第一部分
深度优先搜索算法(以下简称DFS)是一种用于遍历(或搜索)树(或图)的算法。
我们构造这样一个图(如图1),并通过C++实现DFS
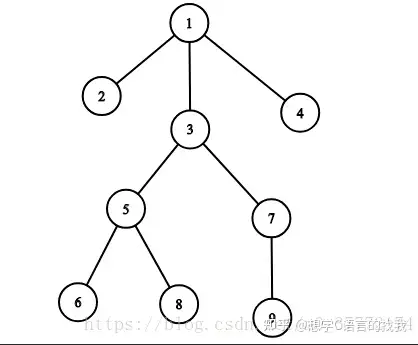
算法过程
1.从根节点开始
2.放入一个节点(起始时放入的为根节点)
3.如果这个节点是第一次出现,则放入堆栈中
4.判断该节点的子节点是否搜索完成,
a.如果是则将该节点出栈,判断该栈是否为空
a.1 若为空则结束
a.2 若不为空则取栈顶元素,并回到第2步
b.如果没有完成搜索,取未被搜索的根节点,并回到第2步
以下代码在vs2017中通过编译
#include<iostream>
#include<vector>
#include<stack>
#include<memory.h>
using namespace std;
vector<vector<int>> tree;//声明一个二维向量
int flag[10];//用于搜索到了节点i的第几个节点
stack <int>stk;//声明一个堆栈
int ar_tree[8] = { 1,1,1,3,5,3,5,7 };
void DFS(int node) {
cout << node <<" ";
if (flag[node] == 0) {
stk.push(node);
}
int temp;
//判断node的子节点是否搜索完成
if (flag[node] < tree[node].size()) {
temp = tree[node][flag[node]];
flag[node]++;
DFS(temp);
}
else {//若已经完成
stk.pop();//弹出子节点
if (!stk.empty()) {//若堆栈不为空
temp = stk.top();//取此时的栈顶元素,即为node的上一级节点
DFS(temp);
}
}
}
int main() {
ios::sync_with_stdio(false);
memset(flag, 0, sizeof(flag));
register int i,temp;
tree.resize(10);//图中的数共有九个节点
//生成树
for (i = 2; i <=9; i++) {
temp = ar_tree[i - 2];
tree[temp].push_back(i);//表示第i个节点为第temp个节点的子节点
}
//DFS
cout << "DFS过程:" << endl;
DFS(1);
cout << endl;
return 0;
}
输入结果如下:
事实上,DFS函数可以通过更短的代码实现,如下
void DFS(int node) {
cout << node << " ";
for (int c : tree[node]) {
DFS(c);
}
}
不过,依赖二叉树等数据结构实现的深度优先搜索算法,会更加简明
第二部分
深度优先搜索是将当前状态按照一定的规则顺序,先拓展一步得到一个新状态,再对这个新状态递归拓展下去。如果无法拓展,则退回一步到上一个状态,再按照原先设定的规则顺序重新寻找一个状态拓展。如此搜索,直至找到目标状态,或者遍历完所有状态。所以,深度优先搜索也是一种“盲目”搜索。
图9.10-1所示的一个“无向图”,从顶点V0开始进行深度优先搜索,得到的一个序列为:V0,V1,V2,V6,V5,V3,V4。
一、深度优先搜索的算法框架
深度优先搜索(Depth First Search,DFS),简称深搜,其状态“退回一步”的顺序符合“后进先出”的特点,所以采用“栈”存储状态。深搜适用于要求所有解方案的题目。
深搜可以采用直接递归的方法实现,其算法框架如下
二、 深度优先搜索应用举例
1、瓷砖
【问题描述】
在一个 w×h 的矩形广场上,每一块 1×1 的地面都铺设了红色或黑色的瓷砖。小林同学站在某一块黑色的瓷砖上,他可以从此处出发,移动到上、下、左、右四个相邻的且是黑色的瓷砖上。现在,他想知道,通过重复上述移动所能经过的黑色瓷砖数。
【输入格式】
第 1 行为 h、w,2≤w、h≤50,之间由一个空格隔开。
以下为一个 w 行 h 列的二维字符矩阵,每个字符为“.”“#”“@”,分别表示该位置为黑色的瓷砖、红色的瓷砖,以及小林的初始位置。
【输出格式】
输出一行一个整数,表示小林从初始位置出发可以到达的瓷砖数。
【输入输出样例】
11 9
.#.........
