GAN的进一步探究
书接上回, 因为本人在GAN才刚入门, 尽管直接调用别人的ACGAN得到的效果已经很棒, 但是我还是想要继续看一下不同参数对于生成图像的影响, 帮助自己去更好理解.
学习率调节
为了平衡D和G的过程, 我们可以适当更改学习率. 这个小trick甚至有个专门的名字叫Two Time-Scale Update Rule([1706.08500v6] (arxiv.org)). 其核心思想就是: 对D采用较大的lr, 而对G采用较小的lr. 乍一看这可能很迷惑, 明明D都已经收敛了, G不咋行, 咋还想着让D比G快呢? 其实, 我们知道, G不再变化的本质就是D足够好了, 所以让D无法给G提供有效信息, 所以我们希望让D能不断指引G做出正确的操作. 对于D提高lr, 使得D不断在最优附近波动, 而对G减小LR, 防止G采用过于激进的手段去骗过D. 我们按照其推荐的参数尝试. 与此同时, 我也尝试了学习率退火这个方案. 很显然, 初始效果显现的速度和最开始的lr是成正比的, 所以在较小的lr下最开始的训练看起来很不理想. 不过我在这里尝试之后, 得到的效果其实不算好, 因此没有放出图像(看到的第一时间就有让人shift+delete的冲动hh).
我开始意识到, 我目前似乎还没有深入论文层次认真阅读, 因此对于很多措施不知道为什么, 下面的内容明显偏离了我最初的目标, 但是足够深入的学习, 相信可以帮助我深层次理解GAN这个强有力的工具.
WGAN细解
WGAN本身重点解决了D和G训练不平衡问题, 解决模式崩塌等.
实际上, 与WGAN有关的有两篇文章: [1701.04862] Towards Principled Methods for Training Generative Adversarial Networks (arxiv.org)讲解了常规GAN的根本问题, 而[1701.07875] Wasserstein GAN (arxiv.org)才介绍了他们是怎么解决这个问题的. 下面我们分别将这两篇文章简记为WGAN序章和WGAN论文. 本部分大量参考了文章令人拍案叫绝的Wasserstein GAN 但是也忠于论文原文, 是二者的二次消化.
对于一篇论文, 我们很需要对于其的直观理解, 这样不会被公式等另一个形式的语言吓到, 但是也需要回到论文原文, 这样可以对一些细致的工程实现更为明确. 我会尽可能遵循这点.
"散度"概念和损失函数变换
所谓"散度", 就是两个分布之间的"差异". 在信息论当中, 事件的概率分布对应了信息熵, 也就是表征一个概率分布至少需要的信息量. (海洋信息学居然会在这个奇怪的地方起作用hh) KL散度通过衡量对数差期望来衡量, 而JS散度为了让其对两个分布符合交换律, 能够用明确的距离表示而改变了形式. 其中: Pr表示实际分布, 而Pg表示生成器分布,PA为二者的中间分布.
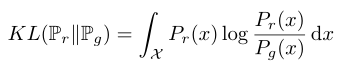
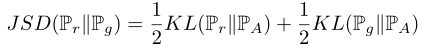
我们又知道损失函数公式的表达形式:
![]() (1)
(1)
实际中, 我们可以将上式对于D求导,并等于0求出极值:
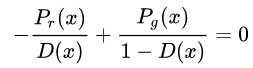 =>
=> 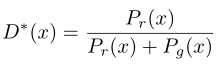 (2)
(2)
我们将(2)代入(1)可以知道:
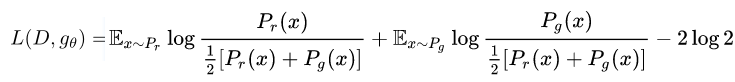 (3)
(3)
这就是两倍JS-2*log2. 需要注意的是, 这个逼近关系仅仅D接近于最优情况下有效, 也就是我们前面在GAN训练当中遇到的情况了(D收敛, G不收敛).
