Kafka
- 大数据系统架构是什么样?为什么需要Kafka这样的桥梁作为连接?
- Kafka的系统设计与传统MQ有什么不同?
- 如何实现分布式?如何动态添加 Broker并通知上下游?
- 有了 Kafka 和 Storm 后如何搭建流式处理系统?如何处理故障带来地数据不准确?
Realtime Data Processing at Facebook 从应用层看大数据如何设计,不只考虑内部架构,还考虑外部使用者
Questioning the Lambda Architecture 关于Lambda架构思考
日志收集器
大数据的来源通常是业务系统产生的日志,最早用于广告和搜索业务。最早还不是流式处理,而是使用MapReduce进行处理。
早期可以通过将日志落地到服务器硬盘,定时分割新文件,使用cronjob定时上传到HDFS上。这样操作简单,但是数据上传前系统没有灾备,机器故障会导致日志丢失。如果不写入本地而是直接向HDFS写入,会导致负载过大。而且多个应用服务器是写入一个文件还是多个文件呢?如果写入一个文件,多个客户端在写入同一个文件时会在主副本上排队,引发竞争。如果写入多个文件,每个时间段产生日志文件数等于发起请求的机器数,会导致大量小文件,不利于存储和计算。
日志收集器 Scribe 和 Flume 就负责从各个应用服务器上收集日志,汇总到一个日志汇集(Log Aggregator)服务器中。多层嵌套可形成一个树状结构,最终只有几个日志汇集服务器向HDFS写入数据。此时不会有太多并发写,也能发挥HDFS顺序写的高吞吐优势。其不是实时上传,而是按照指定时间间隔上传。这样每分钟上传一次日志到HDFS,就可以每分钟运行一次MapReduce进行分析反馈