.#.#######.
.#.#.....#.
.#.#.###.#.
.#.#..@#.#.
.#.#####.#.
.#.......#.
.#########.
...........
【问题分析】
设 ans 表示小林从初始位置出发可以经过的黑色瓷砖数,初始值为 0,从小林的初始位置“@”开始深度优先搜索,ans++,再把该位置设置为红色(已走过),然后穷举其上、下、左、右四个位置是否是黑色瓷砖。是,则递归搜索。
2、 最大黑区域
【问题描述】
二值图像是由黑白两种像素组成的矩形点阵,图像识别的一个操作是求出图像中最大黑区域的面积。请设计一个程序完成二值图像的这个操作。黑区域由黑像素组成,一个黑区域中的每像素至少与该区域中的另一像素相邻,规定一个像素仅与其上、下、左、右的像素相邻。两个不同的黑区域没有相邻的像素。一个黑区域的面积是其所包含的像素数。
【输入格式】
第 1 行含两个正整数 n 和 m,1≤n、m≤100,分别表示二值图像的行数与列数,后面紧跟着n 行,每行含 m 个整数 0 或 1,其中第 i 行表示图像的第 i 行的 m 个像素,0 表示白像素,1 表示黑像素。
【输出格式】
输出一个数,表示相应的图像中最大黑区域的面积。
【输入样例】
5 6
0 1 1 0 0 1
1 1 0 1 0 1
0 1 0 0 1 0
0 0 0 1 1 1
1 0 1 1 1 0
【输出样例】
7
【问题分析】
从左上角开始,利用一个两重循环穷举找到一个黑点(a[i,j]=1),然后 dfs(i,j),dfs 到的点置为 0,一次 dfs 完毕得到一个返回值 s,就是这个黑区域的面积,再通过打擂台,记录每一个黑区域的 s 最大值作为答案 ans。
3、数的拆分
【问题描述】
输入一个整数 n,输出 n 拆分成若干正整数和的所有方案,即 n=S 1 +S 2 +…+S k 的形式,且S 1 ≤S 2 ≤…≤S k ,n≤20,请按照字典序输出。
【输入格式】
一行一个整数 n。
【输出格式】
所有拆分方案,具体格式参见输出样例。
【输入样例】
4
【输出样例】
1+1+1+1
1+1+2
1+3
2+2
4
total=5
【问题分析】
分析对比 5 的拆分和 4 的拆分,可以发现:对于 n>m,n 的拆分和 m 的拆分本质上是一样的,可以把 n 的拆分看成先拆出一个数 i (1<i<n),然后再对剩下的 n-i 递归拆分。
设 rest 表示拆分后的余数,s 数组用来存储拆分的方案。显然,当 rest=0 的时候,就应该输出当前的一种拆分方案。题目规定 S 1 ≤S 2 ≤…≤S k 。显然,S k+1 的范围应该从 S k 到 rest。
4、背包问题
【问题描述】
小明就要去春游了。妈妈给他买了很多好吃的。小明想把这些吃的都放进他的书包,但他很快发现,妈妈买的东西实在太多了,他必须放弃一些,但又希望能带尽可能多的好吃的。举算法解决一些实际问题。
已知小明的书包最多可以装入总重量为 s 的物品,同时也知道小明妈妈给他买的每样东西的重量。请从这些好吃的中选出若干装入小明的书包中,使得装入物品的总重量正好为 s。找到任意一组解输出即可。
【输入数据】
第 1 行包含两个正整数 n(1≤n≤100)和 s(1≤s≤10 000),分别代表有 n 件物品和书包的最大承重 s;
第 2 行包含 n 个正整数,代表每件物品的重量 W i (1≤W i ≤1 000)。同行的两个数字之间用一个空格隔开。
【输出数据】
一行包含有若干用一个空格隔开的正整数,代表被放入书包的若干物品各自的重量。若无可行解,则输出“No Answer !”。
【输入样例】
8 14
1 3 2 5 9 4 7 6
【输出样例】
1 3 4 6
【输入样例】
3 12
2 8 5
【输出样例】
No Answer!