问题与吊打
为什么当D最优之后, 无法再给G提供有效信息呢? 因为此时, 我们再优化G, 相当于优化Pr和Pg的JS散度. 这看起来也没问题, 因为散度越小, 分布也就越接近. 然而, 假使此时Pg和Pr分离太大, 以致于互相之间还没来得及较大重合, 就导致了在相当大的范围内对于某个x, Pr -> 0 或者Pg -> 0. 所以在Pg ≠ 0 的范围内, Pr -> 0, 从而JS -> log2, 常数就导致了信息无法再获得. 当然这在论文中挺靠后的, 原文用很大一部分看似难理解的理论解释了为什么Pg和Pr的重叠不大的问题, 但是只要弄明白说了什么, 就不难.
很显然, 实际上Pr分布的维度远远不到图像像素数量这个级别的维度, 而Pg中, 原文也证明了其维度是达不到的. 这很好理解, 我们用了很低维度的噪声, 利用GAN可以直接生成一个图像. 随后, 论文也证明了: 在这样的情况下, 二者重叠部分的测度远远不能比比拟二者本身的测度, 好比一个三维空间中两个曲面中重叠, 几乎没有可能重叠一个面, 往往都是曲线相交, 而且一定有一个鉴别器将二者完美隔开, 只有个别点不成立. 这样子, 也自然难以获得明确的梯度了.
GAN函数的损失形式 - 从生成器G考虑
生成器的损失函数是:![]() ,这点我们在CS231N中知道, 我们希望最大化的目标是log D, 原因就是考虑梯度问题, 最大化就等于最小化相反数, 这也很自然.
,这点我们在CS231N中知道, 我们希望最大化的目标是log D, 原因就是考虑梯度问题, 最大化就等于最小化相反数, 这也很自然.
但是问题在于,我们首先知道了D的损失函数形式![]() , 所以我们对KL形式变换并对比:
, 所以我们对KL形式变换并对比:
![]()
于是: ![]()
后两项和G并没有任何关系. 其最大问题是:KL散度和JS散度符号相反, 结果一推一拉容易导致梯度不稳定. 而且, 因为KL(Pg || Pr)并非对称, 所以我们根据原始定义知道:
- Pg >> 0 但是 Pr -> 0: 此时KL项局部贡献达到无穷, 表明生成器生成了不真实的样本
- Pr >> 0 但是 Pg -> 0: 此时KL项局部贡献约为0, 表明生成器不去生成真实样本
因为KL贡献问题, 我们就知道, 生成器不会生成那些不真实样本, 但是此时Pr和Pg又相隔很远, 就是说, 大量的原始样本分布覆盖不到. 因为我们已经知道, Pr和Pg重叠部分测度为0, 所以生成器更倾向的就是那些部分了, 所以生成图片单调, 也就是所谓的mode collapse模式崩塌问题.
过渡解决方案
在原文中, 提到的方法是: 给生成样本和真实样本加噪声, 强行产生不可忽略重叠, 随后慢慢噪声退火, 直到两个分布重叠, 让JS散度起作用. 另外, 我们回顾上篇博客, 我们就知道, 大量的措施都是让D没那么完美, 防止D过拟合, 从而可以给G产生有效的梯度.
Wasserstein距离
所以总结一下, 其实说到底就是JS散度和KL散度本身的局限性, 其对于互不交叉的分布效果不好. 那要是真想搞出"远近"的区分, 就需要Wasserstein距离了.
原始公式为:![]()
这个公式的意义是: 将γ作为二者的联合分布(全部的集合), 上面的距离大概就是样本之间距离期望的下界, 我们理解为"样本之间距离期望"其实就可以了, 下界我个人认为是约束衡量标准的唯一性考量.
这个距离最大优越性在于哪怕不重叠, 也能得到明确的距离, 而且这个距离不会突变.但是其难点就是不方便计算, 为此原文转换了这个距离的形式:
![]()
其中sup的意义在于要求函数Lipschitz连续, 且系数为K. Lipschitz连续意思就是函数任意两点之间斜率绝对值不超过K这个常数, 也就表明这个函数必定一致连续. 这也就说明了, 判别器网络参数必须被限制在一个范围内(注意: 生成器不需要这个操作, 因为生成器本身并不影响W距离的计算过程, 不会导致连续性条件不成立).
在深度学习的背景下, 上面的公式变化为:
![]()
因此现在来说, WGAN目的就是缩短距离, 变成了回归任务(真假打分下的GAN严格来说也不算是回归,只是对分类的不同处理), 因此不能有sigmoid.
WGAN - GP : 更进一步
然而, WGAN仍然不完美. 其最大的问题在于直接限制了参数的取值范围, 这可能导致判别器无法拉大真假样本的距离, 有可能参数大量达到极限值, 而且可能导致梯度消失和梯度爆炸, 这些都源自于裁切的不连续性.
为此, 我们不再直接限制D网络参数范围, 而是在loss函数加入了梯度正则化惩罚项:
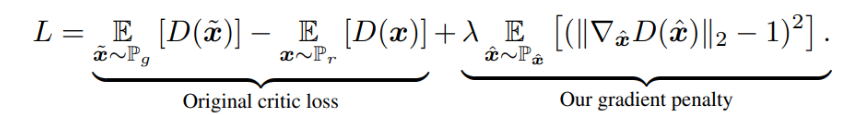
也因为这个操作, 我们现在的训练又可以使用Adam了.
下面是综合下来的具体方法:

由此, 我们将变化总结如下:
- D最后一层不要sigmoid
- 先训练数次D再训练G(注意是iteration而不是epoch)
- 误差项不要log, 同时加入梯度惩罚项
BAGAN细解
BAGAN被提出的目的很简单: 解决数据集数量太少或者不平衡的问题.
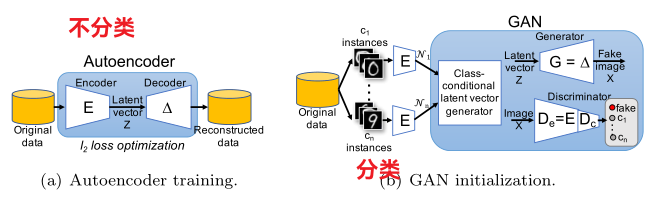
自编码器(AutoEncoder)
所谓自编码器, 其实就是用一个低维度的向量去表示一个高维度的信息. 在GAN当中我们利用噪声可以生成图像, 也就表明, 图像像素数量可能有很大的量级, 却可以被低维度的信息所表示, 比如长度为100的向量.
这个架构其实和通信是很像的, 理想情况下这应当是一个恒等变换.
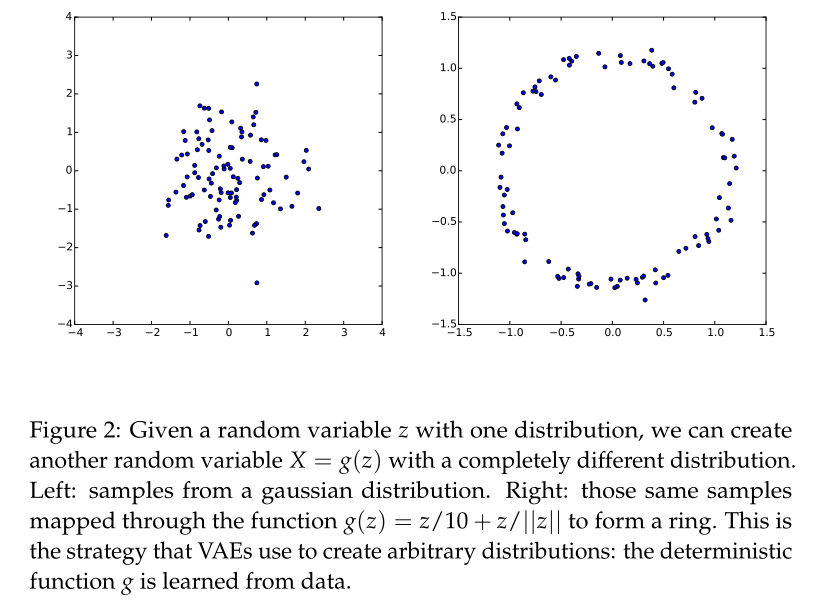
不过自编码器有一个很大的问题, 就是根据一个图片生成的编码向量并不是随机的, 所以我们不能随便找一个编码向量进行decode. 其中一个思路就是我们让编码的向量符合一个特别的数学规则, 比如高斯分布(VAE).
虽然BAGAN论文原文中并未直接提到VAE, 但是却说到了各个类图片的编码由均值向量(μ_c)和协方差矩阵(Σ_c)的高维高斯分布来拟合. 这用到了VAE的核心思想, 所以接下来我们需要好好研究VAE究竟是啥.
变分自编码器(VAE)
VAE是中国内地歌手, 代表作有<<有何不可>>,<<玫瑰花的葬礼>>等
有关于这个知识点, 其实有一篇专门的伪论文讲解, 也就是Tutorial on Variational Autoencoders(arxiv.org), 确实和前面那篇论文相比可以说很深入浅出了.
训练原理图也就是如下:
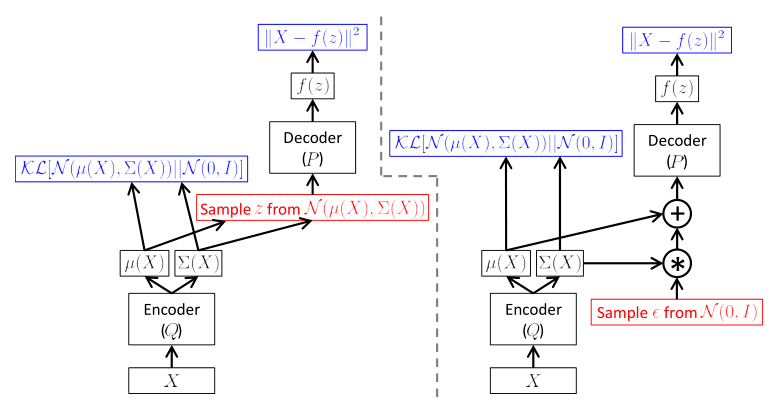
由此可以看出, 此时我们其实想做的就是传统的AE的思路, 不过我们希望将encoder尽可能训练成一个生成符合高斯分布的向量, 原因很简单, 高斯分布可以被映射成任意复杂的分布, 我们利用神经网络的强大拟合能力来做到.
需要注意的一点是: encoder不会直接输出z, 而是输出z应当具有的μ和Σ值.
随后, 我们只需要采样白噪声, 再乘上高斯分布的. 另外, 这里其实还做了一步, 因为传统的VAE并没有任何分类信息, 所以我们利用KL散度并优化它来让μ->零向量, Σ -> I. 在优化足够好的情况下, 我们只需要输入高斯白噪声就可以直接利用decoder来生成图像. 另外, 在BAGAN中, 输入却包含了分类, 这个时候对于每个类别就是采用了采样均值向量(μ_c)和协方差矩阵(Σ_c).
那么问题来了, 损失函数怎么计算呢?这就必须深入到VAE的原理了. VAE有一个基本的公式:
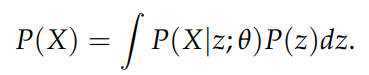
因为我们实际上并不能知道样本的分布具体函数式, 所以我们要做的就是希望在优化θ之后, 尽可能提高训练集上样本的分布概率.
虽然我们知道, 最终的VAE下z是高斯分布任取, 但是在分析和训练当中却并不是这样, 此时我们希望可以找到一些z, 它们更加可能对应样本的X的编码. 因此, 我们假设z ~ Q分布, 并希望其和X关联. 考虑到KL散度在计算分布距离优势, 于是有一个这样的公式:
![]()
但是P(z|X)目前还很难计算, 所以我们需要将先验和后验互相转换, 这很显然就是贝叶斯公式:
![]()
其中X不和z相关, 是一个常量, 所以可以被单独提取出来. 重新将上面的公式排列成散度, 就是最后的结果:
![]()
这个公式当中, 前面表示了我们希望在一定的z下最大化训练集样本X产生概率, 这就是decoder所做的事情, 而后者希望z在训练集样本给定下的分布接近我们自己给z的分布, 这样训练好之后我们就可以用制定的分布即更可能产生X, 这是encoder做的事情.
在实操过程中, 我们已经知道z的形式(不直接让z符合μ_c和Σ_c的原因是希望网络可导), 也即:
![]()
结合论文给出的训练示意图, 我们看到在更实际的操作中, 前者是我们通过z生成分布和实际分布的差距, 可以用两张图片的KL散度或者直接用两张图片的距离替代, 后者就是生成分布和标准分布的KL散度, 前面的Q这一项是从X经过解码器得到的z分布, 后者是我们希望z满足的分布, 也就是μ和Σ的高斯分布和标准高斯分布的KL散度, 其有明确的公式, 多维的计算方法在论文已经给出:
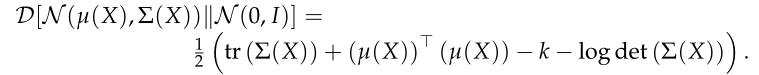
不过如果是一维的高斯分布, 还能更加简单, 公式结论如下:
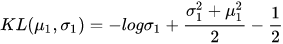
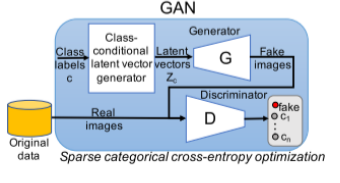
BAGAN的思想
BAGAN与ACGAN的区别主要在下面的地方:
- 直接架构来说, 不再像ACGAN那样有明显的真假分别的损失函数, 而是仅仅将fake和其他类别平行, 这样的目的是防止在少数类别中G倾向于生成真实但是不倾向于少数样本的结果, 其根源是在此时满足"真实"条件和满足样本分类正确难以同时满足
- 利用没有分类的encoder/decoder初始化网络D/G的一部分, 这样保证初始D和G不会明显偏向于某个类别样本. 从样本中直接采样高斯分布信息来对图像进行编码
- 随后输入样本再优化损失函数进行微调
实操部分
WGAN
我们已经明白了, WGAN虽然推导复杂, 但是最终要做的事情却很少. 因此, 想要改造的成本也很少.
我参照的实现是jackyjsy/ACWGAN(github.com), 包括其他修改也都是很明确的:
# discriminator定义
class Discriminator(nn.Module):
# 省略很多内容
def __init__(self, c_dim):
self.fc = nn.Linear(DISC_SIZE*16, 1)
self.classify = nn.Linear(DISC_SIZE*16, c_dim)
def forward(self, x):
h = self.model(x).view(-1,DISC_SIZE*16)
return self.fc(h), self.classify(h) # 看出真假判断不要Log
# ...
out_src, out_cls = self.D(real_x)
d_loss_real = - torch.mean(out_src)
d_loss_fake = torch.mean(out_src)
d_loss_cls = F.binary_cross_entropy_with_logits(
out_cls, real_c, size_average=False) / real_x.size(0) # 上面分类误差也不含log, 但是这个函数表明这一项并未受到WGAN影响
# 梯度惩罚项
alpha = torch.rand(real_x.size(0), 1, 1, 1).cuda().expand_as(real_x)
interpolated = Variable(alpha * real_x.data + (1 - alpha) * fake_x.data, requires_grad=True) # 掺杂部分真实和虚假数据生成梯度
# Variable这个没有任何意义, 据作者意思只是为了应付mypy的报错
out, out_cls = self.D(interpolated) # 对得到的样本获得一次结果
grad = torch.autograd.grad(outputs=out, # 利用这些样本得到梯度
inputs=interpolated,
grad_outputs=torch.ones(out.size()).cuda(), # 梯度计算每个的权重, 全部都是1
retain_graph=True, # 保留计算图
create_graph=True, # 计算计算图
only_inputs=True)[0] # 这个函数返回元组, 第一个元素是结果
grad = grad.view(grad.size(0), -1)
grad_l2norm = torch.sqrt(torch.sum(grad ** 2, dim=1)) # 计算grad的模. 对每个样本分别计算, 取均值, 因此dim=1
d_loss_gp = torch.mean((grad_l2norm - 1)**2) # 均值作为梯度
d_loss = self.lambda_gp * d_loss_gp
# G的训练损失区别, 没有梯度项
g_loss_fake = - torch.mean(out_src)
g_loss = g_loss_fake + self.lambda_cls * g_loss_cls考虑修改的幅度并不大, 所以我们直接在原本的ACGAN基础上修改. 分类误差表达和ACGAN没有任何区别, 但是在和判别损失相加的时候要乘上某个系数(我5和10都试了一遍, 10的效果略好于5). 此外, 原始的WGAN中建议每训练5次D训练一次G, 但是实践中发现在我们的项目中会导致D和G误差迅速发散, 为此我迷惑了好久, 最终发现是这里的问题. 其余我均采用论文默认参数, adam的lr均为0.0002.

可能是因为学习率下降和训练方式不同, 训练最开始的效果不是很好, 训练到1000 epoch之后, 和原始的ACGAN效果基本一致, 这其实倒也很显然, 因为毕竟原本的ACGAN经过精心调参过. 在原始的WGAN论文中, 为了证明WGAN的鲁棒性, 特意拿掉了全部的batchnorm层, 所以我们这里也这么做, 最终发现效果虽然变差了一些, 同样500个epoch附近效果区别并不明显.
VAE的初步搭建
下面的代码源自于 PyTorch实现VAE_vae pytorch实现-CSDN博客
class VAE(nn.Module):
# 本例子中encoder和decoder的架构仅用了全连接层, 事实上可以被设置为卷积层和反卷积层
# 这样更高级的架构
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
# 编码过程
def encode(self, x):
h = F.relu(self.fc1(x)) # 全连接层输入
return self.fc2(h), self.fc3(h) # 随后直接对输入样本通过全连接层输出均值向量和方差向量
# 随机生成隐含向量
def reparameterize(self, mu, log_var):
std = torch.exp(log_var/2) # 根据输入的std向量生成Σ.需要注意, 我们假设Σ是对角阵, 所以其维度和μ是相同的
eps = torch.randn_like(std)
return mu + eps * std
# 解码过程
def decode(self, z):
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h))
# 整个前向传播过程:编码-》解码
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
x_reconst = self.decode(z)
return x_reconst, mu, log_var由此我们看出, 实际上μ和Σ的生成压根不是对输出的总结, 而是硬生生猜出来的. 不过这其实也没事, 因为神经网络拟合能力实在是太强了.
下面是训练的大致架构, 可以看到实际上很简单, 剩下的就是常规的代码:
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
x_reconst, mu, log_var = model(x) # 输入一个已知样本, 输出重构,训练过程中还仅仅是普通的自编码器的逻辑
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False) # 两个图象的KL散度
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # encoder误差,也就是μ和Σ对于标准正态分布的KL散度我们仍然沿用了上一个专题的网络架构, 但是需要注意, 因为我们时从图像生成图像并进行比较, 所以我们必须将decoder的输出归一化到0~1范围内, 也就是说, tanh必须被更改为sigmoid.
在训练阶段, 我们可以根据输入图像分析出输出图像, 进入200个epoch之后损失减小开始放缓, 此时基本可以通过双盲.

但问题就是这是在依葫芦画瓢, 所以我们下面只使用训练好的decoder去分析. 于是就会发现, 因为没有分类, 导致字母之间产生了严重的混淆, 有较为明显的反卷积痕迹, 且实际上我们得到的图像分布应当是26个可能互不相交也可能有所连接的区域分布, 而VAE可能产生对分布之间的混淆. 不过既然原始分布符合正态分布, 理论上我们产生足够多的噪声, 就能获得需要的图像, 所以下面的多少也有几张能用, 但是这样搞效率未免也太低了.

BAGAN搭建
这里我参考了PyTorch implementation of BAGAN(github.com)的实现. 我们知道, 在这里G的结构应当和decoder完全一致, 并将G直接初始化为decoder, 而D在原本encoder之下, 还应当加上分类的全连接层.
因为部分结构不一致, 所以我们不能照搬着加载, 而只能选择性地对部分网络层权重加载进去. 所幸, pytorch提供了相应的方法, 就是将权重以字典地方式保存进去. 随后想要删去某层权重和加载某层权重, 只需要对字典操作就可以.
torch.save(model.state_dict(), 'model_name.pth') # 保存伪码
# 加载
state_e = torch.load('model_name.pth', )
del state_e['fc_z1.weight'] # 删除不需要的内容
del state_e['fc_z1.bias']
state_e.update({'fc_aux.weight':D.state_dict()['fc_aux.weight']}) # 更新需要的内容
state_e.update({'fc_aux.bias':D.state_dict()['fc_aux.bias']})
D.load_state_dict(state_e) # 加载本内容将在稍晚继续更新...