利用发现的数据来创建合成声音是具有挑战性的,因为现实世界的录音通常包含各种类型的音频退化。解决这个问题的一种方法是使用增强模型对语音进行预增强,然后使用增强后的数据进行文本转语音(TTS)模型训练。本论文研究了使用条件扩散模型进行广义语音增强,旨在同时解决多种类型的音频退化。增强是在对数Mel频谱领域中进行的,以与TTS训练目标保持一致。引入文本信息作为附加条件以提高模型的鲁棒性。对现实世界录音的实验证明,使用该模型增强的数据构建的合成声音比那些使用强基线增强的数据进行训练的声音产生了更高质量的合成语音。
引言
通常情况下,文本转语音(TTS)模型是通过精心录制的数据库进行训练的。然而,收集这样的录音是昂贵且有时不切实际的。在实际应用中,有时只能获得目标说话者的低质量录音。这促使人们研究如何利用现成的数据进行语音合成,即并非专门为开发TTS系统而录制的语音数据[1–8]。
在这种情况下开发TTS系统是具有挑战性的,因为发现的数据受到音频质量的高度变化影响。直接使用低质量录音来构建合成声音将不可避免地产生失真的语音。先前的研究尝试在TTS框架内解决这个问题,通过给声学模型增加额外的噪声嵌入[7, 8]。这使得TTS模型可以使用带噪声的语音进行训练,但并未考虑其他形式的音频退化对结果的影响。背景噪声并不是现实录音中唯一存在的干扰。考虑到这一点,预先利用一个单独的模块对发现的数据进行增强可能更为实际,就像[1–4]中所做的那样,尤其是考虑到最近在广义语音增强[9–13]方面的进展,该方法旨在同时解决多种类型的音频退化。
在本研究中,我们提出直接对对数Mel频谱图进行增强,以与TTS训练目标保持一致,并使用条件扩散模型进行广义语音增强。选择扩散模型的动机来自Palette的工作[14],该工作使用单个通用扩散模型处理一系列图像到图像的转换任务。Mel频谱图是一种时频表示,可以视为图像。因此,我们预期扩散模型在Mel频谱图增强方面会很有效。为了提高模型对未知音频退化形式的鲁棒性,将语音的文本内容作为附加条件,这在TTS训练的上下文中通常是可用的。
我们将所提出的增强模型应用于一个真实的语音生成案例:为一位患有喉切除术的男性粤语说话者开发个性化的合成声音,他提供了37分钟的现成录音。这位先生在几年前失去了说话的能力。他提供的录音虽然包含多种类型的退化,但是是唯一可用且珍贵的记录了他声音的资料。我们使用不同系统增强的语音来训练TTS模型。由人类听众进行的主观评估显示,使用所提出的模型增强的语音构建的合成声音在干净度和整体印象方面都比那些使用强语音增强基线增强的数据训练的合成声音评分更高。
相关工作
2.1. 利用发现的数据进行语音合成 许多先前的研究都在解决利用发现的数据进行语音合成的问题。[5, 6]设计了算法来自动从众包数据中选择干净的录音。其他研究考虑了在发现的数据中根本没有高质量样本的情况。[7, 8]在TTS模型中增加了额外的噪声嵌入,使得在TTS训练期间可以将环境噪声与清晰的语音分离。另一种研究方法[1–4]分为两个步骤:预先增强低质量的语音音频,然后使用增强后的数据进行TTS模型训练。
2.2. 广义语音增强 一些先前的工作[9–13]在解决广义语音增强问题时,即同时处理多种类型的音频退化方面取得了进展。他们的成功依赖于对音频退化的良好模拟和先进的神经网络架构。其中大多数模型在波形或幅度谱上运作。然而,对于通常设计用于预测紧凑声学表示(例如Mel频谱图)的TTS声学模型来说,增强后的语音可能不够理想。
2.3. 基于扩散的语音增强 在[13, 15–17]中已经研究了使用扩散模型进行语音增强的方法。其中大多数模型都源自于基于扩散的神经声码器[18],通过用退化的Mel频谱图替换干净的Mel频谱图作为输入。然而,这种设计可能没有充分利用扩散模型在语音增强任务上的优势,因为增强工作主要由条件网络完成。我们的工作与[19]最相似,在该工作中,扩散模型被用于复杂的短时傅里叶变换(STFT)领域的语音增强。然而,他们的模型只针对降噪,并没有专门为开发TTS系统进行优化。
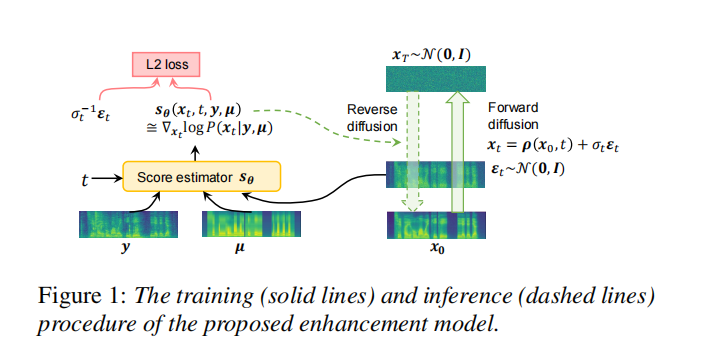