【问题分析】
本题是最简单的“0-1 背包问题”。只要从第一件物品开始,考虑取和不取两种情况,进行递归深搜,一旦发现装入物品的总重量等于背包的容量,就输出答案。
此算法的时间复杂度为O(2^n ),对于 n=100,显然会超时。我们将在后面专门讨论解决 0-1 背包问题的其他算法。
5、体积
【问题描述】
给出 n 件物品,每件物品有一个体积 V i ,求从中取出若干件物品能够组成的不同的体积和有多少种可能。
【输入格式】
第 1 行 1 个正整数,表示 n。
第 2 行 n 个正整数,表示 V i ,每两个数之间用一个空格隔开。
【输出格式】
一行一个数,表示不同的体积和有多少种可能。
【输入样例】
3
1 3 4
【输出样例】
6
【数据规模】
对于 30% 的数据满足:n≤5,V i ≤10。
对于 60% 的数据满足:n≤10,V i ≤20。
对于 100% 的数据满足:n≤20,1≤V i ≤50。
三、深度优先搜索中的剪枝优化
在深度优先搜索的过程中,如果发现以当前状态往下搜索,不可能得到解或者最优解,那么就应该及时“后退”,避免搜索当前结点(状态)下面的“子搜索树”,以减少搜索时间,提高搜索效率。这种思想称为搜索“剪枝”。这跟走迷宫时提前判断出“死胡同”,不走冤枉路一个意思。
6、门票问题
【问题描述】
有很多人在门口排队,每个人将会被发到一个有效的通行密码作为门票。一个有效的密码由 L(3≤L≤15)个小写英文字母组成,至少有一个元音(a、e、i、o 或 u)和两个辅音(除去元音以外的音节),并且是按字母表顺序出现的(例如 abc 是有效的,而 bac 不是)。
现在给定一个期望长度为L和C(1≤C≤26)个小写字母,写一个程序,输出所有的长度为L、能由所给定的 C 个字母组成的有效密码。密码必须按字母表顺序打印出来,一行一个。
【输入格式】
第 1 行是两个由一个空格分开的正整数,L 和 C,3≤L≤15,1≤C≤26。
第 2 行是 C 个由一个空格隔开的小写字母,密码是由这个字母集中的字母来构建的。
【输出格式】
若干行,每行输出一个长度为 L 个字符的密码(没有空格)。输出行必须按照字母顺序排列。
程序只需要输出前 25 000 个有效密码,即使后面还存在有效密码。
【输入样例】
4 6
a t c i s w
【输出样例】
acis
Acit
aciw
acst
acsw
actw
aist
aisw
aitw
astw
cist
cisw
citw
istw
【问题分析】
设 len 表示读入(要生成)的串长,num 表示字符的总个数。因为所有的密码都要按字典序输出,所以对读入的所有字符 a[i]按升序排列。为了处理方便,再设 b[i]表示数组 a 中位置 i 及之后还有几个元音。
采用深度优先搜索,设 dfs(x,y,n1,n2,s)表示搜到第 x 个字符,即将生成的字符串长度为y,至少还要 n1 个元音和 n2 个辅音,生成的字符串为 s,则可以得到以下代码:
void dfs(int x,y,n1,n2; string s)
{ if(y = =len+1)
{ 输出 s;
计数器加 1, 如果等于 25000 就中止程序 ;
}
else if (a[i] 是元音) dfs(x+1,y+1,n1-1,n2,s+a[x]) ;
else dfs(x+1,y+1,n1,n2-1,s+a[x]) ;
}
直接调用 dfs(1,1,1,2, ‘ ’ )即可。但是,运行程序发现超时严重。下面考虑对递归代码(红色部分)进行适当的剪枝优化。
(1)如果接下来的字母全用上但长度也不够,则剪枝,也就是 num-x<len-(y-1)。
(2)如果接下来没有元音且之前没有用过元音,则剪枝,也就是(b[x+1]=0)且(n1=1),或者简化成 b[x+1]<n1。
(3)如果接下来的辅音全取完再加上之前取的辅音也不够 2 个,则剪枝,也就是(num-x-b[x+1])+(2-n2)<2,化简为 num-x-b[x+1]<n2。
红色部分的递归代码优化为:
if(a[x] 是元音 )
if((len-y >= n2) && (num-x-b[x+1] >= n2)) dfs(x+1,y+1,n1-1,n2,s+a[x]);
else
if((len-y >= n1) && (b[x+1] >= n1)) dfs(x+1,y+1,n1,n2-1,s+a[x]);
if((num-x >= len-y+1) && (b[x+1] >= n1) && (num-x-b[x+1] >= n2)) dfs(x+1,y,n1,n2,s);
四、搜索中的回溯法
