ICDE 2021 | DISC:基于密度的跨越流数据的增量聚类
鸣谢:Ruiyuan Li (李瑞远)老师 | 康瑞部落 (kangry.net)
鉴于移动设备和物联网设备的普及,对流媒体数据的持续聚类已成为数据分析中日益重要的工具。在众多的聚类方法之中,基于密度的聚类方法由于其独特的优势而受到广泛的关注。然而,由于其相对较高的计算成本和其有限的可伸缩性,特别是在不断有新的数据加入导致需要更新集群的时候,这一现象将会进一步加剧。为此,本次为大家带来的是数据库国际顶级会议ICDE2021上的论文《DISC:Density-Based Incremental Clustering by Striding over Streaming Data》。这篇文章提出了一种新的基于增量密度的聚类算法DISC,解决了基于密度聚类在处理流式数据时可扩展性有限的问题,不仅如此,该算法能够产生与现有聚类方法相同的聚类结果,但是速度更快,效率更高。

- 背景
这一部分给读者提供关于基于密度的聚类方法的相关信息和在流式数据处理中通常采用的滑动窗口模型的关键特征,以便读者的后续理解。
- DBScan相关概念介绍
密度聚类算法是由Ester等人在20多年前首次提出,该算法通过引入距离阈值ε和密度即距离阈值内点的数量,将点分为核心点core,边界点border,噪声点noise。点的种类由参数Minpts决定:若一个点的密度不小于Minpts,那么该点将会标记为core;若一个点的密度小于Minpts,但是该点在某个核心点的距离阈值之内,那么该店被标记为border,否则,该点被标记为noise。
DBScan算法将聚类定义为一组从聚类的任意核心点出发,通过密度可达关系(density-reachable)与核心点或边界点相连的点的集合。下面给出相关定义:
- 直接密度可达(directly density-reachable):让Nε(p)表示处于p的距离阈值之内点的集合,如果点p为core,且q属于Nε(p),那么q直接密度可达p;
- 密度可达(density-reachable):如果从点p到点q存在一条由直接密度可达的核心点组成的链路,那么点q就被称为从点p密度可达。
如Fig1所示,边界点Y直接密度可达核心点X,核心点A和B相互之间密度可达。
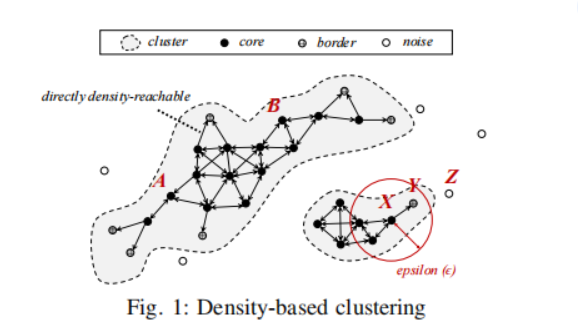
根据核心点和边界点的密度可达关系,DBScan算法试图找到基于密度的聚类。具体而言,在seeding phase找到每个核心点p后,创建一个包含p的单例聚类C。然后,在growing phase将从C中的任意点q直接密度可达的所有点添加到C中。重复该过程直到C不再增长。因此,当算法终止时,DBScan返回基于密度的聚类,每个聚类都是由核心点和边界点组成的最大连通分量。
- Sliding Windows介绍
滑动窗口模型是流数据分析中一种流行模型,通常由两个参数窗口(window)和步长(stride)来定义,窗口的大小定义了要分析的流数据的范围,而步长定义了更新分析结果的间隔。当窗口前进时,大量的数据对象同时进入或离开窗口,同一步长内的数据点之间没有特定的处理顺序,且具有相同的权重或影响力。
- DISC算法介绍
2.1 DISC算法概要
DISC算法与DBScan算法相似,它也会将单个数据点分配到三个类别:core(核心),border(边界),noise(噪声)。在聚类完成后,每个数据点(噪声点除外)都会有一个类ID,即cid。
让Nε(p)表示在点p距离阈值ε内数据点的集合,nε(p)表示集合中的点的数量,该量在聚类过程中时不断更新的。当滑动窗口向前移动的时候,新的数据点会进入窗口,而一些现有的数据点将会离开窗口。DISC算法会根据滑动窗口内数据点的变化来更新nε(p)和类别标签,以便将簇更新到最新的状态,而这一步是通过两个步骤完成的:Collect(收集)和Cluster(聚类)。
Collect步骤会更新每个数据点在当前窗口的nε(p),并且重置或初始化每个数据点离开窗口或进入窗口的标签(label,i.e. l),然后,确定在当前窗口内的ex-cores(前核)和neo-cores(新核)并且更新R-tree的相关索引。
Cluster步骤会找到每个ex-core和neo-core的最小边界核心(the minimal bonding cores),通过检查连通性来确定聚类演变的方式,并最终重新计算每个点在当前窗口中的聚类标签。
在Fig.2中展示了DISC的总体框架:
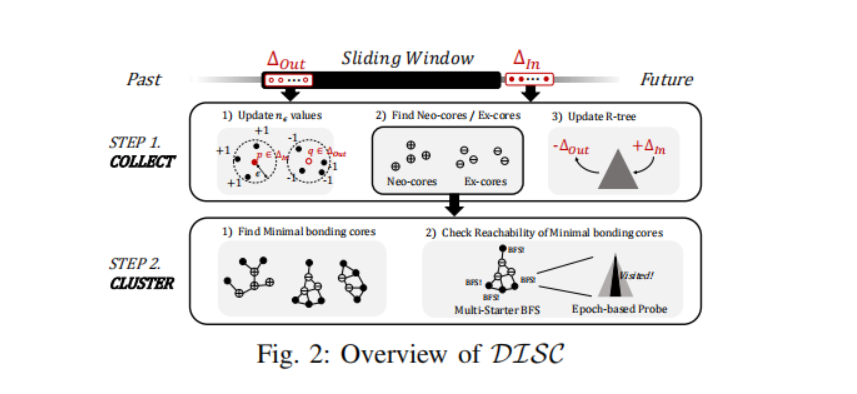
2.2 Collect步骤
这个步骤有两个重要的任务,一个是当数据点p进入或离开滑动窗口的时候,对于属于Nε(p)的每一个数据点q,都需要更新其nε(q)。如果让Δout和Δin分别表示离开滑动窗口点的集合和进入滑动窗口点的集合,那么,若q属于Nε(p),p属于Δout,nε(q)将会减小;相反则会增加;另外一个主要工作就是计算出ex-core和neo-core,其中:
ex-core定义为:前一个窗口中的已经离开的core(i.e. p ∈ Δout)或者仍然处于当前窗口,但是不再是core(i.e. p ∈ Windowcurr ∩ Windowpre);
neo-core定义为:刚进入滑动窗口的core(i.e. p ∈ Δin)或者在前一个滑动窗口中不是core,但是在当前窗口中变为core(i.e. p ∈ Windowprev ∩ Windowcurr);
在接下来的Cluster算法步骤之中,ex-core和neo-core将会对集群演化类型产生重要的影响。Algorithm1展示了Collect算法的步骤:

2.3 Cluster步骤
在Collect步骤中得到的ex-cores和neo-cores共同决定了是否应该拆分集群以及是否应该合并集群。除此以外,其他集群的类型演化,如诞生(emergence),消亡(dissipation),扩大(expansion),缩小(shrink)也仅由ex-core和neo-core决定。
以下先给出Cluster步骤的相关伪代码:

从上述的伪代码可以看出,ex-core用于集群的分裂,缩小或者是消亡,neo-core用于集群的合并,扩大或者是诞生。在集群的分裂和合并两个主要操作之间,拆分集群可以逐步更新集群,下面将会详细阐述该算法的每个子过程。
2.3.1 Splitting a Cluster
首先,一个集群的分裂也包含该集群中核心点之间密度可达性的分裂,当一个点变为ex-core,它可能会切断同一集群之间中的核心点之间的密度可达路径,这反过来可能导致集群的分裂。本质上来讲,只有当前这个ex-core处于同一个集群的两个核心点之间的密度可达路径,并且这两个核心点之间没有更多的密度可达路径的时候,该集群才会被分裂。
为了避免上述过程的大量的冗余搜索过程,论文提出通过检查最小结合核(the minimal bonding core)的密度连通性和最小化所需的范围搜索次数。为了方便理解,下面给出最小结合核的相关定义。
- ex-core的追溯可达外核集(retro-reachable ex-cores set):对于ex-cores中的一对p, q,如果p是直接密度可达q,那么q相对于p是可追溯到达的,所有这样的q所形成的集合称之为R-(p),即:
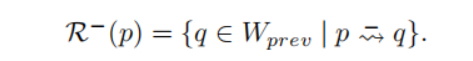
- 最小结合核(the minimal bonding core,M-(p)):对于外核点p,其追溯可达外核集R-(p)中的点r,当存在于Windowprev和Windowcurr中的核心点q,q∈Nε(r)时,q是M-(p)中的一个元素,然后,所有类似于q的数据点组成M-(p)。
如Fig.3,边界点P1和核心点P2将要退出当前窗口(即滑动窗口将要滑动),与P1相邻的B,K数据点变为ex-core,与P2相邻的数据点D,F变为ex-core,显而易见,P2也是ex-core,然后数据点B的追溯可达外核集R-(B) = {B, D, F, K, P2},并且B的最小结合核M-(B) = {A, C, E, G, H, J}。
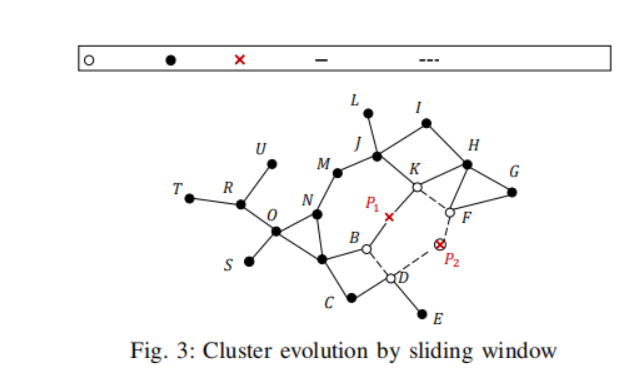
结合最小结合核,接下来的引理和定理可以让我们从繁杂的搜索中脱离出来,而只关注外核点的最小结合核。
引理一:对于外核中的p和q,如果R-(p) = R-(q),那么M-(p) = M-(q);
引理二:对于外核中的点p,如果M-(p)是密度连接的,那么点p不会造成集群分裂;
相关引理引理的证明论文中已详细给出,并且相对简单,在此不在叙述,感兴趣的读者可以查看论文。
有了上述两个引理,定理一就很好说明了。
定理一:对于外核p,如果M-(p)是密度连接的,那么任意一个存在与R-(p)中的点都不会使集群分裂;
由此可见,定理一的使用将会大大减少范围搜索的数量,从而避免了大量的冗余工作。现在,将我们的注意力回归到ex-core对集群的演化的作用之上。
一旦每个外核点p的M-(p)被计算得出,那么就可以决定集群的演变结果了。如果M-(p)不是密度连接的,那么集群将会被分裂;如果M-(p)是密度连接的,那么该集群仅仅是缩小;如果M-(p)是空的,那么该集群将会消失。
为了检查M-(p)的连通性,可以使用BFS进行搜索,但是当M-(p)很大的时候,这样的范围搜索毫无疑问是极为耗费时间的。为此,论文提出一种Multi-Starter BFS算法和Epoch-Based probing method方法来减少时间消耗,将会在叙述完Merging的时候介绍。
2.3.2 Merging Clusters
前面已经叙述了ex-core对于分裂集群的用处,接下来要叙述的是neo-core对于合并集群的作用。首先需要明确的是,只有一个新核(neo-core)才能有助于创建一个新的密度可达路径,因此,只有当一个处于当前窗口的点变为核心点或是一个核心点进入当前窗口,即形成一个neo-core的时候,才可能合并现有的集群。
与处理ex-core存在很多相似之处,处理neo-core的时候也定义了以下的相似定义。
- 新生可达性(nascent-reachability):对于新核中的一对点p和q,如果p是直接密度可达于q,那么,p是新生可达于q;所有的与q类似的点形成点集R+(p),即:
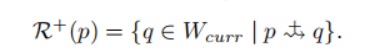
- (新核)最小结合核:对于新核点p,其新生可达集R+(p)中的点r,当存在于Windowprev和Windowcurr中的核心点q,q∈Nε(r)时,q是M+(p)中的一个元素,然后,所有类似于q的数据点组成M+(p)。
与集群的分裂相似,仅基于上述的新生可达集R+(p)和最小结合核M+(p)就可以决定集群的演化方式,如果M+(p)是空集,那么一个仅包含R+(p)新的集群将会诞生;如果M+(p)中所有的点都属于同一个集群,那么该集群将会扩大,加入的点为R+(p)中的点;如果M+(p)中的点分散在多个集群之间,那么这些集群中的核心点将会与R+(p)中的neo-core形成一个单独的集群。
由上述过程可知,一个集群的分裂和多个集群的合并可以被ex-core和neo-core很好的处理。那么,现在的注意力回到检查最小结合核的连接性,即Multi-Starter BFS算法和Epoch-Based Probing of R-tree Index算法之上。
2.4 检查可达性
由前文可以知道,一个集群是否分裂取决于一个外核(ex-core)的最小结合核(the minimal bonding core)是否密度连接。对于给定的一对核,可以通过从任意一个核开始对R-tree索引执行一系列范围搜索,只有当搜索在耗尽所有可达核心之前遇到另一个核心时,才能被声明为密度可达。然而,为了维护这张搜索图,需要消耗O(n2)的成本,这实在是太高了!为此,论文提出Multi-Starter BFS算法,这是传统BFS算法的延伸。下面给出算法的伪代码:

假设有一个非实体化的图G(V,E),其中顶点集V包含核心点,边集E包含一对互为ε邻居的核心点。Multi-Starter BFS算法从G的每个M-(p)中的顶点同时开始一次广度优先搜索。当两个搜索在某个顶点相遇时,它们将把它们的顶点队列合并为一个,然后重新启动一个以合并后的队列为起点的单一搜索。如果所有这些搜索都合并成为一个,那么图G是连通的,这表明M-(p)中的所有核心都是密度连通的。否则,图G具有多个连通分量,而M-(p)不是密度连通的。具体来说,如果在G的所有顶点被访问之前,其中一个队列变为空,那么MS-BFS的该线程将以自己的连通分量终止。在这种情况下,连通分量没有覆盖G中的所有顶点。因此,图G不是连通的。
为了解决传统BFS算法中布尔数组的储存问题,论文又提出相关解决算法——Epoch-Based Probing of R-tree Index。具体伪代码如下:

该算法将访问历史的epoch值存储在R树索引中,而不是使用布尔型的访问或未访问的标识数组。该方法可以通过一个单调递增的计数器有效地实现。在密度可达性检查算法Multi-Starter BFS开始新的情况下,给定一个记号值(tick value),以便每个个体Multi-Starter BFS实例都被赋予一个独特的记号值。叶节点中的一个条目将当前记号值作为它的epoch,这个epoch对应于该条目(和它的核心)的被访问情况。因此,小于当前记号的epoch值暗示着父节点条目中至少存在一个子条目尚未被当前Multi-Starter BFS实例访问到。通过这种算法,删除了每个范围搜索必须探测的索引中任何不必要的部分,从而大大降低了探测R-tree的成本。
当然,DISC的最终目的是为了正确表示集群的id和正确标记当前窗口中的每个数据点的种类。在处理M-和M+时,核心点以及受核心点影响的点的标签可能会发生变化,这些标签会在Multi-Starter BFS过程中进行更新。同时,接近核心点的非核心点的标签也可能发生变化。处理所有点的标签后,所有同一连通分量内的核心点和边界点都会共享相同的聚类id,这确保了与DBSCAN相同的聚类集。
到此为止,DISC算法已经阐述完毕,下面进入评估环节。
- 实验
3.1 实验环境
AMD-based stand-alone machine with Ryzen 7 1700 8-core Processor,64GB RAM,and a 256GB solid-state drive, Ubuntu 18.04 LTS, JDK 1.8.0-121。
3.2 实验数据集
1. DTG:记录总数为30亿的,从城市商用车上的数字行车记录仪设备获得的数据集;
2. GeoLife:记录总数为2480万的GPS轨迹数据集;
3. COVID-19:记录总数为21万的关于新型冠状病毒的地理标签数据集;
4. IRIS:记录总数为180万,从1960年到2019年的地震事件数据集。
3.3 实验结果
3.3.1 基线评估
在实验中,将DBScan作为基线方法,测量了DISC,IncDBScan,EXTRA-N相对与DBScan的性能,相关数据集的参数选择如Table Ⅱ,结果如图4,图5所示。
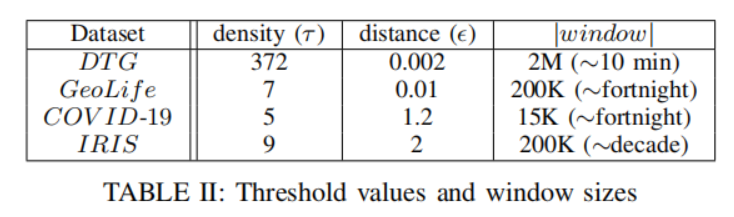
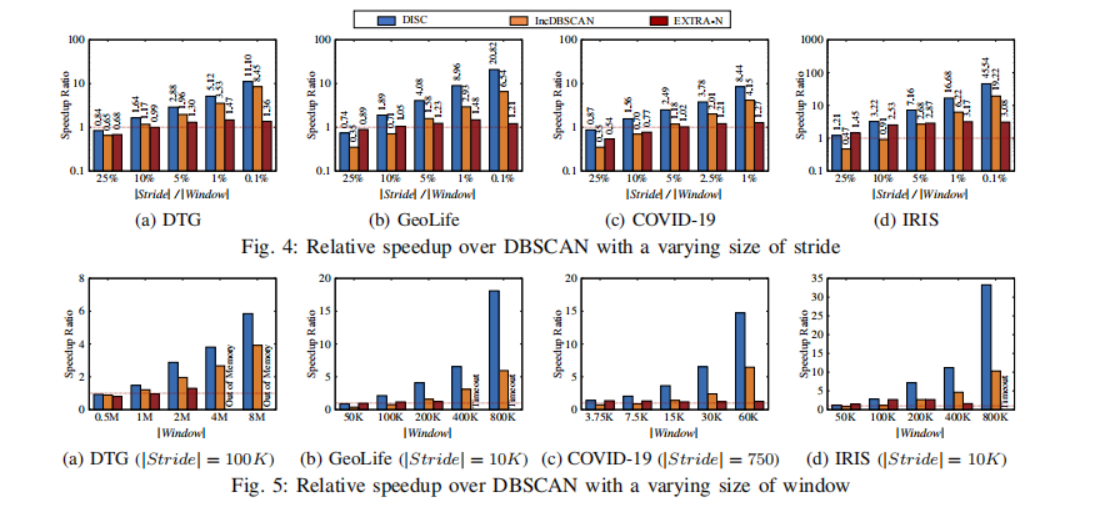
其中,如图4可知,DBScan对4个数据集的平均运行时间分别为102s,523s,496ms,533s。当步幅不大于滑动窗口大小的10%的时候,DISC算法在包括DBScan算法在内的所有聚类算法中表现最好。例如,在图4之中,DISC比表现第二优秀的加速从27%到318%。
3.3.2 深度评估
在展示完DISC的基线评估之后,为了更加详细地了解各种参数设置下的性能特征和所提出的优化技术的影响,下面提供了进一步分析。
- 阈值的影响
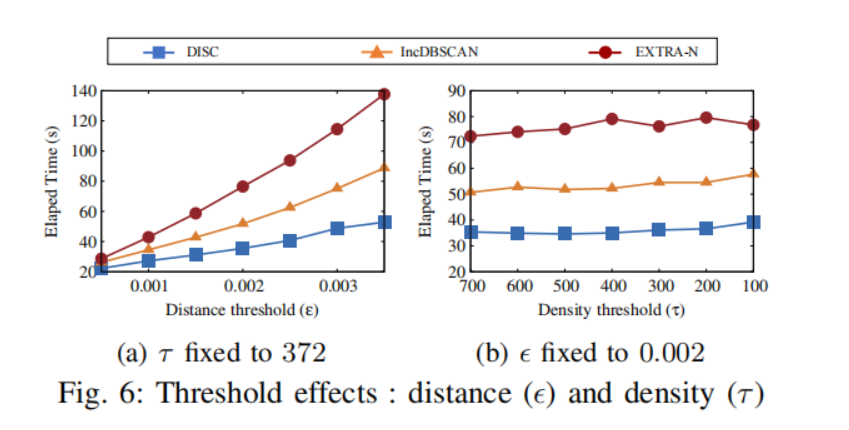
从Fig.6可以看出,无论是哪个阈值,DISC的性能都比其他算法更加稳定和有效。
- 范围搜索
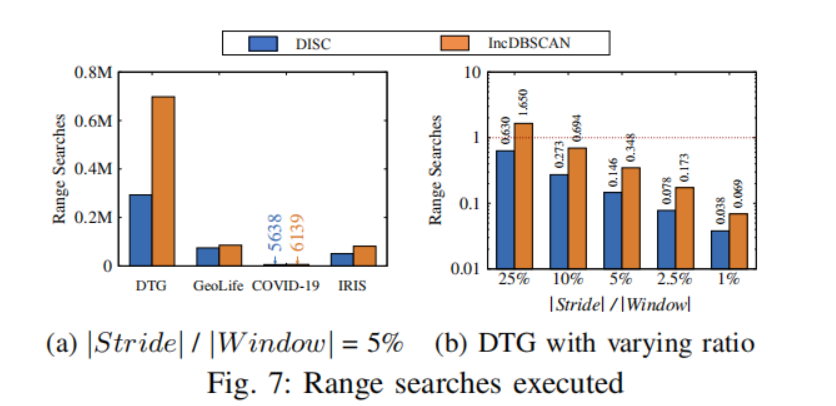
图7(a)显示了由DISC和IncDBSCAN进行的范围搜索的次数,其中步幅与窗口的比值固定为5%。在所有四个数据集上,DISC调用的范围搜索的数量都少于IncDBSCAN。图7(b)比较了两种方法与DTG数据集的DBSCAN的比较。在所有测试的步幅-窗比中,DISC在范围搜索调用的数量上一致地优于IncDBSCAN和DBSCAN。
- MS-BFS和Epoch-based probing
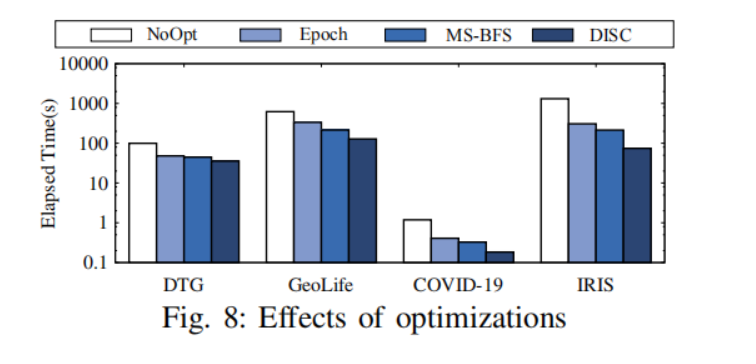
首先需要明确的是,MS-BFS和Epoch-based probing可以相互独立地应用,因此可以单独评价它们的效果。这两种优化技术即使单独应用,也大大减少了运行时间。在两者之间,MS-BFS在所有数据集上都比Epoch-based probing更有效。显然,当两种优化技术同时应用时,获得了最好的性能,在IRIS数据集的情况下产生了超过一个数量级的加速。
3.3.3 距离阈值ε较小值评估
上文已经将DISC与其他的聚类方法进行了比较,下面关注的是当距离阈值ε采用相对小的值的时候捕获簇的详细形状的能力。为此,DISC将与ρ2-DBScan算法,EDM算法,DBS算法在Maze数据集,DTG数据集上进行比较,结果如下图,
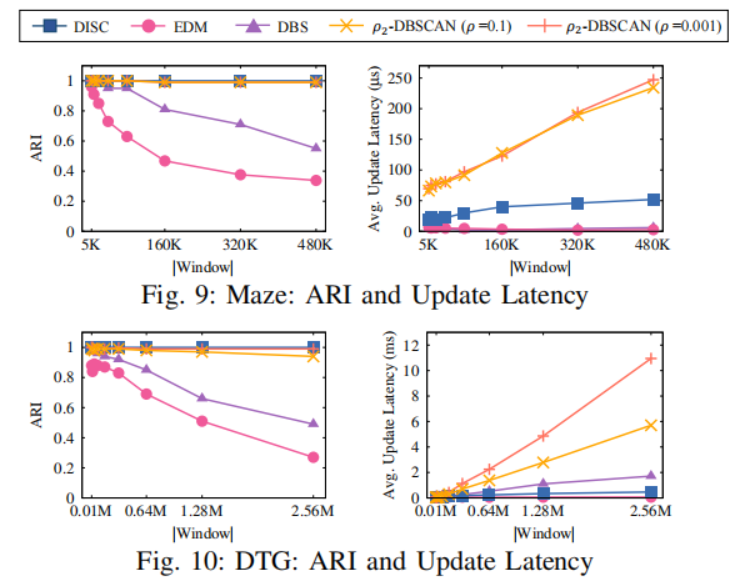
图9显示了在Maze数据集中观察到的质量测量和每点更新延迟。ρ2-DBScan和DISC算法都能够准确检测到集群形状,但是ρ2-DBScan比DISC慢了5倍。在DTG数据集中也展现了相似的趋势。
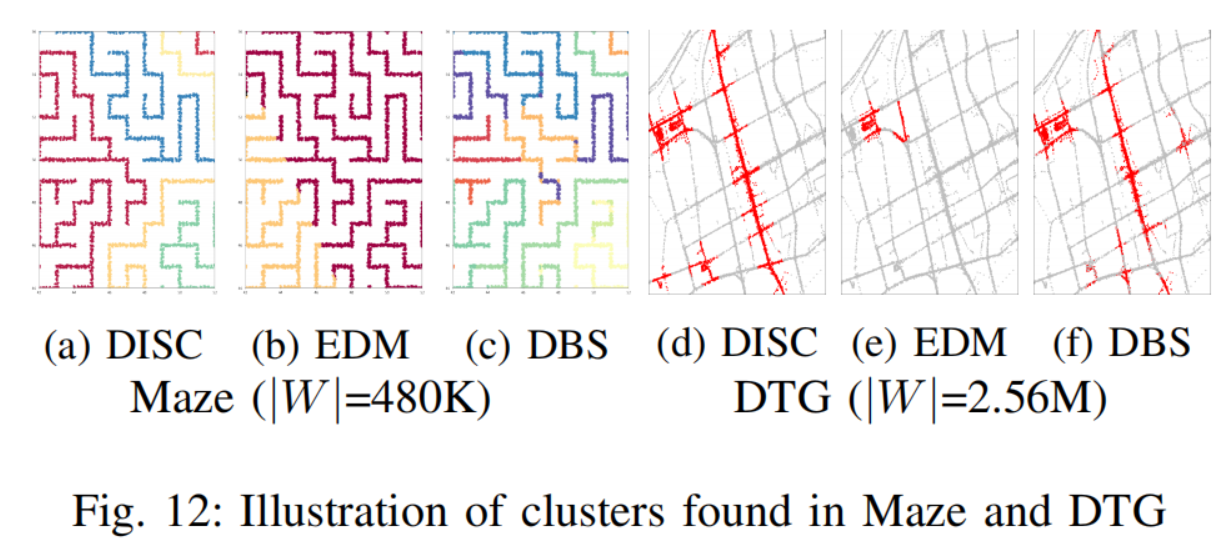
图12展示了通过不同方法发现的集群,可以看出,对于DTG数据集,只有DISC算法正确地检测到单独连通分量作为一个单独的集群。
以上实验证实,DISC可以以相对较低的成本检测出高分辨率的簇!
- 总结
这篇论文介绍了基于密度聚类算法中的核心思想,讨论了基于密度聚类算法的局限性,提出了改进密度聚类算法的解决方法——DISC算法,详细地介绍了DISC算法的设计与实现,同时总结了DISC算法在相关数据集上的杰出性能。