能,用户可以通过确保访问被合并来优化对全局内存的数据访问。
所有这些点也有助于减少片外内存带宽限制问题。SM共享内存中数据的生命周期与在其上处理的线程块的生命周期一样长。因此,一旦块的所有线程完成,SM共享内存中的数据就不再有效。
尽管共享内存的使用将提供最佳运行时间,但在某些应用程序中,在编程阶段内存访问是未知的,拥有更多可用的L1缓存(最大设置为48 kB)将获得最佳结果。此外,L1缓存有助于防止寄存器溢出,而不是直接进入本地(片外)DRAM内存。两级缓存层次结构每个SM一个L1缓存,以及跨芯片、SM共享的L2缓存提供了与传统多核微处理器相同的好处。
需要认识到,在GPU编程中,理解内存类型具有举足轻重的作用。
程序员必须了解各种GPU内存的细微差别,特别是每种内存类型的可用大小、相对访问时间和可访问性限制,以使用CUDA进行正确高效的代码开发。GPGPU编程所需的方法与针对CPU的程序开发方法大不相同,其中所使用的特定数据存储硬件(文件I/O除外)对程序员来说是隐藏的。
例如,在GPU架构中,分配给CUDA内核的每个线程都有自己的寄存器集,因此一个线程无法访问另一个线程的寄存器,无论是否在同一个SM中。特定SM中的线程可以相互协作(通过数据共享)的唯一方式是通过共享内存(下图),通常通过程序员仅分配SM的某些线程来写入其共享内存的特定位置来实现,从而防止写入冲突或浪费周期(例如许多线程从全局内存读取相同的数据并将其写入相同的共享内存地址)。在特定SM的所有线程被允许从刚刚写入的共享内存中读取之前,需要对该SM的所有的线程进行同步,以防止写入后读取(RAW)数据冲突。
GPU基本架构的CUDA表示。
3.10 流处理器(SP)
多线程流处理器(SP)核心是多处理器中的主要线程指令处理器,其寄存器文件(RF)为多达64个线程提供1024个标量32位寄存器。它执行所有基本的浮点运算,包括add.f32、mul.f32、mad.f32(浮动乘加)、min.f32, max.f32和setp.f32(浮动比较和设置判断)。浮点加法和乘法运算与IEEE 754标准兼容,适用于单精度FP数,包括非整数(NaN)和无穷大值。SP核心还实现了所有32位和64位整数运算、比较、转换和逻辑PTX指令。
浮点加法和乘法运算采用IEEE舍入调,甚至作为默认舍入模式。mad.f32浮点乘法加法运算执行带截断的乘法,然后执行带舍入到最接近偶数的加法。SP将输入非正规操作数刷新为符号保留零,舍入后,将目标输出指数范围下溢的结果刷新为符号保留零。
3.11 特殊功能单元(SFU)
某些线程指令可以与SP上执行的其他线程指令同时在SFU上执行。SFU实现了特殊函数指令,该指令计算32位浮点逼近的倒数、倒数平方根和关键超越函数,它还为像素着色器实现32位浮点平面属性插值,提供颜色、深度和纹理坐标等属性的精确插值。
每个流水线SFU每个周期生成一个32位浮点特殊函数结果,每个多处理器的两个SFU以八个SP的简单指令速率的四分之一执行特殊功能指令。SFU还与八个SP同时执行mul.f32乘法指令,将具有适当指令混合的线程的峰值计算率提高到50%。
对于功能评估,Tesla架构SFU采用基于增强的最小极大近似的二次插值来逼近倒数、倒数平方、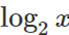 、2x和sin/cos函数,函数计算的精度范围从22到24个尾数位。
、2x和sin/cos函数,函数计算的精度范围从22到24个尾数位。
3.12 与其他多处理器相比
与x86 SSE等SIMD矢量体系结构相比,SIMT多处理器可以独立执行单个线程,而不是总是在同步组中一起执行它们。SIMT硬件在独立线程之间找到数据并行性,而SIMD硬件要求软件在每个向量指令中明确表示数据并行性。当线程采用相同的执行路径时,SIMT机器同步执行32个线程的warp,但当它们分开时,可以独立执行每个线程。这一优势非常明显,因为SIMT程序和指令只描述单个独立线程的行为,而不是四个或更多数据通道的SIMD数据向量。然而,SIMT多处理器具有类似于SIMD的效率,将一个指令单元的面积和成本扩展到32个warp线程和8个流处理器核心。SIMT提供了SIMD的性能和多线程的生产力,避免了为边缘条件和部分发散显式编码SIMD向量的需要。
SIMT多处理器的开销很小,因为它是带有硬件屏障同步的硬件多线程,允许图形着色器和CUDA线程表达非常细粒度的并行性。图形和CUDA程序使用线程来表示每线程程序中的细粒度数据并行性,而不是强迫程序员将其表示为SIMD向量指令。与矢量代码相比,开发标量单线程代码更简单、更高效,SIMT多处理器以类似SIMD的效率执行代码。
将八个流处理器核心紧密耦合到一个多处理器中,然后实现可扩展数量的多处理器,从而形成由多处理器组成的两级多处理器。CUDA编程模型通过为细粒度并行计算提供单个线程,并为粗粒度并行操作提供线程块网格,从而利用了两级层次结构,同一线程程序可以提供细粒度和粗粒度操作。相反,具有SIMD向量指令的CPU必须使用两种不同的编程模型来提供细粒度和粗粒度操作:不同内核上的粗粒度并行线程,以及用于细粒度数据并行的SIMD向量。
3.13 多线程多处理器结论
基于Tesla架构的示例GPU多处理器是高度多线程的,同时执行多达512个轻量级线程,以支持细粒度像素着色器和CUDA线程。它使用了SIMD架构和多线程的一种变体,称为SIMT(单指令多线程),以有效地将一条指令广播到32个并行线程的warp中,同时允许每个线程独立地分支和执行。每个线程在八个流处理器(SP)内核之一上执行其指令流,这些内核最多有64个线程。
PTX ISA是一种基于寄存器的加载/存储标量ISA,用于描述单个线程的执行。由于PTX指令被优化并转换为特定GPU的二进制微指令,因此硬件指令可以快速发展,而不会中断生成PTX指令的编译器和软件工具。
3.14 分块渲染(Binned Rendering)
通常将光栅化定义为将屏幕坐标几何图元直接转换为像素片段的过程,但是,也可以将光栅化到更大的屏幕区域,例如n×n像素块。GeForce 9800 GTX光栅化器就是一个例子,它输出2×2个四边形片段以简化纹理重映射计算。分块渲染(Binned Rendering,亦称装箱渲染)将光栅化分为两个阶段:第一阶段输出中等大小的分块片段,每个片段对应于屏幕坐标中的8×8、16×16或32×32像素网格,随后是第二阶段,该第二阶段将每个分块片段减少为像素片段。当然,平铺片段包括从屏幕坐标图元导出的信息,以便第二阶段光栅化可以产生正确的像素片段。
分块渲染实际上将整个渲染过程分为两个阶段,对应于光栅化的两个阶段。在第一阶段,通过分块光栅化处理场景,并将生成的分块片段分类到各个分格中,每个分格对应于每个屏幕分块。只有在第一阶段完成之后(即在生成了整个场景的分块片段并将其分类到箱子中之后),第二阶段才开始。在第二阶段,每个bin都被单独处理,直到完成,产生一个n×n的像素块,并将其存储在帧缓冲区中。
分块渲染有几个吸引人的特性:
- 局部内存:帧缓冲区数据一致性的绝对保证,仅访问分块中的像素,允许在局部内存中处理像素,而不是从主内存缓存。功耗和主内存周期都可节省,使得分块渲染成为移动设备的一个有吸引力的解决方案。
- 全场景抗锯齿:回想一下,多采样抗锯齿需要在每个像素存储多个颜色和深度采样。由于通过增加采样数提高了质量,因此当渲染到整个帧缓冲区时,存储和带宽都变得非常昂贵,但当渲染仅限于一小块像素时,它们仍然很经济。甚至更高级的渲染算法,如透明表面的顺序无关渲染,都可以通过巧妙地使用局部内存来支持。
- 延迟着色:将渲染限制在一小块像素上解决了延迟着色的关键限制:需要过多的内存存储和带宽,以及与多样本抗锯齿不兼容。
分块渲染的优点是引人注目的,但目前还没有PC级GPU实现它。最根本的原因是,分块渲染与管线Direct3D和OpenGL架构的差异太大,说抽象距离太大。通常,过度的抽象距离会导致产品具有混杂的性能特征(预期快的操作是慢的,预期慢的操作是快的)或与指定操作的细微偏差。遇到的实际问题包括:
- 过度延迟:以前的分块渲染系统,如北卡罗来纳大学教堂山分校开发的PixelPlanes 5系统,增加了全帧延迟时间。
- 较差的多pass操作:Direct3D和OpenGL鼓励先进的多pass渲染技术,在分块实现中,每个最终帧需要多次两遍操作。例如,通过1)渲染在反射中可见的场景,2)将该图像加载为纹理,3)使用适当扭曲的纹理图像渲染表面来渲染来自表面的反射。一些分块渲染系统无法支持此类操作,其他的虽支持但表现不佳。
- 无边界内存需求:虽然分块渲染将像素存储限制为单个块所需的存储,但分块本身所需的内存会随着场景复杂性而增加。OpenGL和Direct3D都没有场景复杂度限制,因此完全确认的实现需要无限的内存(显然不可能),或者必须引入复杂度来处理有限块存储不足的情况。
这些复杂性已经足以将binned渲染排除在主流PC GPU之外。但是最近的实现趋势,特别是使用时间共享的单个计算引擎来实现所有管线着色阶段,可能会克服一些困难。
4 并行内存系统
在GPU本身之外,内存子系统是图形系统性能的最重要决定因素,图形工作负载需要非常高的内存传输速率。像素写入和混合(读取-修改-写入)操作、深度缓冲区读取和写入、纹理贴图读取,以及命令和对象顶点和属性数据读取,构成了大部分内存流量。
现代GPU是高度并行的,例如GeForce 8800可以在600 MHz下处理每个时钟32个像素,每个像素通常需要4字节像素的颜色读写和深度读写。通常读取平均两个或三个四字节的纹素,以生成像素的颜色,对于典型情况,每个时钟需要28字节乘以32像素=896字节,显然对内存系统的带宽需求是巨大的。
为了满足这些要求,GPU内存系统具有以下特点:
- 它们很宽,意味着GPU和它的内存设备之间有大量的引脚来传输数据,而内存阵列本身包括许多DRAM芯片来提供全部的数据总线宽度。
- 它们速度很快,意味着使用积极的信令技术来最大化每引脚的数据速率(比特/秒)。
- GPU寻求使用每个可用周期来向或从内存阵列传输数据。为了实现这一点,GPU特别不以最小化内存系统的延迟为目标。高吞吐量(利用效率)和短延迟从根本上来说是相冲突的。
- 使用的压缩技术既有程序员必须意识到的有损压缩技术,也有应用程序不可见的无损压缩技术。
- 缓存和工作合并结构用于减少所需的片外流量,并确保尽可能充分地使用移动数据所花费的周期。
4.1 显存结构
虽然DRAM通常被视为一个扁平的字节数组,但其内部结构要复杂得多。对于像GPU这样的高性能应用程序,非常有必要深入地理解它。从下往上大致看,VRAM由以下部分组成:
- R行乘以C列的内存平面(memory plane),每个单元为一位。
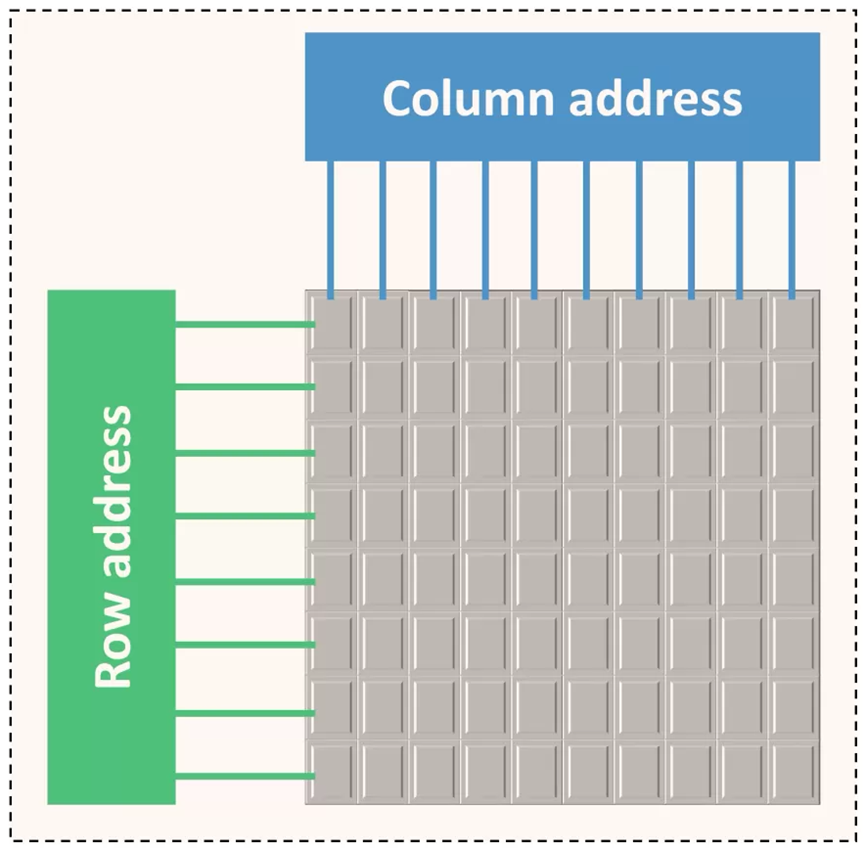
- 由32、64或128个并行使用的内存平面组成的内存体(memory bank)——这些平面通常分布在多个芯片上,其中一个芯片包含16或32个内存平面。bank中的所有页面都连接到行寻址系统(列也是如此),并且这些页面由命令信号和每行/列的地址控制。bank中的行和列越多,地址中需要使用的位就越多。
- 由若干个[2、4或8]个memory bank连接在一起并由地址位选择的内存排(memory rank)——给定内存平面的所有memory bank位于同一芯片中。
- 由一个或两个连接在一起并由芯片选择线选择的memory rank组成的内存子分区(memory subpartition)——rank的行为类似于bank,但不必具有统一的几何结构,而是在单独的芯片中。
- 由一个或两个稍微独立的memory subpartition组成了内存分区(memory partition)。
- 整个VRAM由几个[1-8]个memory partition组成。
以上数量会因不同的GPU架构和家族而不同。
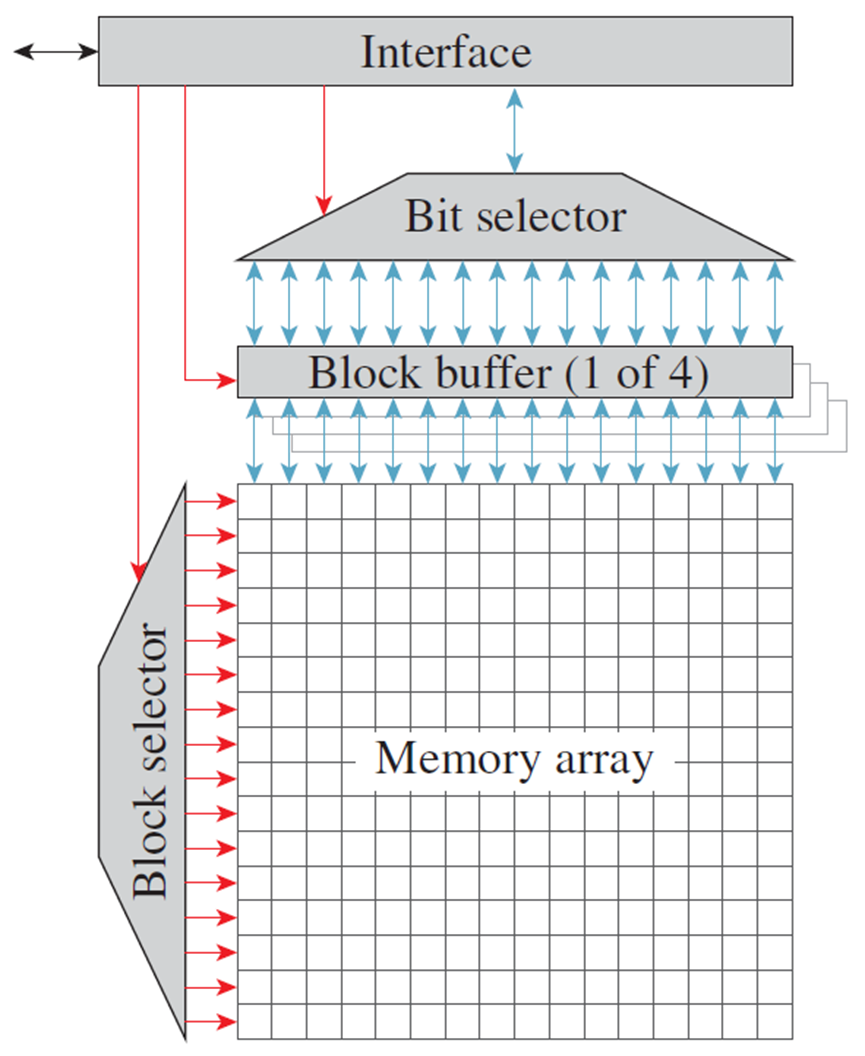
简化GDDR3存储器电路的结构图。为了提高清晰度,实际存储容量(十亿位)减少到256位,实现为16个16位块(也称为行)的阵列。到达块左边缘的红色箭头表示控制路径,而到达块顶部和底部的蓝色箭头表示数据路径。
DRAM最基本的单元是内存平面,它是按所谓的列和行组织的二维位数组:
column
row 0 1 2 3 4 5 6 7
0 X X X X X X X X
