问题
数据库物理文件碎片通常不被视为性能问题。但是,如果数据文件碎片化,则由于机械磁盘中的寻道开销或旋转延迟,数据库引擎将花费更长的时间来检索数据。此外,“NTFS 卷中碎片严重的文件可能不会增长超过一定大小”,如果您在某些非常不幸的情况下启用了“自动增长”,则该过程可能会失败并显示错误:“665(由于文件系统限制,无法完成请求的操作。)”。
在本技巧中,我们将了解物理文件碎片的影响以及如何使用 Microsoft 的 Sysinternals 工具 Contig 解决它。
解决方案
在谈论系统性能时,物理文件碎片是一个需要考虑的问题。但是,我们作为DBA并不太重视这个话题,而是把所有的精力都集中在数据库上,这是我们的工作,但有时我们必须看到全貌。在大多数情况下,物理文件碎片应该是最后要检查的事情。
让我们看看什么会导致文件碎片。
- 许多中型组织为了降低成本,与 SharePoint 或 Web 服务器等其他应用程序共享数据库服务器。在这种情况下,无论数据库如何,文件系统都可能会出现碎片。当数据库需要分配磁盘空间时,它可能是分散的。
- 重复备份操作可能会导致磁盘碎片,因此您应该备份到其他磁盘或设备。
物理文件碎片的影响
聚集索引尝试组织索引,以便只需要顺序读取。如果 .MDF 在磁盘上是连续的,这非常有用,但如果文件分布在磁盘上,则没有那么有用。请记住,SQL Server 不知道文件分配,这是一项操作系统任务。
Sysinternal 的 Contig 工具
这是 Microsoft 的一款免费实用程序,旨在优化单个文件或创建连续的新文件。您可以在这里免费下载:http://technet.microsoft.com/en-us/sysinternals/bb897428
它非常容易使用。使用contig -a选项,您可以使用数据库在线分析指定文件的碎片。要对文件进行碎片整理,只需运行Contig [FileName]即可。
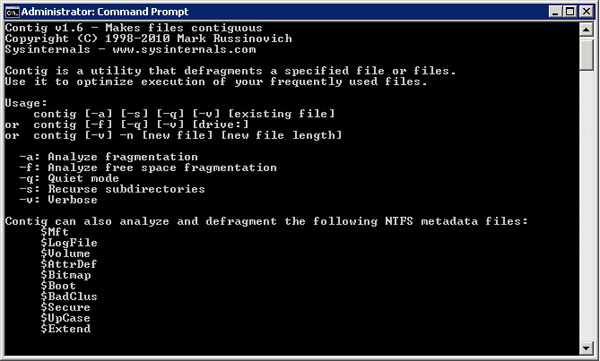
不用说,为了对数据库进行碎片整理,数据库文件必须处于OFFLINE 状态。
示例
我创建了一个物理碎片数据库来向您展示物理文件碎片对性能的影响。该数据库大小为 3.5 GB,如下图所示,它的碎片严重,有 2000 个碎片。
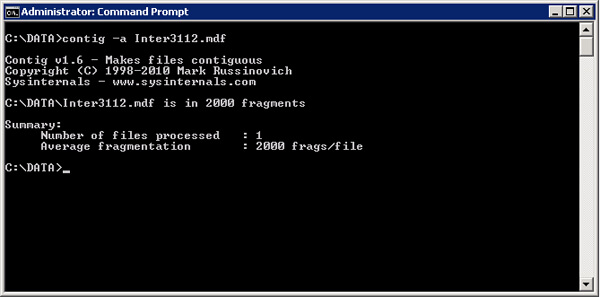
现在,为了对数据文件进行碎片整理,我们需要使数据库脱机,然后运行 contig,然后将数据库恢复为联机状态。
ALTER DATABASE [Inter3112] SET OFFLINE GO
然后我们可以使用如下所示的contig [Filename]来进行碎片整理。我们可以看到命令后只有 4 个片段。
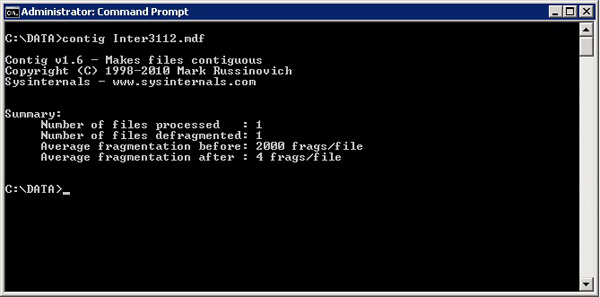
ALTER DATABASE [Inter3112] SET ONLINE GO
检查文件碎片的影响
测试的工作负载是一个简单的DBCC CHECKTABLE。
DBCC CHECKTABLE ('inter3112.dbo.invoice')
GO
借助超出本技巧范围的sys.dm_io_virtual_file_stats DMV,我们可以看到用户等待文件 I/O 完成的总时间(以毫秒为单位)( io_stall列)。
我在 tempdb 中创建了一个表,以便存储sys.dm_io_virtual_file_stats的结果,这是脚本。
CREATE TABLE tempdb..file_stats
(
Row_ID INT IDENTITY (1, 1) ,
sample_ms INT,
num_of_reads BIGINT,
num_of_bytes_read BIGINT,
io_stall_read_ms BIGINT,
num_of_writes BIGINT,
num_of_bytes_written BIGINT,
io_stall_write_ms BIGINT,
io_stall BIGINT,
size_on_disk_bytes BIGINT,
CONSTRAINT Row_ID_PK PRIMARY KEY (Row_ID)
)
INSERT INTO tempdb..file_stats
SELECT sample_ms,
num_of_reads,
num_of_bytes_read,
io_stall_read_ms,
num_of_writes,
num_of_bytes_written,
io_stall_write_ms,
io_stall,
size_on_disk_bytes
FROM sys.dm_io_virtual_file_stats (DB_ID ('inter3112'), 1)
GO
下图中的第 2 行和第 4 行表示文件碎片整理前后DBCC CHECKTABLE的执行情况。如您所见,碎片整理后 io_stall 值从 2415ms 下降到 1344ms,下降了约 1100ms。

结论
在开始对数据库文件进行碎片整理之前,您必须了解适合您的环境的最佳方法是什么,并记住碎片整理是 I/O 密集型工作。此外,这对于较小的数据库文件来说更容易做到,因为不需要那么多的连续磁盘空间,而对于较大的数据库来说则更困难。
后续
- 了解碎片原因SQL Server 碎片的原因(第 3 部分,共 9 部分)
- 检查如何避免碎片SQL Server 碎片如何避免(第 4 部分,共 9 部分)
- 创建 I/O 性能快照创建 IO 性能快照以查找 SQL Server 性能问题
- 识别 I/O 瓶颈如何识别 MS SQL Server 中的 IO 瓶颈
- 管理逻辑数据库碎片管理 SQL Server 数据库碎片
- 阅读此技巧并确定自动增长是否适合您SQL Server 中的自动增长、自动收缩和物理文件碎片