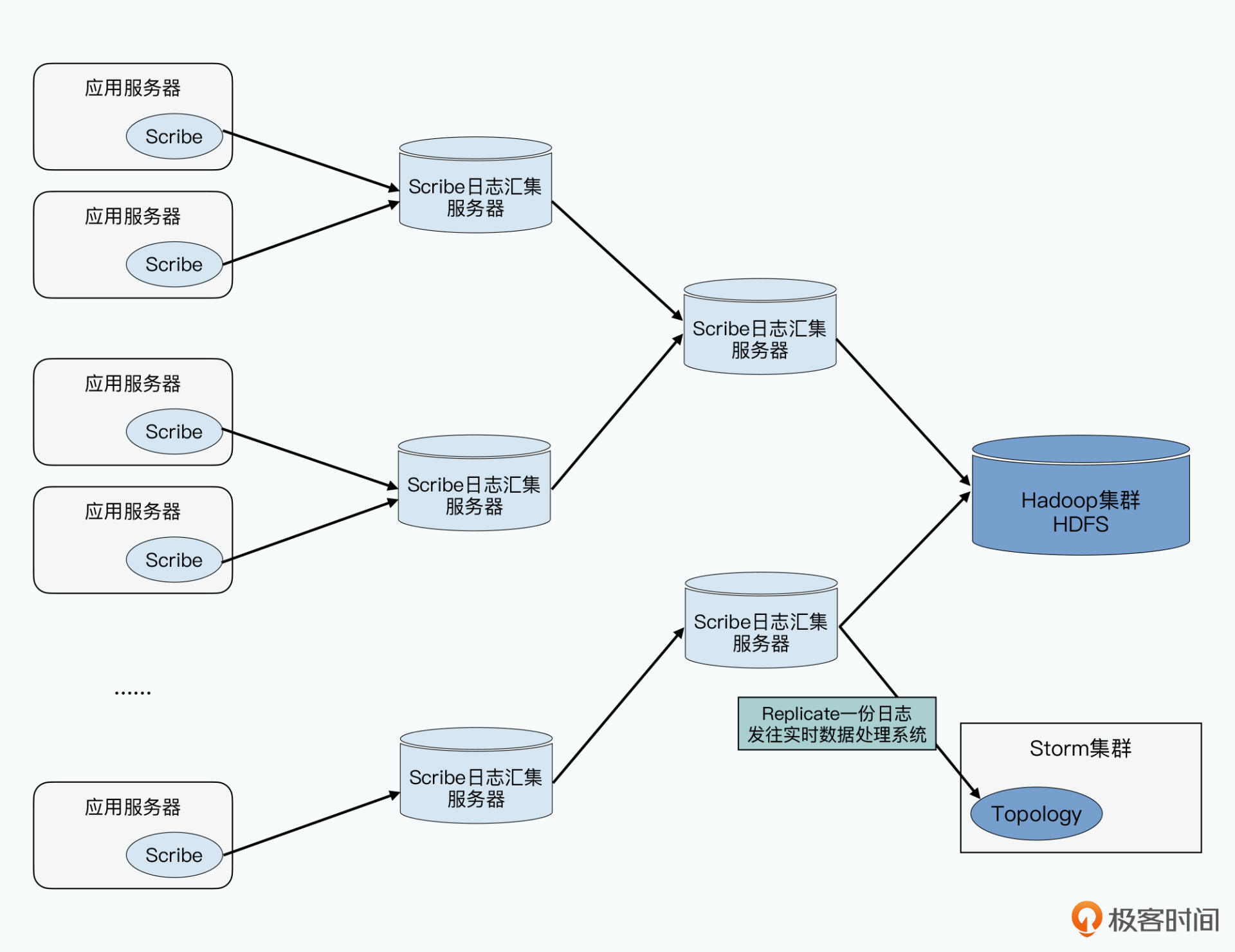
收集日志定时上传的做法有些问题:
- 隐式依赖:要分析最近5分钟的点击数据,那么要在HDFS上通过文件名分辨出
- 容错问题:为预防网络和硬件故障,在日志收集器每次上传数据时查看是否有上传一半的数据
所以需要一个MQ用于配合流式计算
Kafka 系统架构
kafka接受应用服务器发送的日志,下游可以对接HDFS或Storm之类的流式计算系统。此时kafka变成分布式MQ,典型的生产者消费者模型。
- Producer:日志生产者,如应用服务器
- Broker:实际Kafka的服务进程,为了容错和高可用,kafka是分布式的,每台服务器都有对应的Broker进程。所有的消息进行两种类型的分组
- 业务分组:对应Topic概念。如将广告日志、搜索日志分开,两类的格式和用途都不同
- 数据分区:对应Partition,实现分布式的高性能和高可用
- 同一Topic日志平均分配到多台机器,确保并行处理,有助于水平拓展系统的处理能力
- 实现容错,某个Broker出现故障,上游的Producer可将日志发送到其他Broker,确保系统仍能正常运作
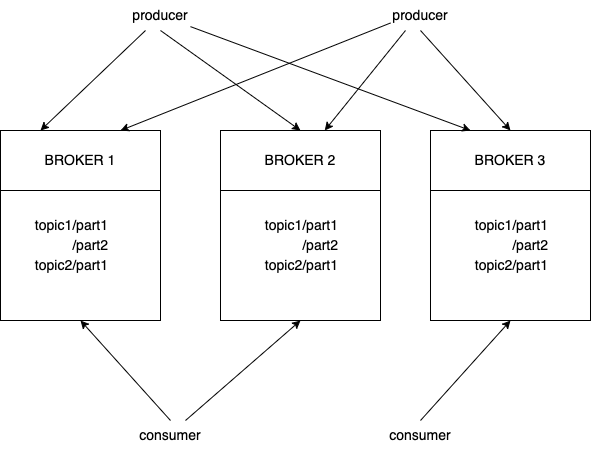
- Consumer:处理日志的。kafka支持多消费者
- 一条消息可能不同程序都要读取,如上传到HDFS和Storm进行处理
- 同一用途程序可能有多个并行消费者确保吞吐量
