Deutch, Daniel, et al. "T-REx: Table repair explanations." Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.
摘要:数据修复是当今许多框架中关键的一步,因为应用程序可能使用来自不同来源和不同可信度级别的数据。因此,这一步一直是许多人关注的焦点工作提出许多不同的方法。为了帮助用户了解这样的数据修复算法的输出,我们提出了T-REx一个系统,通过Shapley值提供数据修复解释。该系统是通用的,并不特定于给定的修复算法或方法:它将算法视为黑盒。给定由用户选择的特定表格单元格,T-REx采用Shapley值来解释每个约束和每个表格单元格在修复感兴趣的单元格中的重要性。然后,T-REx根据约束和表格单元在修复该单元中的重要性对约束和表格单元进行排序。此解释允许用户理解修复过程,以及基于此知识采取行动,以修改影响最大的约束或原始数据库。
Deutch, Daniel, et al. "Explanations for data repair through shapley values." Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
数据修复,即识别和修复数据中的错误是数据科学周期的核心组成部分。大量的研究工作已经致力于自动化的修复过程。然而,它仍然需要数据科学家大量的手工劳动,调整和优化修复模块(根据调查,高达80%的时间)。
为此,我们在本文中提出了一个新的框架,用于解释任何数据修复模块的结果。解释涉及到识别对过程有最大影响的表单元格和数据库约束。反过来,通过Shapley值的博弈论概念来量化影响,Shapley值通常用于解释机器学习分类器结果。主要的技术挑战是Shapley值的精确计算导致指数时间。因此,我们设计和优化新的近似算法,并从理论和经验上分析它们。我们的研究结果表明,我们的方法的效率相比,适应现有的Shapley值计算技术的数据修复设置的替代方案。
研究目的与问题定义
Shapley值的概念最初是在博弈论的背景下提出的,作为量化合作博弈中每个参与者贡献的一种度量。它后来被机器学习(ML)领域采用,作为评估模型中每个特征贡献的工具[4]。给定修复的单元,T-REx计算并呈现已经影响该修复的DC和表单元的Shapley值。本文的方法直接评估输入的贡献,而不是由特定算法使用的隐藏特征的贡献。这允许系统的解决方案将修复算法视为黑盒,并且仅查询它以计算DC和细胞的Shapley值。 对DC对修复的影响的解释可以帮助用户校正它们并使它们适应特定数据和修复算法,而关于数据单元的影响的解释可以帮助理解修复算法本身并改变特定单元以使修复更准确 。
以下图为例是一组否定依赖的例子,否定依赖最左侧就是在这个修复下各个约束的shapley值。

对应的数据表如下图所示:
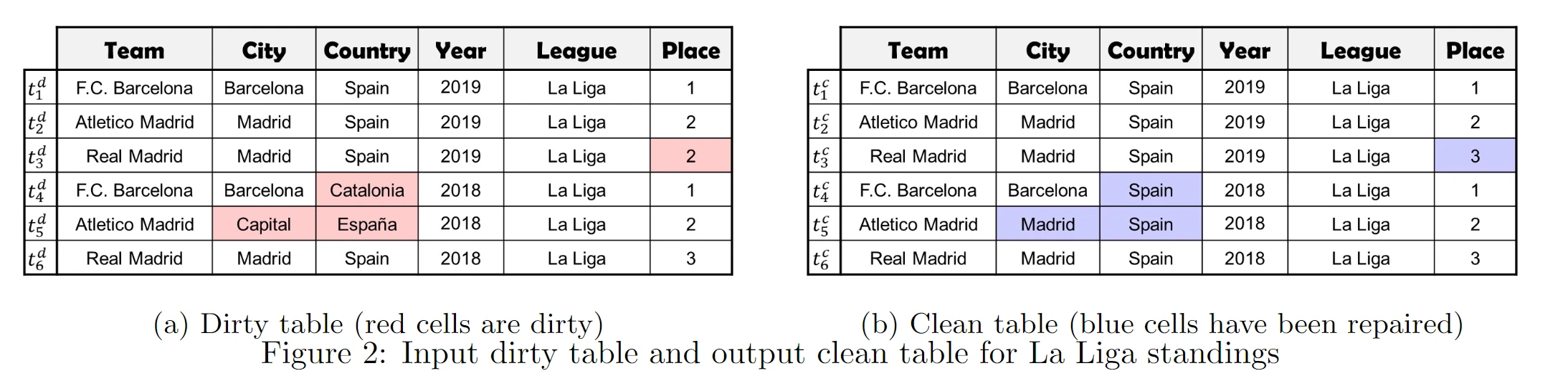
示例的一个简单的处理算法如下图所示,思路就是分别对每个否定依赖进行修复,修复的值用不违法该约束下最频繁的属性值替代。

下面对Shapley 值(下面可能称作贡献值)计算方法进行说明:
1.对约束贡献值进行分析
