Program 1: Parallel Fractal Generation Using Threads
加速比与线程数并不成正比:
| thread nums | serial | thread | speedup |
|---|---|---|---|
| 1 | 395.95 | 395.234 | 1.00x |
| 2 | 394.42 | 201.087 | 1.96x |
| 4 | 395 | 168.894 | 2.34x |
| 8 | 395.28 | 101.748 | 3.84x |
当thread nums为4时,观察每个线程的运行时间,发现有明显的负载不均衡。thread0和3处理的是矩阵的上下两侧,这部分的计算时间小于中间部分。
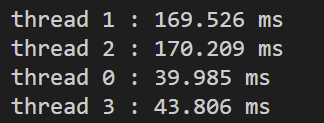
采用一个简单的策略:原来的版本是每个线程处理矩阵的连续的行,现在改为每个线程处理间断的行,以步长为thread nums来处理矩阵行,代码如下:
extern void mandelbrotStep(
float x0, float y0, float x1, float y1,
int width, int height,
int startRow, int totalRows, int step,
int maxIterations,
int output[])
{
float dx = (x1 - x0) / width;
float dy = (y1 - y0) / height;
int endRow = startRow + totalRows * step;
for (int j = startRow; j < endRow; j += step) {
for (int i = 0; i < width; i ++) {
float x = x0 + i * dx;
float y = y0 + j * dy;
int index = (j * width + i);
output[index] = mandel(x, y, maxIterations);
}
}
}
void workerThreadStart(WorkerArgs * const args) {
// TODO FOR CS149 STUDENTS: Implement the body of the worker
// thread here. Each thread should make a call to mandelbrotSerial()
// to compute a part of the output image. For example, in a
// program that uses two threads, thread 0 could compute the top
// half of the image and thread 1 could compute the bottom half.
double startTime = CycleTimer::currentSeconds();
mandelbrotStep(args->x0, args->y0, args->x1, args->y1, args->width, args->height, args->threadId, args->height / args->numThreads, args->numThreads, args->maxIterations, args->output);
double endTime = CycleTimer::currentSeconds();
printf("thread %d : %.3f ms\n", args->threadId, (endTime - startTime) * 1000);
}
测试改进后的代码,加速比有了明显提高:
| thread nums | serial | thread | speedup |
|---|---|---|---|
| 4 | 396.021 | 109.021 | 3.62x |
| 8 | 393.221 | 54.048 | 7.28x |
| 16 | 394.174 | 28.187 | 13.98x |
Program 2: Vectorizing Code Using SIMD Intrinsics
这个实验不难,但是需要有些耐心。
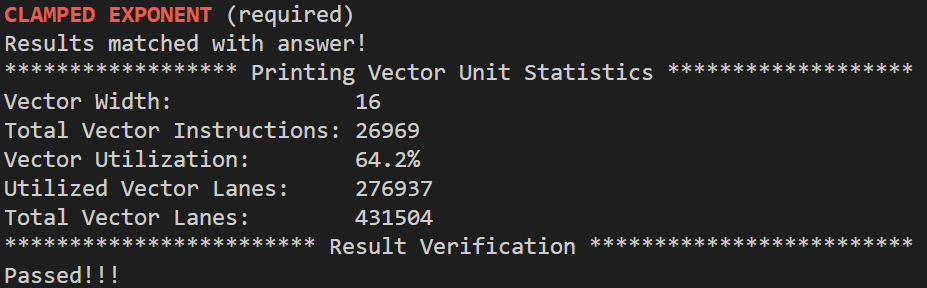