为区分不同的消费者,kafka将用途相同的程序称为一个Cousumer Group。
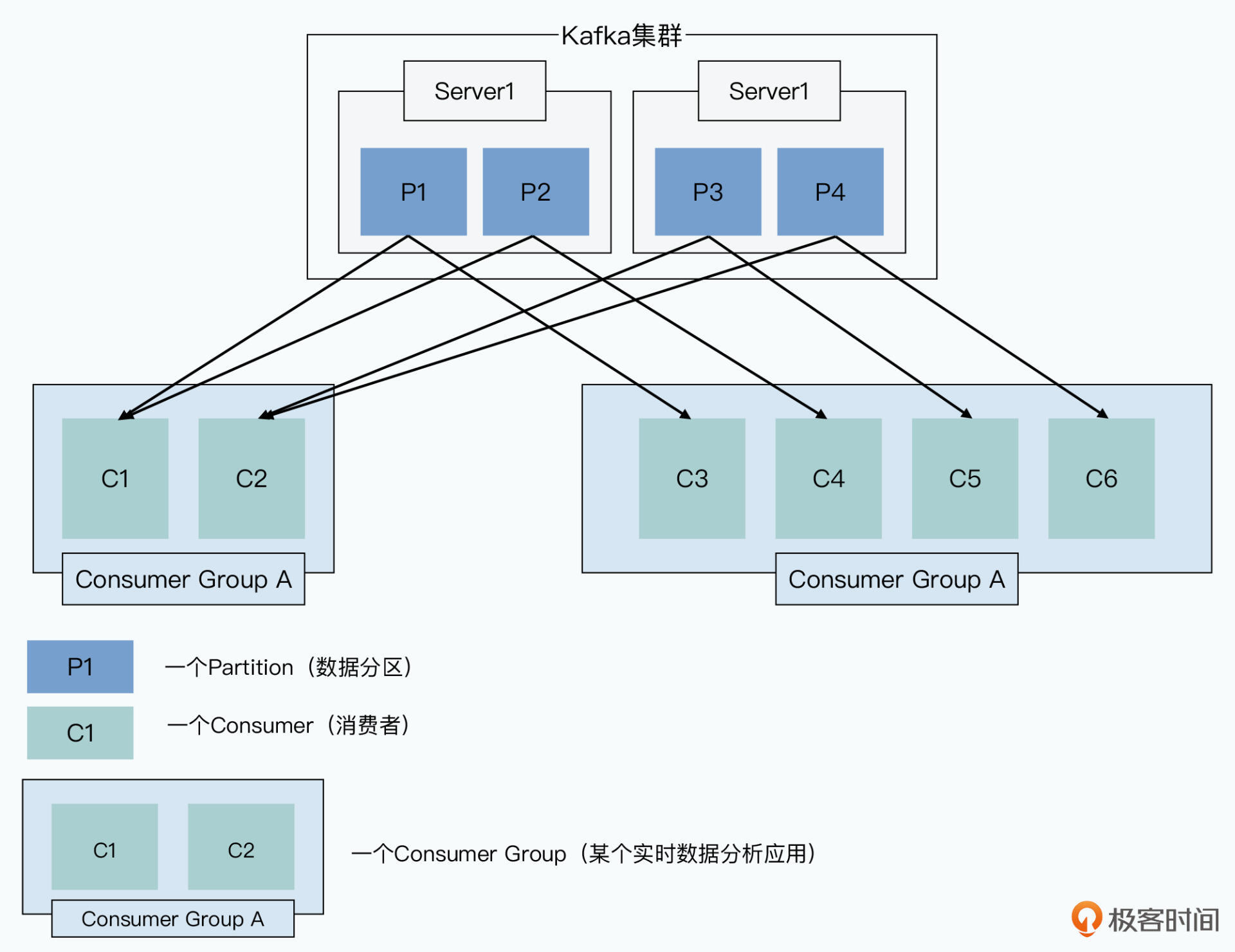
这视乎和一般MQ没区别
拉数据而不是推
原有的主动推送数据到下游的方案有个缺陷:MQ要维护下游是否成功处理消息的状态。传统MQ通过一个 message-id 唯一标识一条消息,当下游所有订阅者消费后才从内存删除。这也意味着下游处理完成前要一直存储着这些信息。
Kafka 采用不同思路:
- 所有Consumer来拉取数据,Consumer消费了哪些数据又其自己维护,kafka无需维护
- 采用简单的追加文件写的方式作为消息队列,kafka中没有唯一的message-id,也没有负责的数据结构。下游消费者只要维护此时处理到的日志在日志文件中的偏移量(offset)即可
此外还有些限制,一个consumer总是顺序地消费来自一个特定分区(Partition)的消息,一个Partiton是kafka里并行处理的最小单位。也就是一个Partition的数据只会被一个consumer处理
Producer的生成消息和Consumer的消费消息都变成了简单的顺序的文件读写
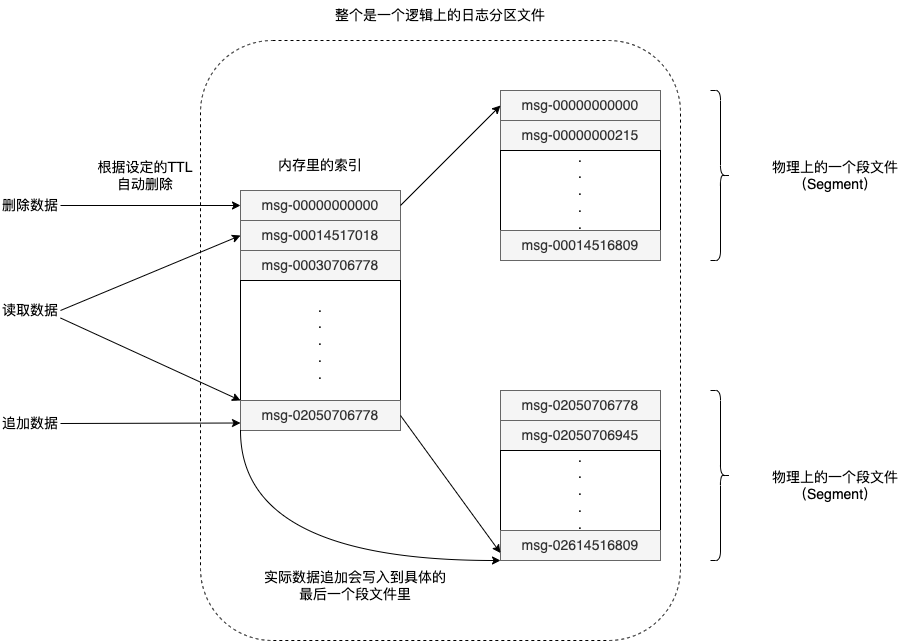
单个 Partition 的读写实现
每个Topic会有多个Partition分布到不同的机器,一个机器可能又多个Partition,一个Partition是一个逻辑上的日志文件。Partition日志文件通过实现成一组大小基本相同的Segment文件,如1GB大小。每当有新消息发来时,Broker将消息追加到最后那个Segment文件。考虑到性能,可自定义将文件刷新到硬盘的条件。
