9.4-1-海量数据下的EFK架构优化升级(1)
一、数据背景
在海量数据场景下,日志管理和分析是一项重要任务。为了解决这个问题,EFK 架构(Elasticsearch + Fluentd + Kibana)已经成为流行的选择。
然而,随着数据规模的增加,传统的 EFK 架构可能面临性能瓶颈和可用性挑战。为了提升架构的性能和可伸缩性,我们可以结合 Kafka 和 Logstash 对 EFK 架构进行优化升级。
首先,引入 Kafka 作为高吞吐量的消息队列是关键的一步。Kafka 可以接收和缓冲大量的日志数据,减轻 Elasticsearch 的压力,并提供更好的可用性和容错性。
然后,我们可以使用 Fluentd 或 Logstash 将日志数据发送到 Kafka 中。将 Kafka 视为中间件层,用于处理日志数据流。这样可以解耦 Fluentd 或 Logstash 和 Elasticsearch之间的直接连接,提高整体的可靠性和灵活性。
通过 Logstash 的 Kafka 插件,我们可以将 Kafka 中的数据消费到 Logstash 中进行处理和转发。这样 Logstash 就负责从 Kafka 中获取数据,然后根据需要进行过滤、解析和转换,最终将数据发送到 Elasticsearch 进行存储和索引。
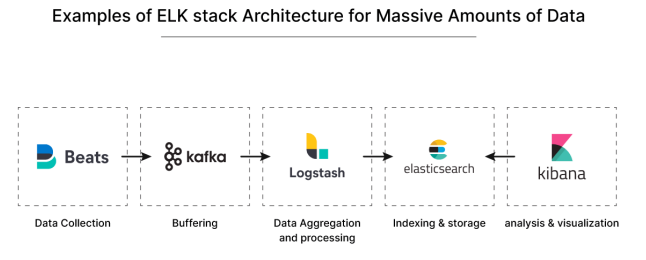
二、KAFKA部署配置
首先在 Kubernetes 集群中安装 Kafka,同样这里使用 Helm 进行安装:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update首先使用 helm pull 拉取 Chart 并解压:
[root@master-1-230 9.4]# helm pull bitnami/kafka --untar --version 17.2.3
[root@master-1-230 9.4]# cd kafka/
[root@master-1-230 kafka]# ll
总用量 204
-rw-r--r-- 1 root root 304 12月 31 18:43 Chart.lock
drwxr-xr-x 4 root root 37 12月 31 18:43 charts
-rw-r--r-- 1 root root 917 12月 31 18:43 Chart.yaml
-rw-r--r-- 1 root root 117638 12月 31 18:43 README.md
drwxr-xr-x 2 root root 4096 12月 31 18:43 templates
-rw-r--r-- 1 root root 74719 12月 31 18:43 values.yaml这里面我们指定使用一个 StorageClass 来提供持久化存储,在 Chart 目录下面创建用于安装的 values 文件:
cat values.yaml |egrep -v "#|^$"
[root@master-1-230 kafka]# cat values.yaml |egrep -v "#|^$"
global:
imageRegistry: ""
imagePullSecrets: []
storageClass: "nfs-storageclass"
kubeVersion: ""
nameOverride: ""
fullnameOverride: ""
clusterDomain: cluster.local
commonLabels: {}
commonAnnotations: {}
extraDeploy: []
diagnosticMode:
enabled: false
command:
- sleep
args:
- infinity
image:
registry: docker.io
repository: bitnami/kafka
tag: 3.2.0-debian-10-r4
pullPolicy: IfNotPresent
pullSecrets: []
debug: false
config: ""
existingConfigmap: ""
log4j: ""
existingLog4jConfigMap: ""
heapOpts: -Xmx1024m -Xms1024m
deleteTopicEnable: false
autoCreateTopicsEnable: true
logFlushIntervalMessages: _10000
logFlushIntervalMs: 1000
logRetentionBytes: _1073741824
logRetentionCheckIntervalMs: 300000
logRetentionHours: 168
logSegmentBytes: _1073741824
logsDirs: /bitnami/kafka/data
maxMessageBytes: _1000012
defaultReplicationFactor: 1
offsetsTopicReplicationFactor: 1
transactionStateLogReplicationFactor: 1
transactionStateLogMinIsr: 1
numIoThreads: 8
numNetworkThreads: 3
numPartitions: 1
numRecoveryThreadsPerDataDir: 1
socketReceiveBufferBytes: 102400
socketRequestMaxBytes: _104857600
socketSendBufferBytes: 102400
zookeeperConnectionTimeoutMs: 6000
zookeeperChrootPath: ""
authorizerClassName: ""
allowEveryoneIfNoAclFound: true
superUsers: User:admin
auth:
clientProtocol: plaintext
externalClientProtocol: ""
interBrokerProtocol: plaintext
sasl:
mechanisms: plain,scram-sha-256,scram-sha-512
interBrokerMechanism: plain
jaas:
clientUsers:
- user
clientPasswords: []
interBrokerUser: admin
interBrokerPassword: ""
zookeeperUser: ""
zookeeperPassword: ""
existingSecret: ""
tls:
type: jks
pemChainIncluded: false
existingSecrets: []
autoGenerated: false
password: ""
existingSecret: ""
jksTruststoreSecret: ""
jksKeystoreSAN: ""
jksTruststore: ""
endpointIdentificationAlgorithm: https
zookeeper:
tls:
enabled: false
type: jks
verifyHostname: true
existingSecret: ""
existingSecretKeystoreKey: zookeeper.keystore.jks
existingSecretTruststoreKey: zookeeper.truststore.jks
passwordsSecret: ""
passwordsSecretKeystoreKey: keystore-password
passwordsSecretTruststoreKey: truststore-password
listeners: []
advertisedListeners: []
listenerSecurityProtocolMap: ""
allowPlaintextListener: true
interBrokerListenerName: INTERNAL
command:
- /scripts/setup.sh
args: []
extraEnvVars: []
extraEnvVarsCM: ""
extraEnvVarsSecret: ""
replicaCount: 1
minBrokerId: 0
containerPorts:
client: 9092
internal: 9093
external: 9094
livenessProbe:
enabled: true
initialDelaySeconds: 10
timeoutSeconds: 5
failureThreshold: 3
periodSeconds: 10
successThreshold: 1
readinessProbe:
enabled: true
initialDelaySeconds: 5
failureThreshold: 6
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
startupProbe:
enabled: false
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 1
failureThreshold: 15
successThreshold: 1
customLivenessProbe: {}
customReadinessProbe: {}
customStartupProbe: {}
lifecycleHooks: {}
resources:
limits: {}
requests: {}
podSecurityContext:
enabled: true
fsGroup: 1001
containerSecurityContext:
enabled: true
runAsUser: 1001
runAsNonRoot: true
hostAliases: []
hostNetwork: false
hostIPC: false
podLabels: {}
podAnnotations: {}
podAffinityPreset: ""
podAntiAffinityPreset: soft
nodeAffinityPreset:
type: ""
key: ""
values: []
affinity: {}
nodeSelector: {}
tolerations: []
topologySpreadConstraints: {}
terminationGracePeriodSeconds: ""
podManagementPolicy: Parallel
priorityClassName: ""
schedulerName: ""
updateStrategy:
type: RollingUpdate
rollingUpdate: {}
extraVolumes: []
extraVolumeMounts: []
sidecars: []
initContainers: []
pdb:
create: false
minAvailable: ""
maxUnavailable: 1
service:
type: ClusterIP
ports:
client: 9092
internal: 9093
external: 9094
nodePorts:
client: ""
external: ""
sessionAffinity: None
sessionAffinityConfig: {}
clusterIP: ""
loadBalancerIP: ""
loadBalancerSourceRanges: []
externalTrafficPolicy: Cluster
annotations: {}
headless:
annotations: {}
labels: {}
extraPorts: []
externalAccess:
enabled: false
autoDiscovery:
enabled: false
image:
registry: docker.io
repository: bitnami/kubectl
tag: 1.24.0-debian-10-r5
pullPolicy: IfNotPresent
pullSecrets: []
resources:
limits: {}
requests: {}
service:
type: LoadBalancer
ports:
external: 9094
loadBalancerIPs: []
loadBalancerNames: []
loadBalancerAnnotations: []
loadBalancerSourceRanges: []
nodePorts: []
useHostIPs: false
usePodIPs: false
domain: ""
annotations: {}
extraPorts: []
networkPolicy:
enabled: false
allowExternal: true
explicitNamespacesSelector: {}
externalAccess:
from: []
egressRules:
customRules: []
persistence:
enabled: true
existingClaim: ""
storageClass: "nfs-storageclass"
accessModes:
- ReadWriteOnce
size: 28Gi
annotations: {}
selector: {}
mountPath: /bitnami/kafka
logPersistence:
enabled: false
existingClaim: ""
storageClass: ""
accessModes:
- ReadWriteOnce
size: 8Gi
annotations: {}
selector: {}
mountPath: /opt/bitnami/kafka/logs
volumePermissions:
enabled: false
image:
registry: docker.io
repository: bitnami/bitnami-shell
tag: 10-debian-10-r434
pullPolicy: IfNotPresent
pullSecrets: []
resources:
limits: {}
requests: {}
containerSecurityContext:
runAsUser: 0
serviceAccount:
create: true
name: ""
automountServiceAccountToken: true
annotations: {}
rbac:
create: false
metrics:
kafka:
enabled: false
image:
registry: docker.io
repository: bitnami/kafka-exporter
tag: 1.4.2-debian-10-r243
pullPolicy: IfNotPresent
pullSecrets: []
certificatesSecret: ""
tlsCert: cert-file
tlsKey: key-file
tlsCaSecret: ""
tlsCaCert: ca-file
extraFlags: {}
command: []
args: []
containerPorts:
metrics: 9308
resources:
limits: {}
requests: {}
podSecurityContext:
enabled: true
fsGroup: 1001
containerSecurityContext:
enabled: true
runAsUser: 1001
runAsNonRoot: true
hostAliases: []
podLabels: {}
podAnnotations: {}
podAffinityPreset: ""
podAntiAffinityPreset: soft
nodeAffinityPreset:
type: ""
key: ""
values: []
affinity: {}
nodeSelector: {}
tolerations: []
schedulerName: ""
priorityClassName: ""
topologySpreadConstraints: []
extraVolumes: []
extraVolumeMounts: []
sidecars: []
initContainers: []
service:
ports:
metrics: 9308
clusterIP: ""
sessionAffinity: None
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "{{ .Values.metrics.kafka.service.ports.metrics }}"
prometheus.io/path: "/metrics"
serviceAccount:
create: true
name: ""
automountServiceAccountToken: true
jmx:
enabled: false
image:
registry: docker.io
repository: bitnami/jmx-exporter
tag: 0.16.1-debian-10-r306
pullPolicy: IfNotPresent
pullSecrets: []
containerSecurityContext:
enabled: true
runAsUser: 1001
runAsNonRoot: true
containerPorts:
metrics: 5556
resources:
limits: {}
requests: {}
service:
ports:
metrics: 5556
clusterIP: ""
sessionAffinity: None
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "{{ .Values.metrics.jmx.service.ports.metrics }}"
prometheus.io/path: "/"
whitelistObjectNames:
- kafka.controller:*
- kafka.server:*
- java.lang:*
- kafka.network:*
- kafka.log:*
config: |-
jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:5555/jmxrmi
lowercaseOutputName: true
lowercaseOutputLabelNames: true
ssl: false
{{- if .Values.metrics.jmx.whitelistObjectNames }}
whitelistObjectNames: ["{{ join "\",\"" .Values.metrics.jmx.whitelistObjectNames }}"]
{{- end }}
existingConfigmap: ""
serviceMonitor:
enabled: false
namespace: ""
interval: ""
scrapeTimeout: ""
labels: {}
selector: {}
relabelings: []
metricRelabelings: []
honorLabels: false
jobLabel: ""
provisioning:
enabled: false
numPartitions: 1
replicationFactor: 1
topics: []
tolerations: []
extraProvisioningCommands: []
parallel: 1
preScript: ""
postScript: ""
auth:
tls:
type: jks
certificatesSecret: ""
cert: tls.crt
key: tls.key
caCert: ca.crt
keystore: keystore.jks
truststore: truststore.jks
passwordsSecret: ""
keyPasswordSecretKey: key-password
keystorePasswordSecretKey: keystore-password
truststorePasswordSecretKey: truststore-password
keyPassword: ""
keystorePassword: ""
truststorePassword: ""
command: []
args: []
extraEnvVars: []
extraEnvVarsCM: ""
extraEnvVarsSecret: ""
podAnnotations: {}
podLabels: {}
resources:
limits: {}
requests: {}
podSecurityContext:
enabled: true
fsGroup: 1001
containerSecurityContext:
enabled: true
runAsUser: 1001
runAsNonRoot: true
schedulerName: ""
extraVolumes: []
extraVolumeMounts: []
sidecars: []
initContainers: []
waitForKafka: true
zookeeper:
enabled: true
replicaCount: 1
auth:
enabled: false
clientUser: ""
clientPassword: ""
serverUsers: ""
serverPasswords: ""
persistence:
enabled: true
storageClass: "nfs-storageclass"
accessModes:
- ReadWriteOnce
size: 28Gi
externalZookeeper:
servers: []安装kafka
[root@master-1-230 kafka]# helm upgrade --install kafka -f values.yaml --namespace logging .
Release "kafka" does not exist. Installing it now.
NAME: kafka
LAST DEPLOYED: Sun Dec 31 18:47:49 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 17.2.3
APP VERSION: 3.2.0
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.logging.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.logging.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace logging -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.logging.svc.cluster.local:9092 \
--topic test \
--from-beginning安装完成后我们可以使用上面的提示来检查 Kafka 是否正常运行:
[root@master-1-230 9.4]# kubectl get pods -n logging -l app.kubernetes.io/instance=kafka
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 8m28s
kafka-zookeeper-0 1/1 Running 0 8m28s用下面的命令创建一个 Kafka 的测试客户端 Pod:
[root@master-1-230 ~]# kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinity
pod/kafka-client created
[root@master-1-230 ~]# kubectl get pod -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 3h24m
elasticsearch-master-1 1/1 Running 0 3h24m
elasticsearch-master-2 1/1 Running 0 3h24m
fluentd-2nqv2 1/1 Running 0 170m
fluentd-dtsgw 1/1 Running 0 170m
fluentd-tp6lk 1/1 Running 0 170m
kafka-0 1/1 Running 0 137m
kafka-client 1/1 Running 0 4s
kafka-zookeeper-0 1/1 Running 0 137m
kibana-kibana-679696bbf8-r2ck6 1/1 Running 0 3h11m然后启动一个终端进入容器内部生产消息:
# 生产者
[root@master-1-230 ~]# kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test02
>hello ,k8s yyds!
[2023-12-31 13:15:53,649] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 4 : {test02=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
>启动另外一个终端进入容器内部消费消息:
# 消费者
[root@master-1-230 ~]# kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic test02 --from-beginning
hello ,k8s yyds!如果在消费端看到了生产的消息数据证明我们的 Kafka 已经运行成功了。
9.4-2-海量数据下的EFK架构优化升级(2)
三、Fluentd 配置Kafka
现在有了 Kafka,我们就可以将 Fluentd 的日志数据输出到 Kafka 了,只需要将Fluentd 配置中的 <match> 更改为使用 Kafka 插件即可,但是在 Fluentd 中输出到Kafka,需要使用到 fluent-plugin-kafka 插件,所以需要我们自定义下 Docker 镜像,最简单的做法就是在上面 Fluentd 镜像的基础上新增 Kafka 插件即可,Dockerfile文件如下所示:
FROM quay.io/fluentd_elasticsearch/fluentd:v3.4.0
#RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" >Gemfile && gem install bundler
RUN gem sources --remove https://rubygems.org/ && gem sources -a https://mirrors.aliyun.com/rubygems/
RUN gem install fluent-plugin-kafka -v 0.17.5 --no-document编译:
[root@master-1-230 fluentd]# docker build -t harbor.ikubernetes.cloud/library/fluentd-kafka:v0.17.5
[root@master-1-230 fluentd]# docker push harbor.ikubernetes.cloud/library/fluentd-kafka:v0.17.5接下来替换 Fluentd 的 Configmap 对象中的 部分,如下所示:
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
output.conf: |-
<match **>
@id kafka
@type kafka2
@log_level info
# list of seed brokers
brokers kafka-0.kafka-headless.logging.svc.cluster.local:9092
use_event_time true
# topic settings
topic_key k8slog
default_topic messages # 注意,kafka中消费使用的是这个topic
# buffer settings
<buffer k8slog>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# producer settings
required_acks -1
compression_codec gzip
</match>[root@master-1-230 fluentd]# kubectl apply -f fluentd-configmap.yaml
configmap/fluentd-conf configured然后替换运行的Fluentd镜像
# fluentd-daemonset.yaml
image:harbor.ikubernetes.cloud/library/fluentd-kafka:v0.17.5直接更新 Fluentd 的 Configmap 与 DaemonSet 资源对象即可:
kubectl apply -f fluentd-configmap.yaml
[root@master-1-230 fluentd]# kubectl apply -f fluentd-daemonset.yaml
serviceaccount/fluentd-es unchanged
clusterrole.rbac.authorization.k8s.io/fluentd-es unchanged
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es configured
daemonset.apps/fluentd configured
[root@master-1-230 fluentd]# kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 4h57m
elasticsearch-master-1 1/1 Running 0 4h57m
elasticsearch-master-2 1/1 Running 0 4h57m
fluentd-6hh7d 1/1 Running 0 42s
fluentd-mq8p5 1/1 Running 0 30s
fluentd-wzwvw 1/1 Running 0 11s
kafka-0 1/1 Running 0 3h50m
kafka-client 1/1 Running 0 92m
kafka-zookeeper-0 1/1 Running 0 3h50m
kibana-kibana-679696bbf8-r2ck6 1/1 Running 0 4h43m更新成功后我们可以使用上面的测试 Kafka 客户端来验证是否有日志数据:
kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic messages --from-beginning
四、安装Logstash
虽然数据从 Kafka 到 Elasticsearch 的方式多种多样,比如可以使用 GitHub - confluentinc/kafka-connect-elasticsearch: Kafka Connect Elasticsearch connector来实现,我们这里还是采用更加流行的 Logstash 方案,上面我们已经将日志从 Fluentd 采集输出到 Kafka 中去了,接下来我们使用 Logstash 来连接 Kafka 与 Elasticsearch 间的日志数据。
首先使用helm pull 拉取Chart并解压
[root@master-1-230 9.4]# helm pull elastic/logstash --untar --version 7.17.3
[root@master-1-230 9.4]# cd logstash/
[root@master-1-230 logstash]# ll
总用量 48
-rw-r--r-- 1 root root 321 12月 31 22:51 Chart.yaml
drwxr-xr-x 7 root root 84 12月 31 22:51 examples
-rw-r--r-- 1 root root 29 12月 31 22:51 Makefile
-rw-r--r-- 1 root root 25018 12月 31 22:51 README.md
drwxr-xr-x 2 root root 4096 12月 31 22:51 templates
-rw-r--r-- 1 root root 6847 12月 31 22:51 values.yaml修改values文件
[root@master-1-230 logstash]# cat values.yaml |egrep -v "#|^$"
---
replicas: 1
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
output { elasticsearch { hosts => [ "elasticsearch-master:9200" ] index => "logstash-k8s-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
logstashPatternDir: "/usr/share/logstash/patterns/"
logstashPattern: {}
extraEnvs: []
envFrom: []
secrets: []
secretMounts: []
hostAliases: []
image: "docker.elastic.co/logstash/logstash"
imageTag: "7.17.3"
imagePullPolicy: "IfNotPresent"
imagePullSecrets: []
podAnnotations: {}
labels: {}
logstashJavaOpts: "-Xmx1g -Xms1g"
resources:
requests:
cpu: "100m"
memory: "1536Mi"
limits:
cpu: "1000m"
memory: "1536Mi"
volumeClaimTemplate:
storageClassName: nfs-storageclass
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
rbac:
create: false
serviceAccountAnnotations: {}
serviceAccountName: ""
annotations:
{}
podSecurityPolicy:
create: false
name: ""
spec:
privileged: false
fsGroup:
rule: RunAsAny
runAsUser:
rule: RunAsAny
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
volumes:
- secret
- configMap
- persistentVolumeClaim
persistence:
enabled: true
annotations: {}
extraVolumes:
[]
extraVolumeMounts:
[]
extraContainers:
[]
extraInitContainers:
[]
priorityClassName: ""
antiAffinityTopologyKey: "kubernetes.io/hostname"
antiAffinity: "hard"
nodeAffinity: {}
podAffinity: {}
podManagementPolicy: "Parallel"
httpPort: 9600
extraPorts:
[]
updateStrategy: RollingUpdate
maxUnavailable: 1
podSecurityContext:
fsGroup: 1000
runAsUser: 1000
securityContext:
capabilities:
drop:
- ALL
runAsNonRoot: true
runAsUser: 1000
terminationGracePeriod: 120
livenessProbe:
httpGet:
path: /
port: http
initialDelaySeconds: 300
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 1
readinessProbe:
httpGet:
path: /
port: http
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 3
schedulerName: ""
nodeSelector: {}
tolerations: []
nameOverride: ""
fullnameOverride: "logstash"
lifecycle:
{}
service:
{}
ingress:
enabled: false
annotations:
{}
className: "nginx"
pathtype: ImplementationSpecific
hosts:
- host: logstash.ikubernetes.cloud
paths:
- path: /beats
servicePort: 5044
- path: /http
servicePort: 8080
tls: []其中最重要的就是通过 logstashPipeline 配置 logstash 数据流的处理配置,通过input 指定日志源 kafka 的配置,通过 output 输出到 Elasticsearch,同样直接使用上面的 Values 文件安装 logstash 即可:
[root@master-1-230 logstash]# helm upgrade --install logstash -f values.yaml --namespace logging .
Release "logstash" does not exist. Installing it now.
NAME: logstash
LAST DEPLOYED: Sun Dec 31 22:58:00 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=logstash -w安装完成后查看logstash 的日志
[root@master-1-230 9.4]# kubectl get pods --namespace=logging -l app=logstash
NAME READY STATUS RESTARTS AGE
logstash-0 1/1 Running 0 13m
kubectl logs -f logstash-0 -n logging由于我们启用了 debug 日志调试,所以我们可以在 logstash 的日志中看到我们采集的日志消息,到这里证明我们的日志数据就获取成功了。
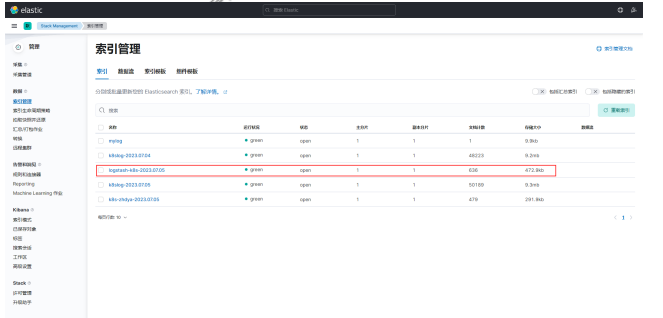
现在我们可以登录到 Kibana 可以看到有如下所示的索引数据了:
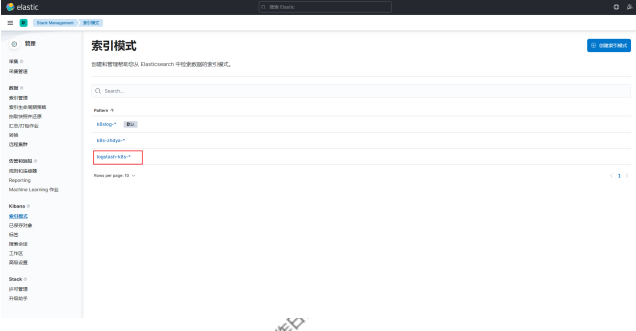
然后同样创建索引模式,匹配上面的索引即可:
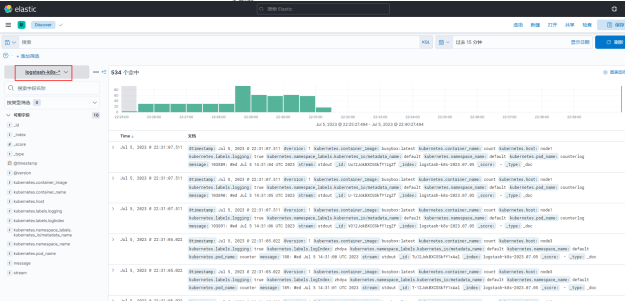
创建完成后就可以前往发现页面过滤日志数据了:
到这里我们就实现了一个使用 Fluentd+Kafka+Logstash+Elasticsearch+Kibana 的Kubernetes 日志收集工具栈,这里我们完整的 Pod 信息如下所示:
[root@master-1-230 fluentd]# kubectl get pod -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 5h22m
elasticsearch-master-1 1/1 Running 0 5h22m
elasticsearch-master-2 1/1 Running 0 5h22m
fluentd-6hh7d 1/1 Running 0 25m
fluentd-mq8p5 1/1 Running 0 25m
fluentd-wzwvw 1/1 Running 0 25m
kafka-0 1/1 Running 0 4h15m
kafka-client 1/1 Running 0 117m
kafka-zookeeper-0 1/1 Running 0 4h15m
kibana-kibana-679696bbf8-r2ck6 0/1 Running 0 5h8m
logstash-0 0/1 Running 0 4m59s当然在实际的工作项目中还需要我们根据实际的业务场景来进行参数性能调优以及高可用等设置,以达到系统的最优性能。
上面我们在配置 logstash 的时候是将日志输出到 "logstash-k8s-%{+YYYY.MM.dd}"这个索引模式的,可能有的场景下只通过日期去区分索引不是很合理;
那么我们可以根据自己的需求去修改索引名称,比如可以根据我们的服务名称来进行区分,那么这个服务名称可以怎么来定义呢?
可以是 Pod 的名称或者通过 label 标签去指定,比如我们这里去做一个规范,要求需要收集日志的 Pod 除了需要添加 logging: true 这个标签之外,还需要添加一个logIndex: <索引名> 的标签。
比如重新更新我们测试的 counter 应用:
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
logging: "true" # 一定要具有该标签才会被采集
logIndex: "zhdya" # 指定索引名称
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]然后重新更新 Logstash 的配置,修改 values 配置:
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 过滤配置(比如可以删除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-master:9200"] index => "k8s-%{[kubernetes][labels][logIndex]}-%{+YYYY.MM.dd}" }
stdout { codec => rubydebug } }logstash 更新
helm upgrade --install logstash -f values.yaml --namespace logging .使用上面的 values 值更新 logstash,正常更新后上面的 counter 这个 Pod 日志会输出到一个名为 k8s-zhdya-2023.07.05 的索引去。

这样我们就实现了自定义索引名称,当然你也可以使用 Pod 名称、容器名称、命名空间名称来作为索引的名称,这完全取决于你自己的需求。
9.5 初识日志收集组件Fluentd
前言
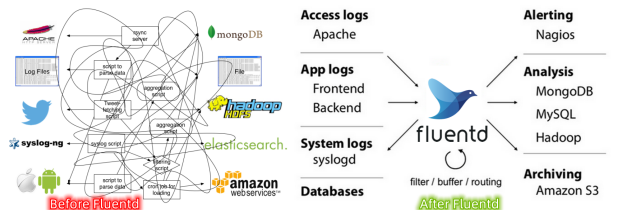
Fluentd 是一个开源的日志收集和传输工具,用于可靠地收集、传输和处理各种类型的日志数据。它被设计成具有灵活性和可扩展性,可以在复杂的日志处理场景中进行配置和定制。
以下是 Fluentd 的主要特性和功能:
- 日志收集:Fluentd 可以从多种来源(如文件、网络、消息队列等)收集结构化和非结构化的日志数据。
- 数据转换和处理:Fluentd 具有强大的数据处理和转换能力。它可以根据需求对收集到的日志数据进行解析、格式化、过滤、聚合和标记等操作。
- 数据路由和传输:Fluentd 支持将处理后的日志数据路由到不同的目的地。它提供了丰富的输出插件,可以将数据发送到各种存储系统(如文件系统、数据库、消息队列、Elasticsearch 等)或其他工具(如监控系统和处理流水线)进行进一步处理。
- 可扩展性:Fluentd 的架构设计允许在大规模和高负载环境下进行水平扩展。
- 插件生态系统:Fluentd 拥有广泛的插件生态系统,提供了各种丰富的输入、输出和过滤器插件。
- 可靠性和可恢复性:Fluentd 具有强大的容错和故障恢复机制。它支持数据缓冲、重试、日志文件切割和轮转等特性,以确保日志数据的可靠传输和处理。
- 配置灵活性:Fluentd 的配置文件采用结构化的格式,允许您灵活地定义数据源、转换规则、目的地和插件参数。
一、基于不同场景的安装配置
主要有2种方式:
- 手动安装:Fluentd 的配置和管理有更高级的要求,或者希望使用最新的稳定版本,可以选择手动安装 Fluentd。手动安装涉及下载源代码并进行编译、安装和配置。这种方式需要更多的技术知识和时间,适合有经验的用户或特殊需求的情况。
- 容器化安装:由于 Fluentd 被广泛用于容器环境中,可以选择使用容器化技术(如Docker)来安装和运行 Fluentd。这种方式使得在不同的云平台、开发环境和生产环境中部署和管理 Fluentd 变得更加方便和可重复。
1.1 手动安装Fluentd
环境配置优化
- 设置NTP
- 增加文件描述符的最大数量
- 优化网络内核参数
设置NTP
强烈建议在节点上设置 NTP 守护进程(例如 chrony 、 ntpd 等)以获得准确的当前时间戳,这对于所有生产服务至关重要。
增加文件描述符的最大数量
查看现有配置
[root@master-1-230 9.5]# ulimit -n
65535如果控制台显示1024,可以修改/etc/security/limits.conf 文件
* soft core unlimited
* hard core unlimited
* soft nofile 65535
* hard nofile 65535如果使用 systemd 下运行 fluentd,也可以使用选项 LimitNOFILE=65536 进行配置,如果你使用的是 td-agent 包,则默认会设置该值。
优化网络内核参数:
对于具有许多 Fluentd 实例的高负载环境,可以将以下配置添加到 /etc/sysctl.conf文件中:
net.core.somaxconn = 1024
net.core.netdev_max_backlog = 5000
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_wmem = 4096 12582912 16777216
net.ipv4.tcp_rmem = 4096 12582912 16777216
net.ipv4.tcp_max_syn_backlog = 8096
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 10240 65535使用 sysctl -p 命令或重新启动节点使更改生效。
一键安装Fluentd
curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh |sh通过 systemctl 来管理 td-agent 服务:
[root@master-1-230 9.5]# systemctl start td-agent && systemctl status td-agent
● td-agent.service - td-agent: Fluentd based data collector for Treasure Data
Loaded: loaded (/usr/lib/systemd/system/td-agent.service; disabled; vendor preset: disabled)
Active: active (running) since 一 2024-01-01 08:47:11 CST; 1s ago
Docs: https://docs.treasuredata.com/articles/td-agent
Process: 12745 ExecStart=/opt/td-agent/embedded/bin/fluentd --log $TD_AGENT_LOG_FILE --daemon /var/run/td-agent/td-agent.pid $TD_AGENT_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 12963 (fluentd)
Tasks: 6
Memory: 55.2M
CGroup: /system.slice/td-agent.service
├─12963 /opt/td-agent/embedded/bin/ruby /opt/td-agent/embedded/bin/fluentd --log /var/log/td-agent/td-agent.log --daemon /var/run/td-agent/td-agent.pid
└─13099 /opt/td-agent/embedded/bin/ruby -Eascii-8bit:ascii-8bit /opt/td-agent/embedded/bin/fluentd --log /var/log/td-agent/td-agent.log --daemon /var/run/td-agent/td-agent.pid --under-supervis...
1月 01 08:46:23 master-1-230 systemd[1]: Starting td-agent: Fluentd based data collector for Treasure Data...
1月 01 08:47:11 master-1-230 systemd[1]: Started td-agent: Fluentd based data collector for Treasure Data.测试验证
td-agent 启动后通过下面的命令发送一条日志
[root@master-1-230 9.5]# netstat -lntp |grep 8888
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 12963/ruby
您在 /var/spool/mail/root 中有新邮件
[root@master-1-230 9.5]# curl -X POST -d 'json={"json":"message01"}' http://localhost:8888/debug.test1.2 Docker安装Fluentd
使用Docker方式在不同的云平台、开发环境和生产环境中部署和管理 Fluentd 变得更加方便和可重复;
mkdir fluentd && cd fluentd
mkdir -p etc logs
cat etc/fluentd_basic.conf
<source>
@type http
port 8888
bind 0.0.0.0
</source>
<match test.basic>
@type stdout
</match>启动Fluentd
docker run -itd -p 8889:8888 --rm -v $(pwd)/etc:/fluentd/etc -v $(pwd)/logs:/fluentd/logs fluent/fluentd:v1.14-1 -c /fluentd/etc/fluentd_basic.conf将 etc 目录和 logs 目录挂载到容器中;
- -c :参数指定 Fluentd 的配置文件;
- -v :参数是用于设置 Fluentd 开启 verbose 模式,便于查看 Fluentd 的日志方便调试;
测试验证:
[root@master-1-230 fluentd]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3144bcaa2b1d fluent/fluentd:v1.14-1 "tini -- /bin/entryp…" 46 seconds ago Up 43 seconds 5140/tcp, 24224/tcp, 0.0.0.0:8889->8888/tcp, :::8889->8888/tcp strange_bohr
[root@master-1-230 fluentd]# netstat -lnp|grep 8889
tcp 0 0 0.0.0.0:8889 0.0.0.0:* LISTEN 14781/docker-proxy
tcp6 0 0 :::8889 :::* LISTEN 14787/docker-proxy
[root@master-1-230 fluentd]# docker logs --tail 100 3144
fluentd -c /fluentd/etc/fluentd_basic.conf
2024-01-01 00:49:13 +0000 [info]: parsing config file is succeeded path="/fluentd/etc/fluentd_basic.conf"
2024-01-01 00:49:13 +0000 [info]: gem 'fluentd' version '1.14.6'
2024-01-01 00:49:13 +0000 [info]: using configuration file: <ROOT>
<source>
@type http
port 8888
bind "0.0.0.0"
</source>
<match test.basic>
@type stdout
</match>
</ROOT>
2024-01-01 00:49:13 +0000 [info]: starting fluentd-1.14.6 pid=7 ruby="2.7.6"
2024-01-01 00:49:13 +0000 [info]: spawn command to main: cmdline=["/usr/bin/ruby", "-Eascii-8bit:ascii-8bit", "/usr/bin/fluentd", "-c", "/fluentd/etc/fluentd_basic.conf", "--plugin", "/fluentd/plugins", "--under-supervisor"]
2024-01-01 00:49:16 +0000 [info]: adding match pattern="test.basic" type="stdout"
2024-01-01 00:49:16 +0000 [info]: adding source type="http"
2024-01-01 00:49:18 +0000 [info]: #0 starting fluentd worker pid=16 ppid=7 worker=0
2024-01-01 00:49:18 +0000 [info]: #0 fluentd worker is now running worker=0启动后我们同样可以发送一条日志到 Fluentd 来验证我们的配置:
[root@master-1-230 9.5]# curl -i -X POST -d 'json={"action":"login","user":100}' http://localhost:8889/test.basic
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: Keep-Alive
Content-Length: 0
您在 /var/spool/mail/root 中有新邮件发送正常后会在Fluentd中看下如下信息:

9.5-2-初识日志收集组件Fluentd(2)
二、时间管理
2.1 时间生命周期
Fluentd 是一个开源的日志收集和传输工具,其事件生命周期可以简单概括为以下几个阶段:
- 输入(Input)阶段:在输入阶段,Fluentd 从各种来源(如文件、网络流、消息队列等)接收日志事件。
- 解析(Parse)阶段:在解析阶段,Fluentd 对输入的原始日志进行解析,将其转换为结构化的事件数据。
- 过滤(Filter)阶段:在过滤阶段,Fluentd 对解析后的事件数据进行筛选、处理和转换。通过配置不同的过滤器插件,可以实现日志的筛选、修改、标记、丰富等操作。
- 缓冲(Buffer)阶段:在缓冲阶段,Fluentd 将经过解析和过滤的事件数据缓存起来,以便进行批量传输或更高效的处理。
- 输出(Output)阶段:在输出阶段,Fluentd 将经过解析、过滤和缓冲的事件数据发送到目标存储、消息队列、日志分析工具或其他目的地。
2.2 事件内容
Fluentd 的事件主要由下面三部分组成:
- 标签(Tag):标签是 Fluentd 用于对事件进行分类和路由的关键标识。它是一个字符串,可以用来表示事件的来源、类型、应用程序等信息。通过配置不同的标签,您可以将事件路由到相应的输出插件或处理流程中。
- 时间(Time):时间是 Fluentd 事件的一个重要属性,表示事件生成或发生的时间戳。时间戳可以是 Unix 时间戳(秒级或毫秒级),也可以是 ISO 8601 格式的字符串。时间戳信息通常用于日志的排序、分析和时间窗口的计算。
- 记录(Record):记录是 Fluentd 事件中的数据部分,它是一个结构化的键值对或JSON 对象。记录包含了事件所携带的具体数据,可以是应用日志、系统指标、传感器数据等各种形式的信息。在 Fluentd 的输入、解析、过滤和输出阶段,记录将被处理、转换和传输。
所有的输入插件都需要解析原始日志,生成满足上面结构的事件字段,比如一条Apache 的访问日志:
192.168.0.1 - - [8/Jul/2023:12:00:00 +0800] "GET / HTTP/1.1" 200 777在通过 in_tail 输入插件处理后,会得到如下所示的输出结果:
tag: apache.access # 通过配置文件指定
time: 1362020400 # 8/Jul/2023:12:00:00 +0800
record: {"user": "-", "method": "GET", "code": 200, "size": 777,"host": "192.168.0.1", "path": "/"}当 Fluentd 收到一条事件后会经过一系列的处理流程:
- 修改事件的相关字段
- 过滤掉一些不需要的事件
- 路由事件输出到不同的地方
三、过滤器Filter
Filter 用于定义一个事件是该被接受或是被过滤掉,接下来我们创建一个新的配置文件新增过滤器。
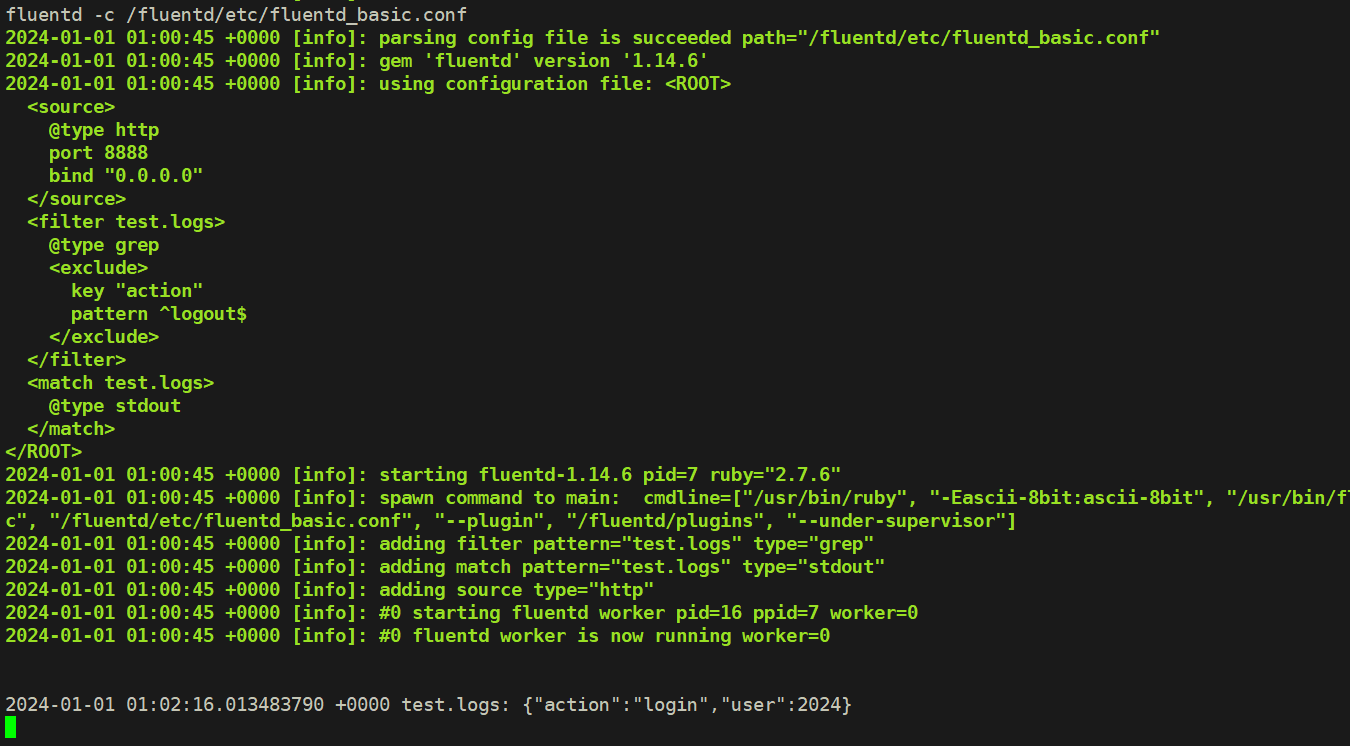
$ cat etc/fluentd_filter.conf
<source>
@type http
port 8888
bind 0.0.0.0
</source>
<filter test.logs>
@type grep
<exclude>
key action
pattern ^logout$
</exclude>
</filter>
<match test.logs>
@type stdout
</match>在该配置文件中我们新增了一个 filter 模块,使用 grep 插件,exclude 部分表示要过滤掉的日志配置,这里我们配置的是 action 这个 key 匹配 ^logout$ 的时候进行过滤,就是直接过滤掉 logout 日志事件。
使用新的配置文件,重新启动 fluentd:
docker run -itd -p 8888:8888 --rm -v $(pwd)/etc:/fluentd/etc -v $(pwd)/logs:/fluentd/logs fluent/fluentd:v1.14-1 -c /fluentd/etc/fluentd_basic.conf
或者
[root@master-1-230 fluentd]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3144bcaa2b1d fluent/fluentd:v1.14-1 "tini -- /bin/entryp…" 11 minutes ago Up 11 minutes 5140/tcp, 24224/tcp, 0.0.0.0:8889->8888/tcp, :::8889->8888/tcp strange_bohr
[root@master-1-230 fluentd]# docker restart 3144
3144
[root@master-1-230 fluentd]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3144bcaa2b1d fluent/fluentd:v1.14-1 "tini -- /bin/entryp…" 11 minutes ago Up 4 seconds 5140/tcp, 24224/tcp, 0.0.0.0:8889->8888/tcp, :::8889->8888/tcp strange_bohr重新向Fluentd提交两条日志数据
curl -X POST -d 'json={"action":"login","user":2024}' http://localhost:8888/test.logs
curl -X POST -d 'json={"action":"logout","user":2024}' http://localhost:8888/test.logs正常这个时候 Fluentd 只会收到第一条日志数据, logout 这条事件被过滤掉了:
四、标识符Lables
Fluentd 的处理流程:根据在配置文件中的定义从上到下依次执行。
假如在配置文件中定义了多个输入源,不同的输入源需要使用不同的 Filters 过滤器的时候,如果还按照顺序执行的方式,配置文件就会变得非常复杂。
为了解决这个问题,Fluentd 中提供了一种标识符 Labels 的方式,可以为不同的输入源指定不同的处理流程。
如下所示创建一个新的配置文件 fluentd_labels.conf :
[root@master-1-230 9.5]# cat fluentd_labels.conf
<source>
@type http
port 8888
bind 0.0.0.0
@label @TEST
</source>
<filter test.logs>
@type grep
<exclude>
key action
pattern ^login$
</exclude>
</filter>
<label @TEST>
<filter test.logs>
@type grep
<exclude>
key action
pattern ^logout$
</exclude>
</filter>
<match test.logs>
@type stdout
</match>
</label>首先我们在输入源中给日志源定义了一个标签 @label @TEST ,然后先定义了一个 filter过滤掉 login 事件,然后在一个 label 模块里面过滤了 logout 事件。
现在我们使用该配置重新启动 Fluentd:
docker run -itd -p 8889:8888 --rm -v $(pwd)/etc:/fluentd/etc -v $(pwd)/logs:/fluentd/logs fluent/fluentd:v1.14-1 -c /fluentd/etc/fluentd_basic.conf
或者
[root@master-1-230 fluentd]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3144bcaa2b1d fluent/fluentd:v1.14-1 "tini -- /bin/entryp…" 17 minutes ago Up 6 minutes 5140/tcp, 24224/tcp, 0.0.0.0:8889->8888/tcp, :::8889->8888/tcp strange_bohr
[root@master-1-230 fluentd]# docker restart 3144
3144
[root@master-1-230 fluentd]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3144bcaa2b1d fluent/fluentd:v1.14-1 "tini -- /bin/entryp…" 18 minutes ago Up 1 second 5140/tcp, 24224/tcp, 0.0.0.0:8889->8888/tcp, :::8889->8888/tcp strange_bohr然后重新向 Fluentd 提交两条日志数据:
[root@master-1-230 9.5]# curl -X POST -d 'json={"action":"login","user":2024}' http://localhost:8889/test.logs
您在 /var/spool/mail/root 中有新邮件
[root@master-1-230 9.5]# curl -X POST -d 'json={"action":"logout","user":2024}' http://localhost:8889/test.logs正常 Fluentd 中会输出一条日志记录:
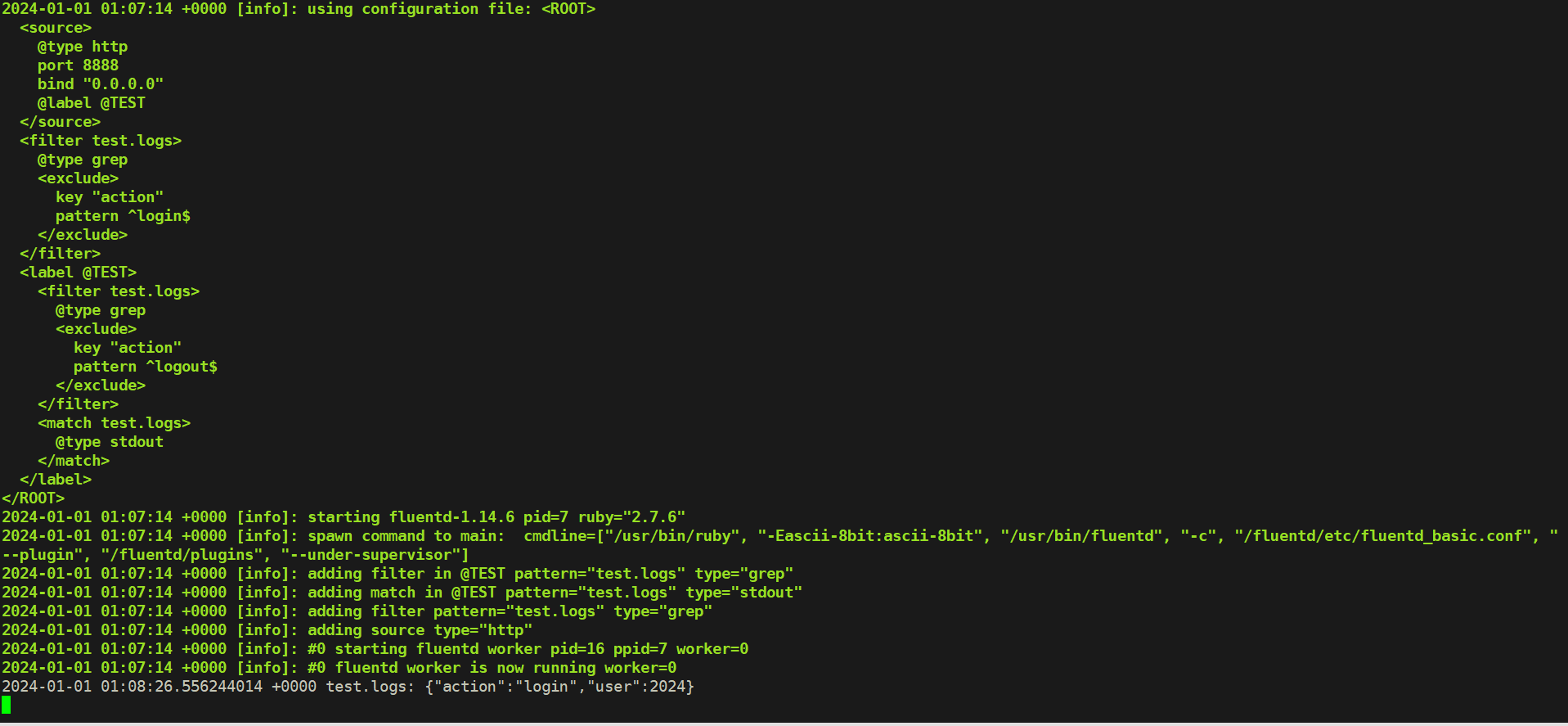
这是因为我们为输入日志设置了 @TEST 的标签,因此跳过中间设置的一些过滤器,只运行了 <label @TEST>...</lable> 标签块里的过滤器,如果标签块里面没有定义过滤器则就不会过滤日志了。