lab2
这个实验是为操作系统编写内存管理代码。内存管理分为两部分: 内核的物理内存分配器,虚拟内存。
1 page : 4k bytes
为获取lab2所需文件,执行如下命令:
git pull
git checkout -b lab2 origin/lab2
git merge lab1
//如果下列文件出现,则成功:
//inc/memlayout.h; kern/pmap.c; kern/pmap.h; kern/kclock.h; kern/kclock.c
其中memlayout.h描述了必须通过修改pmap.c实现的虚拟地址空间布局,如果有不懂的地址名词就去这个文件里找!!!!!!!!!!!!!!
memlayout.h和mmap.h定义了PageInfo结构,您将使用该结构跟踪哪些物理内存页面是空闲的。kclock.c和kclock.h操作PC的电池支持时钟和CMOS RAM硬件,BIOS在其中记录PC所包含的物理内存量,以及其他内容。
pmap.c中的代码需要读取这个设备硬件,以便计算出有多少物理内存,但这部分代码已经完成了:我们并不需要知道CMOS硬件如何工作的细节。
inc/mmu.h也很重要,因为它包含许多对本实验有用的定义。
在本实验和后续的实验中,完成实验室中描述的所有常规练习和至少一个挑战性问题。
Part 1: Physical Page Management
JOS以页面粒度管理PC的物理内存,这样它就可以使用MMU来映射和保护每一块已分配内存。
Exercise 1
这个练习将编写物理页面分配器。它使用结构体 PageInfo对象 的链表跟踪哪些页面是空闲的(与xv6不同的是,这些对象没有嵌入到空闲页面本身中),每个页面对应一个物理页面。
练习1
在文件kern/pmap.c中,必须实现以下函数的代码(可能按照给定的顺序)。
boot_alloc ();Mem_init()(只到调用check_page_free_list(1));page_init ();page_alloc ();page_free()。
Check_page_free_list()和check_page_alloc()测试物理页面分配器。您应该引导JOS并查看check_page_alloc()是否报告成功。修改代码,使其通过。您可能会发现添加自己的assert()来验证您的假设是否正确很有帮助。
而boot_alloc()函数注释也解释:这个函数只分配内存,并不初始化内存,函数中。所以我们仿照该函数中nextfree分配地址的方式分配内存即可。
//boot_alloc()函数修改处
//
// LAB 2: Your code here.
result=nextfree;
nextfree=ROUNDUP(nextfree+n, PGSIZE);
if( (uint32_t)nextfree<KERNBASE ){
panic("boot_alloc: out of memory\n");
}
//其中KERBASE就在memlayout.h文件中定义。这块检测内存不足的判定我也不确定,但根据lab1中我们的结论:将kernel加载到了虚拟地址0xf0000000处,所以判定应该是这样的。
//这也与博客的写法 if( (uint32_t)nextfree - KERNBASE > (npages*PGSIZE))所不同。
return result;
mem_init()函数修改处:
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
//根据注释提示以及之前几句的仿写修改即可,比较简单。
pages = boot_alloc(npages * sizeof(struct PageInfo) )
memset(pages, 0, npages * sizeof(struct PageInfo);
page_init()函数修改处:
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
size_t i;
page_free_list = NULL;//其实是多余的,因为它本就是空指针,这只是为了方便阅读一点。
uint32_t EXTPHYSMEM_alloc = (uint32_t)boot_alloc(0) - KERNBASE;//EXTPHYSMEM_alloc:在EXTPHYSMEM区域已经被占用的bytes数
//从memlayout.h中可以看到 pp_ref是使用page_alloc分配的页 指向此页的指针(通常在页表条目中)数, 不太明白。。。。。 但我看博客上将使用的page 置1.