Broker维护一个简单索引,就是通过一个虚拟偏移量,指向一个具体的Segment文件。那么Consumer要消费数据时根据本地维护的已处理完成偏移量在索引中查找Segment文件再读取。
优秀的 Linux 文件系统
kafka使用本地文件系统承担MQ持久化功能,没有自己实现缓存,而是使用了Linux页缓存(Page Cache)。Kafka写的数据都在Page Cache,且因为流式计算时读写都有很强的时间局部性,Broker刚写入就会被读取,所以大量数据都会命中缓存。kafka使用 mmap 写数据。
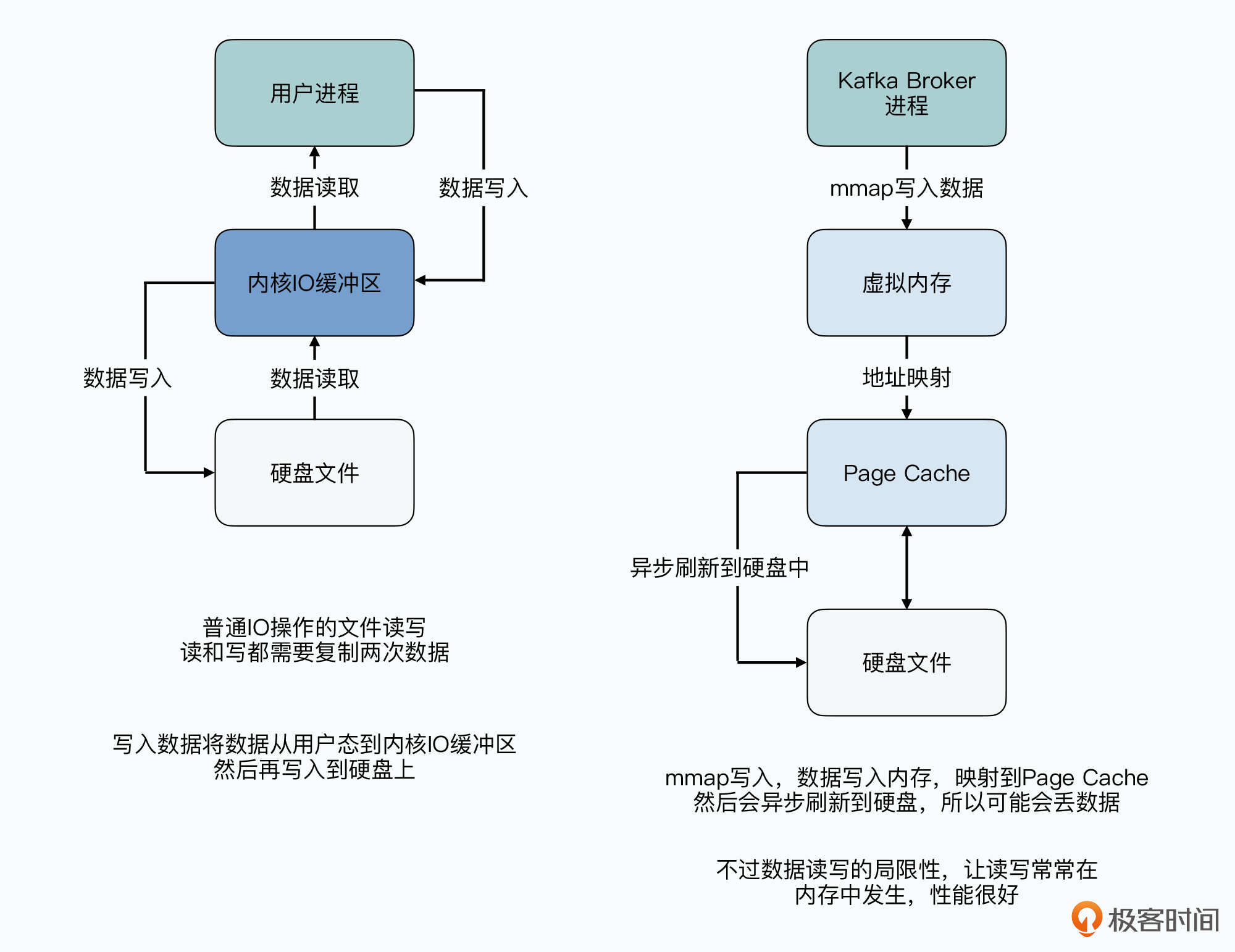
同时避免了两个内存缓存的问题:
- JVM的GC开销
- 缓存冷启动问题。Broker挂掉重启,此时内存没有任何数据,这时读取数据性能比已长时间运行、内存缓存了很多数据的系统性能差很多
这2点会导致系统性能抖动,直接使用Page Cache使得在JVM内除了业务代码没有其他开销
除了利用文件系统,kafka 还用了 sendfile API,通过DMA直接将数据传到网络,省去了从内核态到用户态再到内核态的复制。
小结
kafka比日志收集器和一般MQ好是因为对业务需求假设不同:
- Kafka假设处理海量日志,可容忍丢失,更注重系统整体的吞吐量、可拓展性、错误恢复能力。
- 传统MQ关注小数据量下是否每条消息都被业务系统处理完成,比如业务交易,每条都要确认,但整体吞吐量不大