先看一下abs示例,abs示例不能正确处理N%VECTOR_WIDTH!=0的情况,因为最后剩下的元素并没有被处理。从abs示例可以看出,向量化一个串行程序时,用mask代替if-else语句。clampedExpVector的代码是对照clampedExpSerial一条条转换来的,为了实现clampedExpSerial中的while循环,_cs149_cntbits函数统计掩码maskCountGtOne中1的个数,maskCountGtOne表示既在else语句中又满足while循环条件(count>0)的元素,只要至少有一个元素满足这样的条件,向量都会进入到while循环中进行乘法运算,那么如果VECTOR_WIDTH比较大,即使只有少量元素满足循环条件,也必须进入到while循环,这也是当VECTOR_WIDTH递增时,Vector Utilization递减的原因,令数组大小为10000,分别设置VECTOR_WIDTH为2、8、4、16:
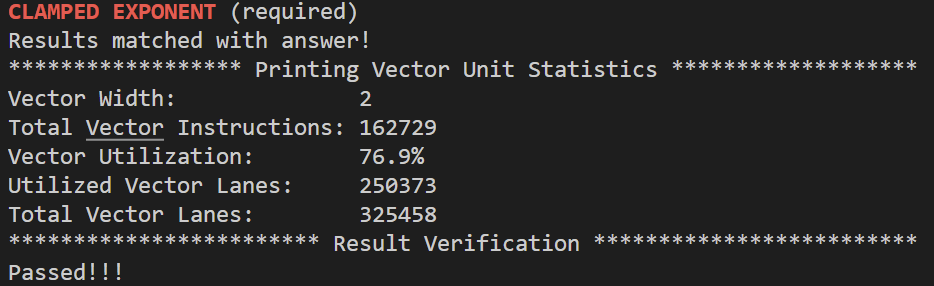
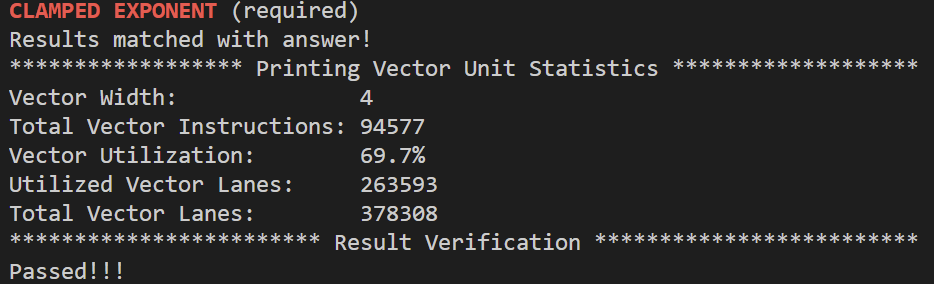
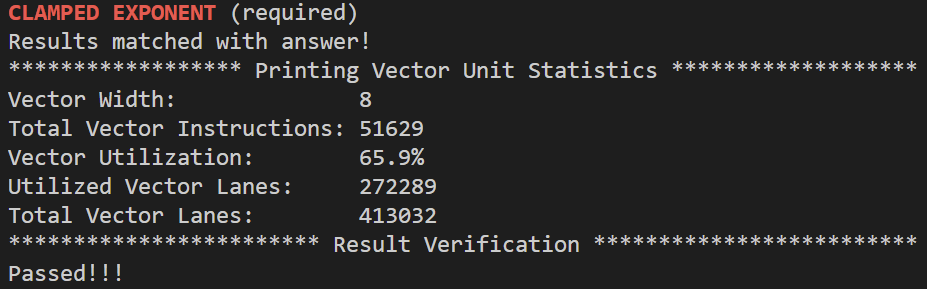
代码如下:
void clampedExpVector(float* values, int* exponents, float* output, int N) {
int i;
__cs149_vec_float x;
__cs149_vec_int y;
__cs149_vec_int count;
__cs149_vec_float result;
__cs149_vec_float floatOne = _cs149_vset_float(1.0f), floatZero = _cs149_vset_float(0.0f), floatMax = _cs149_vset_float(9.999999f);
__cs149_vec_int intOne = _cs149_vset_int(1);
__cs149_vec_int zero = _cs149_vset_int(0);
__cs149_mask maskAll = _cs149_init_ones(), maskExpIsZero, maskExpIsNotZero, maskCountGtOne, maskResultGtMax;
for (i = 0; i + VECTOR_WIDTH <= N; i += VECTOR_WIDTH) {
maskResultGtMax = _cs149_init_ones(0);
_cs149_vload_float(x, values + i, maskAll);
_cs149_vload_int(y, exponents + i, maskAll);
_cs149_veq_int(maskExpIsZero, y, zero, maskAll);
_cs149_vadd_float(result, floatOne, floatZero, maskExpIsZero);
maskExpIsNotZero = _cs149_mask_not(maskExpIsZero);
_cs149_vload_float(result, values + i, maskExpIsNotZero);
_cs149_vload_int(count, exponents + i, maskExpIsNotZero);
_cs149_vgt_int(maskCountGtOne, count, intOne, maskExpIsNotZero);
while (_cs149_cntbits(maskCountGtOne) > 0) {
_cs149_vmult_float(result, result, x, maskCountGtOne);
_cs149_vsub_int(count, count, intOne, maskCountGtOne);
_cs149_vgt_int(maskCountGtOne, count, intOne, maskCountGtOne);
}
_cs149_vgt_float(maskResultGtMax, result, floatMax, maskExpIsNotZero);
_cs149_vadd_float(result, floatMax, floatZero, maskResultGtMax);
_cs149_vstore_float(output + i, result, maskAll);
}
// process the tail
if (i != N) {
i -= VECTOR_WIDTH;
clampedExpSerial(values + i, exponents + i, output + i, N - i);
}
}
arraySumVector的实现里,我没有用interleave函数,时间复杂度是(N / VECTOR_WIDTH + VECTOR_WIDTH),实现很容易,直接把原来的单个元素累加改为向量累加,代码如下:
float arraySumVector(float* values, int N) {
float res = 0;
float v[WINT_WIDTH] = {0.0f};