1 X X X X X X X X
2 X X X X X X X X
3 X X X X X X X X
4 X X X X X X X X
5 X X X X X X X X
6 X X X X X X X X
7 X X X X X X X X
buf X X X X X X X X
内存平面包含一个缓冲区,该缓冲区可容纳整个行。在内部,DRAM通过缓冲区以行为单位进行读/写。因此有几个后果:
- 在对某个位进行操作之前,必须将其行加载到缓冲区中,会很慢。
- 处理完一行后,需要将其写回内存数组,也很慢。
- 因此,访问新行的速度很慢,如果已经有一个活动行,访问速度甚至更慢。
- 在一段不活动时间后,抢先关闭一行通常很有用——这种操作称为precharging(预充电?)一个bank。
- 但是,可以快速访问同一行中的不同列。
由于加载列地址本身比实际访问活动缓冲区中的位花费更多的时间,所以DRAM是以突发方式访问的,即对活动行中1-8个相邻位的一系列访问,通常突发中的所有位都必须位于单个对齐的8位组中。内存平面中的行和列的数量始终是2的幂,并通过行选择和列选择位的计数来衡量[即行/列计数的log2],通常有8-10列位和10-14行位。内存平面被组织在bank中,bank由两个内存平面的幂组成。内存平面是并行连接的,共享地址和控制线,只有数据/数据启用线是分开的。这有效地使内存bank类似于由32位/64位/128位内存单元组成的内存平面,而不是单个位——适用于平面的所有规则仍然适用于bank,但操作的单元比位大。单个存储芯片通常包含16或32个存储平面,用于单个bank,因此多个芯片通常连接在一起以形成更宽的bank。
一个内存芯片包含多个[2、4或8]个bank,使用相同的数据线,并通过bank选择线进行多路复用。虽然在bank之间切换比在一行中的列之间切换要慢一些,但要比在同一bank中的行之间切换快得多。因此,一个内存bank由(MEMORY_CELL_SIZE / MEMORY_CELL_SIZE_PER_CHIP)内存芯片组成。一个或两个通过公共线(包括数据)连接的内存列,芯片选择线除外,构成内存子分区。在rank之间切换与在bank中的列组之间切换具有基本相同的性能后果,唯一的区别是物理实现和为每个rank使用不同数量行选择位的可能性(尽管列计数和列计数必须匹配)。存在多个bank/rank的后果:
- 确保一起访问的数据要么属于同一行,要么属于不同的bank,这一点很重要(以避免行切换)。
- 分块内存布局的设计使分块大致对应于一行,相邻的分块从不共享一个bank。
内存子分区在GPU上有自己的DRAM控制器。1或2个子分区构成一个内存分区,它是一个相当独立的实体,具有自己的内存访问队列、自己的ZROP和CROP单元,以及更高版本卡上的二级缓存。所有内存分区与crossbar逻辑一起构成了GPU的整个VRAM逻辑,分区中的所有子分区必须进行相同的配置,GPU中的分区通常配置相同,但在较新的卡上则不是必需的。子分区/分区存在的后果:
- 与bank一样,可以使用不同的分区来避免相关数据的行冲突。
- 与bank不同,如果(子)分区没有得到同等利用,带宽就会受到影响。因此,负载平衡非常重要。
虽然内存寻址高度依赖于GPU系列,但这里概述了基本方法。内存地址的位按顺序分配给:
- 识别内存单元中的字节,因为无论如何都必须访问整个单元。
- 多个列选择位,以允许突发(burst)。
- 分区/子分区选择-以低位进行,以确保良好的负载平衡,但不能太低,以便在单个分区中保留相对较大的tile,以利于ROP。
- 剩余列选择位。
- 所有/大部分bank选择位,有时是排名选择位,以便相邻地址不会导致行冲突。
- 行位(row bit)。
- 剩余的bank位或rank位,有效地允许将VRAM拆分为两个区域,在其中一个区域放置颜色缓冲区,在另一个区域放置zeta缓冲区,这样它们之间就不会有行冲突。
GPU必须考虑DRAM的独特特性。DRAM芯片在内部被布置为多个(通常为四到八个)存储体(bank),其中每个bank包括2次幂数的行(通常为16384),并且每行包含2次幂位数的位(通常为8192)。DRAM对其控制处理器施加了各种时序要求,例如激活一行需要几十个周期,但一旦激活,该行内的位可以每四个时钟随机访问一个新的列地址。双倍数据速率(DDR)同步DRAM在接口时钟的上升沿(rising edge)和下降沿(falling edge)传输数据(下面两图),因此1GHz时钟DDR DRAM以每数据引脚每秒2千兆比特的速度传输数据。图形DDR DRAM通常有32个双向数据引脚,因此每个时钟可以从DRAM读取或写入8个字节。
单ank和双rank对比。
单速率、双速率、四速率对比图。
GPU内部有大量的内存流量生成器。逻辑图形管线的不同阶段都有自己的请求流:命令和顶点属性提取、着色器纹理提取和加载/存储,以及像素深度和颜色读写。在每个逻辑阶段,通常有多个独立的单元来提供并行吞吐量,都是独立的内存请求者。当在内存系统中查看时,有大量不相关的请求正在运行,是与DRAM优选的参考模式(pattern)的自然不匹配。一种解决方案是GPU的内存控制器为不同的DRAM组保持单独的流量堆,并等待特定DRAM行有足够的流量等待,然后激活该行并同时传输所有流量。请注意,累积未决请求虽然有利于DRAM行位置,从而有效地使用数据总线,但会导致较长的平均等待时间,正如请求者等待其他请求所看到的那样。设计必须注意,任何特定的请求都不会等待太长时间,否则一些处理单元可能会等待数据,最终导致相邻处理器闲置。
GPU内存子系统被布置为多个存储器分区,每个内存分区包括完全独立的内存控制器和一个或两个DRAM设备,这些DRAM设备由该分区完全和独占拥有。为了实现最佳的负载平衡,并因此接近n个分区的理论性能,地址在所有内存分区之间均匀地精细交错,分区交错步长通常是几百字节的块,内存分区的数量旨在平衡处理器和其他内存请求者的数量。
4.2 缓存
GPU工作负载通常具有数百兆字节量级的非常大的工作集,以生成单个图形帧。与CPU不同,在足够大的芯片上构建缓存以容纳接近图形应用程序全部工作集的内容是不现实的。尽管CPU可以假设非常高的缓存命中率(99.9%或更高),但GPU的命中率接近90%,因此必须应对运行中的许多未命中。虽然CPU可以合理地设计为在等待罕见的缓存未命中时停滞,但GPU需要处理混合的未命中和命中。称之为流缓存架构(streaming cache architecture)。
GPU缓存必须为其客户端提供非常高的带宽。考虑纹理缓存的情况,典型的纹理单元可以为每个时钟周期四个像素中的每一个执行两个双线性插值,并且GPU可以具有许多这样的纹理单元,所有这些纹理单元都独立地操作。每个双线性插值需要四个单独的纹素,每个纹素可能是64位值,四个16位组件是典型的,因此总带宽为2×4×4×64=2048位/时钟。每个单独的64位纹素都是独立寻址的,因此缓存需要每个时钟处理32个唯一的地址。这自然有利于SRAM阵列的多组和/或多端口布置。
4.3 MMU
现代GPU能够将虚拟地址转换为物理地址。在GeForce 8800上,所有处理单元都在40位虚拟地址空间中生成内存地址。对于计算,加载和存储线程指令使用32位字节地址,通过添加40位偏移量将其扩展为40位虚拟地址。内存管理单元执行虚拟到物理地址转换;硬件从本地内存中读取页表,以代表分布在处理器和渲染引擎之间的翻译后备缓冲区的层次结构来响应未命中。除了物理页面位之外,GPU页面表条目还指定了每个页面的压缩算法,页面大小从4到128 KB不等。
CUDA公开了不同的内存空间,以允许程序员以最佳性能的方式存储数据值。下图是CPU和GPU内存请求路线:
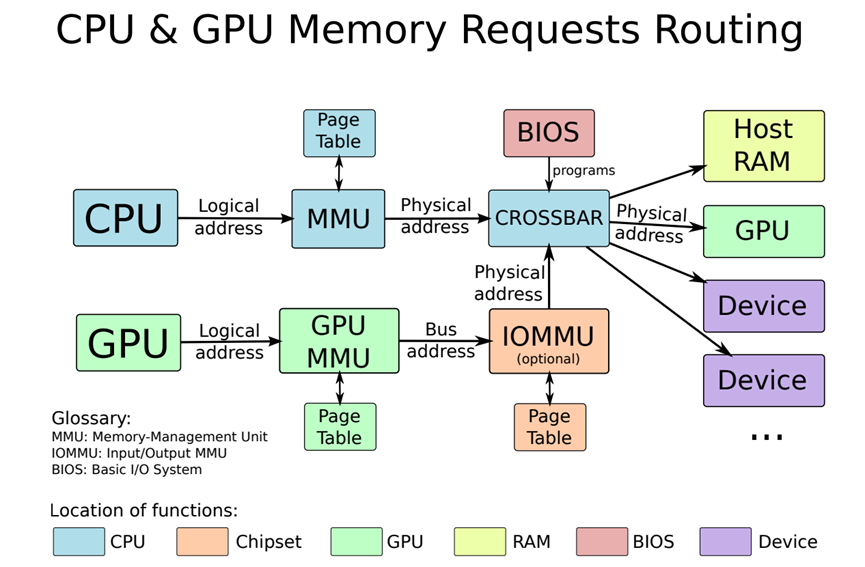
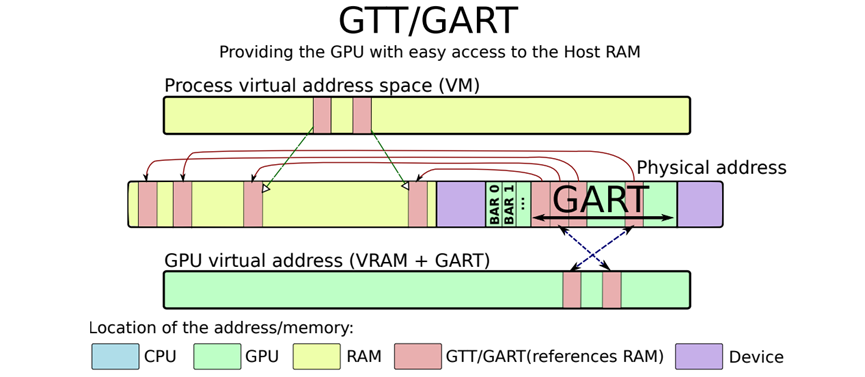
GTT/GART作为CPU-GPU共享缓冲区用于通信:
后面小节的讨论以NVIDIA Tesla架构GPU为基准。
4.4 全局内存
全局内存存储在外部DRAM中,不是任何一个物理流多处理器(SM)的局部,因为它用于不同网格中不同CTA(线程块)之间的通信。事实上,引用全局内存中某个位置的许多CTA可能不会同时在GPU中执行,通过设计,在CUDA中,程序员不知道CTA执行的相对顺序。由于地址空间均匀分布在所有内存分区之间,因此必须有从任何流式多处理器到任何DRAM分区的读/写路径。
不同线程(和不同处理器)对全局内存的访问不能保证具有顺序一致性。线程程序看到一个宽松的(relaxed)内存排序模型,在线程中,内存对同一地址的读写顺序被保留,但对不同地址的访问顺序可能不会被保留。不同线程请求的内存读取和写入是无序的,在CTA中,屏障同步指令bar.sync可用于在CTA的线程之间获得严格的内存排序。membar线程指令提供了一个内存屏障/栅栏操作,该操作提交先前的内存访问,并在继续之前使其他线程可见。线程还可以使用原子内存操作来协调它们共享的内存上的工作。
4.5 共享内存
逐CTA共享内存仅对属于该CTA的线程可见,并且共享内存仅从创建CTA到终止CTA期间占用存储空间,因此共享内存可以驻留在芯片上。这种方法有以下好处:
- 共享内存流量不需要与全局内存引用所需的有限片外带宽竞争。
- 在芯片上构建非常高带宽的内存结构以支持每个流式多处理器的读/写需求是可行的。事实上,共享内存与流式多处理器紧密耦合。
每个流式多处理器包含八个物理线程处理器。在一个共享内存时钟周期内,每个线程处理器可以处理两个线程的指令,因此每个时钟必须处理16个线程的共享内存请求。因为每个线程都可以生成自己的地址,并且地址通常是唯一的,所以共享内存是使用16个可独立寻址的SRAM bank构建的。对于常见的访问模式,16个bank足以保持吞吐量,但也可能存在极端情况,例如所有16个线程可能恰好访问一个SRAM组上的不同地址。必须能够将请求从任何线程通道路由到任何SRAM组,因此需要16*16的互连网络。
4.6 局部内存
逐线程局部内存是仅对单个线程可见的专用内存。局部内存在架构上大于线程的寄存器文件,程序可以将地址计算到局部内存中。为了支持局部内存的大量分配(回想一下,总分配是每线程分配乘以活动线程数),局部内存分配在外部DRAM中。虽然全局和逐线程局部内存驻留在芯片外,但它们非常适合缓存在芯片上。
4.7 常量内存
常量内存对SM上运行的程序是只读的(可以通过命令写入GPU),存储在外部DRAM中,并缓存在SM中。因为通常SIMT warp中的大多数或所有线程都是从常量内存中的同一地址读取的,所以每个时钟的单个地址查找就足够了。常量缓存被设计为向每个warp中的线程广播标量值。
4.8 纹理内存
纹理内存保存大型只读数据数组,用于计算的纹理与用于3D图形的纹理具有相同的属性和功能。虽然纹理通常是二维图像(像素值的2D阵列),但也可以使用1D(线性)和3D(体积)纹理。
计算程序使用tex指令引用纹理,操作数包括用于命名纹理的标识符,以及基于纹理维度的一个、两个或三个坐标。浮点坐标包括指定样本位置的分数部分,通常位于纹素位置之间。在将结果返回到程序之前,非整数坐标调用四个最接近值(对于2D纹理)的双线性加权插值。
纹理提取缓存在流缓存层次结构中,该层次结构旨在优化数千个并发线程的纹理提取吞吐量。一些程序使用纹理提取作为缓存全局内存的方法。
4.9 表面(Surface)
表面是一维、二维或三维像素值阵列及其相关格式的通用术语,定义了多种格式,例如4个8位RGBA整数分量或4个16位浮点分量。程序内核不需要知道表面类型,tex指令根据表面格式将其结果值重新转换为浮点。
4.10 加载/存储访问
带有整数字节寻址的加载/存储指令允许用C和C++等传统语言编写和编译程序,CUDA程序使用加载/存储指令来访问内存。
为了提高内存带宽并减少开销,当地址位于同一块中并满足对齐标准时,局部和全局加载/存储指令将来自同一warp的单个并行线程请求合并为单个内存块请求。将单个小内存请求合并为大数据块请求可以显著提高单独请求的性能,大的线程数,加上支持许多未完成的负载请求,有助于覆盖外部DRAM中实现的局部和全局内存的负载使用延迟。
4.11 ROP