- 考虑第五行中的 "Country" 单元格,用 t5[Country] 表示。为了简化问题,假设我们有一个名为 "Algorithm 1" 的朴素(简单)修复算法。T-REx 计算了每个数据约束(DC,可能是"Data Constraint"的缩写)的贡献并按照贡献进行了排名,其中 C3 是最具影响力的数据约束。C3 的贡献最大,因为在其他三个元组中,"League" 属性的值为 'La Liga',并且与 "Country" 属性的值 'Spain' 相对应。C1 和 C2 各自的贡献相等,因为首先 C1 导致了 "Capital" 属性的值从原来的值变为 'Madrid',然后 C2 导致了 "Country" 单元格的值发生了变化。C4 在修复中没有参与,因此它的贡献为 0。
- 总之,"Algorithm 1" 的简单修复算法被用来修复第五行中的 "Country" 单元格。通过计算每个数据约束的贡献,并将其进行排名,T-REx(可能是一个算法或工具)确定了各个数据约束对修复的影响。在此情景中,C3 对修复的影响最大,C1 和 C2 的影响相等,而 C4 并未参与修复。
2.对单元格贡献值进行分析
- 在给定 "Algorithm 1" 的情况下,注意到 t1[P lace] 的值对 t5[Country] 的修改没有影响 — 因为 t1 与 t5 没有冲突,并且在 "Algorithm 1" 中,属性 P lace 对 Country 没有影响。然而,我们如何确定相对于 t6[City] 来说,t5[League] 对修复的影响是更大还是更小的呢?直观地说,t5[League] 比 t6[City] 更具影响力。这是因为如果 t5[League] 具有不同的值,那么根据 C3,元组 t5 就不会有任何冲突。而如果 t6[City] 具有不同的值,那么根据 C1,在 t3 和 t6 之间将会存在冲突,这将会被 "Algorithm 1" 修复。因此,T-REx 将会比较 t5[League] 和 t6[City],将更高的贡献分配给 t5[League]。
- 总之,通过比较不同数据元素对约束的违规情况,可以判断它们在修复中的相对影响力。在这个特定情景中,t5[League] 对修复的影响被认为比 t6[City] 更大,因为 t5[League] 的值在满足 C3 时可以消除冲突,而 t6[City] 的值在满足 C1 时可以解决冲突。
总结
T-REx 接受算法本身和其输入作为输入,该输入包括一组数据约束(DCs,可能是 "Data Constraints" 的缩写)和一个脏数据数据库表。 该系统的另一个输入是一个特定感兴趣的表格单元格,其修复需要解释。系统随后根据这个感兴趣的单元格的 Shapley 值,对影响力较大的数据约束和表格单元格进行排名。通常情况下,计算 Shapley 值与数据约束/表格单元格数量呈指数关系,因此 T-REx 使用不同的算法来计算数据约束的 Shapley 值以及表格单元格的 Shapley 值。对于数据约束,朴素的方法是可行的,因为数据约束的数量通常较小。相反,表格中的单元格数量可能非常大,因此 T-REx 使用基于 [7] 的采样算法。为了计算 Shapley 值,该系统会反复更改修复算法的输入并查询它,因此不依赖于特定算法的组件或方法。
[7] E. Strumbelj and I. Kononenko. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst., 41(3):647–665, 2014.
