1. RNN
循环神经网络的内容可参考https://www.youtube.com/watch?v=UNmqTiOnRfg。
RNN建模的对象是具有时间上前后依赖关系的对象。以youtube上的这个视频为例,一个厨师如果只根据天气来决定今天他做什么菜,那么就是一个普通的神经网络;但如果他第i天所做的菜不仅和第i天的天气有关,还和第i-1天做了什么菜有关,那么就成为一个循环神经网络。
RNN与一般的前向神经网络工作方式不同。一般的前向神经网络在面对一次输入时,将会把这一次输入的全部数据读入,同时计算并同时输出;RNN则是每次读入输入中的一个单元,在处理输入单元\(x_i\)时,它需要用到输入单元\(x_{i-1}\)产生的输出\(y_{i-1}=hidden_{i-1}\),并进行计算\(y_i=f(x_i,hidden_{i-1})\),\(y_i\)成为当前单元产生的输出,并且同时成为隐藏状态\(hidden_i\)。可以将\({y_1,y_2,...,y_n}\)作为输出,也可以将\(y_n\)作为输出,这取决于需要的输出是一个序列或者是单个值。
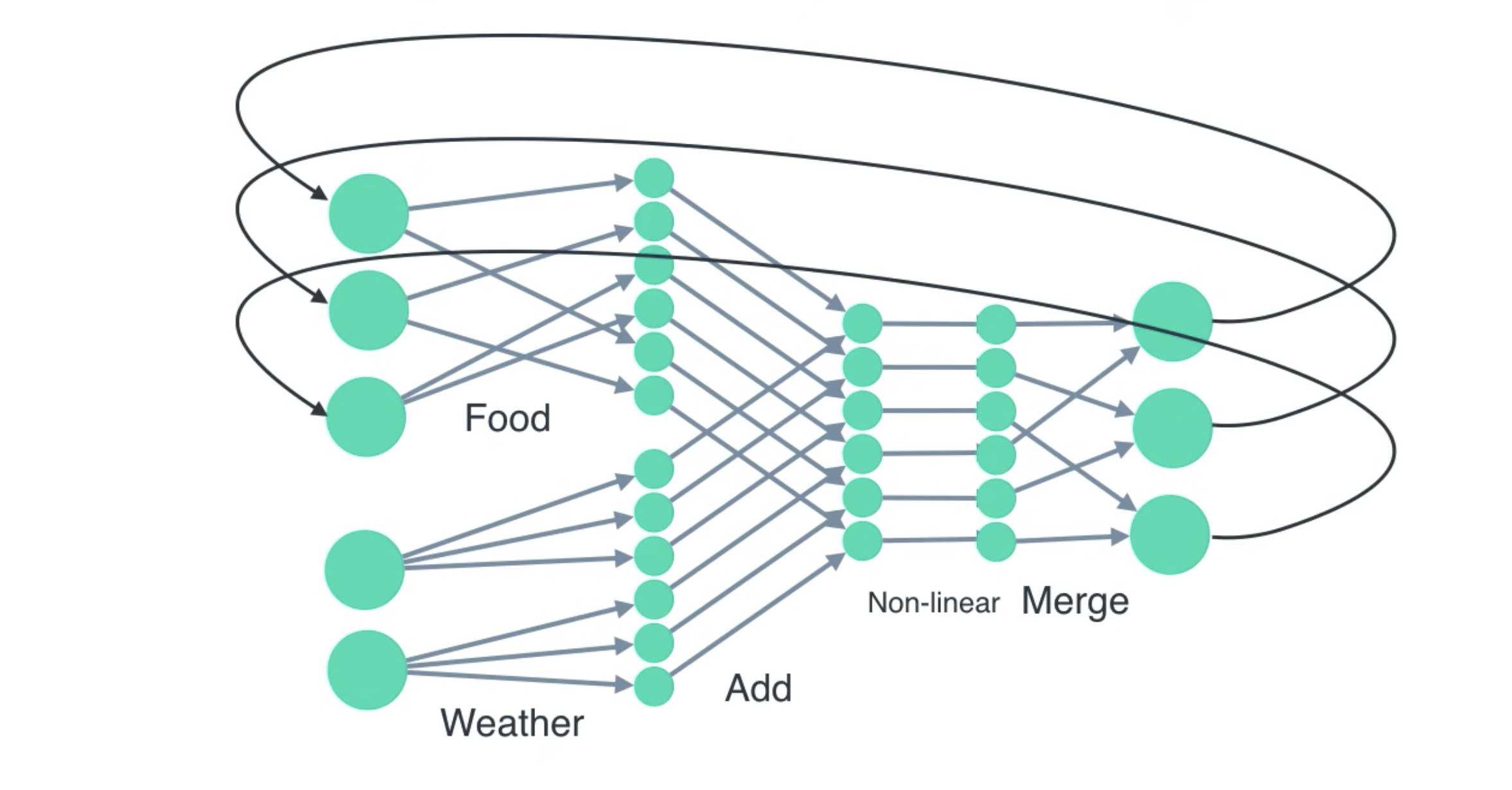
RNN是建立序列模型的基本工具,比如股票价格预测、声音识别,以及自然语言处理。LSTM和GRU属于RNN的变种,这两者的记忆能力要比RNN更强一些。
2. Sequence to sequence model
参考https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/。
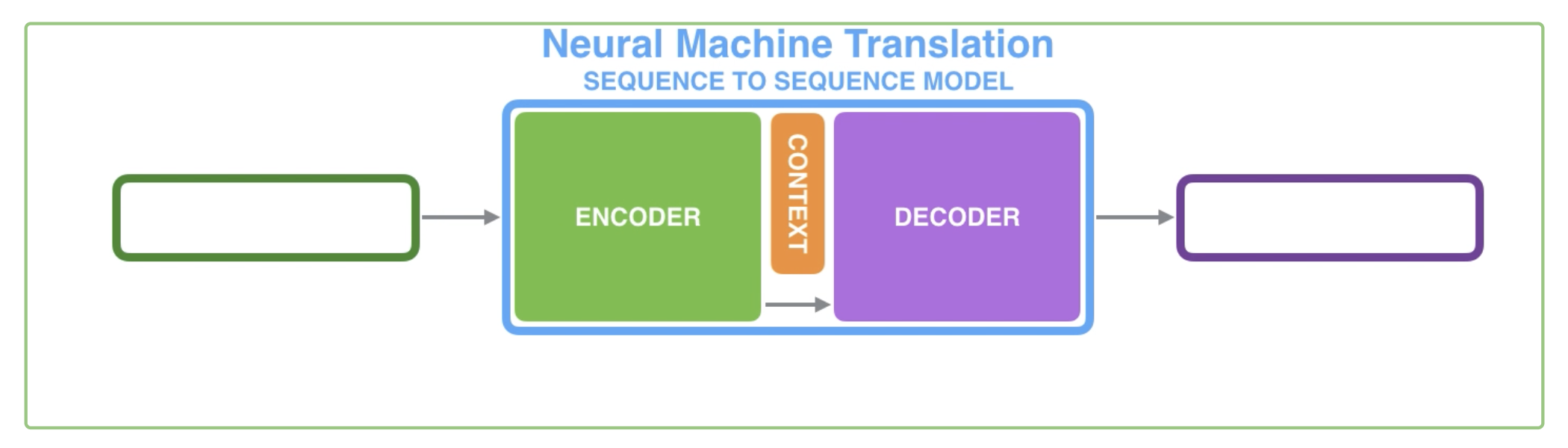
基本的Seq2Seq模型有两个组成部分,一个是Encoder,一个是Decoder。这两个部分都是循环神经网络。输入数据首先进入Encoder,Encoder将生成的最后一个隐藏状态传递给Decoder,作为Decoder的输入,称为Context。Decoder根据这个状态(也是一个向量)生成输出。
显然,Context的长度是可以调整的。它的长度一般是256,512或1024。
3. Seq2Seq with Attention
参考上面那篇文章以及https://blog.floydhub.com/attention-mechanism/。
