期中考试结束了,来填坑,因为真正接触到了玄学和银河的部分,也算是试验了几天的成果把(
在上一个文章中, 我们已经提到了, 通过本课程学到的各种技巧, 我们将准确度提升到了80%, 这已经超过了大多数CS231N博客的效果了. 但是毕竟这个是在基本的卷积网络架构去操作的, 所以后续想要再提升, 就只能依靠更换网络架构了. 我看了一圈, CS231N怎么说只算是一个领进门的, assignment3更多介绍了RNN, GAN这样的其它类型的神经网络, 却没有看到2017年之前那个神经网络快速发展的年代, 巨人们用了哪些精妙的网络结构去提升识别准确度. 下面我们就开始吧.
本次试验其实只算是把别人的操作粗略玩一遍, 算是一个综述类的博客, 实际上如果我们有足够的耐心, 对前面和后面提到的所有操作更细致的调整一遍, 效果还能显著提升.
学习率衰减/退火
这是一个大多数博客都提到的一个技术点, 其也在讲义说到了, 但是我们并未实操. 因为lr不变的情况下, 结果会在最优的位置不断振荡.
实际上的衰减方法有如下几种: (pytorch必须掌握的的4种学习率衰减策略 - 知乎 (zhihu.com))
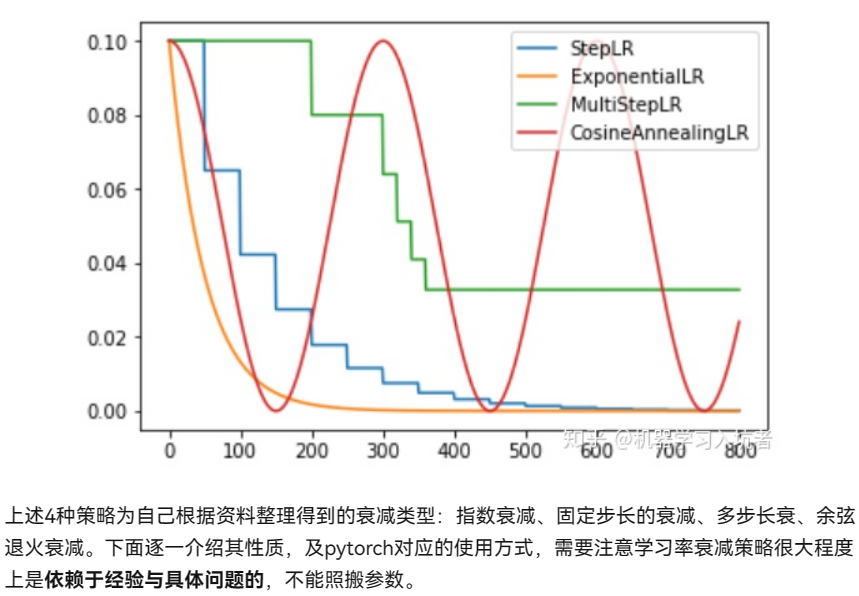
实际上, step和Multistep相当于我们更加精细地去调节衰减地具体过程, 根据前面的训练过程制定计划.
我们选取最简单也是最常用的指数衰减, 因为只有40个epoch, 所以我们直接选择指数系数为0.9, 作为补偿, 我们同时将adam的学习率提升为1.5e-3.
for p in optimizer.param_groups: # 每个epoch执行一次. 也可以视情况选择间隔epoch
p['lr'] *= 0.9或者直接用pytorch封装的函数:
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer_ExpLR, gamma=0.9) # 绑定优化器
# 循环内
scheduler.step() # 执行衰减操作观察结果我们看到了: 在之前加大了batch_size和epoch数量的基础上, 因为初始的lr增大, 所以收敛速度明显加快, 只用了3个epoch就达到了70%的准确率, 而因为学习率衰减, 到后期准确率可以稳定在80%以上.