- 日志收集器关系的是日志收集,不考虑高吞吐传输日志和下游的处理
kafka考虑:实时传输数据 + 实时处理数据
kafka在设计时,不仅简单地只从系统内部思考设计,还考虑全链路地数据流程有哪些需求
分布式实现
Kafka没有master节点,使用zookeeper。没启动一个Broker就注册到 ZooKeeper 上,注册信息是Broker的主机名和端口。还记录Topic和Partition。zookeeper类似Chubby,都是分布式锁。每个Kafka的Broker将自己信息像一个文件样写在一个zookeeper目录下。
此外zookeeper还提供了一个监听-通知机制。Producer只要监听Brokers目录就知道有哪些Broker,Producer也可不关心zookeeper,而是直接发送给负载均衡。
高可用机制
0.8版本后支持了多副本的高可用:
- 每个分区都有多个副本,类似GFS默认3个
- 副本中有一个leader,其余为 follower。Producer只要写入leader,leader将数据同步到本地日志文件
- 每个follower都从leader拉取最新数据,一旦拉到后就像leader发送ACK
- 可自定义多少个follower成功拉取后Producer才写入成功,通过在发送消息里指定acks字段决定,为0无需写入磁盘就算成功,为2则需要1个leader和1个follower都写入磁盘才算成功。acks参数可调节可用性和性能
负载均衡机制