__cs149_vec_float result = _cs149_vset_float(0.0f), tmp, tmp_h;
__cs149_mask maskALL = _cs149_init_ones();
for (int i=0; i<N; i+=VECTOR_WIDTH) {
_cs149_vload_float(tmp, values + i, maskALL);
_cs149_hadd_float(tmp_h, tmp);
_cs149_vadd_float(result, result, tmp_h, maskALL);
}
_cs149_vstore_float(v, result, maskALL);
for (int i = 0; i < VECTOR_WIDTH; i += 2){
res += v[i];
}
return res;
}
Program 3: A Few ISPC Basics
Part 1
ISPC编译器可以产生8宽度的AVX2指令,理论上加速比可以达到8x,但实际只有4.4+,原因是各instance计算负载不同。
Part 2
原始版本的task程序加速比与非task加速比相同:
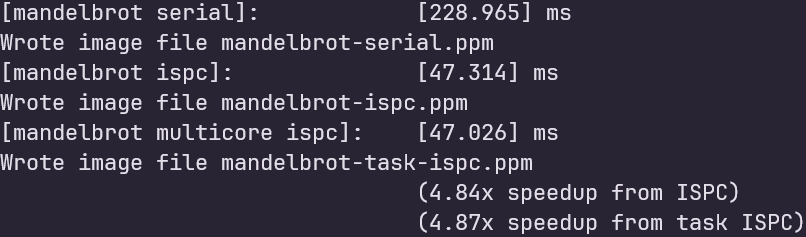
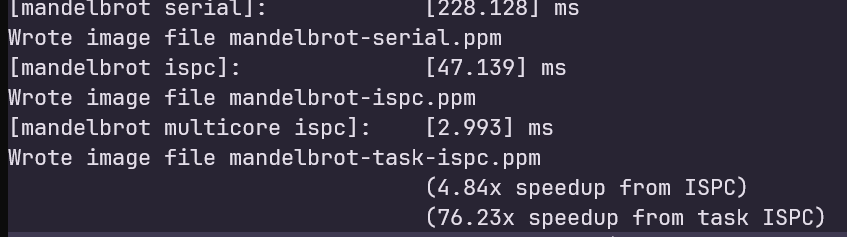
原始task程序将rowsPerTask设置为height的一半,查看main函数中height的值,为800,这里我直接将rowsPerTask设置为1,启动800个task,得到了76x的加速比:
ISPC task和program1中thread的区别
ISPC task主要关注数据间的并行,每个task执行相同的指令,但在不同的数据间操作。而thread更为通用,每个thread都能独立执行不同的任务。
启动10000个ISPC task,如果数据并行性较好,ISPC task能够充分利用SIMD指令,而管理10000个thread可能导致较大的开销。
Program 4: Iterative sqrt
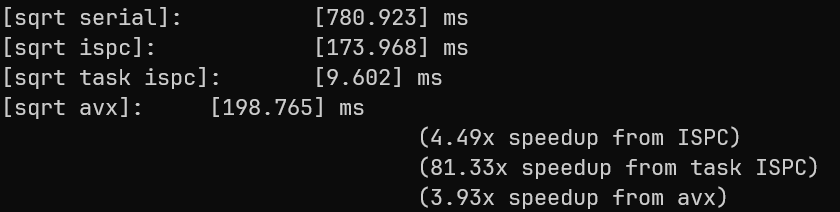
加速比如下图:

根据关系图知,初始数据越靠近3.0f,sqrt中的迭代次数越多, 把数组中的每个元素都设置为2.999f使负载均衡,可以获得最大加速比:

为了验证这个结论,一半数据设置为1.0f,另一半数据设置为2.999f,加速比如下,有了明显下降:

每条AVX2指令可以处理8个数据,即使把每个元素都设置为1.0f还不能够达到最低的加速比,为了让sqrt ispc的加速比最低,利用mask的性质,每8个元素中,有7个1.0f和1个2.999f,测得加速比如下,可以看到sqrt ispc的效率比sqrt serial更差:

AVX版本需要参考intel的文档手写AVX指令,我在这一小节花了很长的时间调试,建议分点调试,例如先完成求绝对值的程序,再接着写后面的逻辑。
void sqrt_avx(int N, float initialGuess, float values[], float output[]) {
static const float kThreshold = 0.00001f;
__m256 threshold = _mm256_set1_ps(kThreshold);
__m256 one = _mm256_set1_ps(1.f);
__m256 zero = _mm256_set1_ps(0.0f);
__m256 half = _mm256_set1_ps(0.5f);
__m256 three = _mm256_set1_ps(3.0f);
for (int i = 0; i < N; i += 8) {
__m256 x = _mm256_loadu_ps(&values[i]);
__m256 guess = _mm256_set1_ps(initialGuess);
// compute (guess * guess * x - 1.f)
__m256 in_abs = _mm256_sub_ps(_mm256_mul_ps(_mm256_mul_ps(guess, guess), x), one);
__m256 mask_abs = _mm256_cmp_ps(zero, in_abs, _CMP_LT_OS);
__m256 in_abs_negative = _mm256_sub_ps(zero, in_abs);
__m256 tmp1 = _mm256_and_ps(mask_abs, in_abs);
__m256 tmp2 = _mm256_andnot_ps(mask_abs, in_abs_negative);
// compute abs(in_abs_negative)