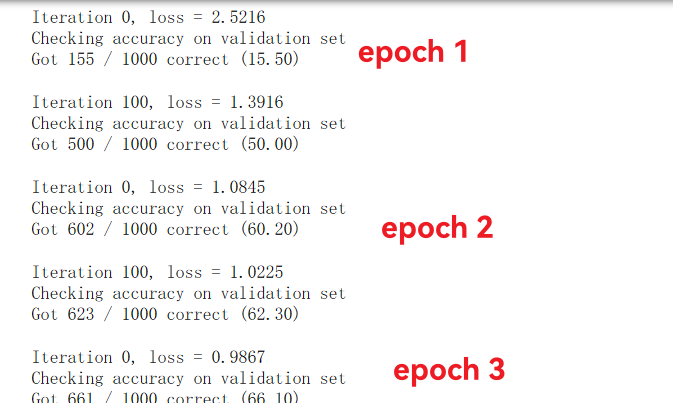
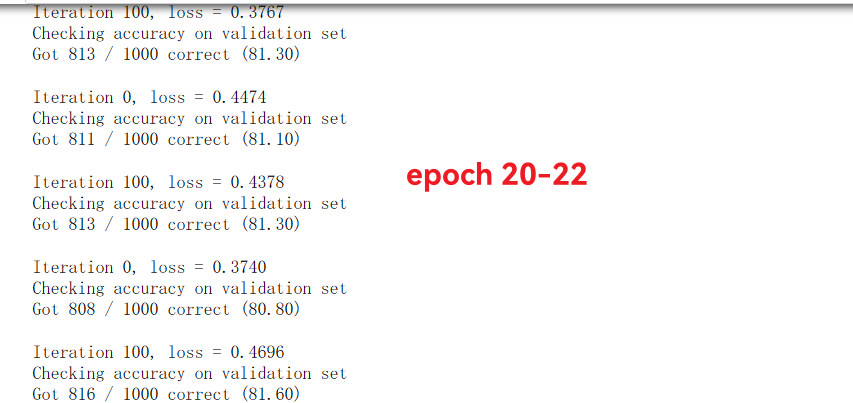
最终我们在相同的场景下实现了81.2%的准确率(+1.4%), 稳定达到了预期的网络性能上限. 证明了这个方法确实是对更好结果有帮助的.
VGG16
我们是时候看一下更高级的网络了. 这个网络怎么说呢, 其实也就是疯狂怼深度的代表, 下面的组织方式大概就是深度神经网络的发展历史, 可以看看ILSVRC-ImageNet历年竞赛冠军_AI强仔的博客-CSDN博客 ,更深入了解网络的进化.
VGG是2014年的ImageNet亚军, 原本不是为了CIFAR10设计的网络. 原始的VGG有数个版本, 我们选取的是VGG16, 其架构如下, 每一层都采用的是3*3的卷积核.
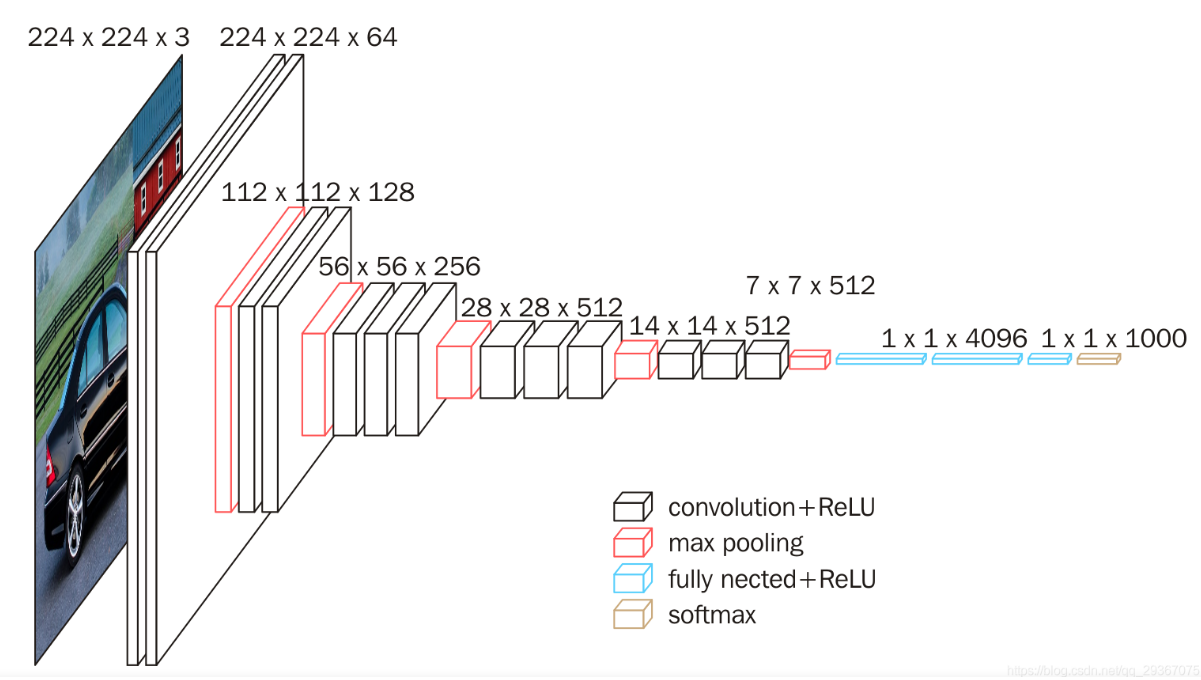
至于为什么是这个尺寸呢? 文章一文读懂VGG网络 - 知乎 (zhihu.com)说的很好, 因为前辈alexnet用的卷积核很大, 而这里采用了3*3的卷积核卷积数次, 代替更大尺寸, 达到了相同的感受野, 同时增加深度. 例如112*112*128之后, 3*3卷积了两次, 其实质上和一个5*5的卷积核等价. 这样,两层卷积等价5*5, 三层等价7*7, 和我们之前疯狂试验卷积核的大小有本质区别.
我们可以加载pytorch提供好的网络模型, 查看架构.
import torchvision
net = torchvision.models.vgg16(pretrained=True) #从预训练模型加载VGG16网络参数
print(net)输出实在太长, 这里就不详细写了, 直接放图, 想认真看的可以放大.

我们的操作其实没什么区别, 只是图像相比原来的小了7*7, 所以全连接层输入元素个数需要做一定的修改,而中间的隐含层也需要根据需要做修改. 这样, 只需要照抄上面的代码, 就可以搭建自己的VGG了. 但是照抄实在是效率太低, 既然有给你, 为什么不照着改呢? 完整的用法可以参考pytorch对网络层的增,删, 改, 修改预训练模型结构_pytorch修改网络结构__-周-_的博客-CSDN博客 ,现在例如我们修改隐含元素数量为256, 就可以这么做:
model = torchvision.models.vgg16(pretrained=False)
model.avgpool = nn.Sequential() # 删除这层平均池化, 保证维度一致
model.classifier[0] = nn.Linear(in_features=512,out_features=256,bias=True)
model.classifier[3] = nn.Linear(in_features=256,out_features=256,bias=True)
model.classifier[6] = nn.Linear(in_features=256,out_features=10,bias=True)
optimizer = optim.Adam(model.parameters(), lr=0.0015)仍然采用前面的参数进行训练. 更深的网络让我的显卡直接完全跑满了,显存占用也来到了2.2G, 训练速度明显变慢了(在我的2060Super矿卡上大概15s/epoch), 这些是之前不曾有的(之前的网络CUDA占用大约只有38%). 中间出现了明显的过拟合, 训练集准确率近乎100%, 但验证集在75%上下浮动. 效果不算很好, 最终得准确率收于76.3%. 看了其他人得代码, 有人成功利用这个网络做到了91%得准确度(VGG16 训练 Cifar10 --91.64%的成功率 - 知乎 (zhihu.com)) , 我发现了一个事实, 网络只能决定上限, 不能决定下限, 如果参数和一些trick用得不好, 效果很有可能不及预期. 不过这里我们暂时打住, 我们先去看看其他网络, 后面我会有一个专题来讨论.
Resnet18
你在Bing搜索这个名字首先就看到了单纯的深度神经网络一些问题 - 随着网络深度增加, 训练和优化变得困难, 有时会产生退化问题, 可能产生梯度消失/梯度爆炸, 和前面的结论一致. 如同论文说到, 因为残差函数更好学习(就好比你去拟合一个函数, 肯定是做差啥的, 最小二乘啥的, 不会不参考原本的数据点乱试). 做差也让一些细小的波动更容易被捕捉.
