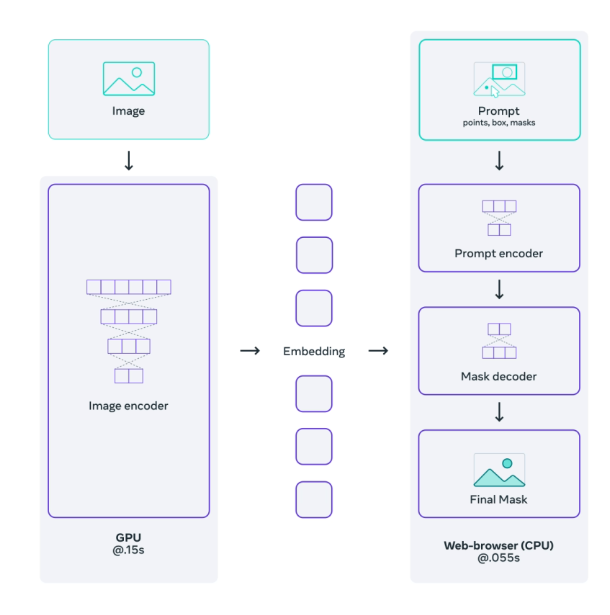
What is the structure of the model?
- A ViT-H image encoder that runs once per image and outputs an image embedding
- A prompt encoder that embeds input prompts such as clicks or boxes
- A lightweight transformer based mask decoder that predicts object masks from the image embedding and prompt embeddings