对于上面的序列模型而言,由于只把最后一个隐藏状态作为Decoder的输入,它不能够有比较长的记忆能力,难以处理长序列。2014年和2015年,Bahdanau和Luong分别提出了两种形式的Attention机制,用于解决这一问题。
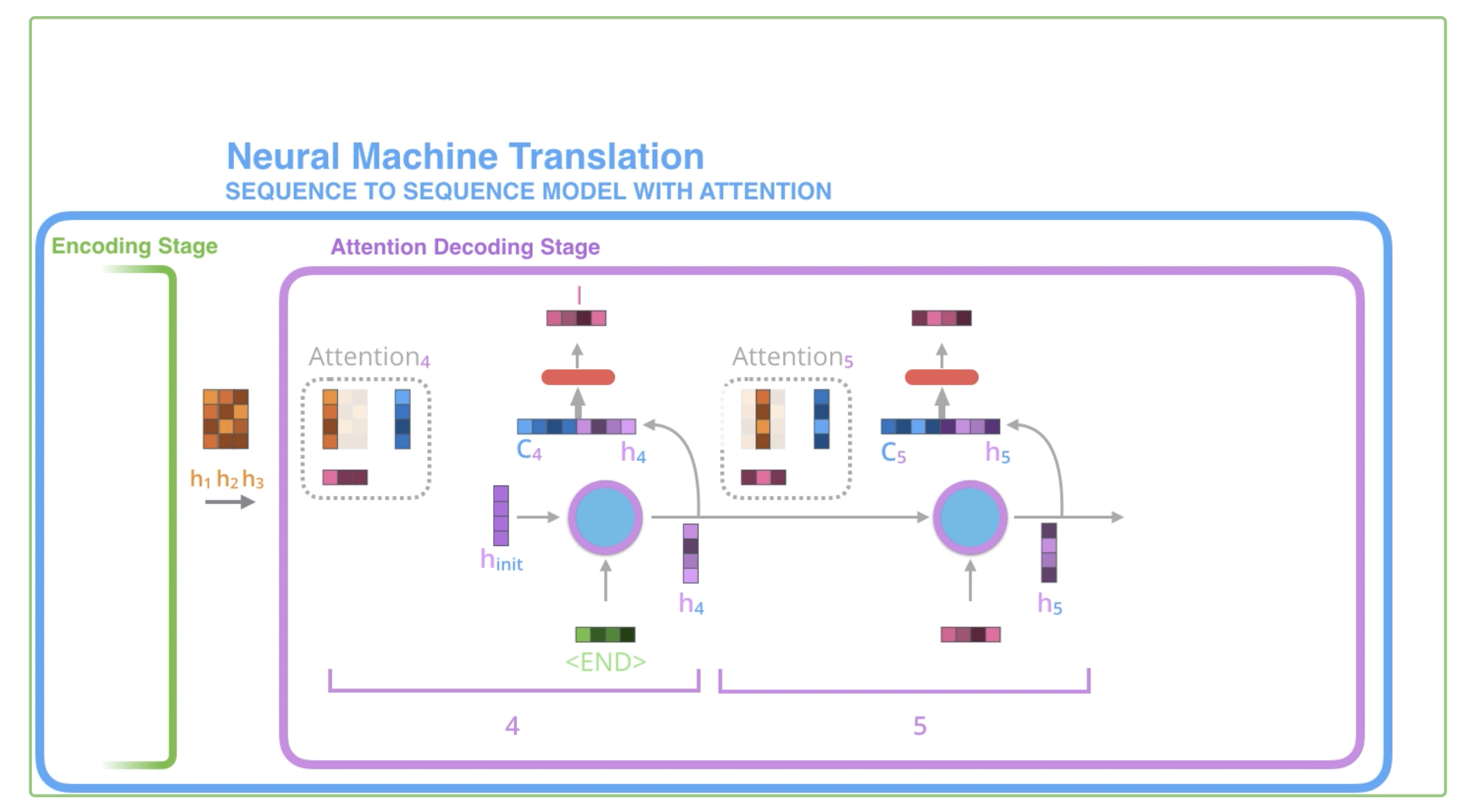
带有Attention的序列模型在Encoder阶段与基本模型一致。与基本的Seq2Seq模型不同的是,此时所有的隐藏状态都被传输到Decoder中。
在Bahdanau Attention中,Decoder在某一阶段的两个输入中,第一个是前一阶段的隐藏状态。然后,用这个隐藏状态给所有的Encoder hidden state打分,将分值softmax并乘到每个Encoder hidden state上,这样就形成了当前Decoder隐藏状态与Encoder每个隐藏状态的关联强弱表示。将所有Encoder hidden state加起来,形成一个向量拼接到Decoder的隐藏状态上,形成当前状态的第二个输入。(获得分值之后的这两步对于Encoder隐藏状态而言相当于一次隐藏状态矩阵和Attention权值向量的一次矩阵乘法)