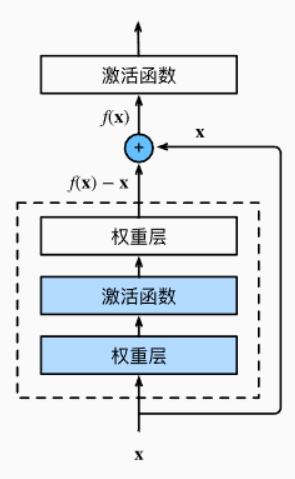
和前面一致, 我们可以直接用别人的网络去进行替换. 不过最后我们也会说明怎么去自己实现这样的网络.

和前面一样,输入的图像是224*224, 但是因为adaptive avgpool的存在, 所以这个网络其实可以直接套用(只要长宽是32的倍数都可以), 只需要将分类改为10分类就可以了.(不过实测不经修改也可以用). 为了加快速度, 我们可以选择pretrained=True选项, 这样训练很快就可以达到80%(注意不能直接用, 因为分类数目不同,否则你会看到1%的准确度hh). 实测自己训练的准确度收于77.8%, 用预训练的模型辅以训练20个epoch后准确度收于82.9%. (注:用更高层次去训练用在这种低阶的任务叫做迁移学习, 例如现在99%的CIFAR10就是这么干的, 但是很多人不认可这个,所以后面我们也不深入探讨) 初始的权重占了很大的优势, 而自己训练过程中出现了过拟合, loss降到了0.0000但是验证集准确度不好.
Densenet
前面的resnet本质上加强了信息流通解决了深度网络的问题, 而densenet更进一步, 各个层之间互相连接.

论文中说到, 对于L层网络, 连接就有L(L+1)/2.
相比于前面, 这个网络的实现更为复杂, 至少看起来不再是那么直观了. 没事, 我们还是先去改动.
pytorch内置了许多不同尺寸的网络, 最简单的是densenet121,你就能看出这个网络有多么深了.
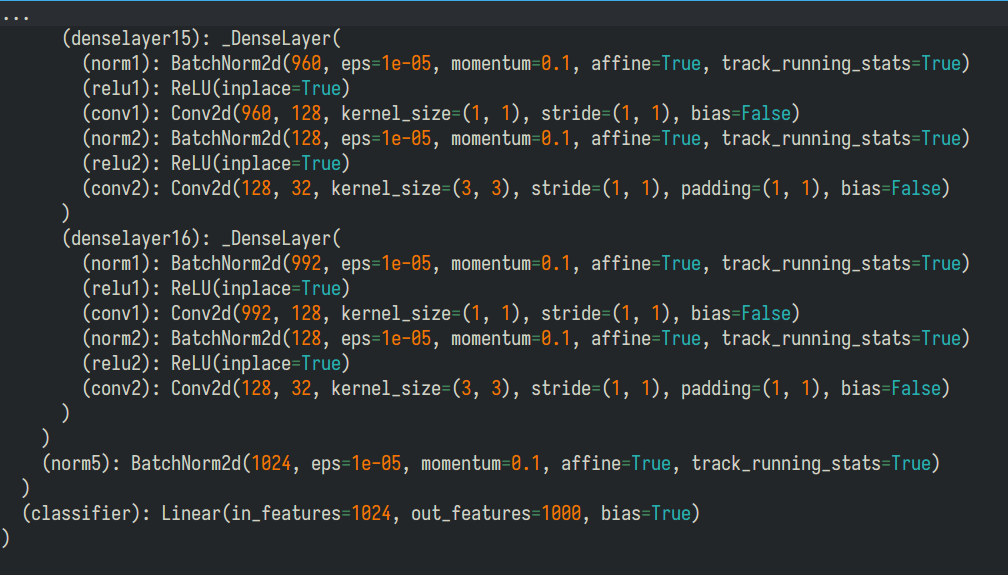
和resnet一样, 这个网络内部有batchnorm, 但是没有dropout(务必注意, dropout和batchnor可能会冲突, 所以这里dropout应当加在全连接层).我们还是仅需修改classifier的内容就可以了. 虽然作者说这个网络的参数没那么多, 但是训练时间还是明显比前面几个网络长了一截... (不过其实120层网络这个速度还行了). 和前面的网络相比, 这个网络可以在第16个epoch达到80%的验证集准确度, 但是最终准确度仍然在80%那样. 同样, 如果选择预训练, 效果更好(大约接近90%). 虽然确实稳步提升, 可惜不能达到我们的预期, 更何况不用别人训练完的模型, 居然连最开始的神经网络都打不过, 实在很难受. 下面我们就一一对看到的现象做一个解释.