NVIDIA Tesla架构GPU包括可扩展流处理器阵列(SPA)和可扩展内存系统,可扩展流处理阵列执行GPU的所有可编程计算,可扩展内存系统包括外部DRAM控制和固定功能光栅操作处理器(Raster Operation Processor,ROP),可直接在内存上执行颜色和深度帧缓冲操作。每个ROP单元与特定的内存分区配对,ROP分区通过互连网络被SM填充数据。每个ROP负责深度和模板测试和更新,以及颜色混合。ROP和内存控制器协作实现无损颜色和深度压缩(高达8:1),以减少外部带宽需求,ROP单元还对内存执行原子操作。
5 浮点运算
如今的GPU使用IEEE 754兼容的单精度32位浮点运算在可编程处理器内核中执行大多数算术运算,早期GPU的定点算法是由16位、24位和32位浮点,然后是IEEE 754兼容的32位浮点继承的。GPU中的一些固定功能逻辑,如纹理过滤硬件,继续使用专有的数字格式,部分GPU还提供IEEE 754兼容的双精度64位浮点指令。
5.1 支持的格式
IEEE 754浮点算术标准规定了基本格式和存储格式。GPU使用两种基本的计算格式,32位和64位二进制浮点,通常称为单精度和双精度,该标准还指定了16位二进制存储浮点格式,半精度。GPU和Cg着色语言采用窄16位半数据格式,以实现高效的数据存储和移动,同时保持高动态范围,GPU在纹理过滤单元和光栅操作单元内以半精度执行许多纹理过滤和像素混合计算。Industrial Light and Magic[2003]开发的OpenEXR高动态范围图像文件格式在计算机成像和运动图像应用中使用相同的半格式颜色分量值。
半精度(half precision):一种16位二进制浮点格式,具有1个符号位、5位指数、10位小数和一个隐含整数位。
5.2 基本算术
GPU可编程内核中常见的单精度浮点运算包括加法、乘法、乘法、最小值、最大值、比较、设置判断以及整数和浮点数之间的转换,浮点指令通常为求反和绝对值提供源操作数修饰符。
乘加(multiply-add,MAD):一种执行复合运算的单浮点指令——乘法后相加。
今天大多数GPU的浮点加法和乘法运算都与IEEE 754标准兼容,适用于单精度FP数,包括非数字(NaN)和无穷大值。FP加法和乘法运算使用IEEE舍入到最接近,甚至作为默认舍入模式。为了提高浮点指令吞吐量,GPU通常使用复合乘加指令(mad),mad运算执行带截断的FP乘法,然后执行带舍入到最接近偶数的FP加法。它在一个发出周期内提供两个浮点运算,而不需要指令调度器调度两个单独的指令,但计算没有融合,并在加法之前截断乘积,使得它不同于后面讨论的融合乘加(fused multiply-add)指令。GPU通常会将非规范化的源操作数刷新为符号保留零,并在舍入后将目标输出指数范围下溢的结果刷新为符号保持零。
5.3 特殊算术
GPU提供硬件来加速特殊函数计算、属性插值和纹理过滤,特殊函数指令包括余弦、正弦、二元指数、二元对数、倒数和平方根倒数。属性插值指令提供了从平面方程求值导出的像素属性的有效生成,前面介绍的特殊函数单元(SFU)计算特殊函数并插值平面属性。
特殊函数单元(special function unit,SFU):计算特殊函数和插值平面属性的硬件单元。
有几种方法可用于执行硬件中的特殊功能。已经表明,基于增强的Minimax逼近的二次插值是一种非常有效的硬件函数逼近方法,包括倒数、倒数平方根、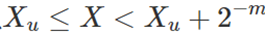 。
。
可以总结SFU二次插值的方法。对于具有n位有效位的二进制输入操作数X,有效位分为两部分:Xu是包含m位的上部,Xl是包含n-m位的下部。较高的m位Xu用于查询一组三个查找表,以返回三个有限域系数C0、C1和C2。要近似的每个函数都需要一组唯一的表,这些系数用于近似范围内的给定函数f(X),通过计算表达式:
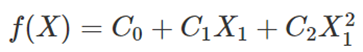
每个函数计算的精度范围为22到24个有效位,示例功能统计如下图所示。
IEEE 754标准规定了除法和平方根的精确舍入要求,但对于许多GPU应用程序,不需要严格遵守,相反,更高的计算吞吐量比最后一位精度更重要。对于SFU特殊函数,CUDA数学库提供了全精度函数和具有SFU指令精度的快速函数。
GPU中的另一种特殊算术运算是属性插值,通常为构成要渲染的场景的图元的顶点指定关键点属性,例如颜色、深度和纹理坐标。必须根据需要在(x,y)屏幕空间内插入这些属性,以确定每个像素位置的属性值,(x,y)平面中给定属性U的值可以使用以下形式的平面方程表示:
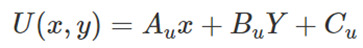
其中A、B和C是与每个属性U关联的插值参数,插值参数A、B、C都表示为单精度浮点数。
考虑到像素着色器处理器中同时需要函数求值器和属性插值器,可以设计一个执行这两个函数以提高效率的SFU。两个函数都使用乘积和运算来插值结果,两个函数中要求和的项数非常相似。
纹理映射和过滤是GPU中另一组关键的专用浮点算术运算。用于纹理映射的操作包括:
1.接收当前屏幕像素(x,y)的纹理地址(s,t),其中s和t是单精度浮点数。
2.计算细节级别以识别正确的纹理MIPmap级别。
3.计算三线性插值分数。
4.缩放所选MIP映射级别的纹理地址(s,t)。
5.访问存储器并检索期望的纹素(纹理元素)。
6.对纹素执行过滤操作。
MIP-map:包含不同分辨率的预计算图像,用于提高渲染速度和减少伪影。
纹理映射对于全速操作需要大量的浮点计算,其中大部分是以16位半精度完成的,例如除了传统的IEEE单精度浮点指令外,GeForce 8800 Ultra还为纹理映射指令提供了约500GFLOPS的专有格式浮点计算。
浮点加法和乘法运算硬件是完全管线化的,延迟被优化以平衡延迟和面积。虽然采用管线,但特殊函数的吞吐量小于浮点加法和乘法运算,特殊函数的四分之一速度吞吐量是现代GPU的典型性能,一个SFU由四个SP核共享。相比之下,CPU对于类似的功能(如除法和平方根)通常具有明显更低的吞吐量,尽管结果更准确。属性插值硬件通常完全管线化,以启用全速像素着色器。
5.4 双精度
Tesla T10P等GPU也支持硬件中的IEEE 754 64位双精度操作。双精度标准浮点算术运算包括加法、乘法以及不同浮点和整数格式之间的转换。2008年IEEE 754浮点标准包括融合乘加(fused-multiply-add,FMA)操作的规范,FMA操作执行浮点乘法,然后执行加法,并进行一次舍入,融合的乘法和加法运算在中间计算中保持了完全的精度。这种行为可以实现更精确的浮点计算,包括积的累加,包括点积、矩阵乘法和多项式求值。FMA指令还实现了精确舍入除法和平方根的高效软件实现,无需硬件除法或平方根单元。
双精度硬件FMA单元实现64位加法、乘法、转换和FMA运算本身,双精度FMA单元的体系结构可在输入和输出上实现全速非标准化数支持。下图显示了FMA单元的结构。
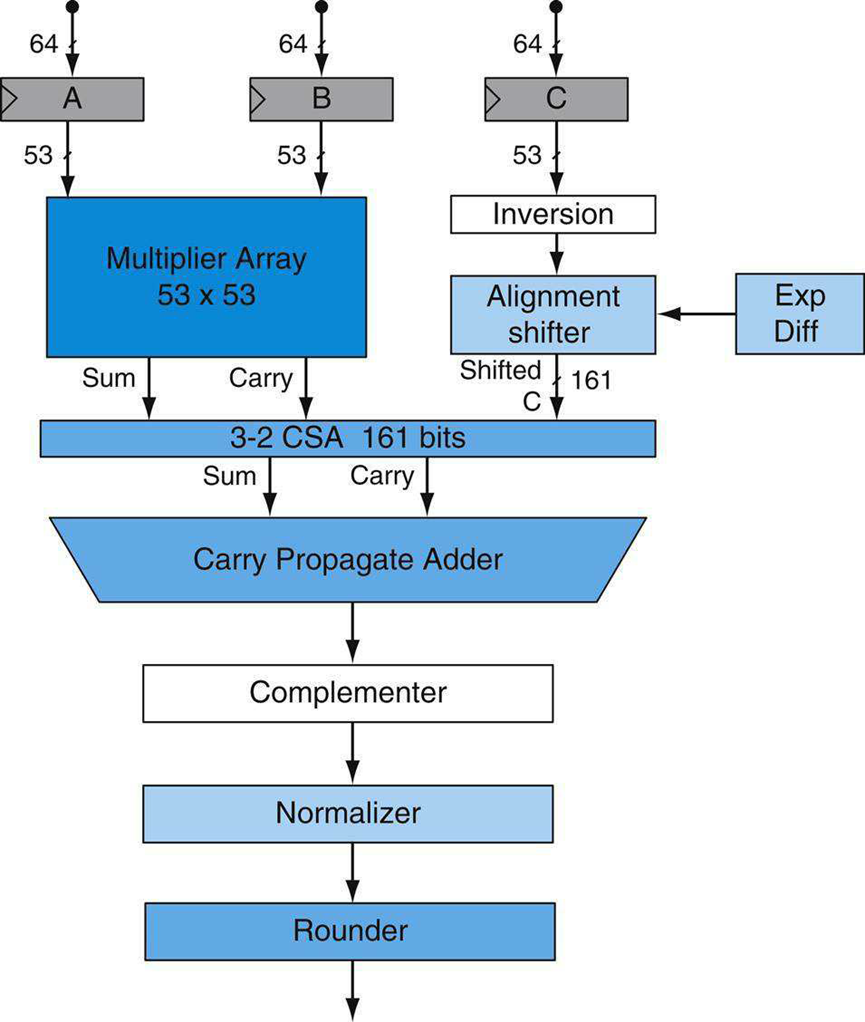
双精度融合乘加(FMA)单元,硬件实现双精度浮点A×B+C。
如上图所示,A和B的有效位相乘形成106位乘积,结果保留进位形式,并行地,53位加数C有条件地反转并与106位乘积对齐,106位乘积的和和进位结果通过161位宽进位保存加法器(CSA)与对齐的加数相加。然后,进位保存输出在进位传播加法器中相加,以产生一个非冗余二进制补码形式的非舍入结果。结果被有条件地重新计算,以便以符号大小形式返回结果,补码结果被归一化,然后被舍入以符合目标格式。
6 可编程GPU
编程多处理器GPU与编程其他多处理器(如多核CPU)有本质上的不同。GPU比CPU提供了两到三个数量级的线程和数据并行性,可扩展到数百个处理器内核和数万个并发线程。GPU继续提高其并行性,大约每12到18个月将其翻倍,这是摩尔定律提高集成电路密度和提高架构效率的结果。为了跨越不同细分市场的广泛价格和性能范围,不同的GPU产品实现了不同数量的处理器和线程。然而,用户希望游戏、图形、图像和计算应用程序能够在任何GPU上运行,无论它执行多少并行线程或拥有多少并行处理器内核,而且他们希望更昂贵的GPU(具有更多线程和内核)能够更快地运行应用程序。因此,GPU编程模型和应用程序被设计为透明地扩展到广泛的并行度。
GPU中大量并行线程和内核背后的驱动力是实时图形性能——需要以每秒至少60帧的交互式帧速率以高分辨率渲染复杂的3D场景。相应地,图形着色语言(如Cg、HLSL、GLSL)的可扩展编程模型被设计为通过许多独立的并行线程利用大程度的并行性,并可扩展到任意数量的处理器核。CUDA可扩展并行编程模型类似地使通用并行计算应用程序能够利用大量并行线程,并可扩展到任意数量的并行处理器内核,对应用程序透明。
在这些可扩展编程模型中,程序员为单个线程编写代码,GPU并行运行无数线程实例,所以程序可以在广泛的硬件并行性上透明地扩展。这种简单的范例源自图形API和描述如何对一个顶点或一个像素进行着色的着色语言,自20世纪90年代末以来,随着GPU快速提高其并行性和性能,一直是一个有效的范例。
简要介绍使用图形API和编程语言为实时图形应用程序编程GPU,然后介绍使用C语言和CUDA编程模型为可视化计算和通用并行计算应用程序编程GPU。
API在GPU和处理器的快速、成功开发中发挥了重要作用。有两个主要的标准图形API:OpenGL和Direct3D。OpenGL是一种开放标准,最初由Silicon Graphics Incorporated提出并定义,OpenGL标准的持续开发和扩展由行业协会Khronos管理。Direct3D是一种事实上的标准,由微软和合作伙伴定义并向前发展。OpenGL和Direct3D的结构相似,并随着GPU硬件的进步不断快速发展,它们定义了映射到GPU硬件和处理器上的逻辑图形处理管线,以及可编程管道阶段的编程模型和语言。
下图说明了Direct3D 10逻辑图形管线,OpenGL具有类似的图形管线结构。API和逻辑管线为可编程着色器阶段提供了流数据流基础设施和管道,如蓝色所示。3D应用程序向GPU发送分组为几何图元点、线、三角形和多边形的顶点序列,输入装配程序收集顶点和基元。顶点着色器程序执行逐顶点处理,包括将顶点3D位置转换为屏幕位置并照亮顶点以确定其颜色,几何着色器程序执行逐图元处理,并可以添加或删除图元,设置和光栅化单元生成由几何图元覆盖的像素片段(片段是对像素的潜在贡献)。
像素着色器程序执行每片段处理,包括插值每片段参数、纹理和着色。像素着色器使用插值浮点坐标,广泛使用采样和过滤查找到大型1D、2D或3D阵列(称为纹理)中。着色器使用贴图、函数、贴花、图像和数据的纹理访问。光栅操作处理(或输出合并)阶段执行Z缓冲深度测试和模板测试,这可以丢弃隐藏的像素片段或用片段的深度替换像素的深度,并执行颜色混合操作,该操作将片段颜色与像素颜色相结合,并用混合的颜色写入像素。
图形API和图形管道为处理每个顶点、图元和像素片段的着色器程序提供输入、输出、内存对象和基础结构。
6.1 编程并行计算应用程序
图形处理模型实际上是多线程、多编程和SIMD执行的组合,NVIDIA称其型号为SIMT(单指令、多线程)。让看看NVIDIA的SIMT执行模型。
程序员首先用CUDA编程语言编写代码。CUDA代表计算统一设备架构,是C/C++的自定义扩展,由NVIDIA的nvcc编译器编译,以在CPU的ISA(用于CPU)和PTX指令集(用于GPU)中生成代码。CUDA程序包含一组在GPU上运行的内核和一组在主机CPU上运行的函数。主机CPU上的功能将数据传输到GPU和从GPU传输数据,初始化变量,并协调GPU上内核的执行,内核被定义为在GPU上并行执行的函数。图形硬件为每个CUDA内核创建多个副本,每个副本在单独的线程上执行。
GPU将每个这样的线程映射到SP核心。可以为单个CUDA内核无缝创建和执行数百个线程。有些人可能会认为,如果多个副本的代码相同,那么运行多个副本有什么意义。答案是代码并不完全相同,代码隐式地将线程的id作为输入,例如,如果为每个CUDA内核生成100个线程,那么每个线程在集合[0...99]中都有一个唯一的id,CUDA内核中的代码根据线程的id执行适当的处理。许多单独应用程序的线程可能同时运行,每个SM的MT发布逻辑调度线程并协调其执行。这种架构中的SM可以处理多达768个线程。