消费数据的逻辑较复杂,主要因为动态增减Broker和Consumer。Consumer一样注册到zookeeper上,同一个Consumer Group下一个Partition只会被一个Consumer消费,这个Partition和Consumer的映射关系也被记录到zookeeper里,也被称为“所有权注册表”。
consumer不断处理partition数据,其处理到的offset位置页记录到zookeeper上。这样即使consumer挂掉,其他consumer来接手也知道从哪开始。
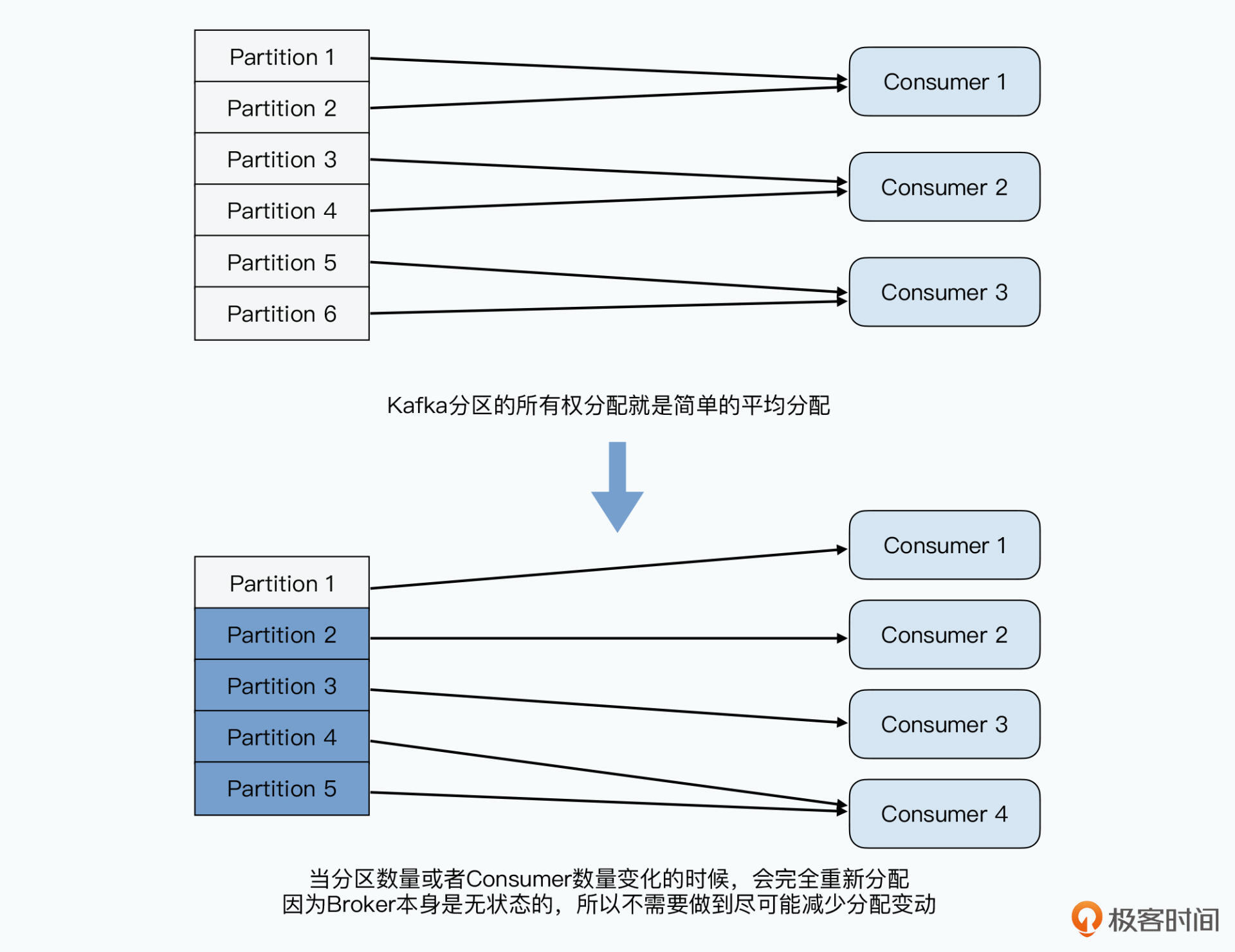
一旦Broker或Consumer增减,kafka就做一次“再平衡(Rebalance)”,就是把分区重新按照consumer的数量进行分配,确保下游负载平均。采用平均分配。有X个分区和Y个consumer,kafka算出N=X/Y,然后将0~N-1分区给第一个consumer,N~2N-1给第二个Consumer。因为Offset保存在Zookeeper,新的consumer知道从哪开始。
kafka和storm都是“至少一次”。通过更新zookeeper上offset确认消息处理成功,如果Consumer出现故障,要从上一个offset重新开始处理,这无法避免重复处理消息。如要避免,需在消息体内通过message-id字段和其他去重机制实现。
顺序保障机制
有些限制:
- kafka很难提供对单条信息的事务。zookeeper上保存的是最新处理完的消息的offset,而不是message-id与是否被消费的状态的映射,所以只能按消息在Partition中偏移量顺序处理
- 没有严格顺序定义。多个Broker间,后来的消息可能被先处理
对于统计广告点击等场景这都不重要,业务间异步通信适合使用传统的MQ
数据处理 - 流批一体
流式计算还有几个问题:
- 只能保障“At Least Once”的数据处理模式,批处理下做到“Exactly Once”。批处理结果是准确的,流式计算结果是有误差的。
- 批处理程序容易修改,流式处理程序不容易
重写一个流式计算程序不难,难的是如何不影响线上程序运行情况下进行发布。根据新的需求生成过去30天数据的新报表,此时可以重放过去30天日志数据。如果存在HDFS,需要拉取数据在发送;使用kafka数据都在本地磁盘,仍需重放日志。重放要花费很多时间、或短时间内消耗大量计算资源。
最常发生的变更是解决分析程序中的bug,这时输入数据和输出结构不会变化,但需要反复修改数据处理程序并反复运行。这对批处理压力不大,但对流式计算会有大量重放日子的工作量。
Lambda 架构
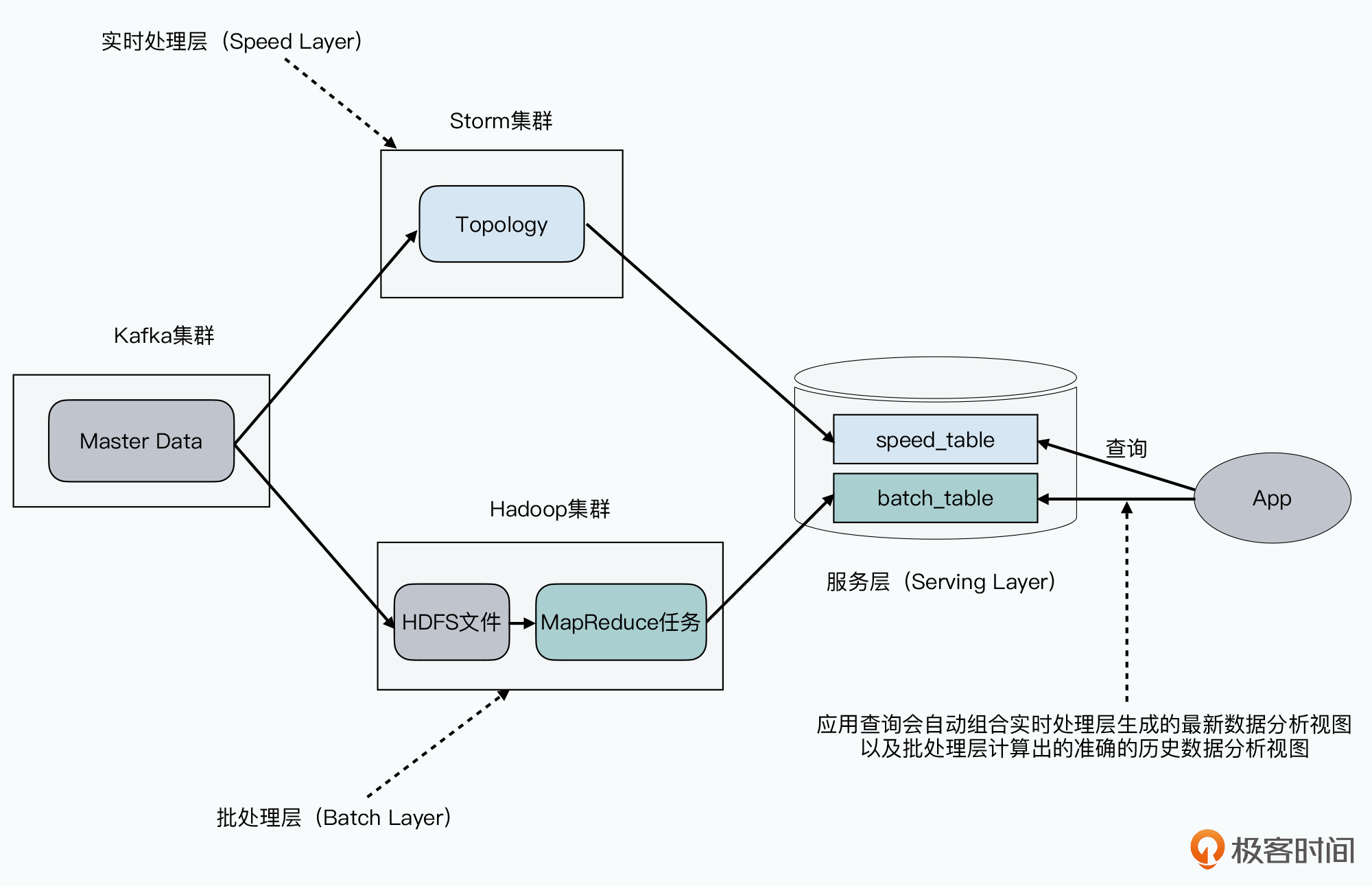
先将数据处理流抽象成 View = Query(Data) 这样一个函数。
- Master Data:原始日志
- Query:批处理或流式处理
- View:基于特定查询的视图
程序有bug只需重写Query,需求有变只要重写View。对于用户只要暴露View即可。这时,可通过Storm进行实时计算尽快获得分析结果;同时定时运行MapReduce程序获得更准确的数据结果。用户看到的是同一个视图,只是先看到的是不精确的结果,后看到修正过的结果。外部用户只要通过SQL直接查询服务层即可。