开始探究
训练问题
接下来的实验我们在resnet18上进行.和前面一样, 既然预训练效果很好, 我们就不得不怀疑是训练的问题了. 前面已经知道, 影响的因素分为batch_size, 学习率和防止过拟合. 然而现在很遗憾, 即使按照上面的操作全部做了一次, 我也只把这个准确率从77.8提升到了78.1%.
数据增强
下面就要引入图像处理中最有力的防止过拟合的方式. 其他博主在用了这个操作之后都得到准确度的暴增. 所谓数据增强, 就是给数据加上扰动, 同时做到训练数据增多和质量提升, 具体有: 翻转变换、随机修剪)、色彩抖动、平移变换、尺度变换、对比度变换、噪声扰动、旋转变换/反射变换等, 都是顾名思义的.
原理不难, 那采用什么增强方式比较好呢? 根据博主【深度学习】Cifar-10-探究不同的改进策略对分类准确率提高的实验, 数据白化(图像归一化), 翻转和截取. 当然其实课程已经帮我们做好了normalize这一基本步骤. 我首先从最简单的裁切和翻转开始. 参照其他博客,这里我们这样修改:
transform_train = T.Compose([
T.ToTensor(),
T.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
T.Resize([40,40]), #新版本T.Scale(40)不再合法
T.RandomHorizontalFlip(),
T.RandomCrop(32),
])
开始训练. 我们关注训练过程

会发现, loss的波动更大, 下降也变慢了, 但是准确率却上升了, 表明这种方法对于过拟合的抑制效果很好. 然而最终准确率仍然只有78.5%, 这表明我们或许采取的增强方式不是很好. 所以数据增强很讲究方式, 既不能欠拟合, 也不能过拟合. 我将上面更改为了随机裁剪T.RandomCrop(32, padding=4), 效果很显著, 最终的训练集loss在0.16左右波动, 准确度经过40个epoch终于达到83.8%(验证集在84%-85%波动), 超过了最开始的神经网络.与此同时, 我试了更深的resnet121, 准确率为84.7%.(这个网络的潜力其实不止于此) 另外, 这种方法应用在普通卷积网络之后准确度不升反降, 因此这个方法实际上充分发掘了深层网络的学习能力. 进一步加上其他例如垂直翻转,旋转和色彩抖动, 都没能取得更好的效果. 这个也是必须根据实际情况选择. 而且每个操作带来的效果还不一样,着实玄学... 不过你就从CIFAR10来看, 这样完全足够了, 大多数博客也都是这么操作的.
继续试验
为了更详细判定目前是否是出现了欠拟合, 我们可以观察趋势, 或者继续增大epoch. 我们结果发现, 两个模型提升到200个epoch训练(耗时大约半小时), 准确度提升都不足2%,loss也在0.16附近波动. 所以模型此时已经不能很好拟合了, 这除了数据增强方式可能有问题之外, 也有可能是学习率的策略等的问题. 我最初做了几次尝试, 准确率都有大幅下降(甚至有一次只有69%), 甚至于我模仿了如何使CIFAR-10测试集的分类准确率从40%提升到90% 说的策略, 准确度也是下降,说明学习方法确实是很大的影响因素, 这个矛盾在深度网络更加突出!