如果并行运行多个应用程序,那么GPU作为一个整体将需要调度数千个线程,调度开销过高。因此,为了简化调度任务,GeForce 8800 GPU将一组32个线程组合成一个warp。每个SM可以管理24个warp,warp是线程的原子单位,warp中的所有线程都被调度,或者warp中没有线程被调度。此外,warp中的所有线程都属于同一内核,并且从完全相同的地址开始。然而,在它们启动之后,可以有不同的程序计数器。
每个SM将warp的线程映射到SP核心,它按指令执行warp指令,类似于经典的SIMD执行,在多个数据流上执行一条指令,然后转到下一条指令。SM为warp中的每个线程执行一条指令,在所有线程完成该指令后,它执行下一条指令。如果内核有一个依赖于数据或线程的分支,那么SM只为那些在正确的分支路径中有指令的线程执行指令。GeForce GPU使用预测指令,对于错误路径上的指令,判断条件为false,因此这些指令被nop指令动态替换。一旦分支路径(已执行和未执行)重新合并,warp中的所有线程将再次激活。与SIMD模型的主要区别在于,在SIMD处理器中,同一线程处理同一指令中的多个数据流。然而,在这种情况下,同一条指令在多个线程中执行,每条指令对不同的数据流进行操作。在warp中执行指令后,MT执行单元可能会调度相同的warp、来自相同应用程序的另一个warp或来自另一个应用程序的warp。GPU本质上实现了warp级别的细粒度多线程,下图显示了一个示例。
Warp的调度。
对于32线程的执行,SM通常使用4个周期。在第一个周期中,它向8个SP核心中的每一个发出8个线程。在第二个周期中,它向SFU再发出8个线程。由于两个SFU各有4个功能单元,因此它们可以并行处理8个指令,而不会产生任何结构冲突。在第三个周期中,又向SP核心发送了8个线程,最后在第四个周期中向两个SFU核心发送8个线程。这种在使用SFU和SP核心之间切换的策略确保了两个单元都保持忙碌。由于warp是一个原子单元,它不能在SM之间拆分,并且warp的每条指令必须在所有活动线程上执行完毕,然后才能执行warp中的下一条指令。可以在概念上将warp的概念等同于32通道宽的SIMD机器,同一应用程序中的多个warp可以独立执行。为了在warp之间进行同步,需要使用全局内存,或者现代GPU中可用的复杂同步原语。
CUDA、Brook和CAL是GPU的编程接口,专注于数据并行计算而不是图形。CAL(计算抽象层)是AMD GPU的低级汇编语言接口,Brook是Buck等人的一种适用于GPU的流式语言,由NVIDIA开发的CUDA是C和C++语言的扩展,用于多核GPU和多核CPU的可扩展并行编程。
凭借新模型,GPU在数据并行和吞吐量计算方面表现出色,可执行高性能计算应用程序和图形应用程序。
为了有效地将大型计算问题映射到高度并行的处理架构,程序员或编译器将问题分解为许多可以并行解决的小问题。例如,程序员将一个大的结果数据数组划分为块,并将每个块进一步划分为元素,从而可以并行地独立计算结果块,并且并行地计算每个块内的元素。下图显示了将结果数据数组分解为3×2块网格,其中每个块进一步分解为5×3元素数组。两级并行分解自然映射到GPU架构:并行多处理器计算结果块,并行线程计算结果元素。
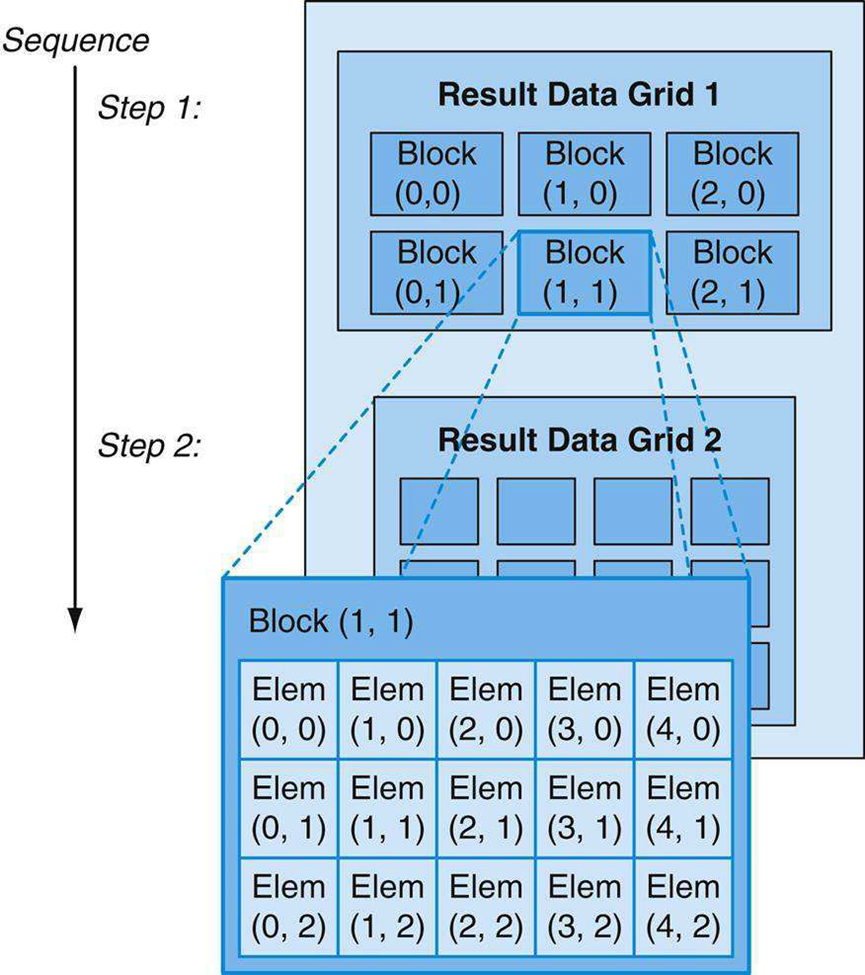
将结果数据分解为要并行计算的元素块网格。
程序员编写一个程序来计算一系列结果数据网格,将每个结果网格划分为粗粒度的结果块,这些块可以独立并行计算。程序使用细粒度并行线程数组计算每个结果块,在线程之间划分工作,以便每个线程计算一个或多个结果元素。
6.2 CUDA编程
CUDA可扩展并行编程模型扩展了C和C++语言,以在高度并行的多处理器(特别是GPU)上为通用应用程序开发大量并行性,早期经验表明,许多复杂的程序可以用一些容易理解的抽象来表达。自2007年NVIDIA发布CUDA以来,开发人员迅速开发了可扩展的并行程序,用于广泛的应用,包括地震数据处理、计算化学、线性代数、稀疏矩阵求解器、排序、搜索、物理模型和可视化计算,这些应用程序可以透明地扩展到数百个处理器内核和数千个并发线程。具有Tesla统一图形和计算架构的NVIDIA GPU运行CUDA C程序,并广泛用于笔记本电脑、PC、工作站和服务器。CUDA模型也适用于其他共享内存并行处理架构,包括多核CPU。
CUDA提供了三个关键抽象——线程组的层次结构、共享内存和屏障同步,为层次结构中的一个线程提供了与传统C代码的清晰并行结构。多级线程、内存和同步提供细粒度数据并行和线程并行,嵌套在粗粒度数据并行和任务并行中,抽象指导程序员将问题划分为可以独立并行解决的粗略子问题,然后划分为可以并行解决的更精细的部分。编程模型可以透明地扩展到大量处理器内核:编译后的CUDA程序可以在任意数量的处理器上执行,只有运行时系统才需要知道物理处理器的数量。
CUDA是C和C++编程语言的最小扩展,程序员编写一个调用并行内核的串行程序,可以是简单的函数,也可以是完整的程序。内核跨一组并行线程并行执行,程序员将这些线程组织成线程块的层次结构和线程块的网格。线程块是一组并发线程,它们可以通过屏障同步和共享访问块专用的内存空间来相互协作。网格是一组线程块,每个线程块可以独立执行,因此可以并行执行。
内核(kernel):一个线程的程序或函数,设计为可由多个线程执行。
线程块(thread block):一组并发线程,它们执行相同的线程程序,并可以协作计算结果。
网格(grid):执行同一内核程序的一组线程块。
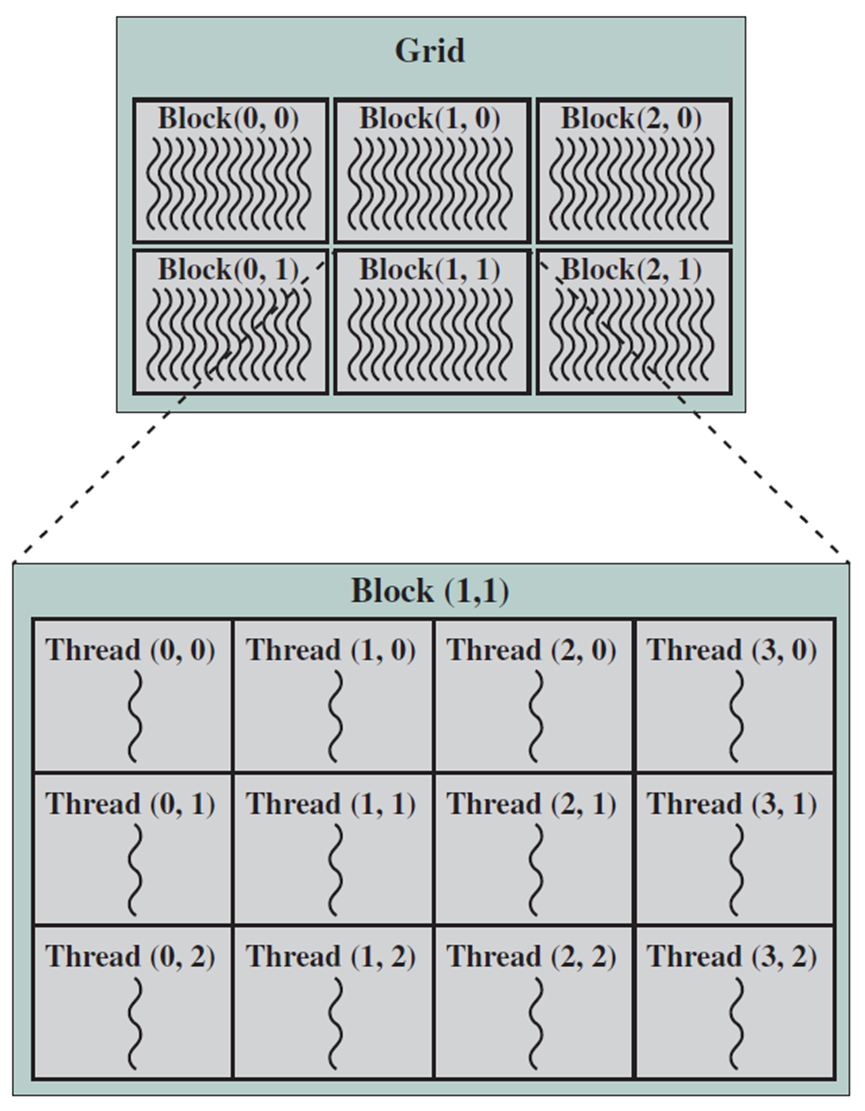
线程、块和网格之间的关系。
CUDA术语与GPU硬件组件等效映射如下表:
|
CUDA术语 |
定义 |
等效的GPU硬件组件 |
|
内核(Kernel) |
在GPU上运行的函数形式的并行代码 |
不适用 |
|
线程(Thread) |
GPU上内核的实例 |
GPU/CUDA处理器核心 |
|
块(Block) |
分配给特定SM的一组线程 |
CUDA多处理器(SM) |
|
网格(Grid) |
GPU |
GPU |
CUDA程序自然映射到GPU的结构。首先在CUDA中编写一个内核,该内核根据运行时分配给它的线程id执行一组操作,内核的动态实例是线程(类似于CPU上下文中的线程)。将一组线程分组为一个块(block)或CTA(协作线程数组),块或CTA对应于warp,一个块中可以有1-512个线程,每个SM在任何时间点最多可以缓冲8个块的状态。块中的每个线程都有一个唯一的线程id,类似地,块被分组在一个网格中,网格包含应用程序的所有线程,不同的块(或warp)可以彼此独立地执行,除非明确实施某种形式的同步。在简单示例中,将块视为线程的线性数组,将网格视为块的线性数组。此外,可以将块定义为线程的2D或3D数组,或者将网格定义为块的2D或三维数组。
现在来看一个小型CUDA程序,它添加了两个n元素数组,让部分考虑CUDA调度。在下面的代码片段中,初始化了三个数组a、b和c,希望添加a和b元素,并将结果保存在c中。
#define N 1024
void main()
{
// 声明数组
int a[N], b[N], c[N];
// 在GPU中声明相应的数组
int size = N * sizeof(int);
int *gpu_a, *gpu_b, *gpu_c;
// 为GPU中的数组分配空间
cudaMalloc((void**) &gpu_a, size);
cudaMalloc((void**) &gpu_b, size);
cudaMalloc((void**) &gpu_c, size);
// 初始化数组
(...)
// 拷贝数组到GPU
cudaMemcpy (gpu_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy (gpu_b, b, size, cudaMemcpyHostToDevice);
}
在这个代码片段中,声明了三个数组(a、b和c),其中包含N个元素,随后定义了它们在gpu中的相应存储位置。然后,使用cudaMalloc调用在GPU中为它们分配空间。接下来,用值初始化数组a和b(代码未显示),然后使用CUDA函数cudaMemcpy将这些数组复制到gpu中的相应位置(gpu_a和gpu_b),它使用名为cudaMemcpyHostToDevice的标志,其中主机是CPU,设备是GPU。
下一个操作是在gpu中添加向量gpu_a和gpu_b。为此,需要编写一个vectorAdd函数来添加向量。此函数应包含三个参数,由两个输入向量和一个输出向量组成。下面展示调用此函数的代码。
vectorAdd <<< N/32, 32 >>> (gpu_a, gpu_b, gpu_c);
使用三个参数调用vectorAdd函数:gpu_a、gpu_b和gpu_c。表达式<<< N/32, 32 >>>向GPU表明,有N=32个块,每个块包含32个线程。假设GPU神奇地添加了两个数组,并将结果保存在其物理内存空间中的数组gpu_c中。主功能的最后一步是从GPU获取结果,并释放GPU中的空间,其代码如下。
/* Copy from the GPU to the CPU */
cudaMemcpy(c, gpu_c, size, cudaMemcpyDeviceToHost);
/* free space in the GPU */
cudaFree(gpu_a);
cudaFree(gpu_b);
cudaFree(gpu_c);
/* end of the main function */
现在,让定义需要在GPU上执行的vectorAdd函数。
/* The GPU kernel */
__global__ void vectorAdd( int *gpu a, int *gpu b, int *gpu c)
{
/* compute the index */
int idx = threadIdx.x + blockIdx.x * blockDim.x;
/* perform the addition */
gpu_c[idx] = gpu_a[idx] + gpu_b[idx];
}
上述代码中,访问CUDA运行时填充的一些内置变量,通常情况网格和块有三个轴(x, y, z)。因为在这个例子中假设块和网格中只有一个轴,所以只使用x轴。变量blockDim.x等于块中的线程数。如果考虑二维网格,那么块的尺寸将是blockDim.x*blockDim.y,blockIdx.x是块的索引,threadIdx.x是块中线程的索引,因此表达式threadIdx.x+blockIdx.x * blockDim.x表示线程的索引。注意此示例中,数组的每个元素与一个线程相关联。由于创建、初始化和切换线程的开销很小,因此可以在GPU的情况下采用这种方法,如果CPU在创建和管理线程时开销很大,那么这种方法是不可行的。一旦计算了线程的索引,就执行加法运算。
GPU创建此内核的N个副本,并将其分发给N个线程。每个内核计算不同的索引,然后执行加法运算。然而,使用CUDA扩展到C/C++,可以编写极其复杂的程序,其中包含同步语句和条件分支语句。
下面再举个并行编程的一个简单的例子,假设得到了n个浮点数的两个向量x和y,并且希望计算某个标量值a的y=ax+y的结果,正是BLAS线性代数库定义的所谓SAXPY内核。下面显示了使用CUDA在串行处理器和并行处理器上执行此计算的C代码。
// 用串行循环计算y=ax+y
void saxpy_serial( int n, float alpha, float * x, float )
{
for( int i=0; i<n; ++i)
y[i] = alpha * x[i] + y[i];
}
// 调用串行SAXPY内核
saxpy_serial(n, 2.0, x, y);
// 用CUDA并行计算y=ax+y
__global__
void saxpy_parallel( int n, float alpha, float *x, float *y)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i < n)
y[i] = alpha * x[i] + y[i];
}
// Invoke parallel SAXPY kernel (256 threads per block)
int nblocks = (n + 255) / 256;