“回溯法”也称“试探法”。它是从问题的某一状态出发,不断“试探”着往前走一步,当一条路走到“尽头”,不能再前进(拓展出新状态)的时候,再倒回一步或者若干步,从另一种可能的状态出发,继续搜索,直到所有的“路径(状态)”都一一试探过。这种不断前进、不断回溯,寻找解的方法,称为“回溯法”。
深度优先搜索求解的时候,当找到目标结点之后,还要回头寻找初始结点到目标结点的解路径。而回溯法则不同,找到目标结点之后,搜索路径就是一条从初始结点到目标结点的解路径。回溯法实际上是状态空间搜索中,深度优先搜索的一种改进,是更实用的一种搜索求解方法。
1、深度优先搜索与回溯法的关系
1)深度优先搜索包含回溯,或者说回溯法是深度优先搜索的一种。
2)深度优先搜索需要控制如何实现状态之间的转移(拓展),回溯法就是深度优先搜索的一种控制策略。
3)回溯的过程中,并不需要记录整棵“搜索树”,而只需记录从初始状态到当前状态的一条搜索路径,是“线性链状”的,其最大优点是占用空间少。
4)深度优先搜索可以采用递归(系统栈)和非递归(手工栈)两种方法实现。递归搜索是系统栈实现一部分的回溯(如果需要记录一些特殊信息或较多的信息,还需要另外手工记录),而非递归是自己用手工栈模拟回溯的过程,所以实现起来略为复杂一点。
2、
递归回溯法算法框架[一]
递归回溯法算法框架[二]
1、P1238 走迷宫
题目描述
有一个 m×n 格的迷宫(表示有 m 行、n 列),其中有可走的也有不可走的,如果用 1 表示可以走,0 表示不可以走,文件读入这 m×n 个数据和起始点、结束点(起始点和结束点都是用两个数据来描述的,分别表示这个点的行号和列号)。现在要你编程找出所有可行的道路,要求所走的路中没有重复的点,走时只能是上下左右四个方向。如果一条路都不可行,则输出相应信息(用 −1 表示无路)。
优先顺序:左上右下。数据保证随机生成。
输入格式
第一行是两个数 m,n(1<m,n<15),接下来是 m 行 nn 列由 1 和 0 组成的数据,最后两行是起始点和结束点。
输出格式
所有可行的路径,描述一个点时用 (x,y) 的形式,除开始点外,其他的都要用 -> 表示方向。
如果没有一条可行的路则输出 −1。
输入输出样例
输入
5 6
1 0 0 1 0 1
1 1 1 1 1 1
0 0 1 1 1 0
1 1 1 1 1 0
1 1 1 0 1 1
1 1
5 6
输出
(1,1)->(2,1)->(2,2)->(2,3)->(2,4)->(2,5)->(3,5)->(3,4)->(3,3)->(4,3)->(4,4)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(2,4)->(2,5)->(3,5)->(3,4)->(4,4)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(2,4)->(2,5)->(3,5)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(2,4)->(3,4)->(3,3)->(4,3)->(4,4)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(2,4)->(3,4)->(3,5)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(2,4)->(3,4)->(4,4)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(3,3)->(3,4)->(2,4)->(2,5)->(3,5)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(3,3)->(3,4)->(3,5)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(3,3)->(3,4)->(4,4)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(3,3)->(4,3)->(4,4)->(3,4)->(2,4)->(2,5)->(3,5)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(3,3)->(4,3)->(4,4)->(3,4)->(3,5)->(4,5)->(5,5)->(5,6)
(1,1)->(2,1)->(2,2)->(2,3)->(3,3)->(4,3)->(4,4)->(4,5)->(5,5)->(5,6)
说明/提示
