在本文中,我们提出了一种新的pFedLA训练框架,该框架能够区分不同客户端的每一层的重要性,从而能够优化具有异构数据的客户端的个性化模型聚合。具体来说,我们在服务器端为每个客户端使用一个专用的超网络,它被训练来识别层粒度上的相互贡献因素。同时,引入参数化机制更新分层聚合权值,逐步利用用户间的相似度,实现精确的模型个性化。在不同的模型和学习任务中进行了大量的实验,我们表明,所提出的方法比最先进的pFL方法取得了明显更高的性能。
1 介绍
联邦学习(FL)已经成为一个突出的协作机器学习框架,可以在不共享私有数据的情况下利用用户间的相似性[33,43,52]。当用户的数据集是非iid(独立且同分布),即用户间距离较大时[23,53],所有客户共享一个全局模型可能会导致收敛速度慢或推理性能差,因为模型可能会显著偏离其本地数据[14,56]。
为了处理这种统计多样性,提出了个性化联邦学习(pFL)机制,允许每个客户端训练一个定制的模型,以适应自己的数据分布[9,12,15,22]。文献在实现pFL方面的现状包括基于数据的方法,即平滑客户数据集之间的统计异质性[8,16],单模型方法,如正则化[22,41],元学习[9],参数解耦[5,24,26],以及多模型方法,即为每个客户训练个性化模型[15,54],通过客户模型的加权组合,可以为每个客户生成个性化的模型。现有的pFL方法在整个模型参数或不同客户的损耗值之间采用距离度量,这不足以利用它们的异构性,因为总体距离度量不能总是反映每个局部模型的重要性,并可能导致不准确的权重组合或非iid分布式数据集的贡献不平衡,从而阻止进一步大规模的客户个性化。主要原因是神经网络的不同层可以有不同的用途,例如,浅层更侧重于局部特征提取,而深层则用于提取全局特征[6,20,21,47,49]。度量模型的距离会忽略这些层次上的差异,导致不准确的个性化,从而影响pFL的训练效率。
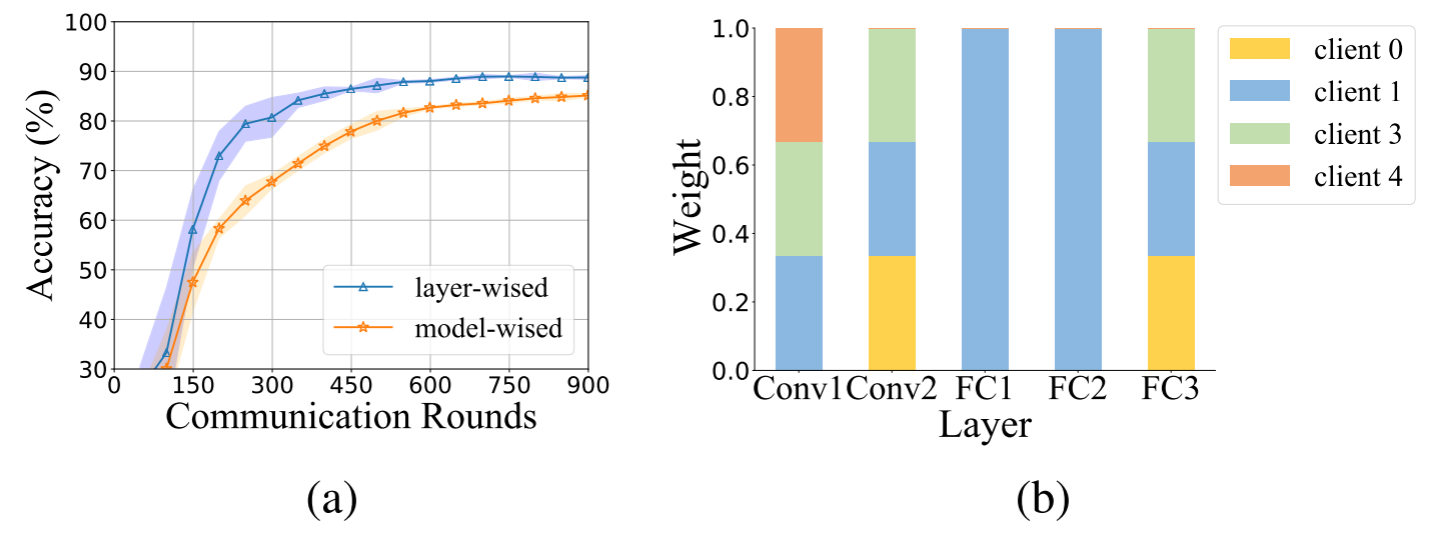
(a) 客户端1的模型性能。两种方法都采用了基于相似度的个性化聚合。即,分层聚合法:通过计算层之间的相似度来进行个性化聚合;模型聚合法:通过计算模型之间的相似度来进行个性化聚合。 (b) 客户端1在最后一轮通信中每一层的权重。
观察分层个性化聚合。 在这个例子中,我们考虑了六个客户端协同学习他们的个性化模型,用于一个九类分类任务。平均模型准确率是通过分层聚合法和模型聚合法得到的,它们分别利用了层间和模型间的相似度。图1显示了对于某个客户端,分层聚合法相比模型聚合法可以获得更高的模型准确率。我们还绘制了客户端最后一轮通信后每一层的权重,并显示了对不同的层应用不同的权重,例如,客户端1的第一和第二全连接层(即FC1, FC2)有较大的权重,而第二卷积层,即Conv1层有较小的权重,可以显著提高个性化模型的准确率。这个例子展示了分层聚合法相比传统的基于模型的个性化联邦学习方法,能够获得更高的性能的潜力,因为层级的相似度可以更准确地反映客户端之间的相关性。通过利用这种分层相似度和识别层级的跨用户贡献,有望为所有客户端生成高效和有效的个性化模型。
受此启发,我们提出了一种新颖的联邦训练框架,即pFedLA,能够以分层的方式自适应地促进客户端之间的底层协作。具体来说,在服务器端,为每个客户端引入了一个专用的超网络,用于在个性化联邦学习训练过程中学习跨客户端层的权重,这被证明可以有效地提高在非独立同分布数据集上的个性化程度。我们实验证明了所提出的pFedLA可以在广泛使用的模型和数据集上,即EMNIST, FashionMNIST, CIFAR10和CIFAR100,比最先进的基线方法获得更高的性能。本文的贡献总结如下:
- 这篇论文是第一个明确揭示了在异构FL客户端中,分层智能聚集与模型智能方法的好处;
- 提出了一种分层的个性化联邦学习(pFedLA)训练框架,可以有效地利用非iid数据的客户之间的用户间相似性,并产生准确的个性化模型;
- 在4个典型的图像分类任务上进行了广泛的实验,证明了pFedLA比最先进的方法有更好的性能。
2 相关工作
2.1 个性化联合学习
近年来,人们提出了多种实现pml的方法,可分为基于数据的和基于模型的两大类。基于数据的方法侧重于减少客户数据集之间的统计异质性,以提高模型的收敛性,而基于模型的方法侧重于为不同的客户生成定制的模型结构或参数。
3
4 实验
5 总结
6 代码
- Personalized Layer-wised Aggregation Federated Learningpersonalized layer-wised aggregation federated detectability safelearning aggregation federated divergence-based aggregation divergence federated federated learning 005 heterogeneous federated learning yourself healthcare federated learning会议 layer-wised personalized clustering-based hierarchical personalized recognition federated