saxpy_parallel<<< nblocks, 256>>> ( n, 2.0, x, y);
__global__声明说明符表示过程是内核入口点,CUDA程序使用扩展函数调用语法启动并行内核:
kernel<<<dimGrid, dimBlock>>>(… parameter list …);
其中,dimGrid和dimBlock是dim3类型的三个元素向量,分别指定网格在块中的尺寸和线程中的块的尺寸。未指定的尺寸默认为1。
上述代码启动了一个由n个线程组成的网格,为向量的每个元素分配一个线程,并在每个块中放置256个线程。每个单独的线程根据其线程和块ID计算元素索引,然后对相应的向量元素执行所需的计算。比较这段代码的串行和并行版本,会发现它们非常相似,是一种相当常见的模式。串行代码由一个循环组成,其中每个迭代都独立于所有其他迭代。这样的循环可以机械地转换为并行内核:每个循环迭代都成为一个独立的线程。通过为每个输出元素分配一个线程,避免了在将结果写入内存时线程之间的任何同步。
CUDA内核的文本只是一个顺序线程的C函数,因此通常很容易编写,并且比为向量运算编写并行代码更简单。通过在启动内核时指定网格及其线程块的维度,可以明确地确定并行性。
并行执行和线程管理是自动的,所有线程的创建、调度和终止都由底层系统为程序员处理。事实上,Tesla架构GPU直接在硬件中执行所有线程管理。块的线程同时执行,并且可以通过调用__syncthreads()内在函数在同步屏障处同步,以此保证在块中的所有线程都到达屏障之前,块中的任何线程都不能继续。在通过屏障之后,这些线程还可以确保在屏障之前看到块中的线程对内存执行的所有写入。因此,块中的线程可以通过在同步屏障处写入和读取每个块共享内存来彼此通信。
同步屏障(synchronization barrier):线程在同步屏障处等待,直到线程块中的所有线程到达该屏障。
由于块中的线程可以共享内存并通过屏障进行同步,因此它们将一起驻留在同一物理处理器或多处理器上,但线程块的数量可能大大超过处理器的数量。CUDA线程编程模型将处理器虚拟化,并使程序员能够灵活地以最方便的粒度进行并行化。虚拟化为线程和线程块允许直观的问题分解,因为块的数量可以由正在处理的数据的大小决定,而不是由系统中的处理器数量决定,它还允许相同的CUDA程序扩展到不同数量的处理器内核。
为了管理这种处理元素虚拟化并提供可扩展性,CUDA要求线程块能够独立执行,必须能够以任何顺序并行或串行执行块。不同的块没有直接通信的方式,尽管它们可以通过例如原子递增队列指针,使用对所有线程可见的全局内存上的原子内存操作来协调它们的活动。这种独立性要求允许跨任意数量的内核以任意顺序调度线程块,从而使CUDA模型可跨任意数量内核以及多种并行架构进行扩展,也有助于避免死锁的可能性。应用程序可以独立或独立地执行多个网格,给定足够的硬件资源,独立网格可以同时执行。从属网格按顺序执行,其间有一个隐式内核间屏障,从而保证第一个网格的所有块在第二个从属网格的任何块开始之前完成。
原子内存操作(atomic memory operation):一种内存读取、修改、写入操作序列,在没有任何干预访问的情况下完成。
线程在执行过程中可以从多个内存空间访问数据,每个线程都有一个专用局部内存,CUDA对不适合线程寄存器的线程专用变量以及堆栈帧和寄存器溢出使用本地内存。每个线程块都有一个共享内存,该内存对该块的所有线程都可见,并且与该块具有相同的生存期。最后,所有线程都可以访问相同的全局内存,程序使用__shared__和__device__类型限定符在共享和全局内存中声明变量。在Tesla架构的GPU上,这些内存空间对应于物理上独立的内存:每个块共享内存是一个低延迟的片上RAM,而全局内存驻留在图形板上的快速DRAM中。
局部内存(local memory):线程专用的逐线程局部内存。
共享内存(shared memory):块的所有线程共享的逐块内存。
全局内存(global memory):所有线程共享的逐应用程序内存。
共享内存应该是每个处理器附近的低延迟内存,很像L1缓存,因此它可以在线程块的线程之间提供高性能通信和数据共享。由于它的生存期与其对应的线程块相同,内核代码通常会初始化共享变量中的数据,使用共享变量进行计算,并将共享内存结果复制到全局内存。顺序相关网格的线程块通过全局内存进行通信,使用它来读取输入和写入结果。
下图显示了线程、线程块和线程块网格的嵌套级别图,还显示了相应的内存共享级别:逐线程、逐线程块和逐应用程序数据共享的局部、共享和全局内存。
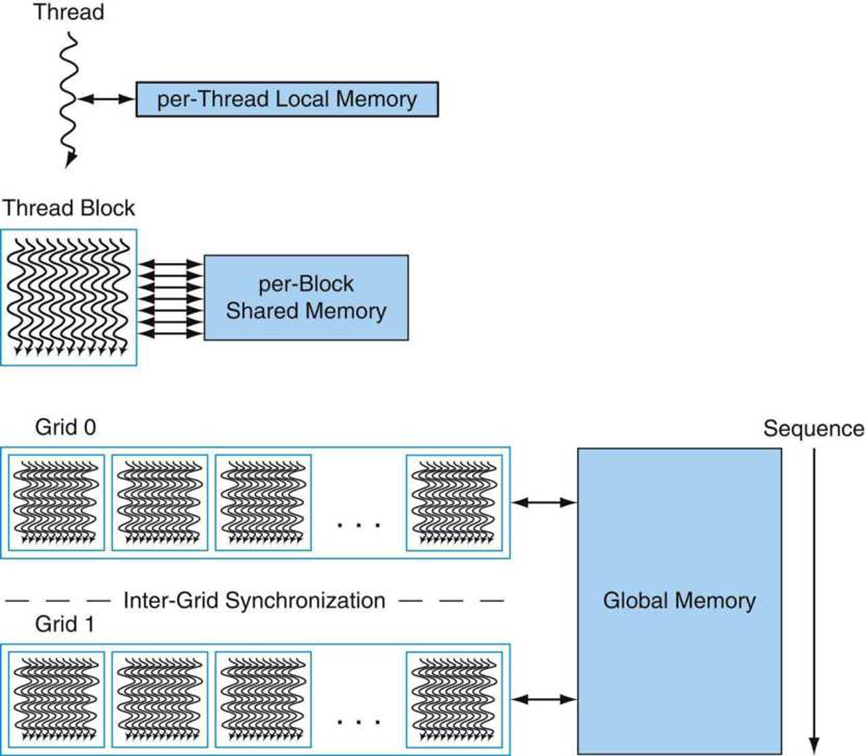
嵌套粒度级别线程、线程块和网格具有相应的局部、共享和全局内存共享级别。逐线程局部内存是线程专用的,逐块共享内存由块的所有线程共享,逐应用程序的全局内存由所有线程共享。
程序通过调用CUDA运行时(如cudaMalloc()和cudaFree())来管理内核可见的全局内存空间。内核可以在物理上独立的设备上执行,就像在GPU上运行内核一样,所以应用程序必须使用cudaMemcpy()在分配的空间和主机系统内存之间复制数据。
CUDA编程模型在风格上类似于熟悉的单程序多数据(SPMD)模型,它显式地表示并行性,每个内核在固定数量的线程上执行。然而,CUDA比SPMD的大多数实现更灵活,因为每个内核调用都会动态地创建一个新的网格,其中包含正确数量的线程块和应用程序步骤的线程。程序员可以为每个内核使用方便的并行度,而不必设计计算的所有阶段来使用相同数量的线程。下图显示了类似SPMD的CUDA代码序列的示例。它首先在3×2块的2D网格上实例化内核F,其中每个2D线程块由5×3个线程组成。然后,它在四个一维线程块的一维网格上实例化内核G,每个一维线程块有六个线程。因为kernelG依赖于kernelF的结果,所以它们被内核间同步屏障分隔开。
单程序多数据(single-program multiple data,SPMD):一种并行编程模型,其中所有线程执行同一程序。SPMD线程通常与屏障同步协调。
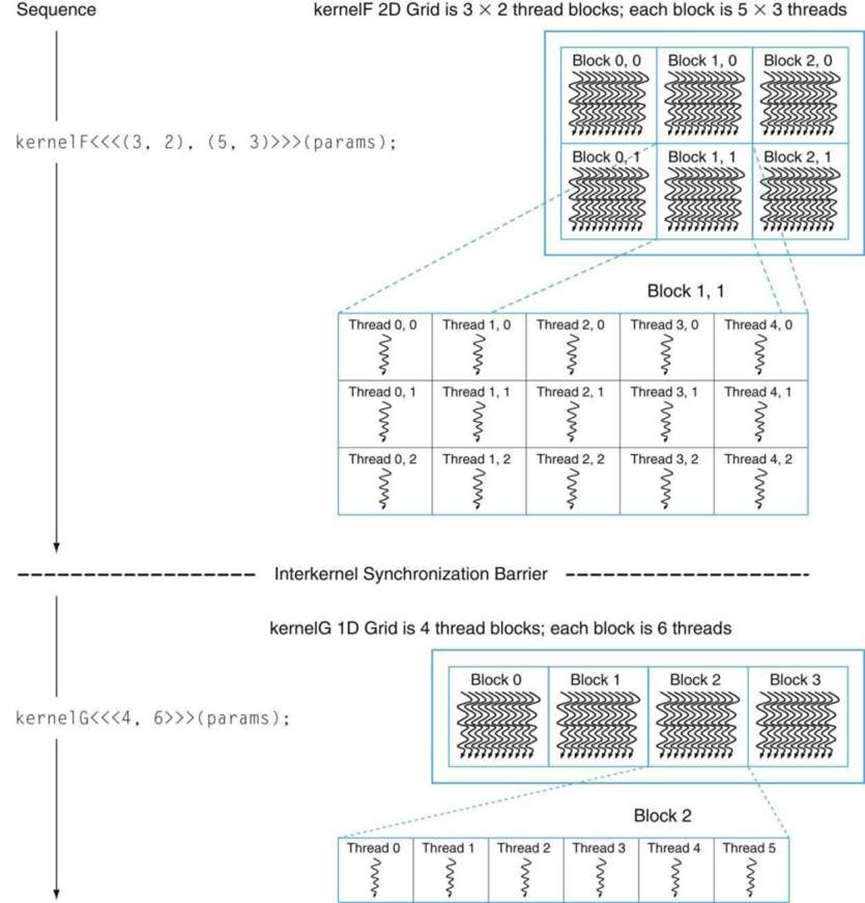
在2D线程块的2D网格上实例化的内核F序列,是一个内核间同步屏障,之后是1D线程块的1D网格上的内核G。
线程块的并发线程表示细粒度数据并行和线程并行,网格的独立线程块表示粗粒度数据并行性,独立网格表示粗粒度任务并行性。内核只是层次结构中一个线程的C代码。
请注意,将GPU内核与CPU执行的代码合并为一个程序,NVIDIA的编译器将单个文件拆分为两个二进制文件,一个二进制在CPU上运行并使用CPU的指令集,另一个二进制运行在GPU上并使用PTX指令集。这是一个典型的MPMD执行方式的例子,在不同的指令集和多个数据流中有不同的程序。因此,可以将GPU的并行编程模型视为SIMD、MPMD和warp级别的细粒度多线程的组合(下图)。
为了提高效率并简化其实现,CUDA编程模型有一些限制。线程和线程块只能通过调用并行内核而不是从并行内核中创建,再加上线程块所需的独立性,使得使用简单的调度器执行CUDA程序成为可能,该调度器引入了最小的运行时开销。事实上,Tesla GPU架构实现了线程和线程块的硬件管理和调度。
任务并行性可以在线程块级别表达,但很难在线程块中表达,因为线程同步障碍在块的所有线程上运行。为了使CUDA程序能够在任意数量的处理器上运行,同一内核网格内的线程块之间的依赖关系是不允许的。由于CUDA要求线程块是独立的并且允许以任何顺序执行块,组合由多个块生成的结果通常必须通过在线程块的新网格上启动第二个内核来完成(尽管线程块可以通过例如原子递增队列指针来使用对所有线程可见的全局内存上的原子内存操作来协调其活动)。
CUDA内核中当前不允许递归函数调用,递归在大规模并行内核中不具备吸引力,因为为数以万计的活动线程提供堆栈空间需要大量内存。通常使用递归(如快速排序)表示的串行算法通常最好使用嵌套数据并行而不是显式递归来实现。
为了支持将CPU和GPU结合在一起的异构系统架构,CUDA程序必须在主机内存和设备内存之间复制数据和结果。通过使用DMA块传输引擎和快速互连,CPU与GPU交互和数据传输的开销最小化,大到需要GPU性能提升的计算密集型问题比小问题更好地分摊开销。
图形和计算的并行编程模型使得GPU架构不同于CPU架构,驱动GPU处理器架构的GPU程序的关键方面是:
- 广泛使用细粒度数据并行性:着色器程序描述如何处理单个像素或顶点,CUDA程序描述如何计算单个结果。
- 高线程编程模型:着色器线程程序处理单个像素或顶点,CUDA线程程序可以生成单个结果。GPU必须以每秒60帧的速度每帧创建和执行数百万个这样的线程程序。
- 可扩展性:当提供额外的处理器时,程序必须自动提高性能,而无需重新编译。
- 密集型浮点(或整数)计算。
- 支持高吞吐量计算。
6.3 NVIDIA GPU内存结构
下图显示了NVIDIA GPU的内存结构,每个多线程SIMD处理器本地的片上内存称为局部内存。它由多线程SIMD处理器内的SIMD通道共享,但此内存不在多线程SIMC处理器之间共享,整个GPU和所有线程块共享的片外DRAM称为GPU内存。
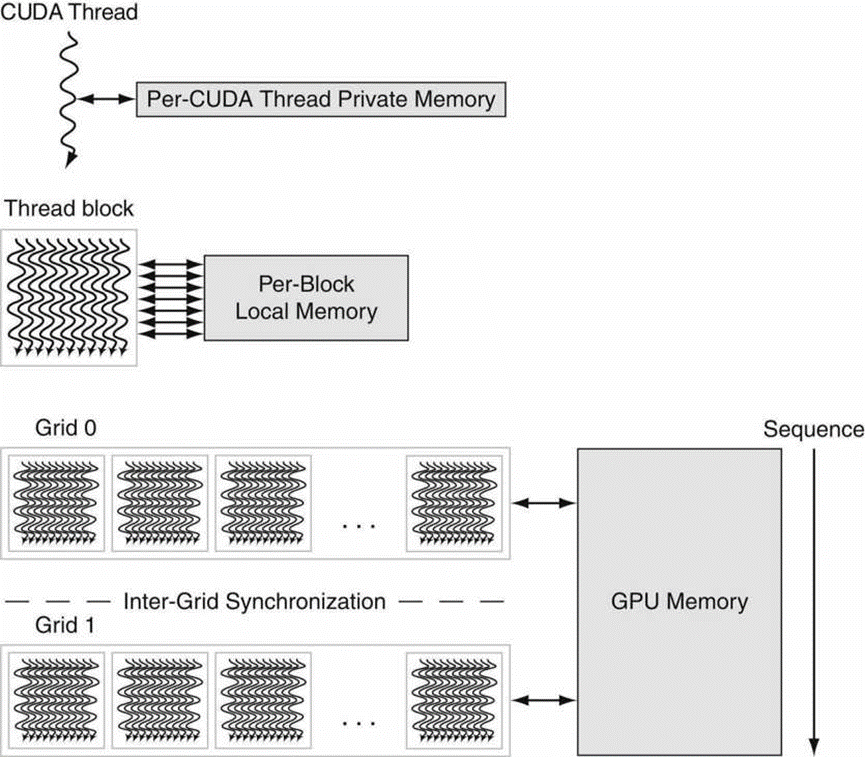
GPU内存结构。GPU内存由矢量化循环共享,线程块中SIMD指令的所有线程共享局部内存。
GPU传统上使用较小的流式缓存,并依赖SIMD指令线程的广泛多线程处理来隐藏DRAM的长延迟,而不是依赖于大型缓存来包含应用程序的整个工作集,因为它们的工作集可能是数百M字节。因此,它们不适合多核微处理器的最后一级缓存。考虑到使用硬件多线程来隐藏DRAM延迟,系统处理器中用于缓存的芯片区域被用于计算资源和大量寄存器,以保存SIMD指令的许多线程的状态。
虽然隐藏内存延迟是基本原理,但请注意,最新的GPU和矢量处理器增加了缓存,例如最近的Fermi架构增加了缓存,但它们被认为是减少GPU内存需求的带宽过滤器,或者是多线程无法隐藏延迟的少数变量的加速器。用于堆栈帧、函数调用和寄存器溢出的本地内存与缓存非常匹配,因为调用函数时延迟很重要。缓存也可以节省能量,因为片上缓存访问比访问多个外部DRAM芯片消耗的能量少得多。
在高层次上,具有SIMD指令扩展的多核计算机确实与GPU有相似之处,下图总结了相似性和差异。两者都是MIMD,其处理器使用多个SIMD通道,尽管GPU有更多的处理器和更多的通道。两者都使用硬件多线程来提高处理器利用率,尽管GPU对更多线程具有硬件支持。两者都使用缓存,尽管GPU使用较小的流缓存,而多核计算机使用大型多级缓存,试图完全包含整个工作集。两者都使用64位地址空间,尽管GPU中的物理主内存要小得多。虽然GPU在页面级别支持内存保护,但它们还不支持按需分页。
|
特性 |
带SIMD的多核(CPU) |
GPU |
|
SIMD处理器 |
4到8 |
8到16 |
|
每个处理器的SIMD通道数 |
2到4 |
8到16 |
|
SIMD线程的多线程硬件支持 |
2到4 |
16到32 |
|
最大的缓存尺寸 |
8M |
0.75M |
|
内存地址尺寸 |
64-bit |
64-bit |
|
主内存尺寸 |
8G到256G |
4G到16G |
|
页面级别的内存保护 |
是 |
是 |
|
按需分页 |
是 |
否 |
|
缓存一致性 |
是 |
否 |
SIMD处理器也类似于矢量处理器。GPU中的多个SIMD处理器充当独立的MIMD核心,就像许多矢量计算机具有多个矢量处理器一样。这种观点认为Fermi GTX 580是一个16核机器,具有多线程硬件支持,每个核有16个通道。最大的区别是多线程,这是GPU的基础,也是大多数向量处理器所缺少的。
GPU和CPU在计算机体系结构谱系中不会追溯到共享祖先,没有缺失链接可以解释这两者。由于这种不同寻常的传统,GPU没有使用计算机架构社区中常见的术语,导致了对GPU是什么以及它们如何工作的困惑。为了帮助解决混淆,下图列出了本文部分使用的更具描述性的术语,与主流计算最接近的术语。
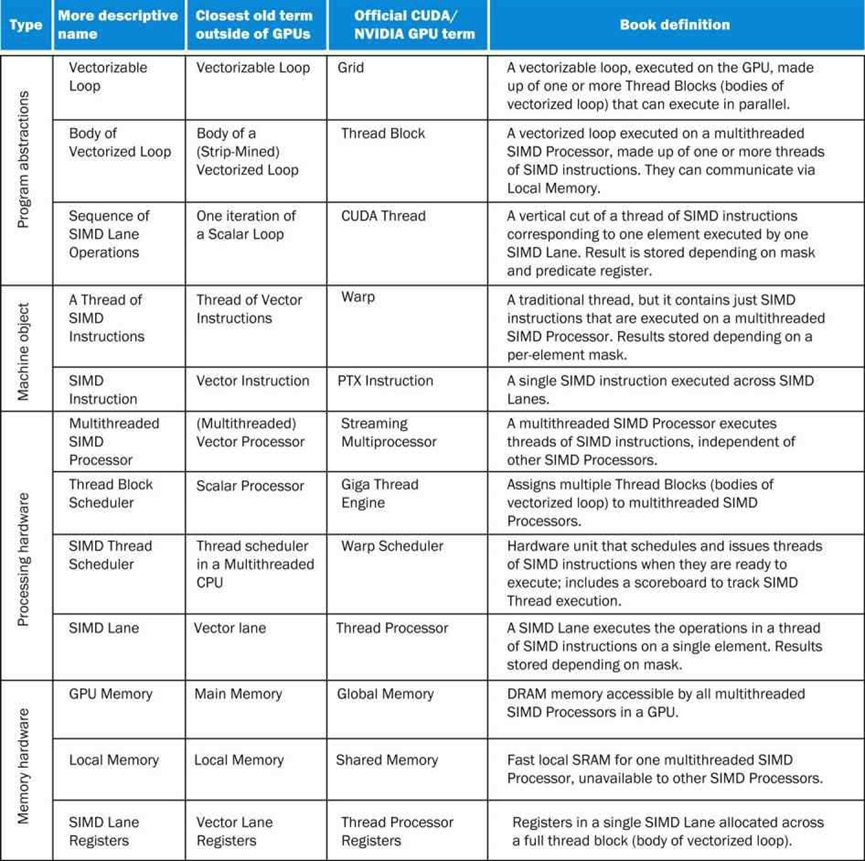
尽管GPU正朝着主流计算方向发展,但他们不能放弃继续在图形方面取得优异成绩的责任。因此,当架构师问,考虑到为做好图形而投入的硬件,如何补充它以提高更广泛应用程序的性能时,GPU的设计可能更有意义?