当我们给定一个大型的Mel频谱图对集合,表示为 $D = {x^{(i)}, y^{(i)}}_{i=1}^N$,其中 $x^{(i)}$ 代表高质量语音样本的Mel频谱图,而 $y^{(i)}$ 代表相应降质样本的Mel频谱图。$y^{(i)}$ 可以通过对 $x^{(i)}$ 应用人工音频退化得到。我们感兴趣的是学习在 $D$ 上的条件分布 $P(x|y)$。如果 $D$ 被构造成具有代表性的样本集,那么可以通过从学习得到的条件分布中进行采样来实现Mel频谱图增强。在这里,采用扩散模型来学习 $P(x|y)$ 的参数化近似。
3.1. 条件扩散过程 我们考虑Variance Preserving (VP)扩散模型[20, 21]。假设 x0 ∼ P(x|y) 是通过增强降质输入 y 而得到的一个增强样本。VP扩散定义了前向过程为: ���=−12������+�����(1)dxt=−21βtxtdt+βt
其中,�∼�(0,1)t∼U(0,1),��=�0+�1�βt=β0+β1t 是预定义的线性噪声调度器,��wt 是标准布朗运动。
由(1)得到的一个重要结果是给定 �0x0,��xt 的条件分布为: �(��∣�0)=�(�(�0,�),��2�)(2)P(xt∣x0)=N(ρ(x0,t),σt2I)(2)
其中,�(�0,�)=�−12∫0������0ρ(x0,t)=e−21∫0tβsdsx0,��2=1−�−∫0�����σt2=1−e−∫0tβsds。
(2) 给出的良好性质表明,如果 �0x0 已知,我们可以使用再参数化技巧来采样 ��xt: ��=�(�0,�)+����,��∼�(0,�)(3)xt=ρ(x0,t)+σtϵt,ϵt∼N(0,I)(3)
此外,当 �→1t→1 时,通过适当的噪声调度器 ��βt,我们有 �(�0,�)→0ρ(x0,t)→0 和 ��→1σt→1,这意味着前向过程逐渐将数据分布从 �(�∣�)P(x∣y) 转换为标准高斯分布 �(0,�)N(0,I)。
扩散模型通过反转上述前向过程生成样本,从一个高斯噪声开始: ���=−12��[��+∇��log�(��∣�)]��(4)dxt=−21βt[xt+∇xtlogP(xt∣y)]dt(4)
注意,反向过程是在条件 �y 下进行的,以实现条件生成。扩散模型的核心部分是训练一个神经网络 ��Sθ 来估计 ∇��log�(��∣�)∇xtlogP(xt∣y)(也称为得分)。一旦对所有时间步骤得分估计已知,我们可以通过从 �=1t=1 到 �=0t=0 模拟反向过程来从 �(�∣�)P(x∣y) 中抽样,通常使用ODE求解器[22]。
3.2. 鲁棒的文本条件
如前所述,Mel频谱图增强模型依赖于一组成对样本的合成数据集来学习条件分布 P(x|y)。因此,训练样本和真实世界的降质录音之间存在一个领域差异是不可避免的。因此,训练得到的模型可能会过拟合到数据集内部,无法很好地泛化到未见过的音频退化。
为了提高模型的鲁棒性,我们引入语音样本的文本内容作为附加条件。在TTS开发的上下文中,通常会提供文本转录,并且已经证明它可以提高SE模型的鲁棒性[23, 24]。受到GradTTS [25]的启发,我们使用一个平均Mel频谱图 µ 来表示文本。µ 的形状与 y 相同,并通过以下三个步骤获得。首先,将每个训练样本的文本转录通过强制对齐转换为时间对齐的音素序列。其次,通过对应于相同音素的语音帧的平均值,在训练数据上创建一个音素到Mel频谱的字典。然后,通过查阅字典,给定任何时间对齐的音素序列,得到相应的平均Mel频谱图 µ。
当提供文本时,反向过程可重写为: ���=−12��[��+∇log�(��∣�,µ)]��(5)dxt=−21βt[xt+∇logP(xt∣y,µ)]dt(5)
3.3. 训练和推断
遵循[20]的方法,我们使得得分估计器 ��Sθ 了解时间步,并使用加权的 L2 损失对其进行训练: �(�)=��,��2�(�0,�)���[��(��,�,�,�)+��−1��2��2]2L(θ)=Et,σt2E(x0,y)Eϵt[2σt2