for (i = 0; i < npages; i++) {
if( i==0 ||(i>=IOPHYSMEM/PGSIZE && i<(EXTPHYSMEM+EXTPHYSMEM_alloc)/PGSIZE)){//不标记为free的页
pages[i].pp_ref = 1;
}else{//标记为free的页
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
page_alloc()函数修改处:
struct PageInfo *
page_alloc(int alloc_flags)
{
// Fill this function in
//不要增加页面的引用计数(pp_ref) - 调用方必须在必要时执行这些操作(显式或通过 page_insert )。
struct PageInfo * res=NULL;
if(!page_free_list) return res;
res=page_free_list;
page_free_list=page_free_list -> pp_link;
res ->pp_link=NULL;
if (alloc_flags & ALLOC_ZERO){//尚未发现ALLOC_ZERO宏在哪个文件中定义,直接根据注释来
memset(page2kva(res) , '\0' , PGSIZE );
}
//返回这个页表索引的地址即可(并非 page2kva(res) )
return res;
}
page_free()函数修改处:
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
//assert()函数在 inc/assert.h文件中定义,其就是按格式调用panic。
assert(pp->pp_ref == 0);
assert(pp->pp_link == NULL);
pp->pp_link=page_free_list;
page_free_list=pp;
}
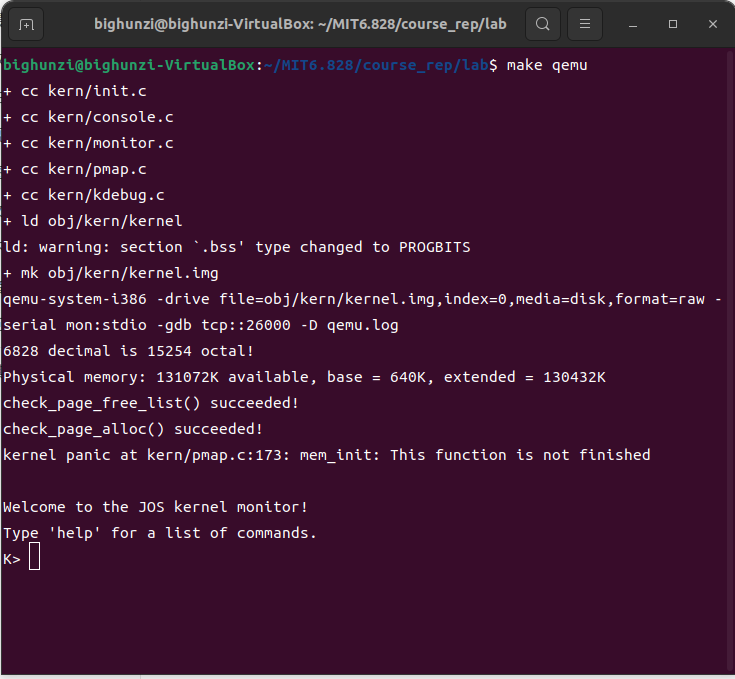
上述代码完成后,测试结果如下,说明代码正确(测试时不要忘记改动mem_init()中的该行语句的位置 ):panic("mem_init: This function is not finished\n")
Part 2: Virtual Memory
先熟悉x86的保护模式内存管理体系结构:即段和页面转换。练习2就在做这个事情。
Exercise 2
练习2
阅读英特尔80386参考手册的第5章和第6章,仔细阅读关于页面转换和基于页面的保护的章节(5.2和6.4)。我们建议你也略读关于段的部分;虽然JOS使用分页硬件进行虚拟内存和保护,但在x86上不能禁用段转换和基于段的保护,因此您需要对它有基本的了解。
Exercise 2 阅读笔记
Chapter 5 Memory Management
Intel 80386将逻辑地址(即程序员看到的地址)转换为物理地址(即物理内存中的实际地址)分为两个步骤: 1. 段转换,其中逻辑地址(由段选择子和段偏移量组成) 被转换为线性地址。2. 页转换,将线性地址转换为物理地址。这个步骤是可选的,由系统软件设计人员自行决定。
5.2 Page Translation
页面转换步骤是可选的。只有设置了CR0的PG位,页面转换才有效,该位通常由操作系统在软件初始化期间设置。
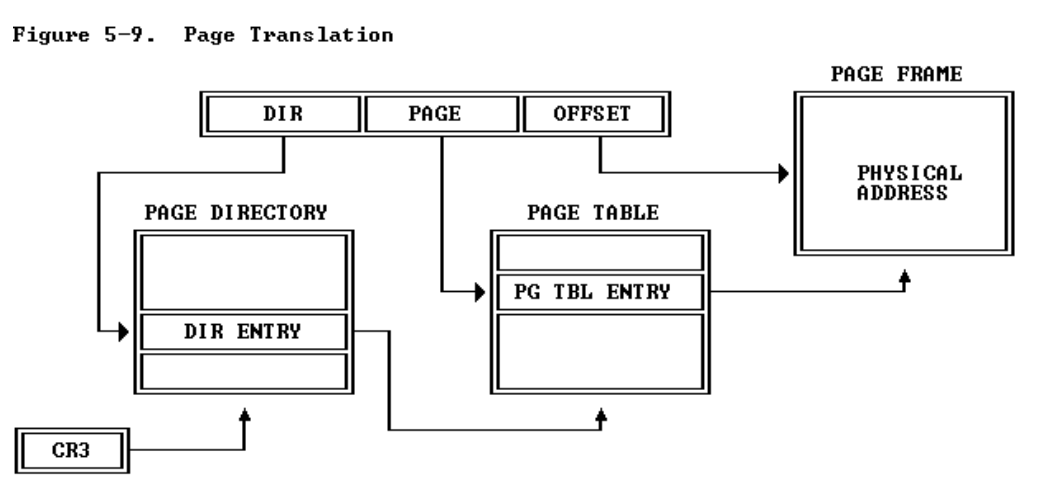
当前页目录的物理地址存储在CPU寄存器CR3中,也称为页目录基寄存器(PDBR)。