关于GPU的更多技术细节可参阅:深入GPU硬件架构及运行机制。
7 i7 960和Tesla GPU性能
Intel研究人员在2010年发表了一篇论文,将四核Intel core i7 960与上一代GPU NVIDIA Tesla GTX 280的多媒体SIMD扩展进行了比较。下表列出了这两种系统的特点。酷睿i7采用英特尔的45纳米半导体技术,而GPU采用台积电的65纳米技术。尽管由中立方或两个相关方进行比较可能更公平,但的目的不是确定一种产品比另一种产品快多少,而是试图了解这两种截然不同的架构风格的特征的相对价值。
|
特性 |
Core i7-960 |
GTX 280 |
GTX 480 |
280/i7的比率 |
480/i7的比率 |
|
处理元素(核或SM)的数量 |
4 |
30 |
15 |
7.5 |
3.8 |
|
时钟频率(GHz) |
3.2 |
1.3 |
1.4 |
0.41 |
0.44 |
|
模具(Die)尺寸 |
263 |
576 |
520 |
2.2 |
2.0 |
|
技术 |
Intel 45 nm |
TSMC 65 nm |
TSMC 40 nm |
1.6 |
1.0 |
|
功率(芯片,非模块) |
130 |
130 |
167 |
1.0 |
1.3 |
|
晶体管 |
700 M |
1400 M |
3030 M |
2.0 |
4.4 |
|
内存带宽(G/sec) |
32 |
141 |
177 |
4.4 |
5.5 |
|
单精度SIMD宽 |
4 |
8 |
32 |
2.0 |
8.0 |
|
双精度SIMD宽 |
2 |
1 |
16 |
0.5 |
8.0 |
|
峰值单精度标量FLOPS(GFLOP/sec) |
26 |
117 |
63 |
4.6 |
2.5 |
|
峰值单精度SIMD FLOPS(GFLOP/sec) |
102 |
311-933 |
515-1344 |
3.0-9.1 |
6.6-13.1 |
|
SP 1相加或相乘 |
N/A |
311 |
515 |
3.0 |
6.6 |
|
SP 1指令融合乘法-加法 |
N/A |
622 |
1344 |
6.1 |
13.1 |
|
特殊的SP双问题融合乘加乘 |
N/A |
933 |
N/A |
9.1 |
- |
|
峰值双精度SIMD FLOPS(GFLOP/sec) |
51 |
78 |
515 |
1.5 |
10.1 |
下图中的Core i7 960和GTX 280的曲线说明了计算机的差异。GTX280不仅具有更高的内存带宽和双精度浮点性能,而且它的双精度脊点也位于左侧。GTX 280的双精度脊点为0.6,而Core i7为3.1。如上所述,曲线的脊点越靠近左侧,就越容易达到峰值计算性能。对于单精度性能,两台计算机的脊点都会向右移动,因此很难达到单精度性能的顶点。请注意,内核的算术强度基于进入主内存的字节,而不是进入缓存的字节。因此,如上所述,如果大多数引用真的到了缓存,缓存可以改变特定计算机上内核的算术强度。还请注意,这两种架构中的单位步长访问都使用此带宽,GTX 280和Core i7上的真实聚集分散地址可能会更慢。
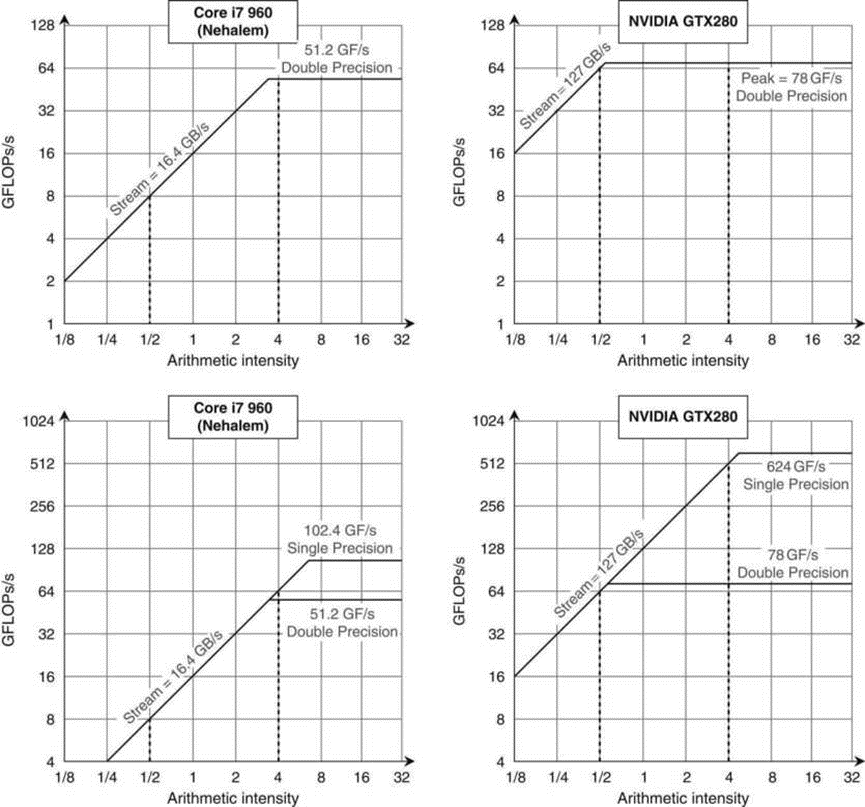
这些曲线在顶行显示双精度浮点性能,在底行显示单精度性能。(DP FP性能上限也在最下面一行,以提供透视图。)左侧的Core i7 960的DP FP性能峰值为51.2 GFLOP/sec,SP FP峰值为102.4 GFLOP/sec,峰值内存带宽为16.4 GBytes/sec。NVIDIA GTX 280的DP FP峰值为78 GFLOP/秒,SP FP峰值为624 GFLOP//秒,内存带宽为127 GB/秒。左侧的垂直虚线表示0.5 FLOP/字节的算术强度,在Core i7上,内存带宽限制为不超过8 DP GFLOP/sec或8 SP GFLOP/sec。右侧的垂直虚线的算术强度为4 FLOP/字节。在Core i7上,它的计算速度仅限于51.2 DP GFLOP/sec和102.4 SP GFLOP/sec,在GTX 280上,它仅限于78 DP GFLOp/sec和624 SP GFLOp/sec。要在Core i8上达到最高的计算速度,需要使用所有四个核心和SSE指令,并使用相同数量的乘法和加法。对于GTX 280,需要在所有多线程SIMD处理器上使用融合乘-加指令。
研究人员通过分析最近提出的四个基准套件的计算和内存特性来选择基准程序,然后“制定了一组捕获这些特性的吞吐量计算内核”。下图显示了性能结果,数字越大意味着速度越快,曲线有助于解释本案例研究中的相对性能。
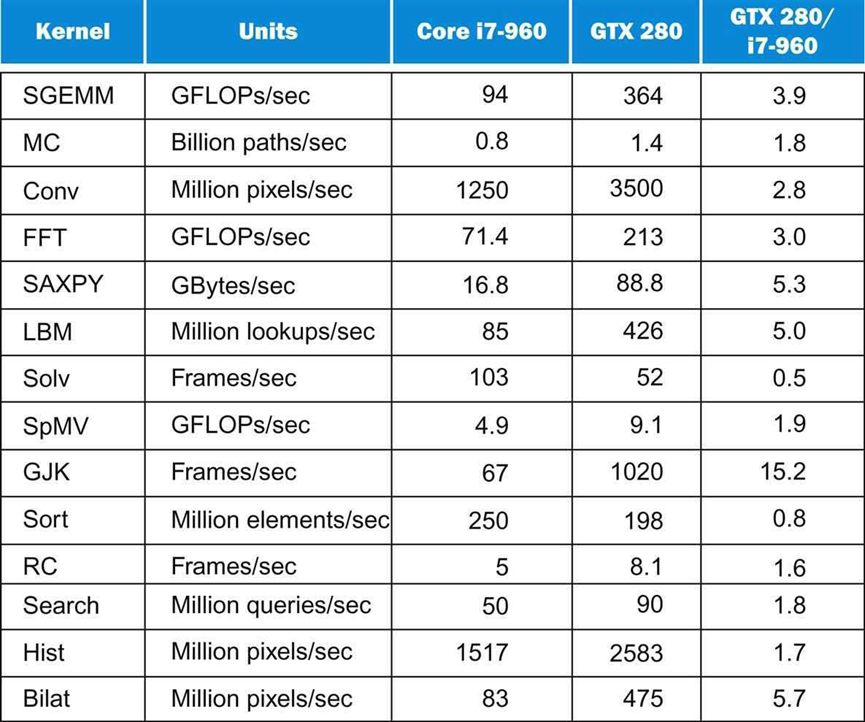
鉴于GTX 280的原始性能规格从2.5倍慢(时钟速率)到7.5倍快(每个芯片的内核数)不等,而性能从2.0倍慢(Solv)到15.2倍快(GJK)不等,Intel研究人员决定找出差异的原因:
- 内存带宽。GPU具有4.4倍的内存带宽,有助于解释为什么LBM和SAXPY的运行速度分别为5.0和5.3倍,它们的工作集有数百兆字节,因此不适合Core i7缓存,为了集中访问内存,它们故意不使用缓存阻塞(cache blocking),曲线的坡度解释了它们的性能。SpMV也有一个大的工作集,但它的运行速度仅为1.9倍,因为GTX 280的双精度浮点运算速度仅为Core i7的1.5倍。
- 计算带宽。剩下的五个内核是计算密集的:SGEMM、Conv、FFT、MC和Bilat,GTX的速度分别为3.9、2.8、3.0、1.8和5.7倍。前三个使用单精度浮点运算,GTX 280单精度运算速度快3到6倍,MC使用双倍精度,这解释了为什么DP性能只快1.5倍,所以它只快1.8倍。Bilat使用GTX 280直接支持的超越函数,Core i7将三分之二的时间用于计算Bilat的超越函数,因此GTX 280的速度要快5.7倍。这一观察有助于指出硬件支持工作负载中发生的操作的价值:双精度浮点运算,甚至可能是超验运算。
- 缓存优势。光线投射(RC)在GTX上的速度仅为1.6倍,因为Core i7缓存的缓存阻塞阻止了它成为内存带宽限制,就像在GPU上一样,缓存阻塞也可以帮助搜索。如果索引树很小,可以放入缓存,那么Core i7的速度是它的两倍,较大的索引树使其内存带宽受限,总体而言,GTX 280的搜索速度快1.8倍,缓存阻塞也有助于排序。虽然大多数程序员不会在SIMD处理器上运行排序,但它可以用一个称为拆分的1位排序原语来编写,但分割算法执行的指令比标量排序多得多,所以Core i7的运行速度是GTX 280的1.25倍。请注意,缓存也有助于Core i7上的其他内核,因为缓存阻塞允许SGEMM、FFT和SpMV成为计算绑定。这一观察再次强调了缓存阻塞优化的重要性。
- 分散-聚集。如果数据分散在主存储器中,多媒体SIMD扩展几乎没有帮助,只有当对数据的访问在16字节边界上对齐时,才能获得最佳性能。因此,GJK从Core i7上的SIMD中获得的好处很少。如上所述,GPU提供了向量架构中的聚集-分散寻址,但大多数SIMD扩展中都忽略了这种寻址,存储器控制器甚至一起批量访问同一DRAM页。这种组合表明GTX 280以惊人的15.2倍于Core i7的速度运行GJK,比上上图中的任何单个物理参数都要大。这一观察结果强化了SIMD扩展中缺少的矢量和GPU架构的聚集散射的重要性。
- 同步。同步性能受到原子更新的限制,尽管Core i7具有硬件获取和增量指令,但原子更新占Core i7总运行时间的28%。因此,Hist在GTX 280上的速度仅为1.7倍,Solv在少量计算中解决了一批独立约束,然后进行了屏障同步。Core i7得益于原子指令和内存一致性模型,即使不是以前对内存层次结构的所有访问都已完成,也能确保正确的结果。在没有内存一致性模型的情况下,GTX 280版本从系统处理器启动了一些批处理,导致GTX 280的运行速度是Core i7的0.5倍。这一观察结果指出了同步性能对于某些数据并行问题的重要性。
令人惊讶的是,Intel研究人员选择的内核发现的Tesla GTX 280中的弱点,已经在Tesla的后续架构中得到了解决:Fermi具有更快的双精度浮点性能、更快的原子运算和缓存。同样有趣的是,比SIMD指令早了几十年的向量架构的聚集-分散支持对于这些SIMD扩展的有效有用性非常重要,有些人在比较之前就已经预测到了这一点。Intel的研究人员指出,14个内核中的6个内核可以更好地利用SIMD,在Core i7上提供更高效的聚集-分散支持。这项研究也肯定了缓存阻塞的重要性。
8 NVidia Tesla架构
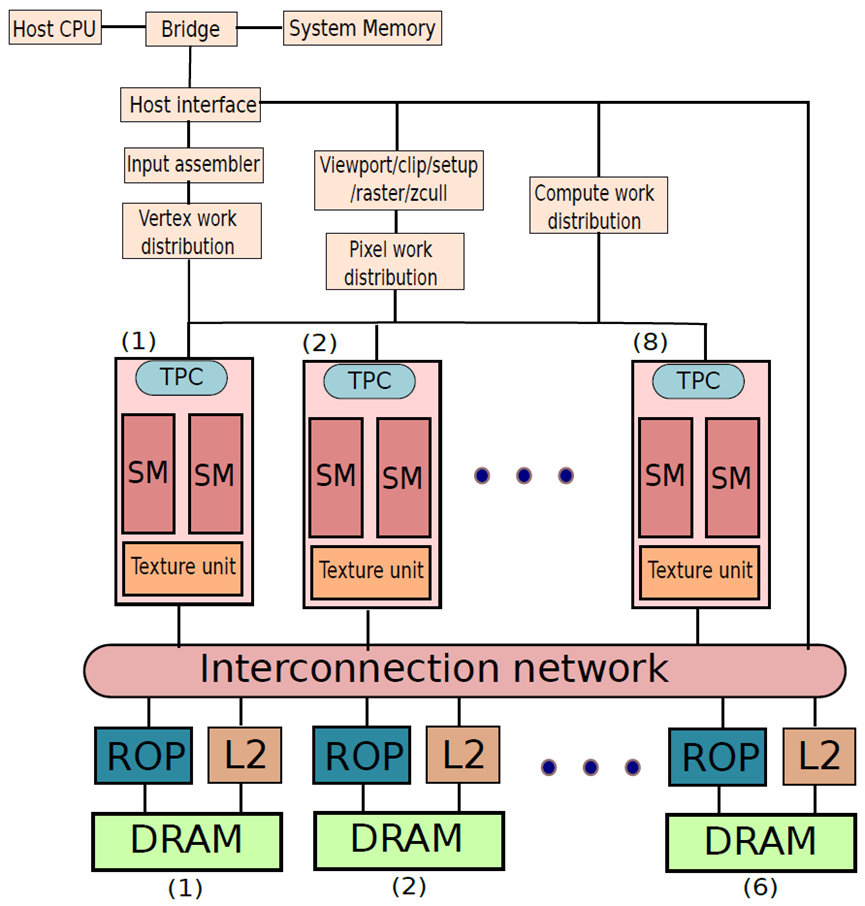
下图显示了Tesla架构,让从图的顶部开始解释。主机CPU通过专用总线向图形处理器发送命令和数据序列,然后,专用总线将一组命令和数据传输到GPU上的缓冲区,随后GPU的单元处理信息。在下图中,工作从上到下流动。GPU本质上是一组非常简单的有序内核,此外,它还有大量额外的硬件来协调复杂任务的执行,并将工作分配给一组核心。GPU还支持多级内存层次结构,并具有专门执行少数图形特定操作的专用单元。
NVIDIA Tesla架构。
8.1 工作分配
GPU可以分配三种工作:顶点处理、像素处理和常规计算工作。GPU定义自己的汇编代码,使用PTX和SASS指令集,这些指令集中的每个指令都在GPU上执行基本操作,它使用寄存器操作数或内存操作数。与CPU不同,GPU中寄存器文件的结构通常不暴露于软件,程序员需要使用无限数量的虚拟寄存器,GPU或设备驱动程序将它们映射到实际寄存器。
现在,对于处理顶点,低级图形软件向GPU发送一系列装配指令。GPU有一个硬件汇编程序,它生成二进制代码,并将其发送到一个专用的顶点处理单元,该单元协调和分配GPU内核之间的工作。或者,CPU可以向GPU发送像素处理操作,GPU执行光栅化、片段处理和深度缓冲的过程。GPU中的一个专用单元为这些操作生成代码片段,并将其发送到像素处理单元,该像素处理单元将工作项分配给GPU核心集。第三个单元是计算工作分配器,它接受CPU的常规计算任务,例如添加两个矩阵或计算两个向量的点积。程序员指定一组子任务,计算工作分配引擎的作用是将这些子任务集发送到GPU中的核心。
在这个阶段之后,GPU或多或少地忽略了指令的来源,注意,这部分工程是GPU成功背后的关键贡献。设计师已经成功地将GPU的功能分为两层,第一层特定于操作类型(图形或通用)。在此阶段,每个流水线的作用是将特定的操作序列转换为一组通用的操作,这样无论高级操作的性质如何,都可以使用相同的硬件单元。现在来看看包含计算引擎的GPGPU的后半部分。
8.2 GPU计算引擎
