| 这个作业属于哪个课程 | 计科1/2班 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 按照规定流程完成个人项目,完整体验制作项目制作相关流程,制作简易论文查重系统 |
- GitHub作业链接:GitHub作业链接
1.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| ·Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 470 | 480 |
| ·Analysis | 需求分析(包括学习新技术) | 100 | 180 |
| ·Design Spec | 生成设计文档 | 60 | 50 |
| ·Design Review | 设计复审 | 60 | 30 |
| ·Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 40 |
| ·Design | 具体设计 | 100 | 120 |
| ·Coding | 具体编码 | 100 | 60 |
| ·Code Review | 代码复审 | 60 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| ·Reporting | 报告 | 90 | 120 |
| ·Test Repor | 报告测试 | 30 | 60 |
| ·Size Measurement | 计算工作量 | 30 | 60 |
| ·Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 90 | 60 |
| 合计 | 740 | 800 |
2.接口和算法设计部分
- 1)接口部分
- 2)算法部分
| 库 | 函数 | 功能 |
|---|---|---|
| re | compile() | 创建了一个正则表达式模式,用于匹配包含一个或多个中文字符的文本片段 |
| re | findall() | 删除论文标点 |
| simhash | Simhash() | 通过对文档的特征进行哈希计算而得到的。海明距离是用来衡量两个Simhash值在位级别上的差异,其定义是两个Simhash值二进制表示中不同位的数量。用于计算最终查重率 |
| jieba | cut() | 对中文字符串进行分词,方便海明码计算 |
| time | time() | 计算算法运行时间 |
| memory_profiler | profile | 对算法进行性能分析 |
-
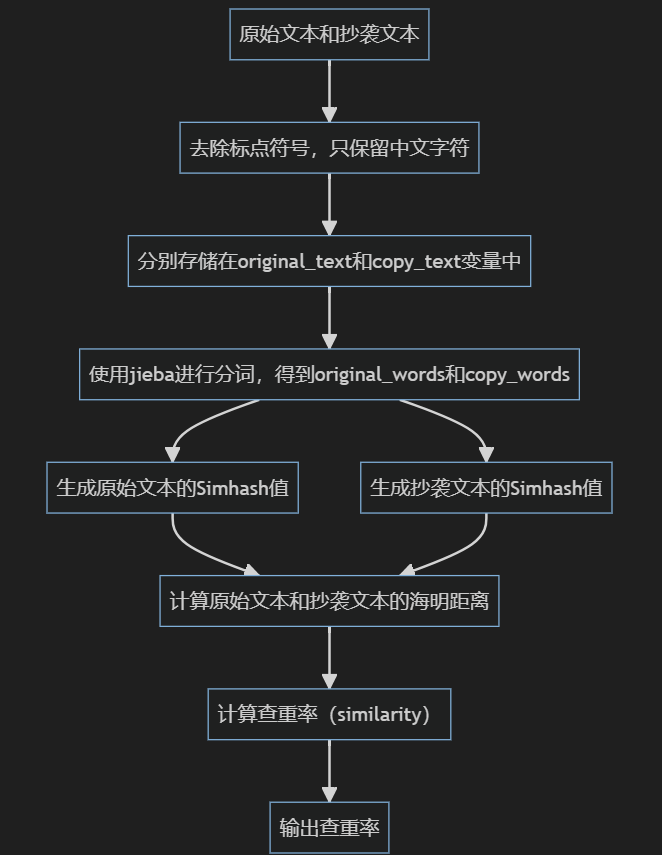
3)流程图
-
4)关键算法具体实现过程
-
1.使用正则表达式模式[\u4e00-\u9fa5]+对原始文本和抄袭文本进行处理,去除标点符号,只保留中文字符。
-
2.将处理后的文本以字符串的形式存储,并赋值给original_text和copy_text变量。
-
3.使用结巴分词工具jieba对字符串进行分词,将原始文本和抄袭文本分别分词,并存储在original_words和copy_words列表中。
-
4.使用Simhash算法生成原始文本和抄袭文本的Simhash值。Simhash是一种用于计算文本相似度的算法。它将文本表示为一个固定位数的二进制数值,其中相似的文本具有较高的汉明距离,而不相似的文本具有较低的汉明距离。
-
5.计算原始文本和抄袭文本的海明距离(Hamming Distance),即Simhash值之间的汉明距离。海明距离表示两个Simhash值二进制表示中不同位的数量。
-
6.根据海明距离计算查重率(similarity),查重率的计算公式为:1 - (海明距离 / 64)。
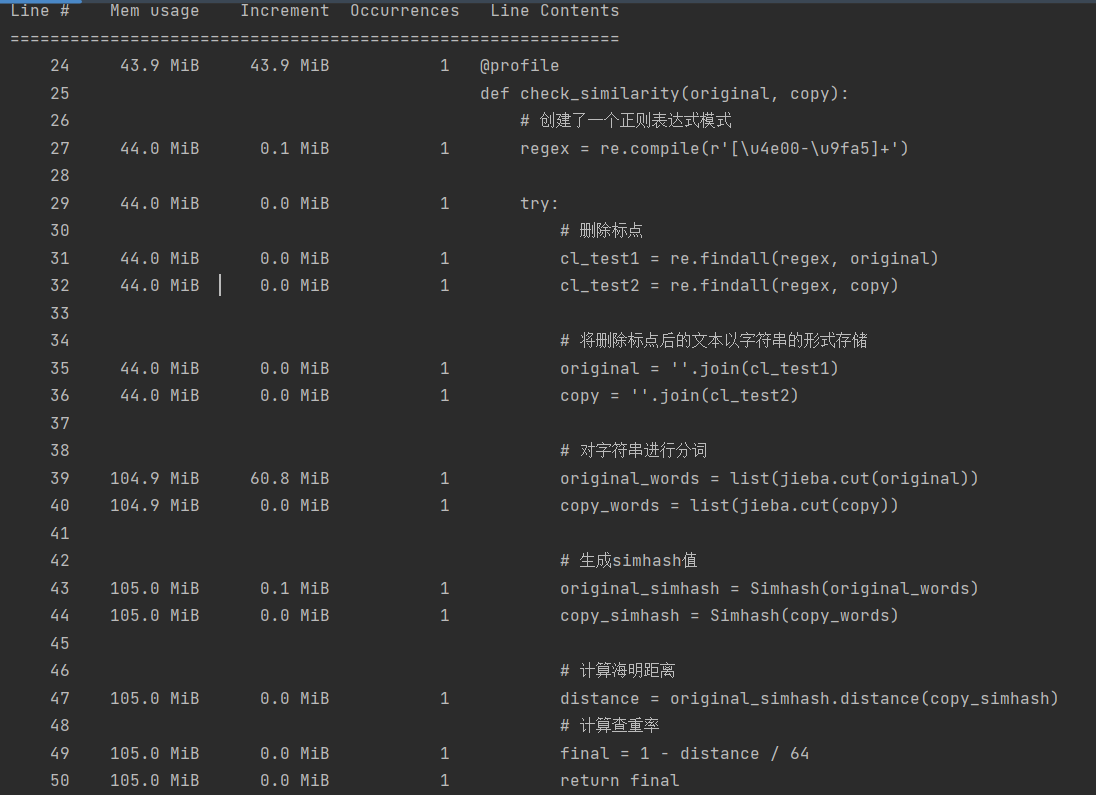
3.性能分析
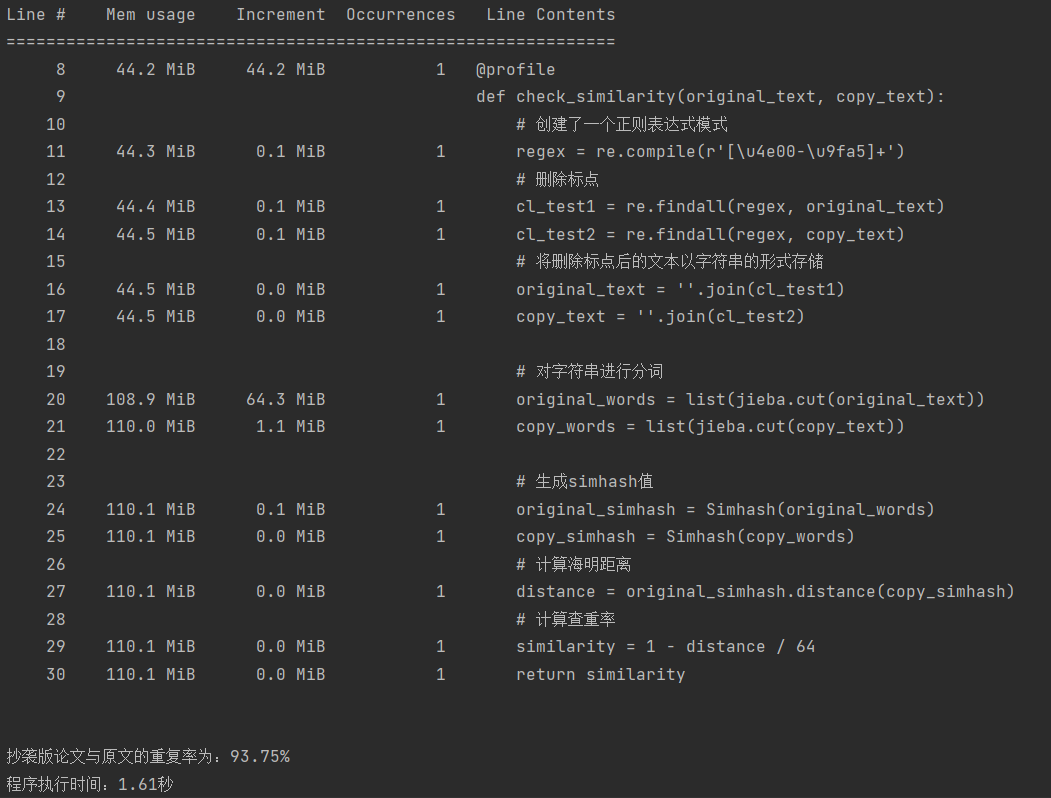
- 如上图所示,程序执行的时间为1.61s,其中将文本创建为正则表达式需要44.2MiB的,紧接着整个算法耗时最长以及占用内存最多的部分是进行分词算法,需要64.3 MiB。因此我们的算法优化可以从分词算法的优化进行。但受限于理论知识过少,目前笔者暂时未发现更好的算法。