__m256 pred = _mm256_or_ps(tmp1, tmp2);
__m256 mask_pred_gt_kThreshold = _mm256_cmp_ps(pred, threshold, _CMP_GT_OS);
// while mask_pred_gt_kThreshold is not all zero
while (!_mm256_testz_ps(mask_pred_gt_kThreshold, mask_pred_gt_kThreshold)) {
__m256 tmp1, tmp2, tmp3;
__m256 guess_cubic = _mm256_mul_ps(guess, _mm256_mul_ps(guess, guess));
__m256 guess_in_while = _mm256_mul_ps(_mm256_sub_ps(_mm256_mul_ps(three, guess), _mm256_mul_ps(x, guess_cubic)), half);
tmp1 = _mm256_and_ps(mask_pred_gt_kThreshold, guess_in_while);
tmp2 = _mm256_andnot_ps(mask_pred_gt_kThreshold, guess);
guess = _mm256_or_ps(tmp1, tmp2);
__m256 pred_positive = _mm256_sub_ps(_mm256_mul_ps(_mm256_mul_ps(guess, guess), x), one);
__m256 pred_negative = _mm256_sub_ps(zero, pred_positive);
__m256 mask_while_abs = _mm256_cmp_ps(zero, pred_positive, _CMP_LT_OS);
// in while loop but (guess * guess * x - 1.f) is not positive
__m256 mask_while_nabs = _mm256_andnot_ps(mask_while_abs, mask_pred_gt_kThreshold);
// in while loop and (guess * guess * x - 1.f) is positive
mask_while_abs = _mm256_and_ps(mask_while_abs, mask_pred_gt_kThreshold);
tmp1 = _mm256_and_ps(mask_while_nabs, pred_negative);
tmp2 = _mm256_and_ps(mask_while_abs, pred_positive);
tmp3 = _mm256_andnot_ps(mask_pred_gt_kThreshold, pred);
pred = _mm256_or_ps(tmp3, _mm256_or_ps(tmp1, tmp2));
mask_pred_gt_kThreshold = _mm256_cmp_ps(pred, threshold, _CMP_GT_OS);
}
__m256 res = _mm256_mul_ps(x, guess);
_mm256_storeu_ps(&output[i], res);
}
}
在写AVX指令的时,一定要牢记向量的思想!if-else语句用掩码来处理,_mm256_cmp_ps这条指令是用来生成掩码的,具体行为可参考intel的手册。
求绝对值的思路:
用_mm256_cmp_ps指令找出向量中小于0的元素,这一步可以得到掩码,对于这些元素,用临时变量pred_negative存放它们的绝对值,利用掩码配合位运算来生成最终的绝对值向量。
Program 5: BLAS saxpy
虽然划分了64个任务,但是仅能得到1.99x的加速比,这里程序的加速受到了带宽的限制,应该在计算时涉及大量的内存访问。

计算内存带宽时,乘4的的原因是:写result涉及两个访存操作,当写入result时,首先从内存将cache line加载到内存中(cache未命中),向该cache line写入数据,当该cache line被替换时,该cache line被写回到内存。
- Parallelism Multi-Core Exploring Project Multiparallelism multi-core exploring project multi-core multi-core processor lecture2 lecture multi-core processor lecture modern parallelism exploring parallelism lecture1 lecture cmu concurrency parallelism and evaluation exploring humanized models exploring unreal系统ue4