GeForce 8800 GPU有128个内核。核心小组分为8组,每个组称为TPC(纹理/处理器集群),每个TPC包含两个SM(流式多处理器)。此外,每个SM包含8个称为流处理器(SP)的核心,每个SP都是一个简单的有序内核,具有符合IEEE 754的浮点ALU、分支和内存访问单元。除了一组简单的内核外,每个SM都包含一些专用的内存结构。这些内存结构包含常量、纹理数据和GPU指令。所有SP都可以并行执行一组指令,并且彼此紧密同步。
8.3 互连网络、DRAM模块、二级缓存和ROP
8个TPC通过互连网络连接到一组缓存、DRAM模块和ROP(光栅操作处理器)。SM包含一级缓存,在缓存未命中时,SP核心通过NOC访问相关的二级缓存库。在GPU的情况下,二级缓存是在存储体(bank)级别上分割的共享缓存,在二级缓存之下,GPU有一个大的外部DRAM内存。GeForce 8800有384个引脚可连接到外部DRAM模块,该组引脚分为6组,每组包含64个引脚。物理内存空间也被分成6个部分,跨越6个组。光栅化操作通常需要一些专门的处理例程,不幸的是,这些例程在TPC上运行效率低下,因此GeForce 8800芯片具有6个ROP,每个ROP处理器每个周期最多可以处理4个像素,它主要对像素的颜色进行插值,并执行颜色混合操作。
9 NVidia RTX 4090架构和特性
前不久,NVIDIA宣布推出Ada Lovelace GeForce一代时,曾有过一些大胆的声明,光线跟踪性能的有效翻倍,在测试了一系列流行的渲染引擎之后,确实如此。

RTX 4090 GPU芯片结构。
Ada Lovelace一代带来了第四代Tensor磁芯和改进的光流。在创建过程中,这些功能加速了降噪等功能,而在游戏应用中,它们通过DLSS 3.0进行了升级。在光线跟踪核心方面,Ada Lovelace推出了第三代实现,并在很大程度上提供比Ampere一代提高2倍的性能。
其他值得注意的功能是Shader Execution Reordering,它进一步提高了光线跟踪性能,包括在游戏中,其中一个例子显示《赛博朋克2077》中有44%的提升。此外,Intel率先推出AV1加速GPU编码器,NVIDIA也紧随其后,Ada Lovelace也推出了一款。有趣的是,NVIDIA提供了板载双编码器,它声称这将使编码时间减半。将通过即将推出的完整创作者性能外观来探索这一点。
在开始了解NVIDIA最新旗舰的渲染性能之前,先看看NVIDIA官方正版的硬件参数:
|
GPU型号 |
核心数 |
最大频率 |
峰值FP32 |
内存 |
带宽 |
总功率 |
|
RTX 4090 |
16,384 |
2,520 |
82.6 TFLOPS |
24GB |
1008 GB/s |
450W |
|
RTX 4080 16GB |
9,728 |
2,510 |
48.8 TFLOPS |
16GB |
717 GB/s |
320W |
|
RTX 3090 Ti |
10,752 |
1,860 |
40 TFLOPS |
24GB |
1008 GB/s |
450W |
|
RTX 3080 Ti |
10,240 |
1,670 |
34.1 TFLOPS |
12GB |
912 GB/s |
350W |
|
RTX 3070 Ti |
6,144 |
1,770 |
21.7 TFLOPS |
8GB |
608 GB/s |
290W |
|
RTX 3060 Ti |
4,864 |
1,670 |
16.2 TFLOPS |
8GB |
448 GB/s |
200W |
RTX 4090配备了这一代的第一款Ada Lovelace GPU:AD102。但值得注意的是,这款旗舰卡中使用的芯片并不是全核,尽管其规格表已经非常庞大。其核心是16384个CUDA内核,分布在128个流式多处理器(SM)上,意味着比RTX 3090 Ti的GA102 GPU(其本身就是完整的Ampere核心)增加了52%。

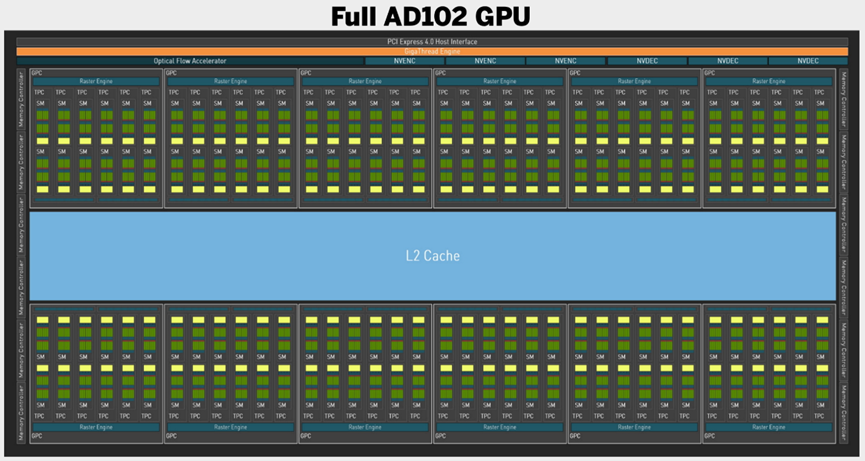
上:RTX 4090内的AD102结构;下:完整的AD102 GPU结构。
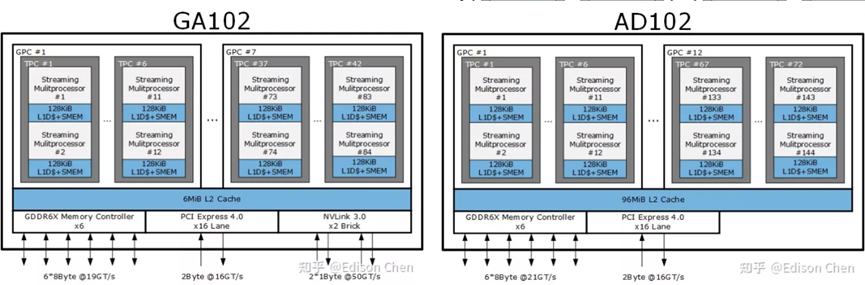
GA102和AD102架构对比图。
完整的AD102芯片包括18432个CUDA核心和144个SM,也意味着将看到144个第三代RT核心和576个第四代Tensor核心。如果英伟达愿意,RTX 4090 Ti甚至Titan都有足够的空间。
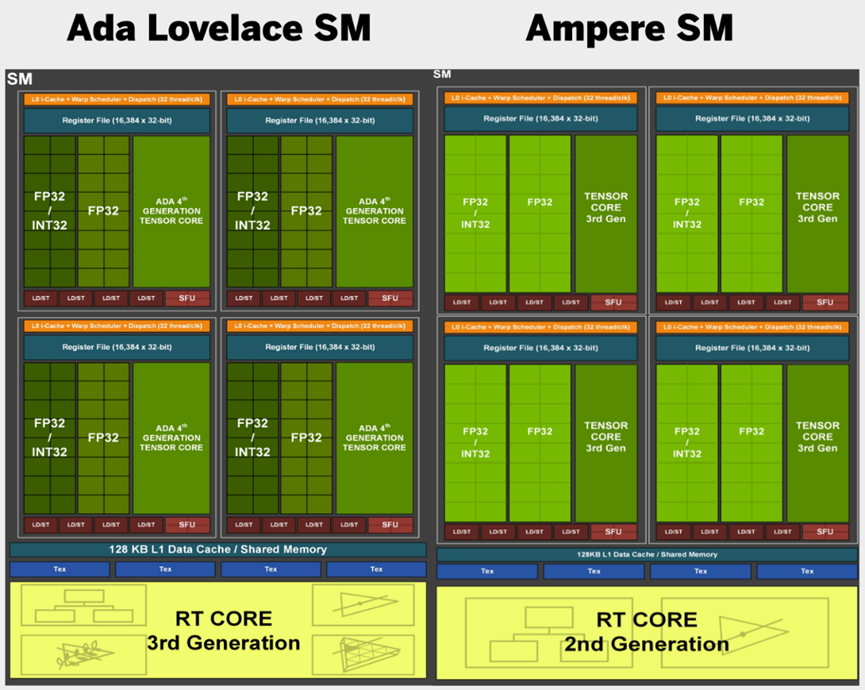
Ada Lovelace和Ampere架构的SM对比图。
内存变化不大,同样是24GB的GDDR6X以21Gbps的速度运行,可提供1008GB/秒的内存带宽。下表是GeForce RTX 4090和GeForce RTX 3090 Ti的部分参数对比图:
|
GeForce RTX 4090 |
GeForce RTX 3090 Ti |
|
|
架构 |
Ada Lovelace |
Ampere |
|
CUDA核心 |
16,432 |
10,752 |
|
SM |
128 |
84 |
|
RT核心 |
128 |
84 |
|
Tensor核心 |
512 4代 |
336 3代 |
|
ROP |
176 |
112 |
|
最大频率 |
2,520MHz |
1,860MHz |
|
内存 |
24GB GDDR6X |
24GB GDDR6X |
|
内存速度 |
21Gbps |
21Gbps |
|
内存带宽 |
1,008GB/s |
1,008GB/s |
|
总线宽 |
384 |
384 |
|
L1 | L2缓存 |
16,384KB | 73,728KB |
10,752KB | 6,144KB |
|
制作工艺 |
5nm TSMC |
8nm Samsung |
|
晶体管 |
763亿 |
283亿 |
|
芯片面积 |
608.5mm² |
628.5mm² |
|
总功率 |
450W |
450W |
在方程式的原始着色器方面,事情也没有从Ampere架构中真正发展到那么远。每个SM仍然使用相同的64个专用FP32单元,但具有64个单元的辅助流,可以根据需要在浮点和整数计算之间进行拆分,与Ampere引入的相同。
当查看RTX 3090和RTX 4090之间的相对性能差异时,可以从光栅化的角度看到这两种架构有多相似。
如果忽略光线追踪和放大,则相应的性能提升仅略高于AD102 GPU中额外的CUDA内核数量。尽管业绩增长“略高于”相应水平,但确实表明在这一水平上存在一些差异。
部分原因在于英伟达用于Ada Lovelace GPU的新4纳米生产工艺。与Ampere的8纳米三星工艺相比,据说台积电制造的4N工艺在相同功率下提供了两倍的性能,或者在相同性能下提供了一半的性能。
这意味着英伟达可以在时钟速度方面具有超强的攻击性,RTX 4090的提升时钟为2520MHz。实际上,在测试中看到了Founders Edition卡的平均频率为2716MHz,比上一代的RTX 3090快了整整1GHz。
而且,由于工艺的缩减,英伟达与台积电合作的工程师已经在AD102核心中塞进了惊人的763亿个晶体管。考虑到608.5mm²的Ada GPU包含的晶体管比GA102硅的283亿晶体管还要多,它可能比628.4mm²的Ampere芯片小得多。
事实上,英伟达能够继续将数量不断增加的晶体管塞进单片芯片中,并仍然不断缩小其实际管芯尺寸,这证明了该领域先进工艺节点的威力。作为参考,RTX 2080 Ti的TU102芯片面积为754mm²,仅容纳186亿个12nm晶体管。但并不意味着单片GPU可以永远继续,不受限制。GPU的竞争对手AMD承诺将于11月推出新的RDNA 3芯片,转而使用图形计算芯片。考虑到AD102 GPU的复杂性仅次于先进的814mm²Nvidia Hopper硅的800亿晶体管,它肯定是一种昂贵的芯片。然而,较小的计算芯片应该会降低成本,提高产量。
更多参数规格和特性如下所示:

但至少到目前,暴力的整体方法仍在为英伟达带来回报。
当想要更高的速度,并且已经尽可能多地安装了先进的晶体管时,还能做什么?答案是可以在包中添加更多的缓存,是AMD在其Infinity Cache中取得的巨大效果,尽管英伟达不一定会采用一些花哨的新品牌方法,但它在Ada核心中增加了大量L2缓存。
上一代GA102包含6144KB的共享二级缓存,位于其SM的中间,Ada将其增加16倍,以创建98304KB的二级缓存池,供AD102 SM使用。对于RTX 4090版本的芯片,其容量降至73728KB,但仍有大量缓存。每个SM的L1数量没有变化,但因为现在芯片内总共有更多的SM,这也意味着与Ampere相比,L1缓存的数量也更大。
但如今,光栅化并不是GPU的全部。当图灵首次在游戏中引入实时光线追踪时,可能会有这样的感觉,现在它几乎已经成为PC游戏的标准组成。升级也是如此,因此架构如何接近PC游戏的这两大支柱,对于整体理解设计至关重要。
如今的所有三家显卡制造商都专注于光线追踪性能以及升级技术的复杂性,俨然成为他们之间的一场全新战争。
RTX 4090的规格为450W,是一款耗电的GPU,因此PSU越大越好。NVIDIA规定的最低功率为850W,在进行密集的3DMark测试时,已经达到了650W的峰值。RTX 4090需要3个8针电源连接器,或者一个带有新的PCIe 5支持PSU的电源连接器。由于测试平台的PSU刚好符合最低要求,将在未来转向更大的PSU。
关于RTX 4090的冷却器,其设计与上一代RTX 3090相似,但发动机罩下的改进有利于温度。最新型号的风扇更大,同时减少了叶片数量。经过对RTX 4090进行了足够的测试,在3DMark Fire Strike Ultra测试期间,它比3090(总功率650W)多了100W。
阐述完它的硬件规格,下面聊聊其渲染特性。
Ada流式多处理器中发生了真正的变化。光栅化组件可能非常相似,但第三代RT Core已经发生了巨大变化。前两代RT Core包含一对专用单元,即长方体相交引擎和三角体相交引擎,在计算光线跟踪核心的边界体积层次(BVH)算法时,这两个单元从SM的其余部分中提取了大量RT工作量。
Ada引入了另外两个独立的单元来卸载SM的更多工作: Opacity Micromap Engine(OME)和Displaced Micro-Mesh Engine。第一种方法在处理场景中的透明度时大大加快了计算速度,第二种方法旨在分解几何上复杂的对象,以减少完成整个BVH计算所需的时间。

左:Ampere三角形相交示意图,其中射线可能会多次击中浅黄色的三角形,每次击中都会触发一次anyhit着色器。右:Ada的OPACITY MICRO MAPS Shading(OMMS)的纹理渲染技术,配合OME可以显著减少Alpha遍历后的计算。透过 OMMS 技术,射线遇到上图中浅蓝色部分的时候直接忽略掉 anyhit 计算,从而显著提升这类物件的计算量。
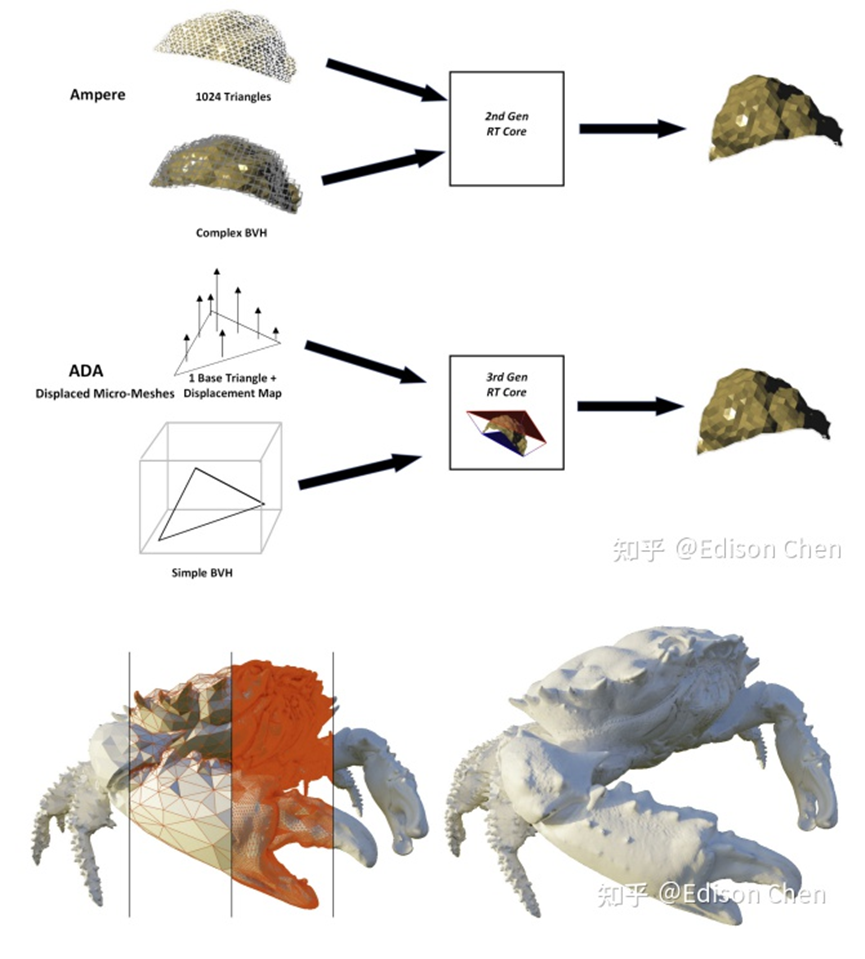
Displaced Micro-Mesh Engine工作机制示意图。