演变为Twitter的SummingBird
Kappa 架构
Lambda架构的缺点:什么都要两遍
- 所有视图在实时计算层计算一次,在批处理层计算一次。即使没有修改程序也要付出双倍计算资源
- 批处理和流处理底层框架不同,代码要两套,要双倍开发资源
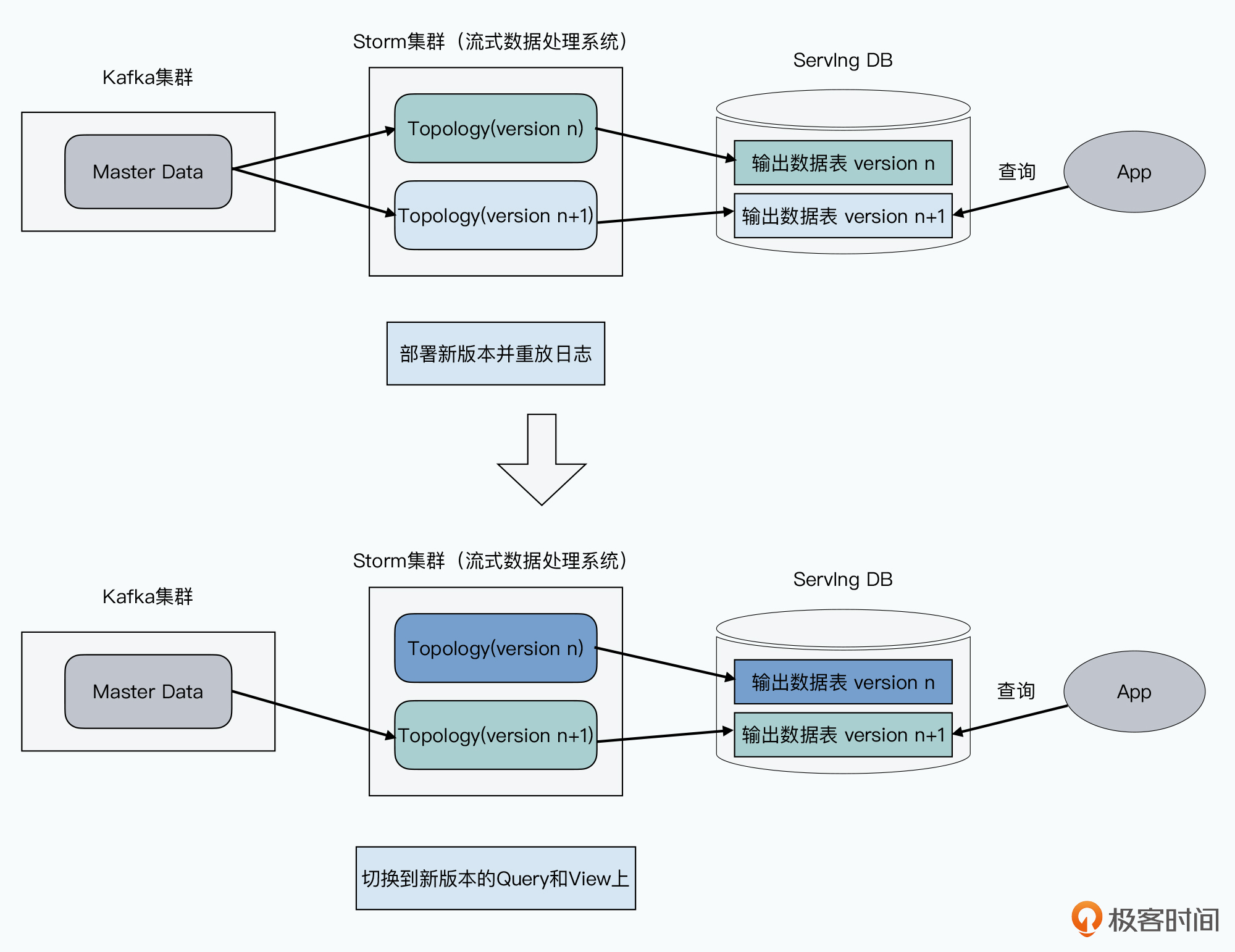
通过日志收集器收集日志落地到HDFS上,一但想重放日志,就要把日志从HDFS分片拉到不同服务器,再搭建日志收集器集群重放日志。
有了kafka后重放日志简单了,因为所有日志都在kafka集群本地硬盘上。重放日志也就是重置offset。
Kappa 架构去掉了 Lambda 架构的批处理层,再实时处理层支持了多个视图版本。如果要对Query修改,先多部署一个新版本的代码,对其进行日志重放,在服务层生成新的视图结果。日志重放完成前,外部用户查询仍得到旧程序产生结果,一旦新程序赶上进度就停止旧版本的实时处理层代码。
Kappa架构提出后大数据进入“流批一体”阶段
小结
kafka 没有 master,Broker也不维持状态。Broker 的状态信息和 Consumer 处理数据的偏移offset都记录在zookeeper上。
数据分区平均顺序分配给Consumer,通过ZooKeeper里的“所有权注册表”记录下来。
Lambda 将数据处理流程分为批处理层、实时处理层、服务层,抽象为 View=Query(Data)
Kappa 架构利用kafka把日志放在Broker本地硬盘特性,提出放弃批处理转而提供多版本实时处理层程序。这也是之后大数据技术的进化方向