总之,T-REx 是一个系统,用于解释和排名对特定表格单元格的修复影响,并使用 Shapley 值来衡量影响的大小。系统使用不同的算法来计算数据约束和表格单元格的 Shapley 值,以适应不同的约束和单元格数量。它通过多次改变修复算法的输入并进行查询来计算 Shapley 值,以获得影响排名。
方法与实施方案
- T-REx基于Shapley值为数据修复解释提供了一个新颖的系统。Shapley值最初是在合作博弈论的背景下提出的,作为量化合作博弈中每个玩家贡献的一种方法。它后来被机器学习社区采用,作为评估模型中每个特征贡献的工具。给定一个已修复的单元格,T-REx计算并呈现已影响此修复的DCs和表格单元格的Shapley值。[Page 1]
- T-REx的输入是修复算法本身及其输入,即一组DCs和一个脏数据库表。系统然后根据它们对感兴趣的单元格的Shapley值对影响DCs和表格单元格进行排序。
- T-REx的实现使用Python 3.6和底层的PostgreSQL 10.6数据库引擎。其基于Web的GUI使用JavaScript、CSS和HTML构建。
Shapley值:
在合作博弈论中,Shapley值是一种分配每个玩家的贡献的方法,假设他们合作。设 (?) 是玩家的有限集合,而 (?: 2^? → ℝ) 是一个特征函数,其中 (?(∅) = 0)。这个函数将玩家的集合映射到他们根据游戏生成的联合价值。玩家 (?) 对联盟 (?) 的贡献由于 (?) 的加入而导致 (?) 的变化来定义,即 (?(? ∪ {?}) - ?(?))。玩家 (?) 的Shapley值是这种贡献在可以形成的不同排列中的平均值。
直观地说,对于任何玩家 (?),这个值是 (?) 对任何可能的联盟中 (?) 的变化的贡献的总和,由联盟的大小加权,这样中等大小的联盟(存在更多的这样的联盟)的贡献会更低。
公式:
$$
\phi_?(?, ?, ?) = \sum_{?⊆?∖{?}} \frac{|?|!(|?|-|?|-1)!}{|?|!} (?(? ∪ {?}) - ?(?))
$$
伪代码:

使用Shapley值,我们可以计算每个单元格对错误值的修复贡献。
实验设置
- 使用的数据集:用户研究使用了两个数据集:
- Hospital:该数据集有 21K 个单元和 19 个拒绝约束 (DC)。
- MAS:这个数据集更大,有 2M 个单元和 11 个 DC。