后面我参考了文章Resnet18训练CIFAR10 准确率95%意识到, 网络结构本身可能也需要修改.我们作为初学者, 可能总是会想着别人提供的模型肯定是最佳优化过的, 但是由于应用场景的不同, 我们需要对网络进行适当的微调. 之前我们没有展示这个网络结构最开始的样子:
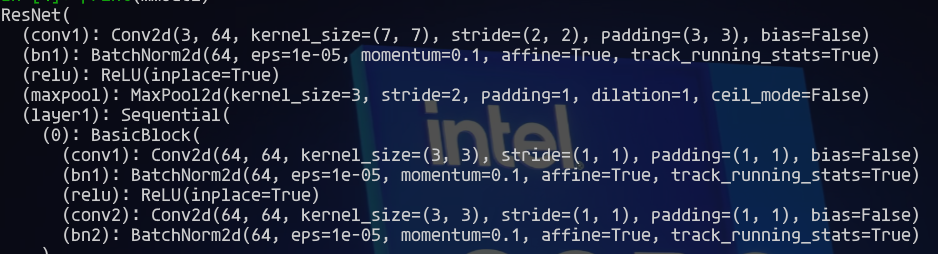
最大的问题就在于, 因为32*32图像太小了, 所以并不适合过大的卷积核. 所以我们将之修改为3*3的卷积, 同时maxpool这里初始化也并无太大意义, 所以应当直接取出.我们同时修改策略为每10个epoch学习率变为原来的1/10的方式尝试. 训练了40个epoch(耗时30分钟左右)之后, 虽然没有达到那篇文章95%的夸张程度, 但是也成功做到了90.2%的准确度, 有了相当明显的提升, 也总算是真正体现了深度网络的优势.同时查看loss和准确率走势发现, 准确率有波动但是仍然在上升, loss下降的趋势也仍然存在.
我们再和那个文章的优化方式同步, 即引入适当的L2正则化惩罚, 下降方法是动量SGD(方法之间确实没有优劣之分,其实原本的adam应该也行,我没试), 进行更长时间的训练, epoch变为80个, 最终准确度93.1%, 如果再继续或许能到94-95%, 但无论如何, 我们也算是明白了操作的基本套路了, 所以我也就到这了.
当然,实际的网络修改方式其实远远不止于此, 但是本质上都源于大量的工程实践, 炼丹本身就不是按照配方调整就好的, 要多尝试多观察. 也期待自己后面能够多总结.
另外, 估计后面真想认真搞可能需要上云了
深度网络的代码实现
结束了探究, 我们还剩最后一个问题: 怎么用代码实现上面的网络呢? 毕竟前面我们都是改别人的. 我们从简单的VGG开始: 虽然VGG层之间没有流动, 可以用传统的sequential写, 但是一个一个太复杂了. 更不要提resnet18这种复杂模型了.
我们知道, nn.sequential实际上就是一个复合的网络, 前面增删改的时候, 我们就用过这种方式来给网络添加层. 这也就表明, 我们实际上可以将网络拆分成数个块分别实现, 并将具体的参数利用函数(比如__init__传参)确定. 下面我们来尝试实现resnet18.
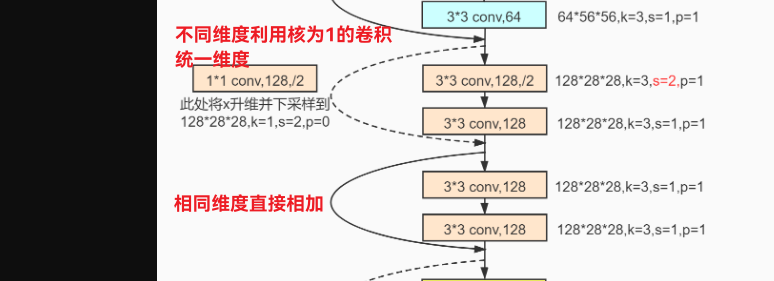
可以看到, 在这个网络中, 存在的基本结构也就两个: 直接相加的残差块和通过卷积层统一维度相加的残差块. 所以我们先实现这两个基本结构: (PyTorch实现ResNet18)
class RestNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride): # 将参数写在__init__内
super(RestNetBasicBlock, self).__init__() # 记得init超类
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)
return F.relu(x + output) # 相加的操作通过forward函数内实现
class RestNetDownBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential( # 原本的x进行downsample的经过层
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
extra_x = self.extra(x) # 原本的x进行downsample的经过层
output = self.conv1(x) # 常规推进
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)
return F.relu(extra_x + out) # 相加这样, 我们写网络也就比较简单了.
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
self.layer4 = nn.Sequential(RestNetDownBlock(256, 512, [2, 1]),
RestNetBasicBlock(512, 512, 1))虽然都很基础, 但都是本人亲自实践而成, 耗时数天的炼丹经历也让自己更加了解了调模型那种讨厌但是欲罢不能的奇妙感受.