梯度消失和梯度爆炸
2 神经网络梯度消失与梯度爆炸
2.1 简介梯度消失与梯度爆炸
层数比较多的神经网络模型在训练的时候会出现梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
例如,对于图1所示的含有3个隐藏层的神经网络,
梯度消失问题发生时,靠近输出层的 hidden layer 3 的权值更新相对正常,但是靠近输入层的 hidden layer1 的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,仍接近于初始化的权值。这就导致hidden layer 1 相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习。
梯度爆炸的情况是:当初始的权值过大,靠近输入层的 hidden layer 1 的权值变化比靠近输出层的 hidden layer 3 的权值变化更快,就会引起梯度爆炸的问题。

2.2 梯度不稳定问题
在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中梯度或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。
梯度不稳定的原因:前面层(左侧)上的梯度是来自后面层(右侧)上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
2.3 产生梯度消失的根本原因
我们以图2的反向传播为例,假设每一层只有一个神经元且对于每一层都可以用公式1表示,其中σ为sigmoid函数,C表示的是代价函数,前一层的输出和后一层的输入关系如公式1所示。我们可以推导出公式2。



∂y4/∂z4=σ‘(z4)
而sigmoid函数的导数 如图3右图所示。
如图3右图所示。

图3
可见,的最大值为1/4,而我们一般会使用标准方法来初始化网络权重,即使用一个均值为0标准差为1的高斯分布。因此,初始化的网络权值ω通常(大部分)都小于1,从而有
 。对于2式的链式求导,层数越多,求导结果越小,最终导致梯度消失的情况出现。
。对于2式的链式求导,层数越多,求导结果越小,最终导致梯度消失的情况出现。

对于图4, 和
和 有共同的求导项。可以看出,前面(左侧)的网络层比后面(右侧)的网络层梯度变化更小,故权值变化缓慢,从而引起了梯度消失问题。
有共同的求导项。可以看出,前面(左侧)的网络层比后面(右侧)的网络层梯度变化更小,故权值变化缓慢,从而引起了梯度消失问题。
2.4 产生梯度爆炸的根本原因
当 ,也就是w比较大的情况。则前面(左侧)的网络层比后面(右侧)的网络层梯度变化更快,引起了梯度爆炸的问题。
,也就是w比较大的情况。则前面(左侧)的网络层比后面(右侧)的网络层梯度变化更快,引起了梯度爆炸的问题。
2.5 当激活函数为sigmoid时,梯度消失和梯度爆炸哪个更容易发生?
结论:梯度爆炸问题在使用sigmoid激活函数时,出现的情况较少,不容易发生。
量化分析梯度爆炸时x的取值范围:因导数最大为0.25,故|w|>4, 才可能出现;按照
才可能出现;按照 可计算出x的数值变化范围很窄,仅在公式3范围内,才会出现梯度爆炸。画图如5所示,可见x的数值变化范围很小;最大数值范围也仅仅0.45,当|w|=6.9时出现。因此仅仅在此很窄的范围内会出现梯度爆炸的问题。
可计算出x的数值变化范围很窄,仅在公式3范围内,才会出现梯度爆炸。画图如5所示,可见x的数值变化范围很小;最大数值范围也仅仅0.45,当|w|=6.9时出现。因此仅仅在此很窄的范围内会出现梯度爆炸的问题。


2.6 如何解决梯度消失和梯度爆炸
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
1. 用 ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout 等替代 sigmoid 函数。
ReLU:让激活函数的导数为1(缺点:由于负数部分恒为0,会导致一些神经元无法激活,可通过设置小学习率部分解决)。
LeakyReLU:包含了ReLU的几乎所有优点,同时解决了ReLU中0区间带来的影响。
ELU:和LeakyReLU一样,都是为了解决0区间问题,相对于来,ELU计算更耗时一些
2. 用 Batch Normalization。
BatchNorm是对每一层的输出做scale和shift的方法。通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到接近均值为0方差为1的标准正态分布。
防止梯度消失原理:正则化后的输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,使得让梯度变大,避免梯度消失问题产生。
防止梯度爆炸原理:正则化后的输入值所在区域的梯度小于1。
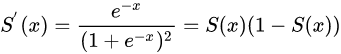
注:而且使用BN层后可以增加学习率,进而大大加快训练速度。
3. 残差结构与LSTM可以有效防止梯度消失
二者的原理类似,以残差网络为例,残差中有很多跨层连接结构,如下图所示:
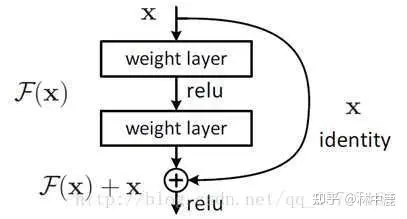
这样的结构在反向传播中具有很大的好处,见下式:
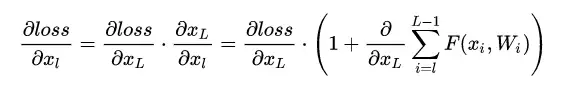
小括号中的1表明shortcut可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。
4 合适的初始化方式
无法完全解决,但可以有效缓解该问题。
https://zhuanlan.zhihu.com/p/356915267
如何发现梯度消失和梯度爆炸
直接方法:可以通过tensorboard可视化每层的梯度分布。
间接方法:可以分析顶层网络输出数据分布,如果数据分布方差变得特别大,那么梯度爆炸;变得非常小,则梯度消失。
原文链接:https://blog.csdn.net/weixin_39910711/article/details/114849349
========================================
https://zhuanlan.zhihu.com/p/483651927
以4个单个神经元进行串联形成的MLP为例,下图是其神经网络的结构:

其解析式可以分别写为:

根据链式法则,我们可以求得初始层对于最后损失函数的梯度为:



当激活函数使用sigmoid时,其导数为:

因此其导数存在为[0, 0.25] 区间内。则:
当参数初始化(或者更新到)小于1时,初始层对损失函数的梯度远小于 1/256。(梯度消失)
当参数初始化(这个更新到)较大的时候,浅层的累乘会导致梯度数值变得很大。(梯度爆炸)
总的来说,梯度消失和梯度爆炸的本质是一样的,即源于反向传播中梯度的累乘影响,从而导致了浅层网络的参数发生了变化微弱或者震荡较大的问题。
- 当梯度消失发生时,最后一个隐层梯度更新基本正常,但是越往前的隐层内更新越慢,甚至有可能会出现停滞,此时,多层深度神经网络可能会退化为浅层的神经网络(只有后面几层在学习),因为浅层基本没有学习,对输入仅仅做了一个映射而已。
- 当梯度爆炸发生时,最后一个隐层梯度同样更新正常,但是向前传播的梯度累计过程中,浅层网络可能会产生剧烈的波动,从而导致训练下来的特征分布变化很大,同时输入的特征分布可能与震荡幅度不同,从而导致最后的损失存在极大的偏差。
梯度消失和梯度爆炸本质上是一样的,均因为网络层数太深而引发的梯度反向传播中的连乘效应。
1、技术性方案:
1.1 激活函数:
激活函数的主要功能是在神经网络计算中引入非线性计算来强化网络对非线性的泛化性。Sigmoid在这个功能上很好的进行了应用,但同样也存在之前例子中的问题,即梯度累乘所导致的梯度缩减。为了避免这种情况,我们可以更换激活函数,来削减反向传播时候的梯度累加。
ReLU以及这个系列的激活函数其实就应对了这个问题,在反向传播时,激活函数的导数为0或1,这就避免了激活值在传输过程中的梯度累积问题。当然,后续的变体中也解决了0点不可导(elu),负数没有激活值(leakyRelu)等一系列的问题。
总的来说,ReLU作用可以从两个方面来解析:正向保留激活值、反向统一化梯度。
1.2 Normalization
Normalization的提出是为了解决神经网络中的ICS问题,在这里同样也是利用规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到接近均值为0方差为1的标准正太分布,即严重偏离的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,使得让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
详见 深度学习知识点——规范化(Normalization)和Dropout
1.3 残差链接
从正向来看,残差连接将浅层特征共享到深层网络中,有利于整体神经网络特征的稳定性;从反向来看,引入深层反向的短梯度,有效地保留了更新的效果(避免梯度消失。)
1.4 记忆式结构
记忆式结构常见于RNN中的LSTM网络中,通过其中的门结构(记忆门,遗忘门)来整合序列分析过程中的信息,同样来达到稳固信息的功能。
1.5 梯度裁剪:
针对梯度爆炸,梯度裁剪设置一个梯度剪切阈值,将梯度强制限制在范围内。如果更新梯度时,梯度超过了这个阈值,则利用上界将梯度限制在正常范围内。torch中的梯度裁剪源码如下所示:
def clip_grad_norm_(parameters: _tensor_or_tensors, max_norm: float, norm_type: float = 2.0) -> torch.Tensor:
r"""Clips gradient norm of an iterable of parameters.
The norm is computed over all gradients together, as if they were
concatenated into a single vector. Gradients are modified in-place.
Args:
parameters (Iterable[Tensor] or Tensor): an iterable of Tensors or a
single Tensor that will have gradients normalized
max_norm (float or int): max norm of the gradients
norm_type (float or int): type of the used p-norm. Can be ``'inf'`` for
infinity norm.
Returns:
Total norm of the parameters (viewed as a single vector).
"""
if isinstance(parameters, torch.Tensor):
parameters = [parameters]
parameters = [p for p in parameters if p.grad is not None]
max_norm = float(max_norm)
norm_type = float(norm_type)
if len(parameters) == 0:
return torch.tensor(0.)
device = parameters[0].grad.device
if norm_type == inf:
total_norm = max(p.grad.detach().abs().max().to(device) for p in parameters)
else:
total_norm = torch.norm(torch.stack([torch.norm(p.grad.detach(), norm_type).to(device) for p in parameters]), norm_type)
clip_coef = max_norm / (total_norm + 1e-6)
if clip_coef < 1:
for p in parameters:
p.grad.detach().mul_(clip_coef.to(p.grad.device))
return total_norm1.6 正则化:
在这里的正则化指的是权重正则化,即在损失函数中加入网络参数权重的惩罚项。当梯度爆炸发生时,惩罚项(通常是L1范数或L2范数)的值会变得很大,从而抑制(或者反向)参数的更新强度(或者方向),以此来抑制惩罚项(也可以说是正则化项)的大小,从而在一定程度上限制梯度爆炸的发生。
权重衰减也是一种有效地正则化方法,即在每次参数更新的时候,引入一个衰减参数。类比Adam,在梯度上我们可以使用自适应的学习率来进行梯度矫正,而在原始参数上,我们对原始参数进行衰减,从而达到正则化参数的效果,更新方程为:
2、策略性方案:
2.1 逐层训练
即boosting的实现思想,通过单层单层的训练来达到不考虑梯度累计(纵向累计)的效果。
2.2 预训练加微调
广义思想采用合理的权重初始化方法,在正常范围内进行训练,以此来避免梯度异常的问题。
https://zhuanlan.zhihu.com/p/483651927
=========================================
https://zhuanlan.zhihu.com/p/516698105
目前优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。这样做是有一定原因的,首先,深层网络由许多非线性层堆叠而来,每一层非线性层都可以视为是一个非线性函数 f(x)(非线性来自于非线性激活函数),因此整个深度网络可以视为是一个复合的非线性多元函数 :
我们最终的目的是希望这个多元函数可以很好的完成输入到输出之间的映射。
梯度消失与梯度爆炸其实是一种情况。例如,下图以三个隐层的单神经元网络为例:

以上图为例,假设每一层网络激活后的输出为
,其中 i 为第i 层,x 代表第i 层的输入,也就是第 i−1 层的输出,f 是激活函数,那么,可得出
BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为 w←w+Δw,给定学习率 α,得出
。如果要更新第二隐藏层的权值信息,根据链式求导法则,更新梯度信息:
即对激活函数求导后与权重相乘。如果激活函数求导后与权重相乘的积大于1,那么层数增多的时候,最终的求出的梯度更新信息将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
=========================================
https://zhuanlan.zhihu.com/p/268007336
https://www.cnblogs.com/mengnan/p/9480804.html
https://blog.csdn.net/qq_25737169/article/details/78847691
https://baike.baidu.com/item/%E6%A2%AF%E5%BA%A6%E6%B6%88%E5%A4%B1%E9%97%AE%E9%A2%98/22761355?fr=aladdin