在对页进行读或写操作之前,处理器将两层页表中相应的访问位设置为1。
当80386被用来执行为没有分段的体系结构设计的软件时,有效地“关闭”80386的分段功能可能是权宜之计。80386没有禁用分段的模式,但是可以通过在段寄存器中初始加载包含整个32位线性地址空间的描述符的选择器来实现相同的效果。一旦加载,段寄存器不需要改变。80386指令使用的32位偏移量足以寻址整个线性地址空间。(这也是linux的寻址方式)
Chapter 6 Protection
为了帮助更快地调试应用程序并使其在工作中更加稳定,80386包含了验证内存访问和指令执行是否符合保护标准的机制。根据系统设计目标,可以使用或忽略这些机制。
段是保护的单位。
6.4 Page-Level Protection
与页面相关的保护有两种:可寻址域限制 与 类型检查。
Exercise 3
在x86术语中,虚拟地址由段选择子和段内的偏移量组成。线性地址是在段转换之后,页面转换之前得到的地址。物理地址是经过段和页转换后最终得到的地址,或者说最终通过硬件总线传输到RAM的地址。
在boot/boot.S文件中,我们有一个全局描述符表(GDT),其通过将所有段基址设置为0,将段限制为0xffffffff 来有效地禁用段转换。因此,“选择子”没有作用,线性地址总是等于虚拟地址的偏移量。在实验室3中,我们将不得不与段进行更多的交互,以设置特权级别,但对于内存转换,我们可以在整个JOS实验中忽略段,而只关注页转换。
回想一下,在实验1的第3部分中,我们安装了一个简单的页表,这样内核就可以在它的链接地址0xf0100000上运行,即使它实际上是在ROM BIOS上方的0x00100000上加载到物理内存中。这个页表只映射了4MB内存。在本实验中将为JOS设置的虚拟地址空间布局中,我们将扩展该布局,来映射从虚拟地址0xf0000000开始的第一个256MB物理内存,并映射虚拟地址空间的许多其他区域。
练习3
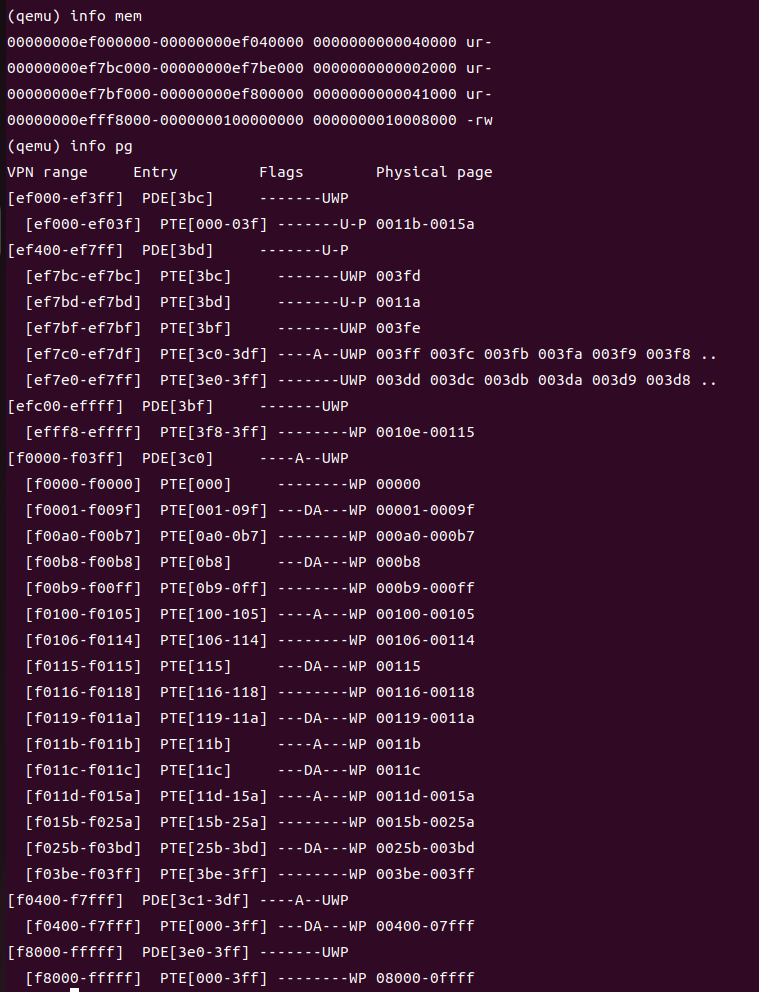
虽然GDB只能通过虚拟地址访问QEMU的内存,但在设置虚拟内存时检查物理内存通常是有用的。回顾实验工具指南中的QEMU监视器命令,特别是xp命令,该命令允许您检查物理内存。要访问QEMU监视器,请在终端中按Ctrl-a c(相同的绑定将返回到串行控制台)。
在QEMU监控器中使用xp命令和在GDB中使用x命令检查相应物理地址和虚拟地址上的内存,并确保看到相同的数据。
我们的QEMU补丁版本提供了一个info pg命令,这个命令也可能被证明是有用的:它显示了当前页表的紧凑而详细的表示,包括所有映射的内存范围、权限和标志。Stock QEMU还提供了一个info mem命令,用于显示映射的虚拟地址范围和权限的概述。
qemu-system-i386 -hda obj/kern/kernel.img -monitor stdio -gdb tcp::26000 -D qemu.log //使用文档中提到的qemu monitor进入方法并不好使,看到网上的一些博客说这条命令好使,我就尝试了一下,发现果然好使。。。
xp/Nx paddr //查看paddr物理地址处开始的,N个字的16进制的表示结果。
info registers //展示所有内部寄存器的状态。
info mem -//展示所有已经被页表映射的虚拟地址空间,以及它们的访问优先级。
info pg //展示当前页表的结构。
//具体去手册上看
为了帮助编写代码,JOS源代码区分了两种情况:uintptr_t类型表示不透明的虚拟地址,physaddr_t类型表示物理地址。JOS内核可以通过先将uintptr_t转换为指针类型来完成对uintptr_t的解引用。
注意:MMU会转换所有的内存引用!!!!!!!!!!!!!!!!内核不能绕过虚拟地址转换,因此不能直接加载和存储到物理地址。
问题
假设下面的JOS内核代码是正确的,变量x应该有什么类型,uintptr_t还是physaddr_t?
x应该是uintptr_t。
为了将物理地址转换为内核可以实际读写的虚拟地址,内核必须向物理地址添加0xf0000000,以便在重新映射的区域中找到其对应的虚拟地址。您应该使用KADDR(pa)来完成该添加。
内核全局变量和由boot_alloc()分配的内存位于加载内核的区域,从0xf0000000开始,正是我们映射所有物理内存的区域。因此,要将该区域中的虚拟地址转换为物理地址,内核可以简单地减去0xf0000000。您应该使用PADDR(va)来做这个减法。
在未来的实验中,经常会将相同的物理页面同时映射到多个虚拟地址(或多个环境的地址空间)。将在对应于物理页面的struct PageInfo的pp_ref字段中保存对每个物理页面的引用数量的计数。当物理页的此计数为零时,可以释放该页,因为不再使用它。一般来说,这个计数应该等于物理页在所有页表中出现在UTOP下面的次数(UTOP上面的映射大部分是由内核在引导时设置的,永远不应该被释放,所以没有必要引用计数它们)。我们还将使用它来跟踪指向页目录页的指针数量,以及页目录对页表页的引用数量。
使用page_alloc时要小心。它返回的页面总是有一个0的引用计数,所以只要对返回的页面做了一些事情(比如将它插入到页表中),pp_ref就应该增加。有时这由其他函数(例如page_insert)处理,有时调用page_alloc的函数必须直接处理。
Exercise 4
现在将编写一组例程来管理页表:插入和删除线性地址到物理地址映射,并在需要时创建页表页。
练习4
在kern/pmap.c文件中,必须实现以下函数的代码:pgdir_walk(), boot_map_region(), page_lookup(), page_remove(), page_insert()。
利用mem_init()调用的Check_page()测试页表管理例程。在继续之前,您应该确保它报告成功。
从头捋一下。
pgdir_walk()代码:
//这个函数的目的就是返回一个指向对应线性地址va的 pte。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
pde_t* dir_entry=pgdir+PDX(va); //PDX(va)返回page directory index,dir_entry是指向页目录中的DIR ENTRY(见图)的指针。
if( !(*dir_entry & PTE_P) ){//如果这个页表不存在
if(create==false) return NULL;
else{
struct PageInfo * new_pp =page_alloc(1);//别忘了这个它返回的是struct PageInfo *
if(new_pp==NULL){
return NULL;
}
new_pp->pp_ref++;
*dir_entry=(page2pa(new_pp) | PTE_P | PTE_W | PTE_U);//设置dir_entry的标志位。注释中说可以设置宽松,所以这里全部设置为最宽松:可读写,应用程序级别即可访问。 dirty位 和access位不做设置。
memset(page2kva(new_pp) , '\0' , PGSIZE);//初始化new_page的物理内存,一定要用虚拟地址!!!!!
}
}
//注意,返回的应该是虚拟内存。PTE_ADDR()在mmu.h中定义,就是将pte转换为physaddr_t,再提取出前面表示地址的位。
pte_t * page_base = KADDR(PTE_ADDR(*dir_entry));//注意这块的类型定义,这涉及地址运算。 很重要,之前的bug就是因为这里!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
return &page_base[PTX(va)];
}
boot_map_region()代码:
//这个函数的目的是添加size大小的虚拟地址和物理地址的映射关系,调用pgdir_walk()依次分配即可。
//与boot_alloc()联合使用。
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
pte_t* pt_entry;
for(int i=0; i<size;i+=PGSIZE){
pt_entry=pgdir_walk(pgdir, (void *) va ,1);
if (pt_entry == NULL) {
panic("boot_map_region(): out of memory\n");
}
* pt_entry=(pa |perm | PTE_P);//按照注释对pg_entry置标志位。
pa+=PGSIZE;
va+=PGSIZE;
}
}
page_lookup()代码:
//函数目的是返回虚拟地址 va 对应的页的struct PageInfo *,
//它将会被 page_remove()调用,所以不应该再将pgdir_walk()的create参数置1了,它不再需要申请空间了。
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// Fill this function in
pte_t * pt_entry=pgdir_walk(pgdir,va,0);
if(pt_entry==NULL) return NULL;
if(!(*pt_entry & PTE_P)) return NULL;
if(pte_store) *pte_store=pt_entry;
struct PageInfo* res=pa2page(PTE_ADDR(*pt_entry));
return res;
}
page_remove()代码:
//函数目的:解除虚拟地址“va”的物理页的映射。
//tlb_invalidate()的直接调用即可。
//page_decref()作用:减少页面上的引用计数,如果没有更多的引用,则释放它。
void
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t *pt_entry;
struct PageInfo * pp=page_lookup(pgdir,va,&pt_entry);
if(pp==NULL) return ;
page_decref(pp);
*pt_entry= 0;
tlb_invalidate(pgdir, va);
}
page_insert()代码:
//函数目的:将物理页面'pp'映射到虚拟地址'va'。
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
pte_t* pt_entry=pgdir_walk(pgdir,va,1);
if(pt_entry==NULL) return -E_NO_MEM;
pp->pp_ref++;//这个一定要在前面,否则如果相同的pp 重新插入相同的va就会把 pp释放掉了。
if( (*pt_entry) & PTE_P ){//如果这个页已经存在
page_remove(pgdir, va);
}
*pt_entry= page2pa(pp);
*pt_entry = *pt_entry | perm | PTE_P ;
return 0;
}
报告成功!
Part 3: Kernel Address Space
JOS将处理器的32位线性地址空间分为两部分。我们将在实验3中开始加载和运行的用户环境(进程)将控制下部的布局和内容,而内核始终保持对上部的完全控制。分隔线是由inc/memlayout.h中的符号ULIM任意定义的,其为内核保留了大约256MB(0xffffffff-0xef800000)的虚拟地址空间。(但是要注意,在lab3中env_setup_vm()可以看出,UTOP之上皆是内核空间,这些内存被所有进程统一映射,除了uvpt) 这就解释了为什么我们需要在实验1中给内核提供如此高的链接地址:否则内核的虚拟地址空间中就没有足够的空间同时映射到下面的用户环境中
对于本部分和后面的实验,参考inc/memlayout.h中的JOS内存布局图是很有帮助的!
由于内核和用户内存都存在于每个环境的地址空间中,我们必须在x86页表中使用权限位,以使用户代码只访问地址空间的用户部分。
用户环境将没有权限访问ULIM以上的任何内存,而内核将能够读写这些内存。对于地址范围[UTOP,ULIM),内核和用户环境都有相同的权限:它们可以读但不能写这个地址范围。这个地址范围用于向用户环境公开只读的某些内核数据结构。最后,UTOP下面的地址空间是供用户环境使用的;用户环境将设置访问此内存的权限。
Exercise 5
该练习将在UTOP上面设置地址空间:地址空间的内核部分。inc /memlayout.h显示了你应该使用的布局。将使用刚才编写的函数来设置适当的线性到物理映射。
练习5
在调用check_page()之后,填充mem_init()中缺失的代码。完成代码后应该可以通过check_kern_pgdir()和check_page_installed_pgdir()检查。
添加的代码:
//这两行关于权限的解释没怎么看懂。
// Your code goes here:
//这里用ROUNDUP()是因为boot_map_region()注释中要求了size参数应该是PGSIZE的倍数,但其实按照我的写法不加也行。
boot_map_region(kern_pgdir, UPAGES,ROUNDUP(npages * sizeof(struct PageInfo), PGSIZE) , PADDR(pages), PTE_U | PTE_P);//但其实按照memlayout.h中的图,直接用PTSIZE也一样。因为PTSIZE远超过所需内存了,并且按图来说,其空闲内存也无他用,这里就正常写。
// 意思好像是第二部分不进行映射
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
// Your code goes here:
boot_map_region(kern_pgdir, KERNBASE, 0xffffffff-KERNBASE , 0, PTE_W);
测试成功!
问题2
此时页目录中的哪些条目(行)已被填充?它们映射哪些地址,指向哪里?换句话说,尽可能多地填写这个表格。
问题3
我们将内核和用户环境放在同一个地址空间中。为什么用户程序不能读写内核内存?保护内核内存的具体机制是什么?
用户程序不能去随意修改内核中的代码,数据,否则可能会破坏内核,造成程序崩溃。
因为在页目录项,页表项中有Supervisor/User标志位,通过标志位标识该段内存的受代码访问权限。
问题4
这个操作系统能支持的最大物理内存是多少?为什么?
根据qemu日志来说,应该是131072K。这个显示是由pmap.c文件中的i386_detect_memory()函数显示出的。

问题5
如果我们实际拥有最大数量的物理内存,那么管理内存的空间开销是多少?这些开销是如何分解的?
最大物理内存即4G, 那么我们需要 1个page directory table (4K Bytes),1K个page entry table (4K Bytes) , 1M个 struct PageInfo (如果存在内存对齐机制的话, 8 Bytes),共计 12M+ 4K Bytes.
问题6
重新查看kern/entry.s和kern/entrypgdir.c中的页表设置。在我们立即打开分页之后,EIP仍然是一个较低的数字(略多于1MB)。我们在什么时候过渡到运行在KERNBASE之上的EIP ?在启用分页和开始在KERNBASE之上的EIP上运行之间,是什么使我们能够继续在低EIP上执行?为什么这种转变是必要的?
答案:
在entry.S文件中有一个指令 jmp *%eax,这个指令要完成跳转,就会重新设置EIP的值,把它设置为寄存器eax中的值,而这个值是大于KERNBASE的,所以就完成了EIP从小的值到大于KERNBASE的值的转换。在entry_pgdir这个页表中,也把虚拟地址空间[0, 4MB)映射到物理地址空间[0, 4MB)上,所以当访问位于[0, 4MB)之间的虚拟地址时,可以把它们转换为物理地址。
我们在JOS中使用的地址空间布局并不是唯一可能的。操作系统可能会将内核映射到低线性地址,而将线性地址空间的上部留给用户进程。然而,x86内核通常不采用这种方法,因为x86的一种向后兼容模式,即虚拟8086模式,在处理器中“硬连接”以使用线性地址空间的底部,因此如果内核映射到那里,则这种兼容模式根本不能使用。
甚至可以设计内核,使其不必为自己保留处理器线性或虚拟地址空间的任何固定部分,而是有效地允许用户级进程不受限制地使用整个4GB的虚拟地址空间——同时仍然完全保护内核不受这些进程的影响,并保护不同进程彼此不受影响!