数据保证随机生成。事实上,如果n=m=14 且每个位置都是 11 的话,有 6945066476152136166427470154890735899648869450664761521361664274701548907358996488 种路径。
2、P1036 [NOIP2002 普及组] 选数
题目描述
已知 n 个整数 x1,x2,…,xn,以及1个整数k(k<nk<n)。从n个整数中任选k个整数相加,可分别得到一系列的和。例如当n=4,k=3,4个整数分别为3,7,12,19时,可得全部的组合与它们的和为:
3+7+12=22
3+7+19=29
7+12+19=38
3+12+19=34。
现在,要求你计算出和为素数共有多少种。
例如上例,只有一种的和为素数:3+7+19=29。
输入格式
键盘输入,格式为:
n,k(k<n1≤n≤20,k<n)
x1,x2,…,xn(1≤xi≤5000000)
输出格式
屏幕输出,格式为: 1个整数(满足条件的种数)。
输入输出样例
输入
4 3
3 7 12 19
输出
1
说明/提示
【题目来源】
NOIP 2002 普及组第二题
3、数的拆分
【问题描述】
输入 n,输出将 n 拆分成若干正整数和的所有方案,即 n=S 1 +S 2 +…+S k 的形式,且 S 1 ≤S 2 ≤…≤S k ,n≤20,请按照字典序输出。
【输入格式】
一行一个整数 n。
【输出格式】
所有拆分方案,具体格式参见输出样例。
【输入样例】
4
【输出样例】
1+1+1+1
1+1+2
1+3
2+2
4
total=5
【问题分析】
与深度优先搜索的方法类似,从 dep=1 开始,每次 dfs(dep)先拆出一个数 i,记录下来,并且修改余数 rest=rest-i,然后 dfs(dep+1)去递归拆分下去,只是每次递归结束后需要做回溯操作,即 rest=rest+i。
4、选排列的生成
【问题描述】
设有 n 个整数的集合 {1,2,3,…,n},从中取出任意 r 个数进行排列(0<r<n<20),编程输出所有的排列方案。请按照字典序输出。
【输入格式】
一行两个整数 n 和 r,之间用一个空格隔开。
【输出格式】
所有排列方案,具体格式参见输出样例。
【输入样例】
4 2
【输出样例】
1 2
1 3
1 4
2 1
2 3
2 4
3 1
3 2
3 4
4 1
4 2
4 3
total=12
【问题分析】
复述一下题意就是:r 个位置,每个位置放一个 1~n 之间的整数,要求每个数不能重复,输出所有的排列方案。
可以从第 1 个位置开始,每个位置放置数 k,k 从 1 开始不断尝试直到 n,如果能放(没用过)就放,放好后再尝试下一个位置,如果第 r 个位置也放好了,则说明一种方案已经形成,则输出一种方案、计数,继续寻找下一种方案(回溯)。如果不能放置(该数已用过)就换放下一个数,如果 k大于 n 了,表示不能继续放下去了,则回溯。一个数有没有用过,只要开一个哈希表判断即可。
5、N 皇后问题
【问题描述】
要在 N×N(N≤8)的国际象棋棋盘中放 N 个皇后,使得任意两个皇后都不能互相吃(提示:皇后能吃同一行、同一列、同一对角线的其他皇后)。
请问有多少种方案,并按字典序输出所有的方案。每种方案输出每一行皇后的纵坐标(场宽为 5),如果无解,则输出“no solute!”。
【输入格式】
一行一个整数 N。
【输出格式】
每行对应一种方案,具体格式参见输出样例。
【输入样例】
4
【输出样例】
2 4 1 3
3 1 4 2
记忆化搜索
1、P1434 [SHOI2002]滑雪
题目描述
Michael 喜欢滑雪。这并不奇怪,因为滑雪的确很刺激。可是为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你。Michael 想知道在一个区域中最长的滑坡。区域由一个二维数组给出。数组的每个数字代表点的高度。下面是一个例子:
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
一个人可以从某个点滑向上下左右相邻四个点之一,当且仅当高度会减小。在上面的例子中,一条可行的滑坡为 24-17-16-1(从 24 开始,在 1 结束)。当然 25-24-23-…-3-2-1 更长。事实上,这是最长的一条。
输入格式
输入的第一行为表示区域的二维数组的行数 R 和列数 C。下面是 R 行,每行有 C 个数,代表高度(两个数字之间用 1 个空格间隔)。
输出格式
输出区域中最长滑坡的长度。
输入输出样例
输入
5 5
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