Luong Attention的不同点在于打分的方式不同,以及Attention作用的阶段不同。Luong Attention在计算得到一个隐藏状态之后,一方面直接传给下一阶段作为输入,另一方面作用Attention机制,将Attention作用之后的结果作为模型的当前输出。然后这个输出就作为下一阶段的第二个输入使用。
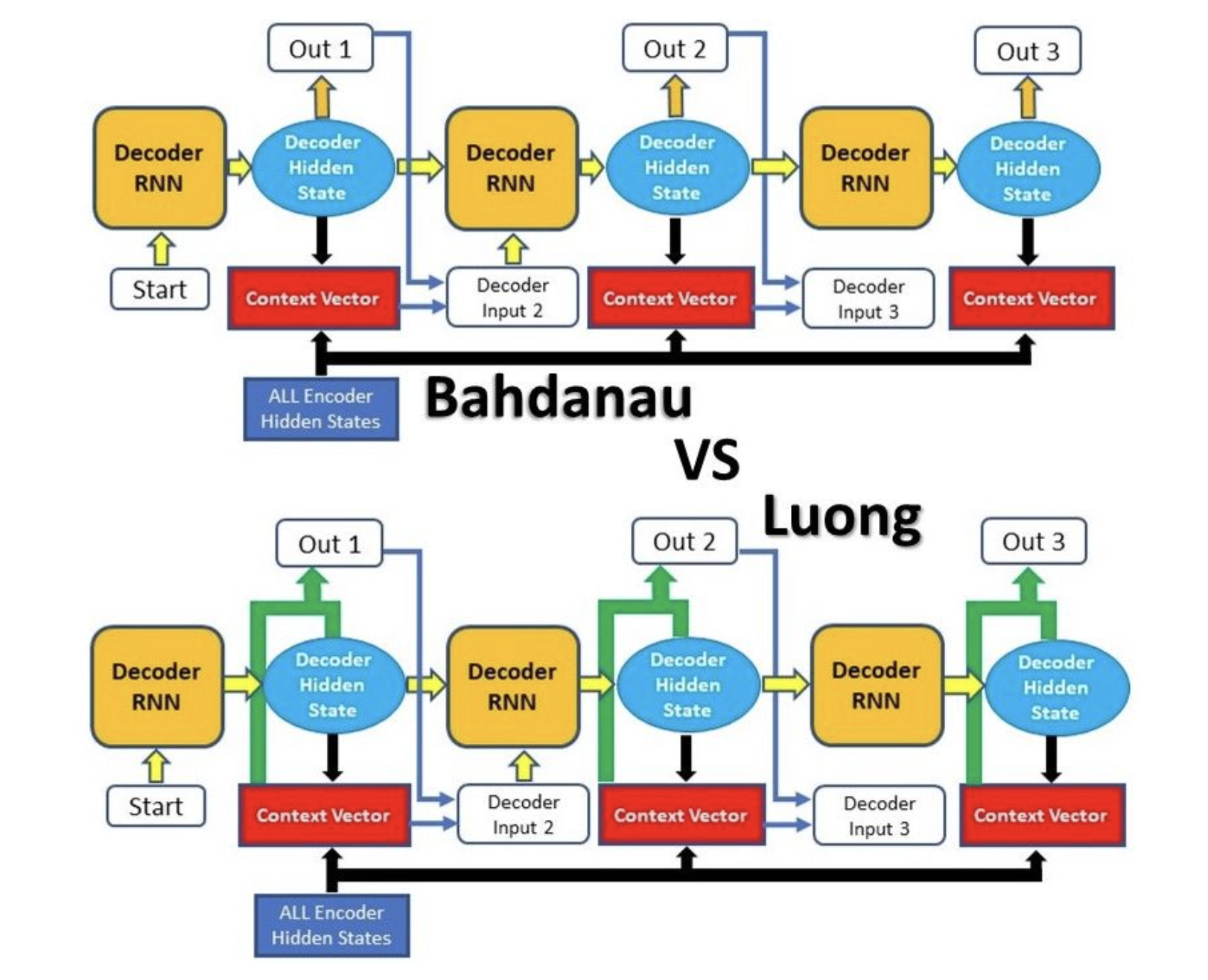
具体的打分方式先不管了,还没看懂x
4. Self Attention && Transformer
参考http://jalammar.github.io/illustrated-transformer/。
Transformer由Google在2017年提出(Attention Is All You Need)。尽管在加入Attention之后,Seq2Seq的长期记忆能力被改善,但是仍然保留了RNN的成分。而RNN的前后依赖特性使得它无法在一个样本的计算内部进行并行。Transformer仍然基于Encoder-Decoder的结构,但是完全舍弃了RNN的结构,单纯依靠Attention来完成序列建模的任务(正如它的标题所说)。