- 参与者:该研究涉及 20 位用户。所有参与者都获得了每个问题修复过程中使用的数据库和约束。他们还了解了该研究、相关符号和所使用的数据集。用户分为两组:
- 一组可以访问T-Rex的输出。
- 另一组无法访问T-Rex的输出。
本文展示了 T-Rex 的一个测试,重点关注用户研究中的Q4 和Q5。此用例演示了 T-Rex 如何快速查明 MAS 数据集中的问题。考虑了具有大约 2M 个单元和一组 11 个函数依赖性的 MAS 数据库实例。Q1-Q5如下:
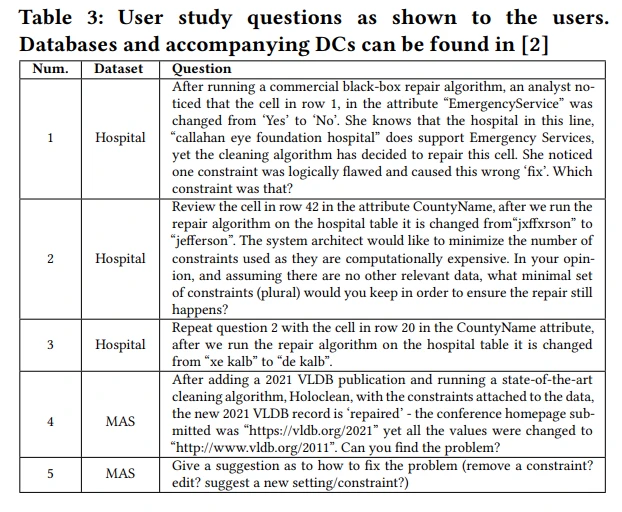
结果:
-
T-Rex可用性:
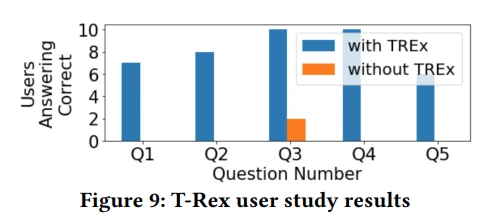
- 结果凸显了T-Rex解释的优势。例如,在问题 Q3 中,所有 10 位有权访问 T-Rex 的用户都回答正确,而只有 2 位没有访问权限的用户回答正确。
- 无法访问 T-Rex 的用户无法回答 Q1、Q2、Q4、Q5。相比之下,至少有 7 位有权访问 T-Rex 的用户可以回答这些问题。
- 所有有权访问 T-Rex 的用户都正确回答了问题 4,而所有没有访问权限的用户都未能回答问题。
- 对于Q5,60%的 T-Rex 用户建议了正确的修复方案,2 人提供了部分修复方案。
- 该研究展示了用户如何使用 T-Rex 轻松识别修复过程中的错误并实现更好的修复。
-
结果:
-
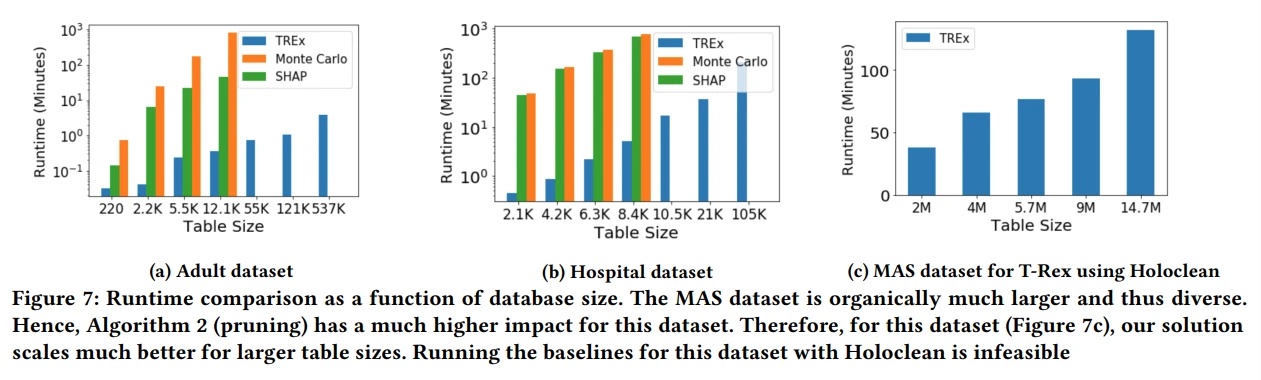
比较了不同数据集的运行时间与数据库大小的函数关系。它表明 T-Rex 对于较大的表大小可以更好地扩展,特别是对于 MAS 数据集。
-
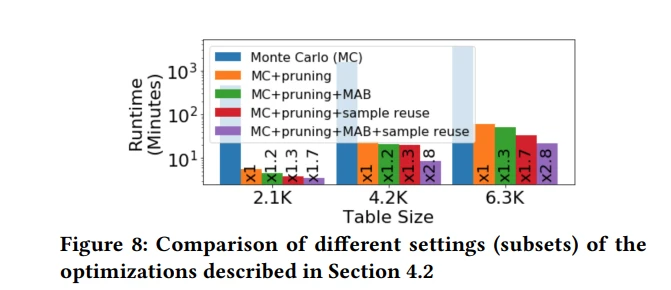
比较了文章中描述的优化的不同设置。
-
显示了 T-Rex 用户研究的结果
-
总体而言,实验结果强调了 T-Rex 系统在为数据修复过程提供解释方面的实用性和效率。用户研究结果特别强调了该系统在帮助用户理解和改进维修过程方面的有效性。
心得启发
1.通过Shapley值解释修复有助于理解修复过程,并且通过计算shapley的值,可以判断约束和单元格对修复的贡献情况,这种方法对数据清洗重要性采样很有帮助。
2.在交互式系统中,可以通过把单元贡献度和约束贡献度给用户参考,达到交互式清洗的目的。