输出
25
说明/提示
对于 100% 的数据,1≤R,C≤100。
2、P7074 [CSP-J2020] 方格取数
题目描述
设有 n×m 的方格图,每个方格中都有一个整数。现有一只小熊,想从图的左上角走到右下角,每一步只能向上、向下或向右走一格,并且不能重复经过已经走过的方格,也不能走出边界。小熊会取走所有经过的方格中的整数,求它能取到的整数之和的最大值。
输入格式
第一行有两个整数 n,m。
接下来 n 行每行 m 个整数,依次代表每个方格中的整数。
输出格式
一个整数,表示小熊能取到的整数之和的最大值。
输入输出样例
输入
3 4
1 -1 3 2
2 -1 4 -1
-2 2 -3 -1
输出
9
输入
2 5
-1 -1 -3 -2 -7
-2 -1 -4 -1 -2
输出
-10
说明/提示
样例 1 解释
样例 2 解释
数据规模与约定
对于 20% 的数据,n,m≤5。
对于40% 的数据,n,m≤50。
对于 70% 的数据,n,m≤300。
对于 100% 的数据,1≤n,m≤10^3。方格中整数的绝对值不超过 10^4。
P3956 [NOIP2017 普及组] 棋盘
题目描述
有一个m×m的棋盘,棋盘上每一个格子可能是红色、黄色或没有任何颜色的。你现在要从棋盘的最左上角走到棋盘的最右下角。
任何一个时刻,你所站在的位置必须是有颜色的(不能是无色的), 你只能向上、 下、左、 右四个方向前进。当你从一个格子走向另一个格子时,如果两个格子的颜色相同,那你不需要花费金币;如果不同,则你需要花费 1个金币。
另外, 你可以花费 2 个金币施展魔法让下一个无色格子暂时变为你指定的颜色。但这个魔法不能连续使用, 而且这个魔法的持续时间很短,也就是说,如果你使用了这个魔法,走到了这个暂时有颜色的格子上,你就不能继续使用魔法; 只有当你离开这个位置,走到一个本来就有颜色的格子上的时候,你才能继续使用这个魔法,而当你离开了这个位置(施展魔法使得变为有颜色的格子)时,这个格子恢复为无色。
现在你要从棋盘的最左上角,走到棋盘的最右下角,求花费的最少金币是多少?
输入格式
第一行包含两个正整数m,n,以一个空格分开,分别代表棋盘的大小,棋盘上有颜色的格子的数量。
接下来的n行,每行三个正整数x,y,c, 分别表示坐标为(x,y)的格子有颜色c。
其中c=1 代表黄色,c=0 代表红色。 相邻两个数之间用一个空格隔开。 棋盘左上角的坐标为(1, 1),右下角的坐标为(m,m)。
棋盘上其余的格子都是无色。保证棋盘的左上角,也就是(1,1) 一定是有颜色的。
输出格式
一个整数,表示花费的金币的最小值,如果无法到达,输出−1。
输入输出样例
输入
5 7
1 1 0
1 2 0
2 2 1
3 3 1
3 4 0
4 4 1
5 5 0
输出
8
输入
5 5
1 1 0
1 2 0
2 2 1
3 3 1
5 5 0
输出
-1
说明/提示
输入输出样例 1 说明
从(1,1)(1,1)开始,走到(1,2)(1,2)不花费金币
从(1,2)(1,2)向下走到(2,2)(2,2)花费 11 枚金币
从(2,2)(2,2)施展魔法,将(2,3)(2,3)变为黄色,花费 22 枚金币
从(2,2)(2,2)走到(2,3)(2,3)不花费金币
从(2,3)(2,3)走到(3,3)(3,3)不花费金币
从(3,3)(3,3)走到(3,4)(3,4)花费 11 枚金币
从(3,4)(3,4)走到(4,4)(4,4)花费 11 枚金币
从(4,4)(4,4)施展魔法,将(4,5)(4,5)变为黄色,花费22 枚金币,
从(4,4)(4,4)走到(4,5)(4,5)不花费金币
从(4,5)(4,5)走到(5,5)(5,5)花费 11 枚金币
共花费 88枚金币。
输入输出样例 2 说明
从( 1, 1)(1,1)走到( 1, 2)(1,2),不花费金币
从( 1, 2)(1,2)走到( 2, 2)(2,2),花费11金币
施展魔法将( 2, 3)(2,3)变为黄色,并从( 2, 2)(2,2)走到( 2, 3)(2,3)花费22 金币
从( 2, 3)(2,3)走到( 3, 3)(3,3)不花费金币
从( 3, 3)(3,3)只能施展魔法到达( 3, 2),( 2, 3),( 3, 4),( 4, 3)(3,2),(2,3),(3,4),(4,3)
而从以上四点均无法到达( 5, 5)(5,5),故无法到达终点,输出-1−1
数据规模与约定
对于 30%的数据, 1≤m≤5,1≤n≤10。
对于 60%的数据, 1≤m≤20,1≤n≤200。
对于 100%的数据, 1≤m≤100,1≤n≤1,000。