在了解Transfomer之前,需要先了解Self Attention。这是同一篇论文里提出来的东西(应该)
4.1 Self Attention
之前提到的Attention机制,其主要目的是表示输出序列的某个位置与输入序列的所有位置之间的关联紧密程度。而Self Attention的目的则是为了表示输入序列内部的词语互相之间的关联程度,比如一个句子中的it到底指代的是什么。
Self Attention的计算过程我看了好几遍了,依然觉得十分抽象。
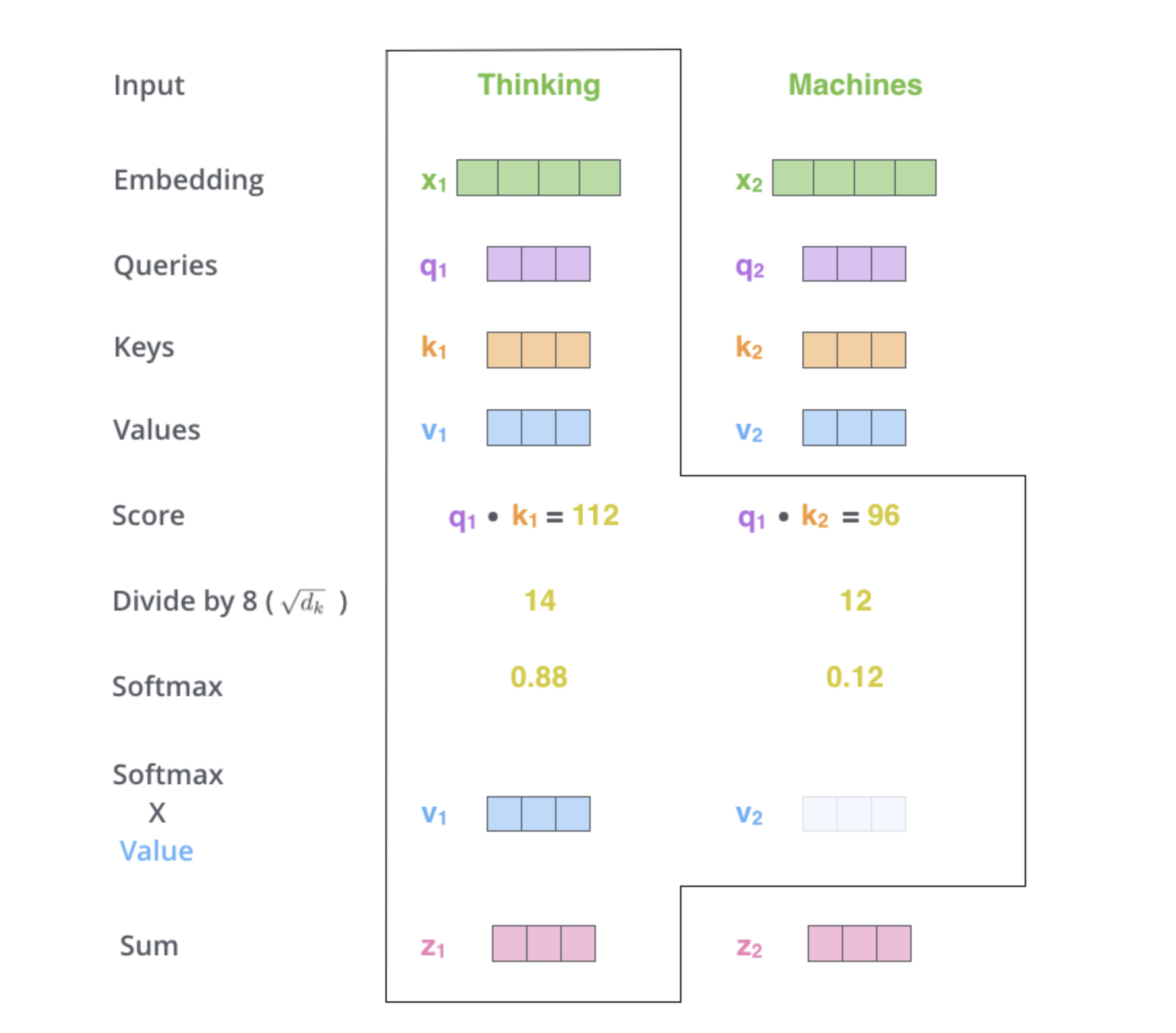
Self Attention接收的输入是一系列的词,每个词用词向量表示(当然也不一定是原始的词,Transformer中有很多Encoding Block,输入的也可能是上一层的输出)。对于每一个词向量,Self Attention有三个可训练的矩阵,分别为\(W^Q,W^K,W^V\),将向量分别乘上这三个矩阵,获得\(q(query),k(key),v(value)\)三个向量。