除此之外,Nvidia还称之为“GPU的一项重大创新,就像20世纪90年代CPU的无序执行一样”。创建了着色器执行重新排序(SER)来切换着色工作负载,从而允许Ada芯片通过实时重新调度任务来大大提高图形管线的效率。
Intel一直在为其炼金术师GPU(在新选项卡中打开)开发类似的功能,线程排序单元,以帮助光线跟踪场景中的发散光线。据报道,它的设置不需要开发人员的输入。目前,Nvidia需要一个特定的API来将SER集成到开发者的游戏代码中,正在与微软和其他公司合作,将该功能引入DirectX 12和Vulkan等标准图形API中。
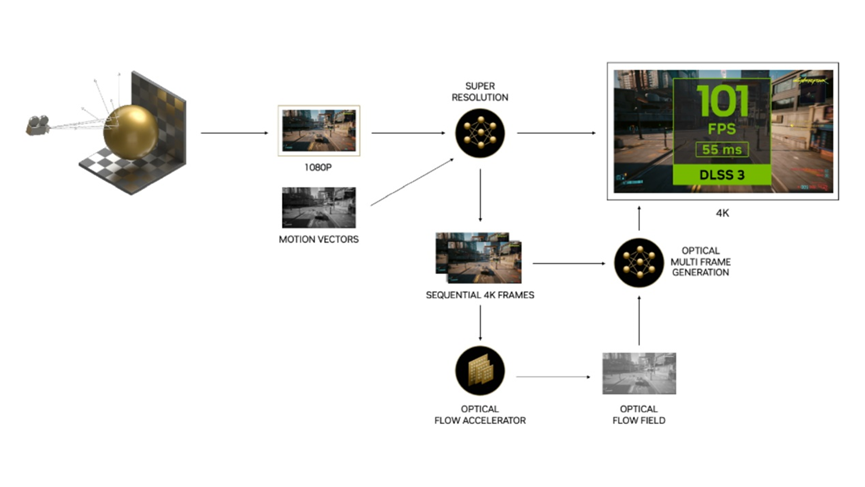
最后来看看DLSS 3.0,它的王牌:帧生成,DLSS 3现在不仅会升级,还会自己创建整个游戏帧。不一定是从头开始,而是通过使用AI和深度学习的力量,对下一帧的外观进行最佳猜测,如果真的要渲染它,然后它在下一个真正渲染的帧之前注入AI生成的帧。
这是巫毒,是黑魔法,是黑暗的艺术,而且相当壮观。它使用第四代张量核内的增强型硬件单元(称为光流单元)进行所有这些飞行计算,然后利用神经网络将先前帧中的所有数据、场景中的运动矢量和光流单元拉到一起,以帮助创建一个全新的帧,该帧还能够包括光线追踪和后期处理效果。

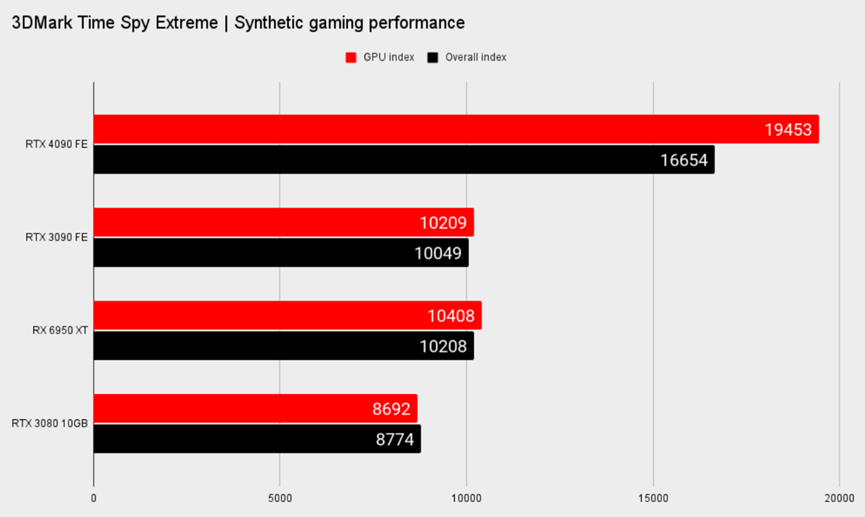
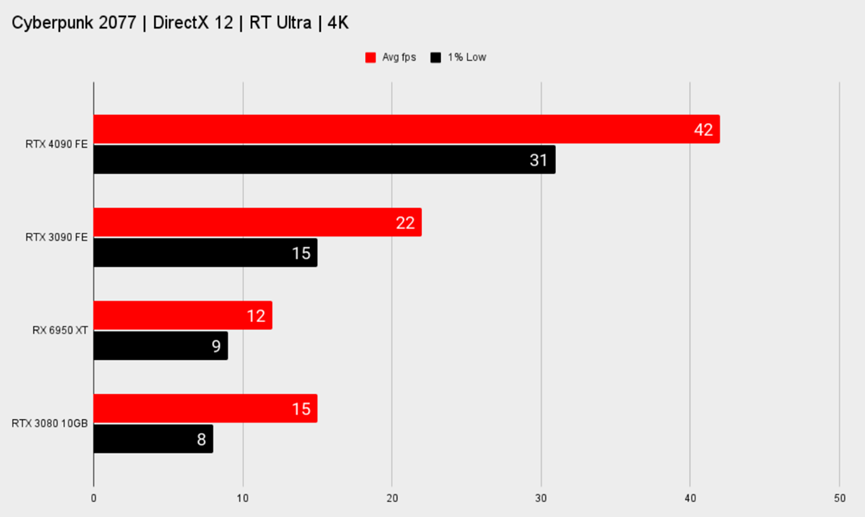
英伟达与DLSS升级(现在称为DLSS超级分辨率)一起工作时表示,在某些情况下,AI将通过升级生成初始帧的四分之三,然后使用帧生成生成整个第二帧。总的来说,它估计AI正在创建所有显示像素的八分之七。它在3DMark Time Spy Extreme的得分是大安培核心的两倍,在光线追踪或DLSS加入之前,原始硅提供的4K帧速率也是《赛博朋克2077》的两倍。
赛博朋克2077的对比数据如下:
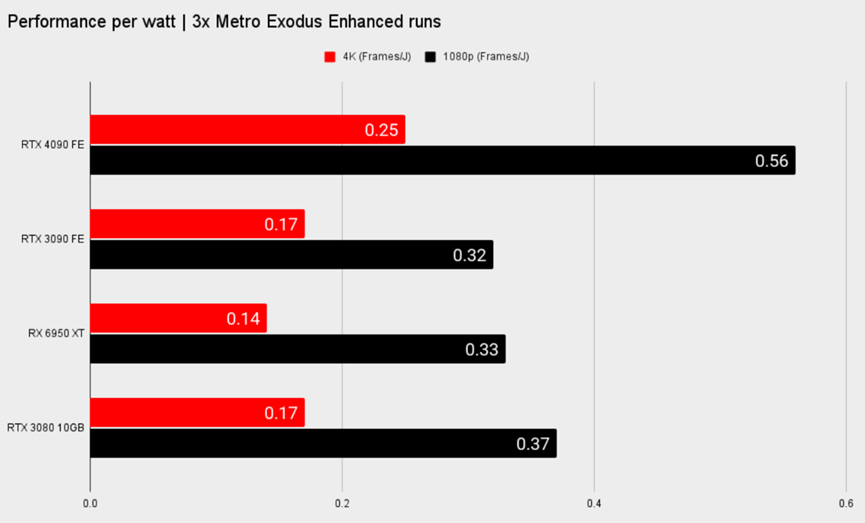
在能效方面,4090的平均功率高于3090约18%,每瓦特的性能是3090的1.75倍(1080P),平均温度比3090低约4.5%。
10 谬论与陷阱
GPU的发展和变化如此之快,以至于出现了许多谬误和陷阱,此节介绍其中一部分。
10.1 谬论:GPU只是SIMD向量多处理器
很容易得出这样的错误结论:GPU只是简单的SIMD向量多处理器。GPU有一个SPMD风格的编程模型,程序员可以编写一个在多个线程实例中使用多个数据执行的程序,但这些线程的执行不是单纯的SIMD或向量,实际上它是单指令多线程(SIMT)。每个GPU线程都有自己的标量寄存器、线程专用内存、线程执行状态、线程ID、独立执行和分支路径以及有效的程序计数器,并且可以独立地寻址内存。尽管当用于线程的PC相同时,一组线程(如32个线程的warp)执行效率更高,但不是必需的,所以多处理器并非纯粹的SIMD。线程执行模型是MIMD,具有屏障同步和SIMT优化。如果单个线程加载/存储内存访问也可以合并为块访问,则执行效率更高,但不是绝对必要。在纯SIMD向量架构中,不同线程的内存/寄存器访问必须以规则向量模式对齐,GPU对寄存器或存储器访问没有这种限制,然而,如果线程的warp访问局部数据块,则执行效率更高。
与纯SIMD模型相比,SIMT GPU可以同时执行多个线程warp。在图形应用中,可能有多组顶点程序、像素程序和几何程序同时在多处理器阵列中运行,计算程序也可以在不同的warp中同时执行不同的程序。
10.2 谬论:GPU性能的增长速度不能超过摩尔定律
摩尔定律只是一个速率,不是任何其他速率的“光速”限制。摩尔定律描述了一种预期,即随着时间的推移,随着半导体技术的进步和晶体管的变小,每个晶体管的制造成本将呈指数下降。换言之,在制造成本不变的情况下,晶体管的数量将成倍增加。戈登·摩尔(Gordon Moore)预测,在相同的制造成本下,每年将提供大约两倍的晶体管数量,后来将其修改为每2年增加一倍。尽管摩尔在1965年做出了最初的预测,当时每个集成电路只有50个组件,但事实证明这一预测非常一致。晶体管尺寸的减小在历史上也有其他好处,例如每个晶体管的功率更低,恒定功率下的时钟速度更快。
越来越多的晶体管被芯片设计师用来制造处理器、内存和其他组件。一段时间以来,CPU设计者使用额外的晶体管以类似摩尔定律的速度提高处理器性能,以至于许多人认为每18-24个月处理器性能增长两倍是摩尔定律。事实上,事实并非如此。
微处理器设计人员将一些新晶体管用于处理器核心,改进了架构和设计,并通过流水线实现了更高的时钟速度。其余的新晶体管用于提供更多的缓存,以加快内存访问速度。相比之下,GPU设计者几乎不使用任何新晶体管来提供更多缓存,大多数晶体管用于改进处理器内核和添加更多处理器内核。GPU通过四种机制加快速度:
- GPU设计人员通过应用成倍增加的晶体管来构建更并行、从而更快的处理器,直接获得摩尔定律的好处。
- GPU设计者可以随着时间的推移改进架构,提高处理效率。
- 摩尔定律假设成本不变,因此,如果花费更多的钱购买更大的芯片和更多的晶体管,显然可以超过摩尔定律的比率。
- GPU内存系统通过使用更快的内存、更宽的内存、数据压缩和更好的缓存,以几乎与处理速度相当的速度增加了有效带宽。
这四种方法的结合在历史上允许GPU性能定期翻倍,大约每12到18个月一次,超过了摩尔定律的速度,已经在图形应用程序上演示了大约10年,并且没有明显放缓的迹象。最具挑战性的限速器似乎是内存系统,但竞争性创新也在迅速推进。
10.3 谬论:GPU仅渲染3D图形不能做通用计算
GPU用于渲染3D图形以及2D图形和视频。为了满足图形软件开发人员在图形API的接口和性能/功能要求中所表达的需求,GPU已经成为大规模并行可编程浮点处理器。在图形领域,这些处理器通过图形API和晦涩难懂的图形编程语言(OpenGL和Direct3D中的GLSL、Cg和HLSL)进行编程。然而,没有什么可以阻止GPU架构师将并行处理器内核暴露给没有图形API或神秘图形语言的程序员。
事实上,Tesla架构的GPU系列通过一个名为CUDA的软件环境来暴露处理器,该软件环境允许程序员使用C语言和C++开发通用应用程序。GPU是图灵完备的处理器,因此它们可以运行CPU可以运行的任何程序,尽管可能不太好,也许更快。
10.4 谬论:GPU无法快速运行双精度浮点程序
在过去,GPU根本无法运行双精度浮点程序,除非通过软件仿真,但软件仿真一点都不快。GPU已经从索引算术表示(颜色查找表)到每个颜色分量8位整数,再到定点算术,再到单精度浮点,后又增加了双精度。现代GPU几乎所有计算都采用单精度IEEE浮点运算,并且开始使用双精度运算。
GPU可以支持双精度浮点和单精度浮点,只需少量额外成本。如今,双精度运行速度比单精度运行速度慢,大约慢5到10倍。对于增加的额外成本,随着更多应用的需要,双精度性能可以在阶段中相对于单精度提高。
10.5 谬论:GPU不能正确执行浮点运算
至少在Tesla体系结构系列处理器中,GPU执行IEEE 754浮点标准规定的单精度浮点处理。因此,就精度而言,GPU与任何其他符合IEEE 754的处理器一样。
如今的GPU没有实现标准中描述的某些特定功能,例如处理非规范化的数字和提供精确的浮点异常,但Tesla T10P GPU提供了完整的IEEE舍入、融合乘加和双精度非规范化数字支持。
10.6 谬论:O(n)算法很难加速
无论GPU处理数据的速度有多快,向设备传输数据和从设备传输数据的步骤可能会限制具有O(n)复杂性的算法的性能(每个数据的工作量很小)。当使用DMA传输时,PCIe总线上的最高传输速率约为48 GB/秒,而对于非DMA传输则稍低,相比之下,CPU对系统内存的访问速度通常为8–12 GB/秒。例如矢量加法,将受到输入到GPU的传输和计算返回输出的限制,有三种方法可以克服传输数据的成本:
- 尽量将数据留在GPU上,而不是在复杂算法的不同步骤中来回移动数据。CUDA故意在两次启动之间将数据单独留在GPU中以支持这一点。
- GPU支持复制入、复制出和计算的并发操作,因此数据可以在设备进行计算时流入和流出设备。该模型对于任何可以在到达时处理的数据流都很有用。例如视频处理、网络路由、数据压缩/解压缩,甚至更简单的计算,如大向量数学。
- 将CPU和GPU一起使用,通过将工作的子集分配给每一个来提高性能,将系统视为异构计算平台。CUDA编程模型支持将工作分配给一个或多个GPU,以及在不使用线程的情况下继续使用CPU(通过异步GPU功能),因此保持所有GPU和CPU同时工作以更快地解决问题相对简单。
10.7 陷阱:只需使用更多的线程来覆盖更长的内存延迟
CPU内核通常被设计为以全速运行单个线程。要全速运行,每个指令及其数据都需要在该指令运行时可用。如果下一条指令未就绪或该指令所需的数据不可用,则该指令无法运行,处理器将停滞。外部内存与处理器相距较远,因此从内存中获取数据需要许多周期的浪费执行。
因此,CPU需要大型局部缓存来保持运行而不停滞,内存延迟很长,因此可以通过努力在缓存中运行来避免。在某些情况下,程序工作集的需求可能比任何缓存都大,一些CPU使用多线程来容忍延迟,但每个内核的线程数通常被限制在一个小数目。
GPU策略不同。GPU内核设计为同时运行多个线程,但一次只能从任何线程执行一条指令。另一种说法是GPU缓慢地运行每个线程,但总体上高效地运行线程。每个线程都可以容忍一定的内存延迟,因为有其他线程可以运行。
这样做的缺点是需要多个多线程来覆盖内存延迟。此外,如果内存访问在线程之间分散(scattered)或不是相关的(correlated),那么内存系统在响应每个单独的请求时会逐渐变慢,最终即使是多个线程也无法覆盖延迟。因此,陷阱在于,对于“只使用更多线程”策略来覆盖延迟,必须有足够的线程,并且线程必须在内存访问的位置方面表现良好。
电源
着重阐述移动设备的电源技术。
智能手机已成为日常生活中不可替代的商品。无论是职业还是个人生活,每项任务都以某种方式或其他方式与这些设备相关。为了满足日益增长的依赖,这些智能手机每天都在变得更加强大。强大的处理器、更多的存储空间和改进的摄像头是每个买家都想要的功能。
除了操作系统,消费者还使用各种应用程序,这些应用程序使用设备的不同传感器和处理能力。所有这些过程都需要一个电源来运行,移动设备中则是一个电池。这些电池必须不时充电,以保持流程正常运行。更长的电池寿命是选择智能手机的另一个重要标准,与电池寿命优化相关的技术发展速度与智能手机行业的其他垂直行业不同。
通过硬件和软件技术可以提高智能手机的电池寿命。改变硬件可能意味着安装更大的电池,但也意味着增加智能手机的尺寸。设计高效的电源管理单元和高效的集成电路(IC)是一种可行的解决方案。此外,操作系统中管理电池密集型应用程序和明智使用可用电池的软件改进也被视为该问题的另一个潜在解决方案。
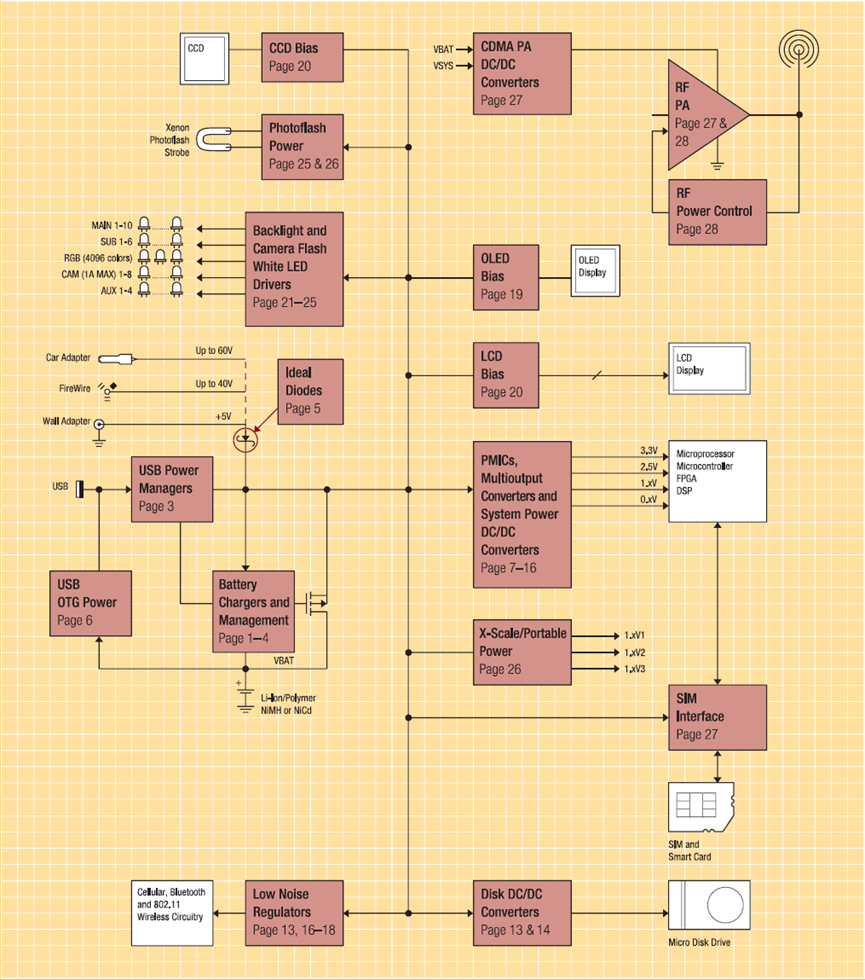
下图是一款便携式产品的电源管理:
智能手机的耗电组件多种多样,常见的如下图所示: