lab2代码 https://github.com/TL-SN/rCore/tree/lab2
lab2 目的
本章我们的目标让泥盆纪“邓式鱼”操作系统能够感知多个应用程序的存在,并一个接一个地运行这些应用程序,当一个应用程序执行完毕后,会启动下一个应用程序,直到所有的应用程序都执行完毕。
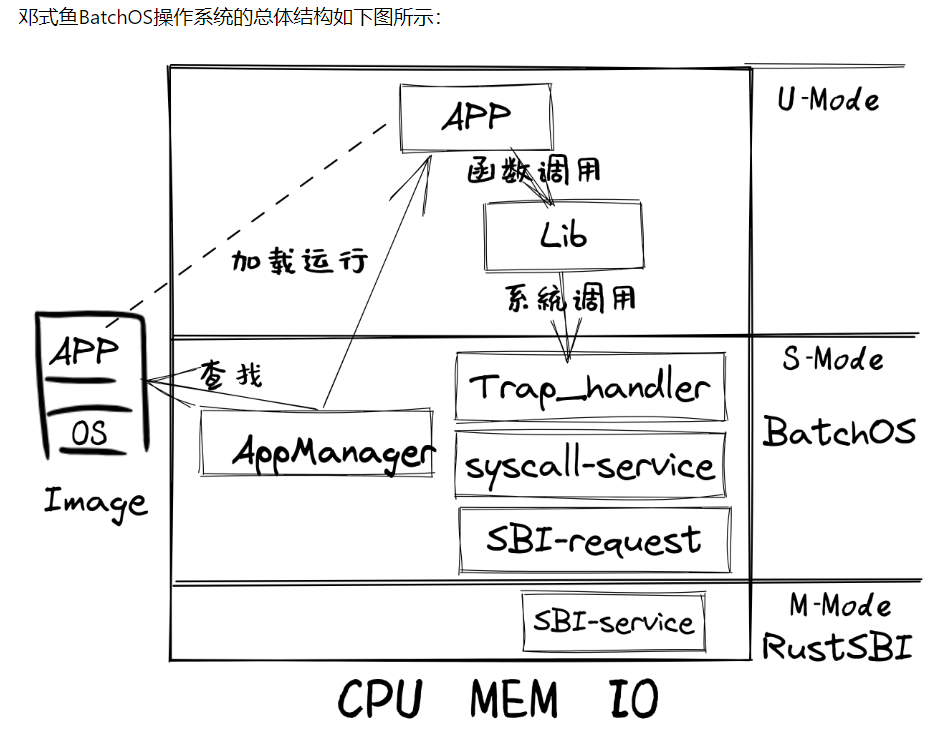
知识点
sret与eret与ecall
eret 代表一类执行环境返回指令,而 sret 特指从 Supervisor 模式的执行环境(即 OS 内核)返回的那条指令,也是本书中主要用到的指令。除了 sret 之外, mret 也属于执行环境返回指令,当从 Machine 模式的执行环境返回时使用, RustSBI 会用到这条指令。
ecall : 具有用户态到内核态的执行环境切换能力的函数调用指令;
sret : 表示从 S 模式返回到 U 模式
特权级
我们之前提到的引导加载程序会在加电后对整个系统进行初始化,它实际上是 SEE 功能的一部分,也就是说在 RISC-V 架构上的引导加载程序一般运行在 M 模式上
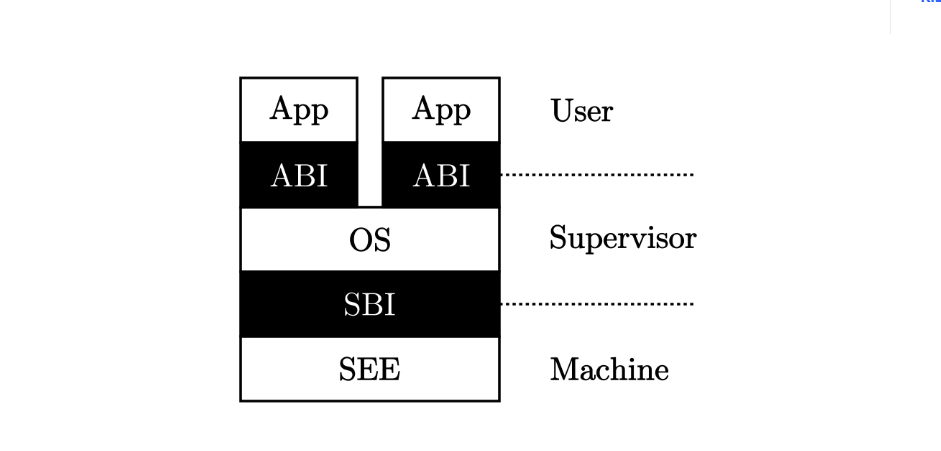
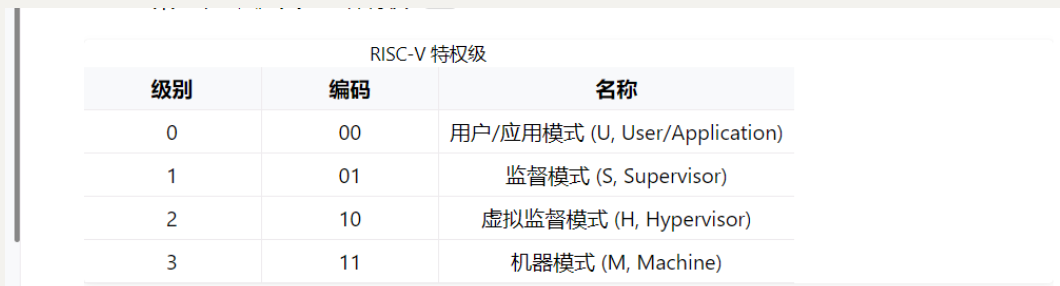
M 模式软件 SEE 和 S 模式的内核之间的接口被称为 监督模式二进制接口 (Supervisor Binary Interface, SBI),而内核和 U 模式的应用程序之间的接口被称为 应用程序二进制接口 (Application Binary Interface, ABI),当然它有一个更加通俗的名字—— 系统调用 (syscall, System Call) 。
进入S特权Trap的相关CSR

sstatus : SPP 等字段给出 Trap 发生之前 CPU 处在哪个特权级(S/U)等信息
sepc : 当 Trap 是一个异常的时候,记录 Trap 发生之前执行的最后一条指令的地址
scause : 描述 Trap 的原因
stval : 给出 Trap 附加信息
stvec : 控制 Trap 处理代码的入口地址
Trap切换栈帧图

rust知识点
use crate与use super
use crate:::- 这种方式用于从 crate(箱)的根开始的绝对路径。
- 当你想要引入位于 crate 根目录下的模块或项时,你会使用
use crate::。 - 它是明确地从当前 crate 的根目录开始引用模块或项。
- 例如,如果你有一个叫做
foo的模块在 crate 根目录下,你可以使用use crate::foo;来引入它。
use super:::- 这种方式用于从当前模块的父模块开始的相对路径。
- 当你想要引入当前模块的父模块中的内容时,你会使用
use super::。 - 它相当于在文件系统中的
../,用于向上移动一级。 - 例如,如果你在一个子模块中,并想要引入父模块中的
bar函数,你可以使用use super::bar;。
rust---智能指针
通过记录所有者的数量,使一份数据被多个所有者同时持有,并在没有任何所有者时自动清理数据
引用与智能指针的不同
引用: 只借用数据
智能指针: 很多时候都拥有它所指向的数据
string与vec
智能指针的实现

智能指针实例---Box
Box


使用场景 :
1、在编译时,某类型的大小无法确定。但使用该类型时,上下文却需要知道它的确切大小。
2、当你有大量数据,想移交所有权,但需要确保在操作时数据不会被复制。
3、在编译时,某类型的大小无法确定。但使用该类型时,上下文却需要知道它的确切大小。当你有大量数据,想移交所有权,但需要确保在操作时数据不会被复制。
例子---使用Box实现链表
首先介绍Cons List
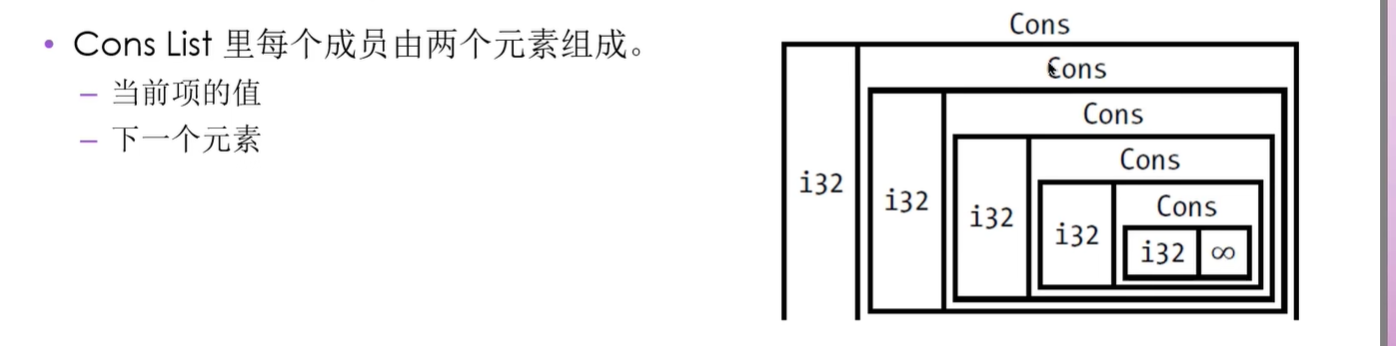
直接用Cons List实现链表会报错,因为rust无法计算存储一个list需要多大的空间
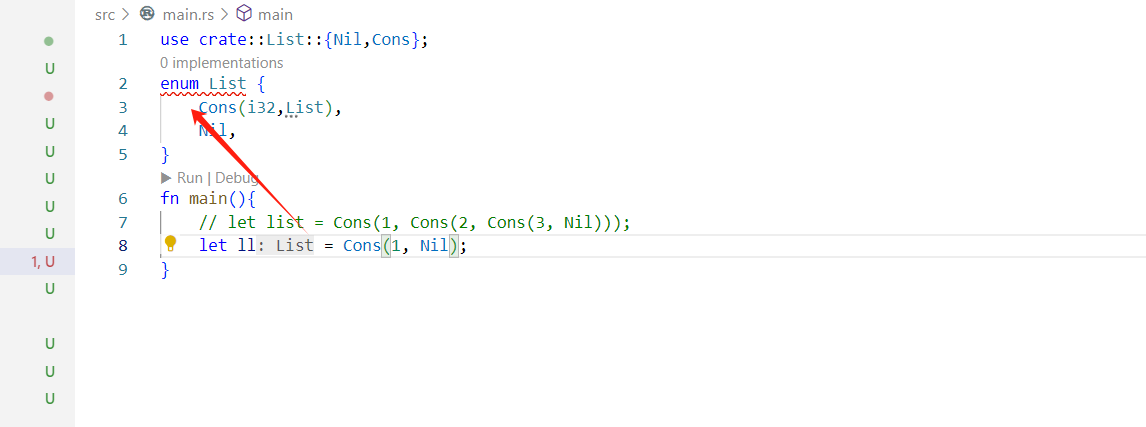
我们可以使用Box
Box
我们需要修改成这样:
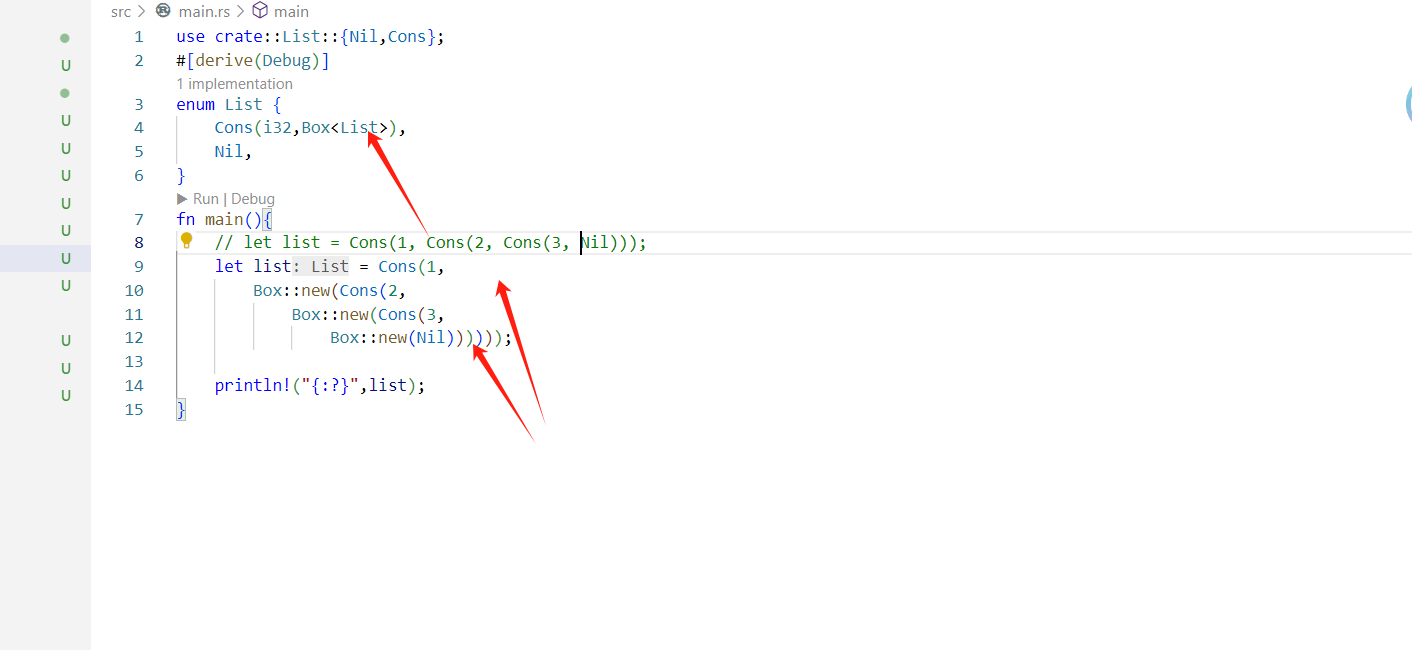
这下可以运行了
Deref Trait
实现Deref Trait使我们可以自定义解引用运算符*的行为。通过实现Deref,智能指针可像常规引用一样来处理

可以看到,let y = Box::new(x);相当于对x加了一层引用
相当于这样:

下面我们手动实现一个具有Deref 特征的结构体MyBox
struct MyBox<T>(T);
impl<T> MyBox<T>{
fn new(x: T) -> MyBox<T>{
MyBox(x)
}
}
fn main(){
let x = 5;
let y = MyBox::new(x);
assert_eq!(5,x);
assert_eq!(5,*y);
}
这个是还未实现Deref 解引用特征的结构体,可以发现,*y操作是直接报错的
use std::ops::Deref;
struct MyBox<T>(T);
impl<T> MyBox<T>{
fn new(x: T) -> MyBox<T>{
MyBox(x)
}
}
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0 // 元组的第0个元素的地址
}
}
fn main(){
let x = 5;
let y = MyBox::new(x);
assert_eq!(5,x);
assert_eq!(5,*y); // *y <=> *(y.deref())
}
这里实现了Deref特征,可以发现程序正常运行
ps: 其实我觉得如果以c语言的角度理解这个解引用,这个Deref 特征的实现简直就是杀鸡用牛刀,本质上就是返回第零个元素的地址
Deref Coercion---隐式解引用转化
为函数和方法提供了一种便捷的特性

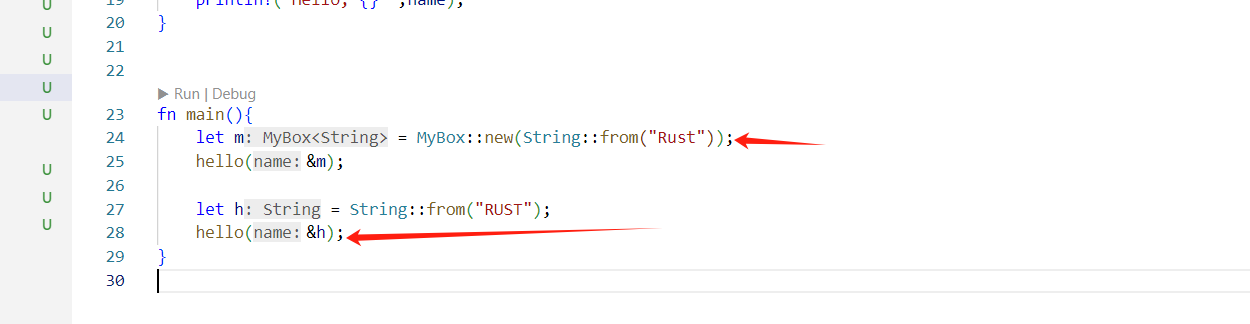
- 由于MyBox实现了Deref,故&MyBox
=> &String - 由于String也实现了Deref,故&String => &str
即连续的隐式Deref转化
Drop Trait
可以让我们自定义当值将要离开作用域时发生的动作,类似于析构函数
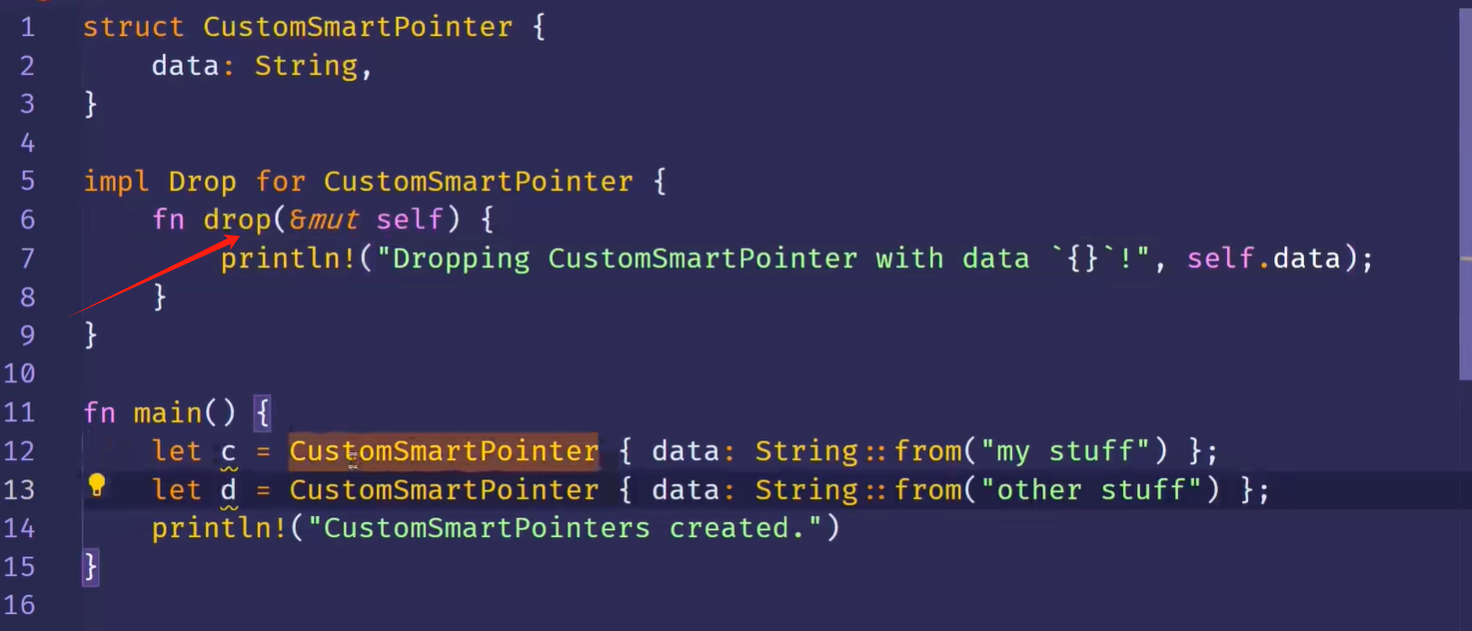

显而易见,与析构函数极其相似
不能显式调用drop函数,但可以调用标准库的std::mem::drop函数来提前drop值
提前清理值
Rc<T>
reference couting,通过不可变引用使程序不同部分之间共享只读数据
引用计数智能指针
使用场景
1、需要在heap上分配数据,这些数据被程序的多个部分读取(只读),但在编译时无法确定哪个部分最后使用完这些数据
2、单线程
例子
以图中方式建立链表

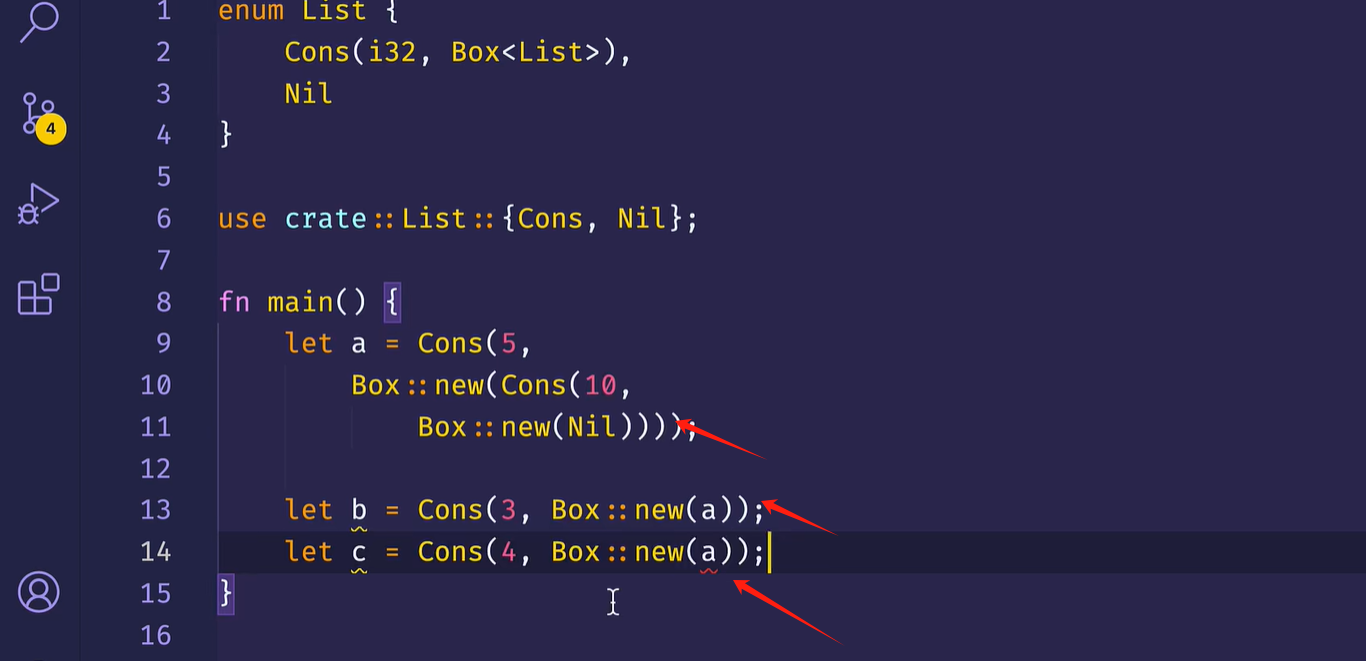
会报错,因为执行完 第13行代码后,a的所有权被转移到b,a自动销毁


用Rc
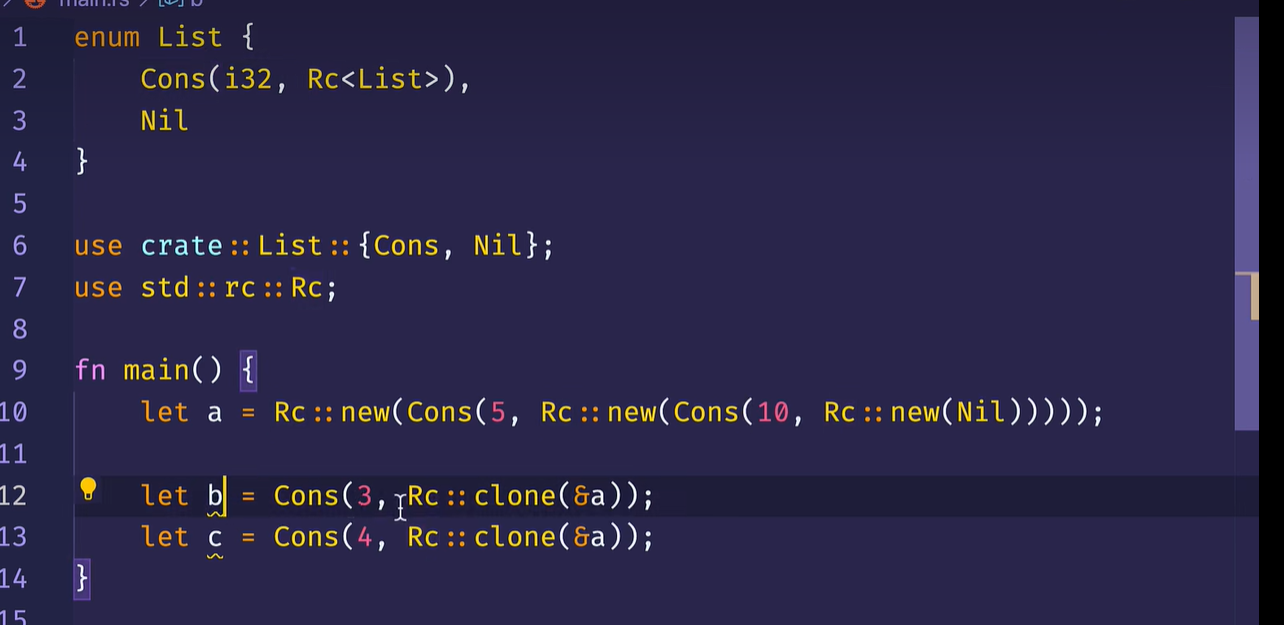
每次调用clone都会使Rc引用计数+1
再看一个例子
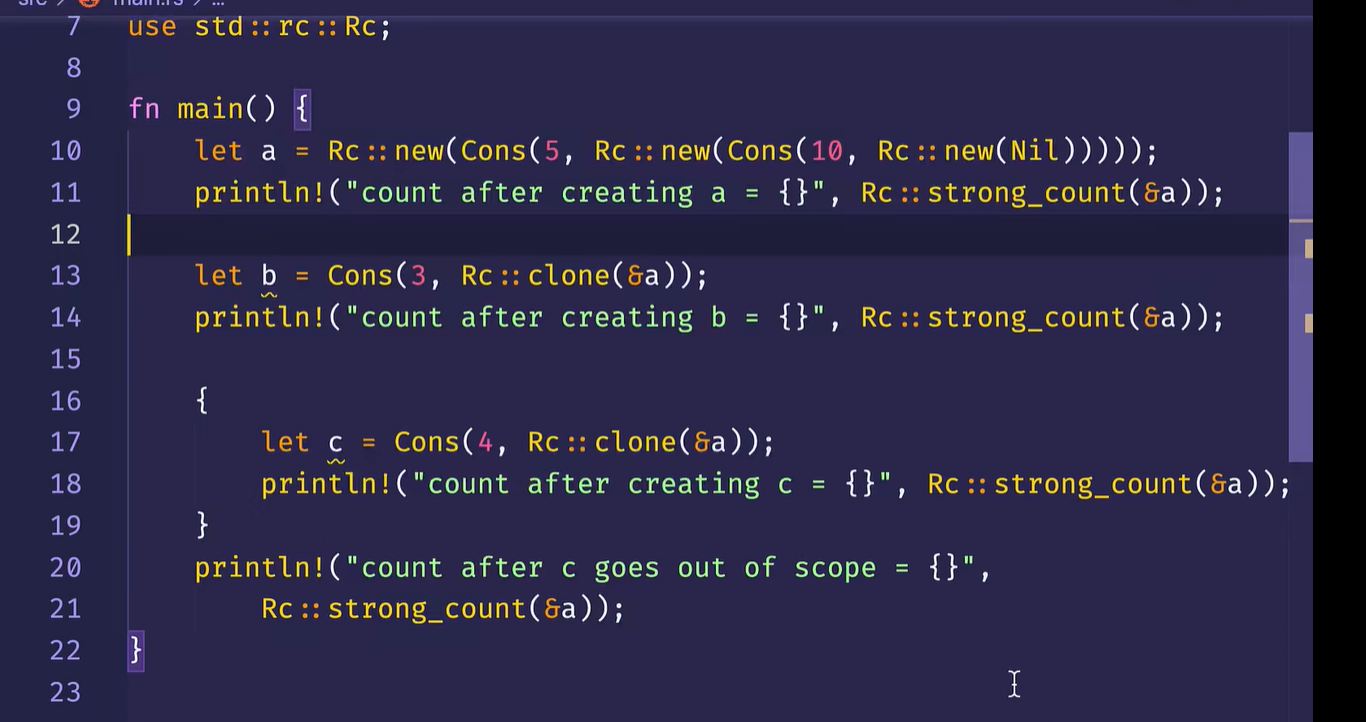
运行:
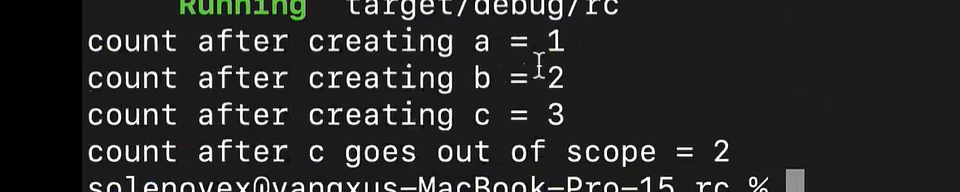
很明显,第16~19行代码一运行结束,rc计数就会减一
RefCell和内部可变性
上面讲的Rc


RefCell也只能用于单线程
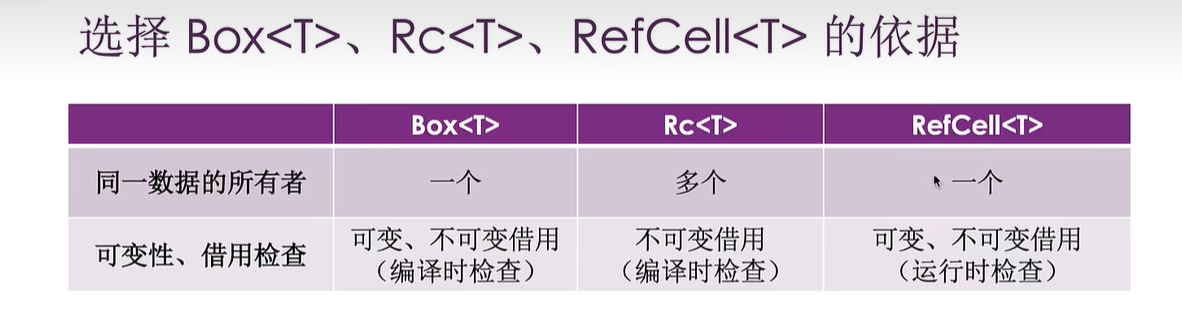
选择Box
RefCell---可变的借用一个不可变的值
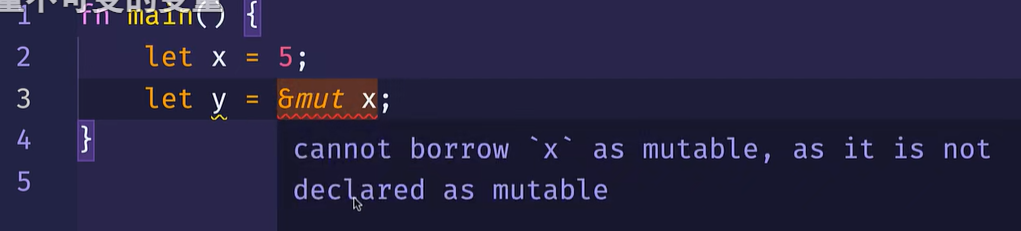
上面的图片是无法可变的借用一个不可变的值的例子
适用场景
代码片段:
// 定义在外部库中的特征
pub trait Messenger {
fn send(&self, msg: String);
}
// --------------------------
// 我们的代码中的数据结构和实现
struct MsgQueue {
msg_cache: Vec<String>,
}
impl Messenger for MsgQueue {
fn send(&self, msg: String) {
self.msg_cache.push(msg)
}
}

修改方法,引入RefCell:
use std::cell::RefCell;
pub trait Messenger {
fn send(&self, msg: String);
}
pub struct MsgQueue {
msg_cache: RefCell<Vec<String>>,
}
impl Messenger for MsgQueue {
fn send(&self, msg: String) {
self.msg_cache.borrow_mut().push(msg)
}
}
fn main() {
let mq = MsgQueue {
msg_cache: RefCell::new(Vec::new()),
};
mq.send("hello, world".to_string());
}
其实就是在一个不可变方法修改一个不可变值,默认这样是不可以的,但用RefCell包裹一层就绕开了这个规则。与 const T *p 修改T道理一样


Rc与RefCell结合使用,实现具有多重所有权的可变数据
#[derive(Debug)]
enum List{
Cons(Rc<RefCell<i32>>,Rc<List>),
Nil,
}
use crate::List::{Cons,Nil};
use std::rc::Rc;
use std::cell::RefCell;
fn main(){
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value),Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(6)),Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(10)),Rc::clone(&a));
*value.borrow_mut()+=10;
println!("a after = {:?}",a);
println!("b after = {:?}",b);
println!("c after = {:?}",c);
}
b , c就是利用Rc才能使用的a
RISC-V汇编指令集
汇编指示符
1、.align n 按2的n次幂字节对齐
2、.balign n 按n字节对齐
3、.global sym 声明sym未全局符号,其它文件可以访问
4、.string “str” 将字符串str放入内存
5、.byte b1,…,bn 在内存中连续存储n个单字节
.word w1,…,wn 在内存中连续存储n个字(4字节)
6、.text 代码段,之后跟的符号都在.text内
7、.data 数据段,之后跟的符号都在.data内
8、.bss 未初始化数据段,之后跟的符号都在.bss中
https://lgl88911.github.io/2021/02/28/RISC-V汇编快速入门/
常见寄存器
risc-v 有32个通用寄存器(简写 reg),标号为x0 - x31
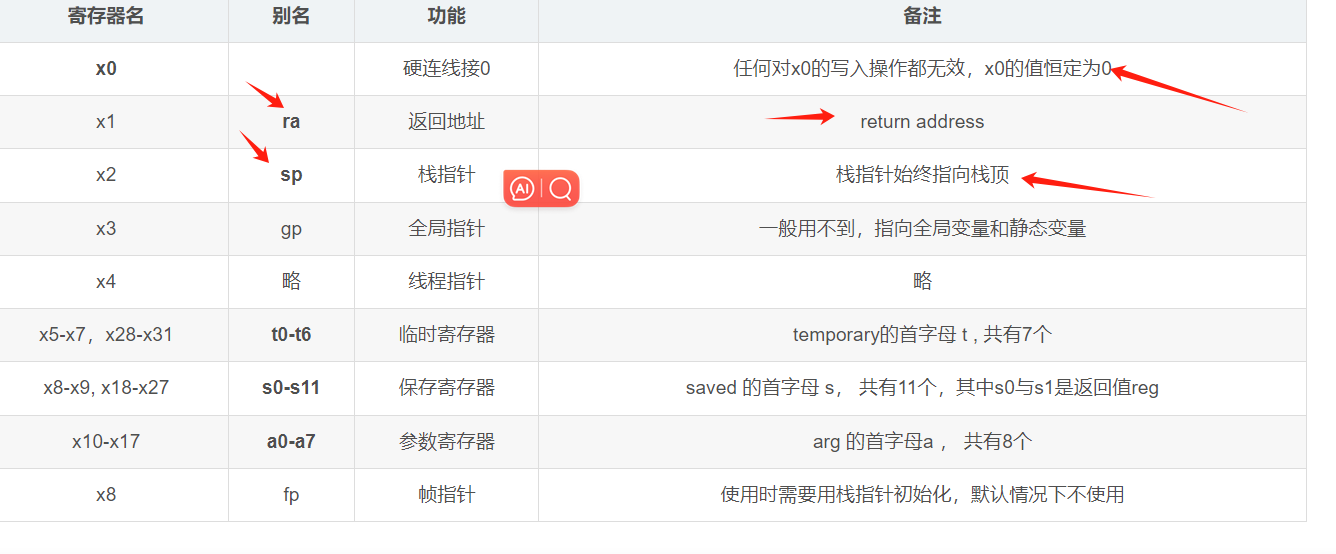
需要注意的是寄存器的别名
RISC-V指令
1、add => add t0, t1, t2 => t0 = t1 + t2
addi => addi t0, t1, -2 => t0 = t1 + (-2)
addi可以加负数,从而精简指令的个数
2、ld => ld t0, 0(t1) => t0 = memory[t1 + 0]
3、lw => lw t2, 20(t3) => t2 = memory[20 + t3]
ld、lw、lh、lb都是从内存中取值,而ld是从内存中取出64位数值,lw是取32位数值,lh是取16位,lb取8位
4、sd => sd t0, 0(t1) => memory[0+t1] = t0
5、sw => sw t0, 0(t1) => memory[0+t1] = t0
sd、sw、sh、sb的区别与ld...的相同
6、lwu => lwu t2, 20(t3) => t2 = memory[20 + t3]
lw 与lwu的区别在于,前者取出32位数值作符号扩展到64位,而后者做无符号扩展到64位
7、sll => sll t1, t2, t3 => t1 = t2 << t3
8、srl => srl t1, t2, t3 => t1 = t2 >> t3
t2右移t3位,做无符号扩展后赋值给t1
9、sra => sra t1, t2, t3 => t1 = t2 >> t3
t2右移t3位,做符号扩展后赋值给t1
10、beq => beq a1, a2, Lable => if(a1 == a2){goto Lable;}
11、jal => jal ra, Symbol => 跳转到Symbol中去, 并把ra设置成返回地址
12、jal => jal ra, 100 => 跳转到pc + 100 * 2的地方中去, 并把ra设置成返回地址
13、jalr => jalr ra, 40(t0) => 跳转到t0+40 的地方中去, 并把ra设置成返回地址
14、mv t0, t1 => t0 = t1
15、li t0, 100 => t0 = 100
16、j Label => 无条件跳到Label 处
17、ret => jal x0, ra
RISC-V中断的一些知识
参考: https://www.cnblogs.com/harrypotterjackson/p/17548837.html
lab2实现批处理的大体流程
在说明大体流程前先说明几个定义
1、AppManager
管理用户模式下的App应用的类
struct AppManager {
num_app: usize, // 记录app的数量
current_app: usize, // 记录表示当前执行的是第几个应用
app_start: [usize; MAX_APP_NUM + 1], // 所有app的起始地址
}
2、trap结构体
记录了trap前后保留的上下文
pub struct TrapContext { // Trap 结构体
/// general regs[0..31] // 32个寄存器
pub x: [usize; 32],
/// CSR sstatus
pub sstatus: Sstatus, // 当前所处的模式
/// CSR sepc
pub sepc: usize, // trap前的地址
}
3、所有用户程序执行的时候都在0x80400000的位置执行
4、所有用户程序均用 rust-objcopy --strip-all 转换为原始二进制格式,并被保存到了os的.data段
5、初始化0x105号CSR寄存器,RISC-V架构默认使用这个寄存器保存陷入地址
而且RISC-V的ecall跳转到的目标地址就是 0x105号的CSR寄存器 ,我们可以看到,RISC-V使用trap来实现系统调用
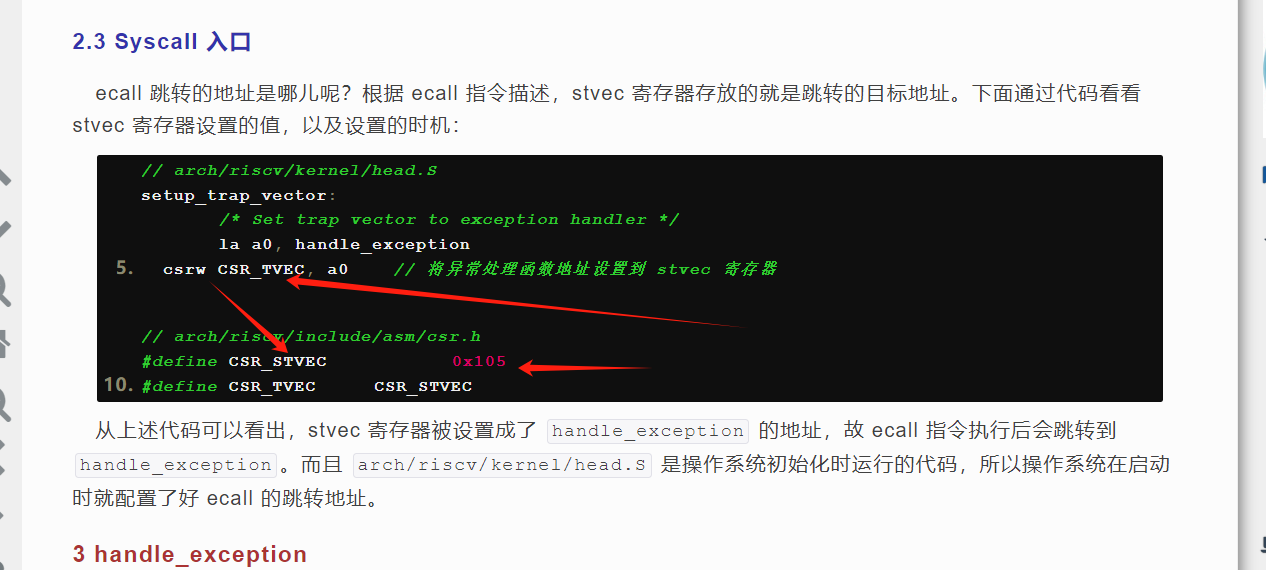
6、所有用户程序均被编号,从0~4
7、trap_handler,用户执行trap指令并保存完毕上下文后会首先进入os的trap_handler中,由trap_handler决定下一步的工作
8、0x105 CSR寄存器指向的地址
其地址指向一处汇编代码存在的地址,该处汇编代码的功能就是切换为内核栈,保存用户态上下文(trap结构体)到内核栈上
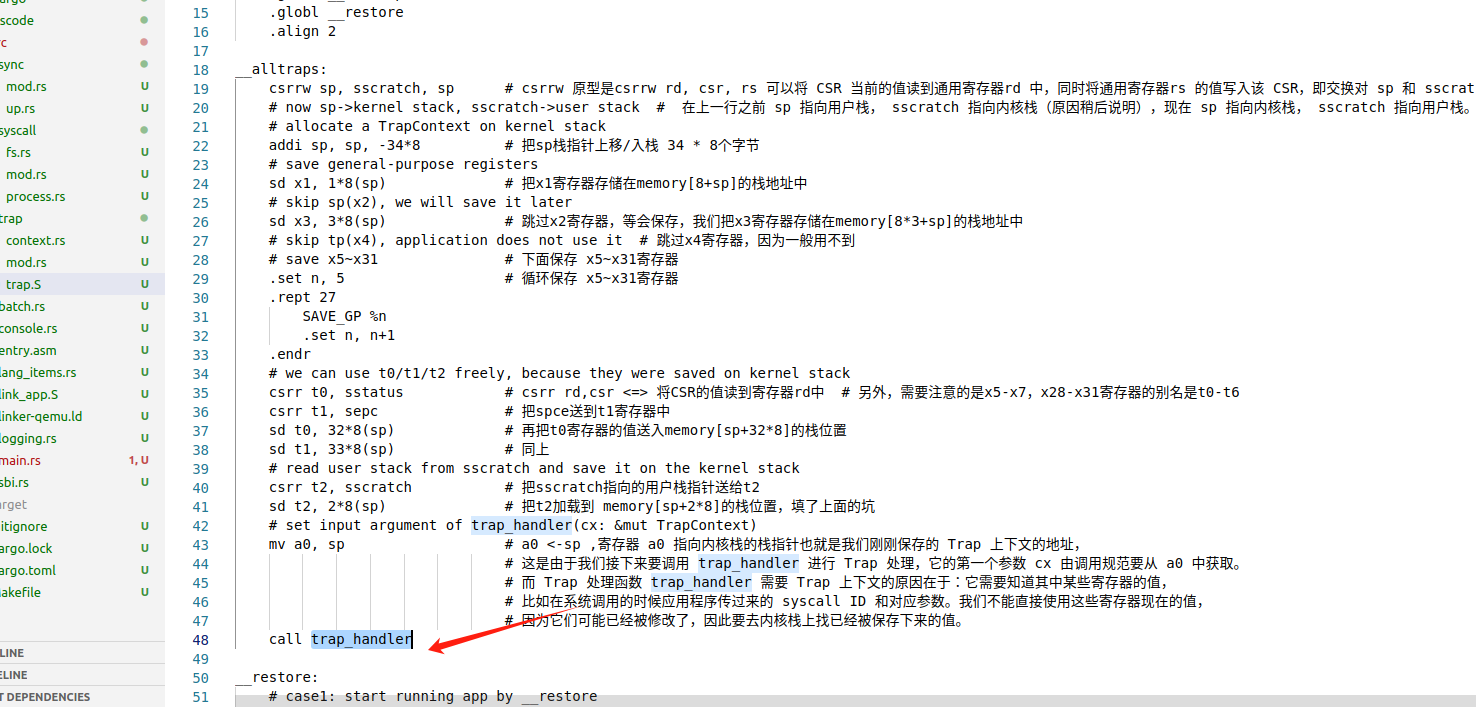
同时利用a0寄存器传参,调用trap_handler函数并把刚保存在trap结构体上的地址传递给trap_handler