4.模块异常分析
示例结果如下:
- 原文文本输入错误
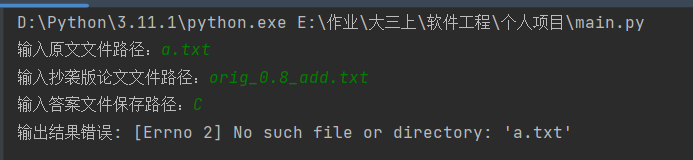
-抄袭文本输入异常

由上图可知本程序可以检测错误的输入样本。
5.Code Quality Analysis
在Pycharm自带了代码检查功能,一下为笔者整个项目的检验结果,由于可以检测整个项目,连文本中的所有语法也能检测出错误,以下为结果图:
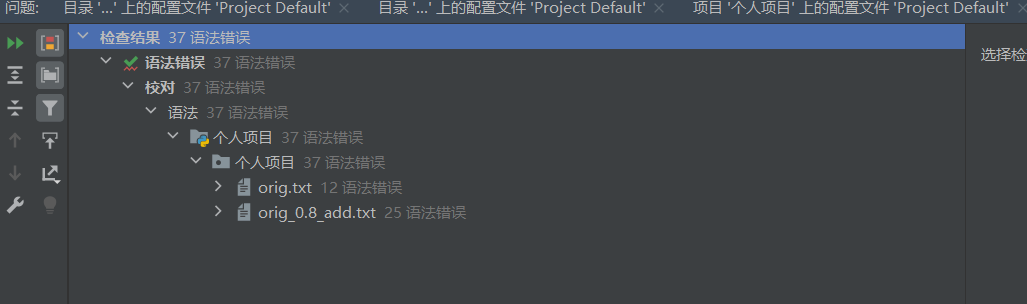
通过上图可以发现,在程序中的代码已无错误,只有文本检测出错误(代码检测功能无报错)说明代码性能良好。
6.独特之处
- 通过定义不同的类检查模块异常。
- 通过海明码和海明距离计算重复率。
7.程序简易样例测试阶段
- 定义了test.txt 和 test_add.txt 作为原文和抄袭文档,并将test query result.txt作为结果输出文档,具体测试结果如下:
原文文本:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭文本:今天是周天,天气晴朗,我晚上要去看电影。

程序正常运行,结果无异常,说明性能良好。
8.文章检测实操结果
原文文本:orig.txt
抄袭文本:orig_0.8_add.txt
最终结果: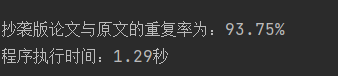
9.后续优化部分
- 1)添加不同语言检验的异常结果分析
- 2)尝试进行语义分析
- 3)根据搜索引擎,还有多种方法可实现论文查重代码编写,如余弦相似度算法,动态规划算法等,尝试写出以上算法并将全部算法的结果进行比对,寻找最优性能的算法。
附录
- 1.文件的具体代码可从Github中获取,文本和结果样例以及requirement.txt同样可以从中获取。
- 2.程序调用的库有:
import re
import jieba
from simhash import Simhash
import time
from memory_profiler import profile