接下来的过程依旧是对于某个词而言,为所有词对它的关联度打分。分数的计算是用这个词的\(q\)去点乘其他词的\(v\),得到的分数除以\(\sqrt{d_k}\),\(d_k\)是\(key\)的长度(这一步的理由不是很明确,好像就是单纯为了把这个值变得小一点)。然后softmax。用得到的分数将所有词的\(v\)加权相加(一次矩阵乘法),就得到了这个词经过Self Attention之后的输出。
将以上过程写成矩阵形式,就得到了最抽象的公式:
4.2 Multihead Self Attention
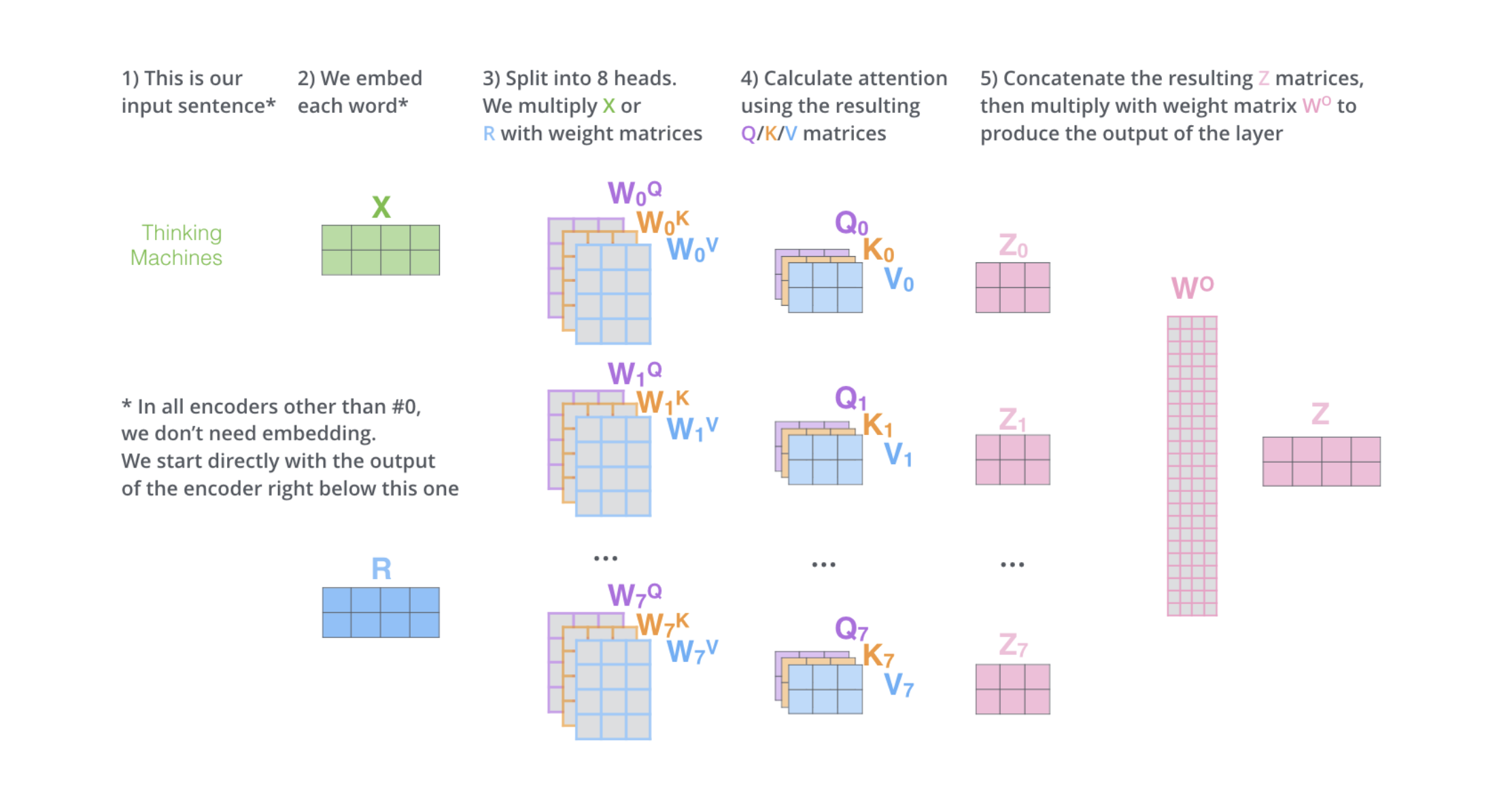
从上面可以看出来,上面的计算只是打分的过程,本质上决定分数和关联度的其实是用于生成\(Q,K,V\)的三个矩阵\(W^Q,W^K,W^V\)。为了让模型能够提取不同角度、不同层面的语意联系,可以使用多组的\(W^Q,W^K,W^V\)来进行多次的Attention计算。由于矩阵也是训练出来的,所以这样做有机会能够提取不同层面的语意。这就称为多头注意力。
多头注意力会产生很多个输出\(z\),处理的办法相对简单粗暴,也就是把输出全部拼起来,然后乘上一个矩阵\(W^O\)调整输出的尺寸。
4.3 Transformer
同时参考https://www.youtube.com/watch?v=nzqlFIcCSWQ。李沐的这个视频基本把Transformer所有的细节都讲了。
Transformer的架构有很多细节,这里不做过多展开,先描述一下大致的结构。细节后面有需要的话再慢慢补。
总体上,Transformer是由Encoders和Decoders构成。Encoders中有多个Encoder Block,Decoder中有相同数量的Decoder Block。
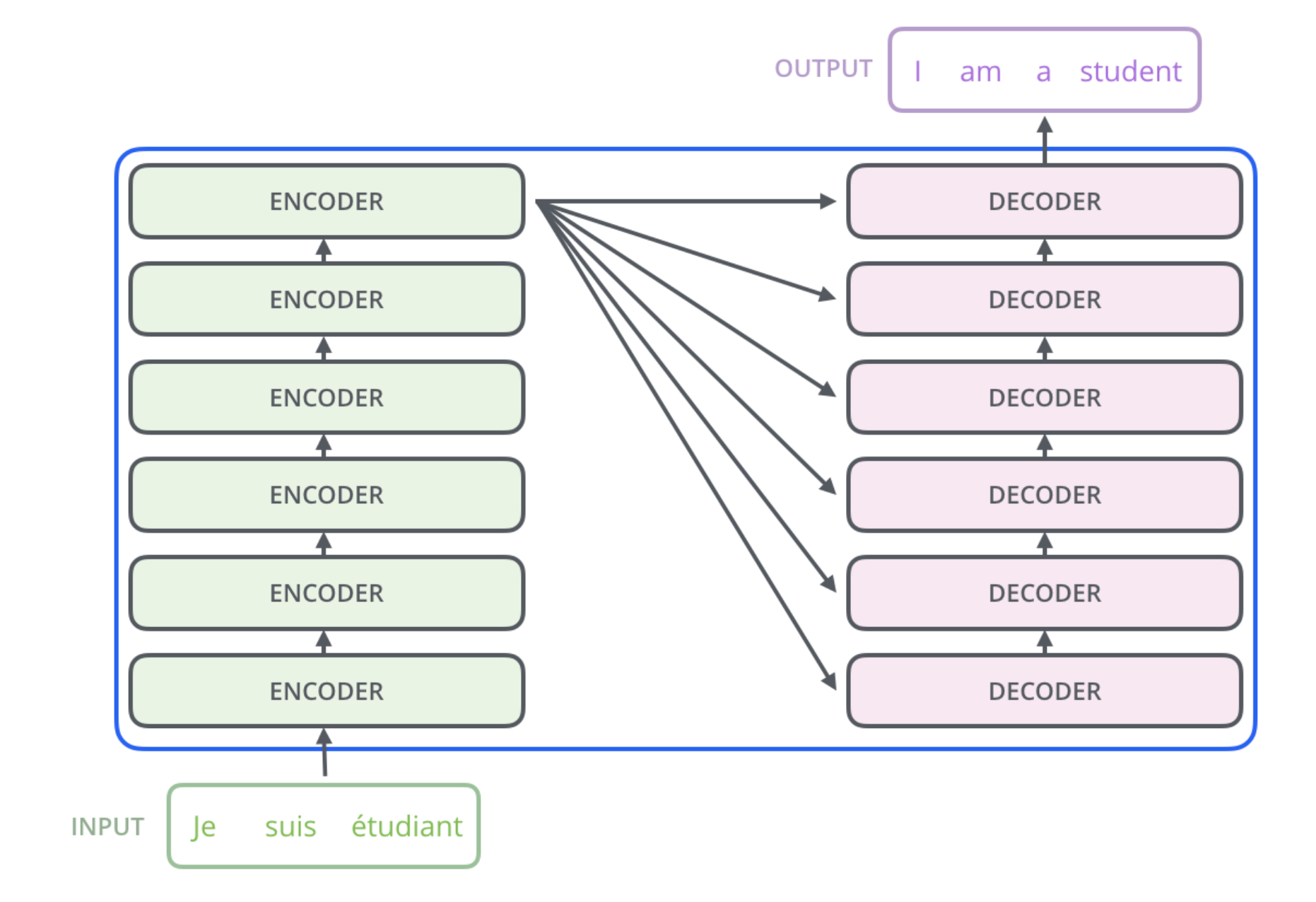
然后就要看一看Encoder和Decoder的内部构造。放上论文当中这张著名的图:
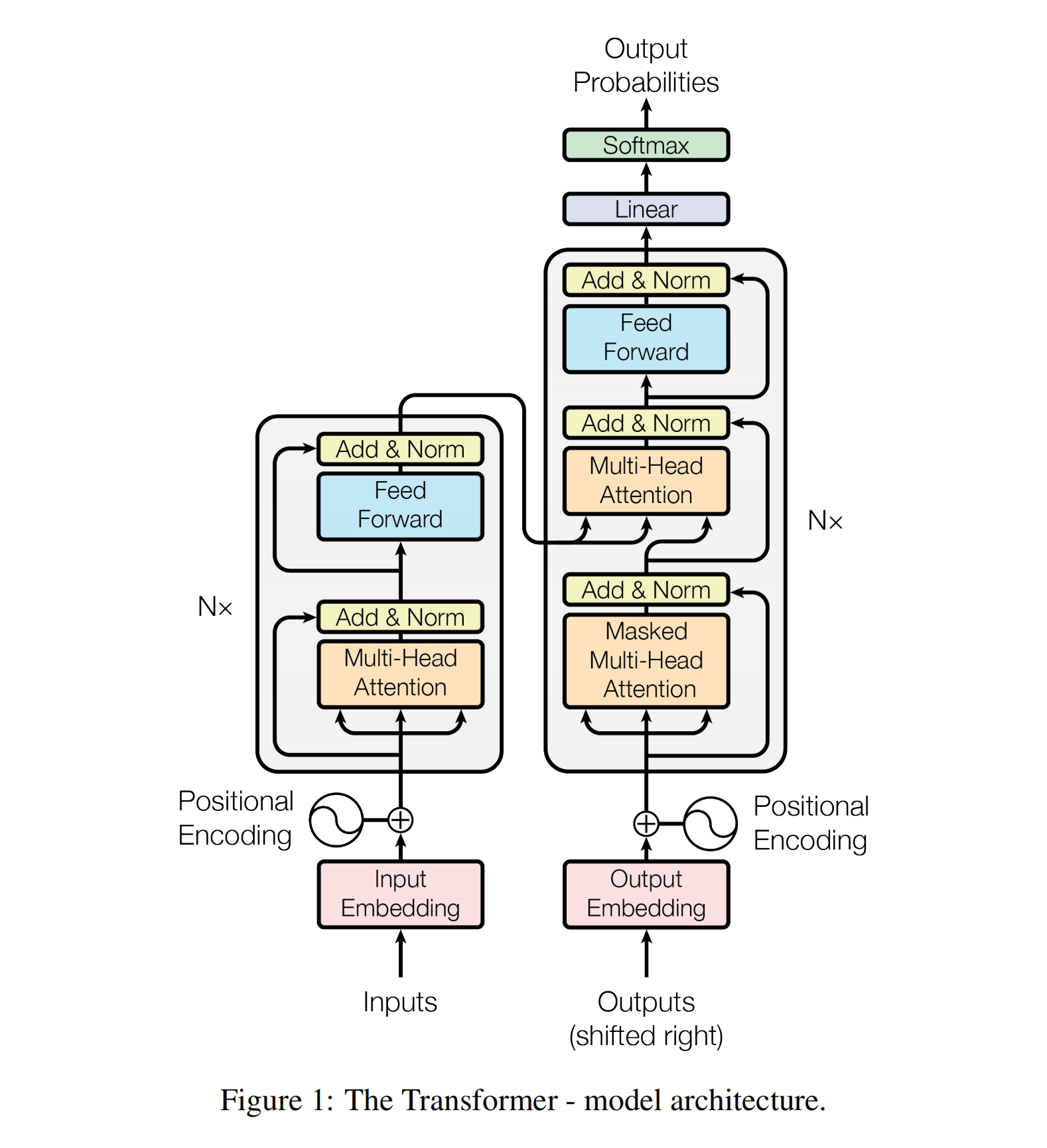
Encoder Block总体包含两个部分,一个是Self Attention,一个是FFN。下面橙色的块代表Self Attention,橙色块下方的三个输入口从左到右依次代表Key、Value、Query,Encoder中的QKV全部都是从输入中产生的,所以是自注意力块。过了自注意力之后是一个残差连接(Residual Connect)和LayerNorm,这个我还不是特别清楚,之后再说。FFN是同时对所有词向量进行的(Point-wise),将原本512维的向量放大成2048维之后再缩减为512维,本质上是一个一层隐层的全连接。
右侧Decoder的下方输入部分写的是Output,看上去有点奇怪。实际上它是自回归的(Auto Regressive),也就是Decoder从上方产生输出之后再传回下方作为输入,预测下一个词。
Decoder有两层Attention,第一层是自注意力,但是是含Mask的,主要目的是不能让注意力看到应该成为预测对象的后面的词。Mask的措施是在注意力的分数进行softmax之前,把需要遮挡掉的部分设置成-inf,从而分数就会变成0。第二层不是自注意力,Key和Value是从左边的最后一个Encoder连过来的。用Decoder中的每一个Query对Encoder产生的每一个词进行打分,实际上是评价Encoder的每个词对Decoder中某个词的关联度。