主要流程:
1、初始化0x105 CSR寄存器,把trap处理程序的地址写入该寄存器中
2、os做执行0号app的初始化工作
- 把app的二进制数据从.data段载入到0x80400000位置
- os恢复上下文(由于一开始在os中,所以0号app没有需要恢复的上下文,但会获得pc:0x80400000与用户栈空间的初始地址)
3、执行0号app,执行结束后调用exit()函数
- eixt内部执行了系统调用: sys_exit,用户执行系统调用进行trap,系统调用内部使用ecall 指令跳转到内核S态,目的地址来自0x105号CSR寄存器,该地址把用户的上下文(保留32个寄存器,trap前的地址,所处模式)保存在内核栈上(trap结构体)并用a0寄存器传参调用trap_handler
- trap_handler分发trap到sys_exit
4、执行完sys_exit后触发run_next_app函数
之后就循环 1~4,一直到执行完所有的app
存疑


这里SPP的字段被修改为CPU当前特权级,但SPP 不是用来保存之前的特权模式吗
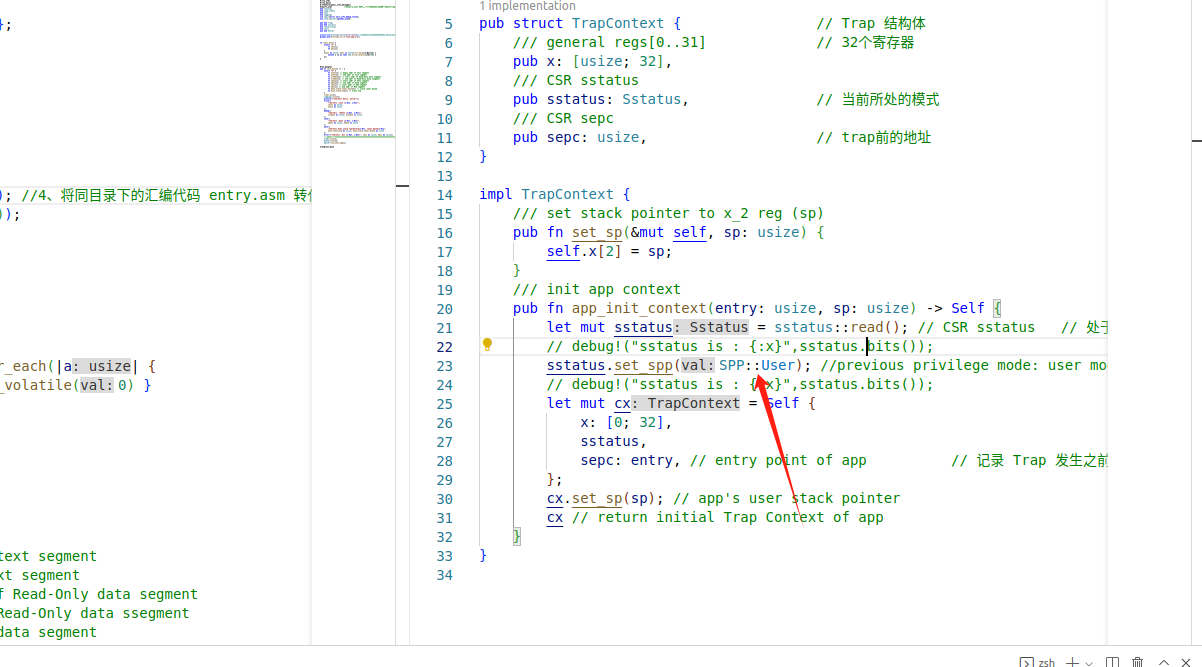
lab2对spp的处理感觉不是很完善,只写了退出s模式时候的spp处理,系统调用进入spp处理是只字不提
而且这些工作不是由CPU自主完成的嘛?
-------------------------------------------------------- 一些思考 ---------------------------------------------------------
我在实验的时候发现,如果把这里的SPP::user改成SPP::Supervisor会发生变化
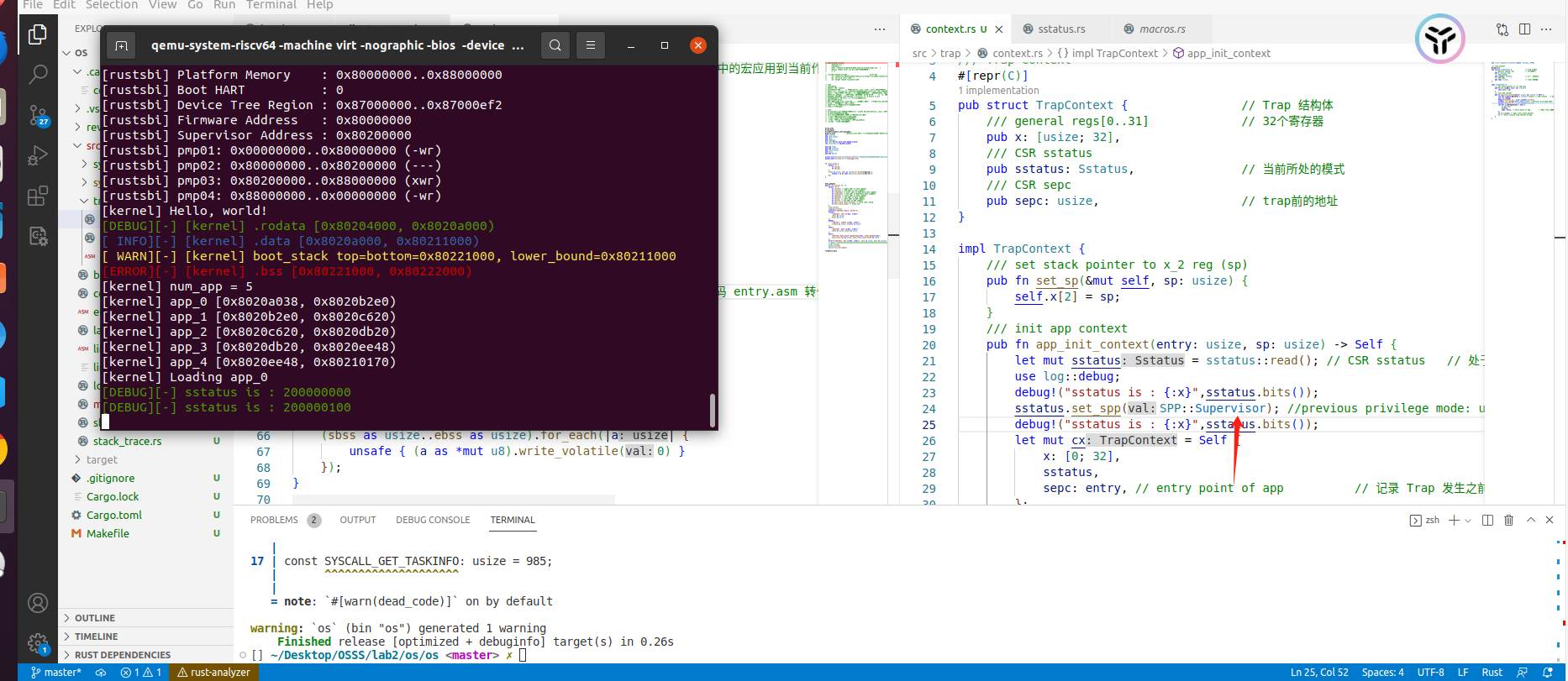
变化如下:

qemu卡死在第0个app里,(因为SPP=1时执行sret相当于s模式下的trap)
我猜测:
-
lab2文档的表述可能有些问题,SPP主要功能就是用来保存之前的特权模式的
-
当从 U 模式触发陷阱(如系统调用通过
ecall指令)转换到 S 模式时,CPU 自动将SPP设置为 U 模式,以指示在处理完陷阱后应该返回到 U 模式。这种情况下,SPP的值被设置为 0,表示 U 模式。而SPP的工作方式是这样的
-
当从 S 模式返回到 U 模式时(通常在陷阱或系统调用处理完毕后),CPU 会检查
sstatus寄存器中的SPP字段。如果SPP被之前的操作设置为 U 模式(即 0),CPU 会将当前模式切换回 U 模式。在切换回 U 模式的过程中,
SPP字段的值通常不会被操作系统或 CPU 显式修改。一旦完成sret指令,SPP字段可能被清零或保留(具体行为取决于 RISC-V 的具体实现),因为在 U 模式中,SPP的值不再重要。
系统调用的时候,CPU也会自主修改SPP,但不是说只能由CPU修改,操作系统也能修改
在lab2的实例中,s与u模式的相互切换过程中,SPP就一直为0的状态,我们看不到cpu为我们做的工作(本来就是0,CPU还要再把SPP设为0,所以我们看不到)
可以再后面的学习中留意一下这个问题
一些git命令
1、git init
执行指令进行初始化,会在原始文件夹中生成一个隐藏的文件夹.git
2、git add
执行指令将文件添加到本地仓库
git add . //添加当前文件夹下的所有文件
$ git add **.cpp //添加当前文件夹下的**.cpp这个文件
3、git commit -m "tlsn"
输入本次的提交说明,准备提交暂存区中的更改的已跟踪文件,单引号内为说明内容
git commit -m "layout" //引号中的内容为对该文件的描述
4、关联github仓库
git remote add origin https://github.com/TL-SN/rCore.git
5、 git push origin branch-name
git push origin lab2
如果我想新建分支并传入文件:

感觉首先得关联github仓库,而且我觉得直接git push origin branch-name修改branch也可以?
lab3的时候试试