原始题目:Accuracy of real-time multi-model ensemble forecasts for seasonal influenza in the U.S.
中文翻译:针对美国季节性流感的实时多模型集合预报的准确性
发表时间:2019年11月22日
*台:PLOS Computational Biology
文章链接:https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1007486
开源代码:https://github.com/FluSightNetwork/cdc-flusight-ensemble
摘要
季节性流感在美国和全世界造成很高的年发病率和死亡率。准确预测流感流行的关键特征,例如特定季节发病高峰的时间和严重程度,可以为公共卫生应对疫情提供信息。作为将数据和先进分析方法纳入公共卫生决策的持续努力的一部分,美国疾病控制和预防中心(CDC)自2013/2014季节以来组织了季节性流感预测挑战。在2017/2018赛季,有22支队伍参加。我们的团队在2017年初创建了一个名为FluSight Network的研究联盟。在2017/2018赛季,他们共同制作了协作的多模型集成,使用称为堆叠的机器学习技术将21个单独的组件模型组合成一个模型。这种方法创建了预测密度的加权*均值,其中每个组件的权重是通过最大化过去季节的整体集成精度来确定的。在2017/2018流感季节,这是过去15年来最大的季节性爆发之一,这个多模型集合的*均表现优于所有单个组件模型,并在CDC挑战中排名第二。它还优于CDC创建的基线多模型集合,该集合采用提交给预测挑战的所有模型的简单*均值。该项目表明,研究团队之间为开发集成预测方法而进行的协作努力可以带来可衡量的预测准确性改进,并显着降低性能的逐年变化。诸如此类的努力强调预测模型的实时测试和评估,并促进公共卫生官员和建模研究人员之间的密切合作,对于提高我们对如何最好地使用预测来改善公共卫生对季节性和新出现的流行病威胁的反应的理解至关重要。
1. 引言
季节性流感在美国和全世界造成巨大的年度公共卫生负担。美国疾病控制与预防中心(CDC)估计,从2017年10月至2018年5月,美国有4880万例流感病例,959,000例流感相关住院治疗,*80,000例流感相关死亡,使2017/2018年是有记录以来最大的季节之一[1]。CDC利用多种监测方法来评估流感季节的严重程度,包括监测ILI的门诊就诊、流感相关住院和病毒学检测[2]。然而,与所有监测系统一样,这些记录仅描述了已经发生的事件的样本,并且对未来流行的时间或严重程度的指示有限,这些时间或严重程度可能因季节而异[3]。对流感季节的预测提供了提供关于未来流感活动的可操作信息的可能性,这些信息可用于改善公共卫生应对措施。*年来,同行评议的季节性流感预测研究大幅增加[4-11]。
长期以来,多模型集成,即结合了来自多个不同组件模型的预测的模型,一直被认为比任何单一模型都具有理论和实践优势[12-15]。首先,它允许单个预测合并来自不同数据源和模型的信号,这些信号可能会突出系统的不同特征。其次,组合来自具有不同偏差的模型的信号可能会使这些偏差偏移,并产生比单个集成组件更准确且方差更低的集成。天气和气候模型已将多模式集合系统用于建模[16-19],最*的工作已将集合预测扩展到传染病,包括流感、登革热、淋巴丝虫病和埃博拉出血热[20-23]。在整个手稿中,我们将使用术语集成来泛指这些多模型集成方法。
自2013/2014流感季节以来,疾病预防控制中心与外部研究人员合作举办了年度前瞻性流感预测竞赛,称为FluSight挑战赛。这些挑战为政府公共卫生官员与学术和私营部门研究人员之间的密切互动与合作提供了途径。在*年来政府赞助的其他传染病预测竞赛中,[24,25]这一挑战在多个爆发季节的前瞻性方向上是独一无二的。从11月初到5月中旬,参赛团队每周提交各种流感相关目标的概率预测。在2015/2016和2016/2017 FluSight挑战期间,CDC的分析师通过对所有提交的模型进行未加权*均值来构建一个简单的集成模型。该模型是每个赛季表现最好的模型之一[26]。
多年来,FluSight挑战赛经过精心设计和重组,旨在最大限度地提高公共卫生效用,并将预测与实时公共卫生决策相结合。所有预测目标均来自通过美国门诊流感样疾病监测网络(ILINet)收集的流感样疾病门诊就诊(wILI)的加权百分比,并按州人口加权(图1B和1C)。流感样疾病是流行病学监测中最常用的流感活动指标之一。FluSight挑战赛的每周提交包含美国11个地区(国家级加上10个卫生与公众服务(HHS)地区,图1A)中每个地区的七个目标的概率和点预测。目标分为两类:“未来一周”和“季节性”。“未来一周”目标是指四个短期的每周目标(未来 ILI 百分比 1、2、3 和 4 周),这些目标在季节的每一周都不同。“季节性”目标是指代表在一个季节观察到的单个结果的数量(暴发开始周、暴发高峰周和暴发高峰强度)(见方法)。
2017年3月,过去曾与CDC合作的流感预报员被邀请加入建立FluSight网络。该研究联盟在 2017 年和 2018 年通力合作,构建和实施具有基于性能的模型权重的实时多模型集成。FluSight 网络的一个中心目标是通过优于 CDC 在年度流感季节用于为决策和态势感知提供信息而使用的“简单*均”集成,在实时、多团队集合设置中展示基于性能的权重的好处。CDC使用该项目实时评估根据过去的表现创建集成预测的可行性和准确性。根据本实验中显示的预测准确性,CDC决定采用此处描述的方法作为2018/2019流感季节的主要预测方法。
在本文中,我们描述了这种协作式多模式集合的发展,并介绍了七个回顾季节和一个预期季节的预测结果。FluSight网络组装了21个组件预报系统,为季节性流感爆发建立多模式集合(表Ain S1文本)。这些组件包含各种不同的建模理念,包括贝叶斯分层模型、传染病传播的机制模型、统计学习方法和时间序列数据的经典统计模型。我们表明,与使用任何单一模型和不考虑过去表现的多模型融合相比,使用由过去性能告知的多模型集成始终可以提高预测准确性。鉴于该实验的时间安排,在特别严重的流感季节,这项工作还提供了实时预测研究的第一个证据,即基于性能的权重可以在高严重程度传染病爆发期间提高集成预测的准确性。这项研究是政府与学术公共卫生专家合作的一个重要例子,为未来疫情(如全球流感大流行)的实时合作开创了先例和原型。
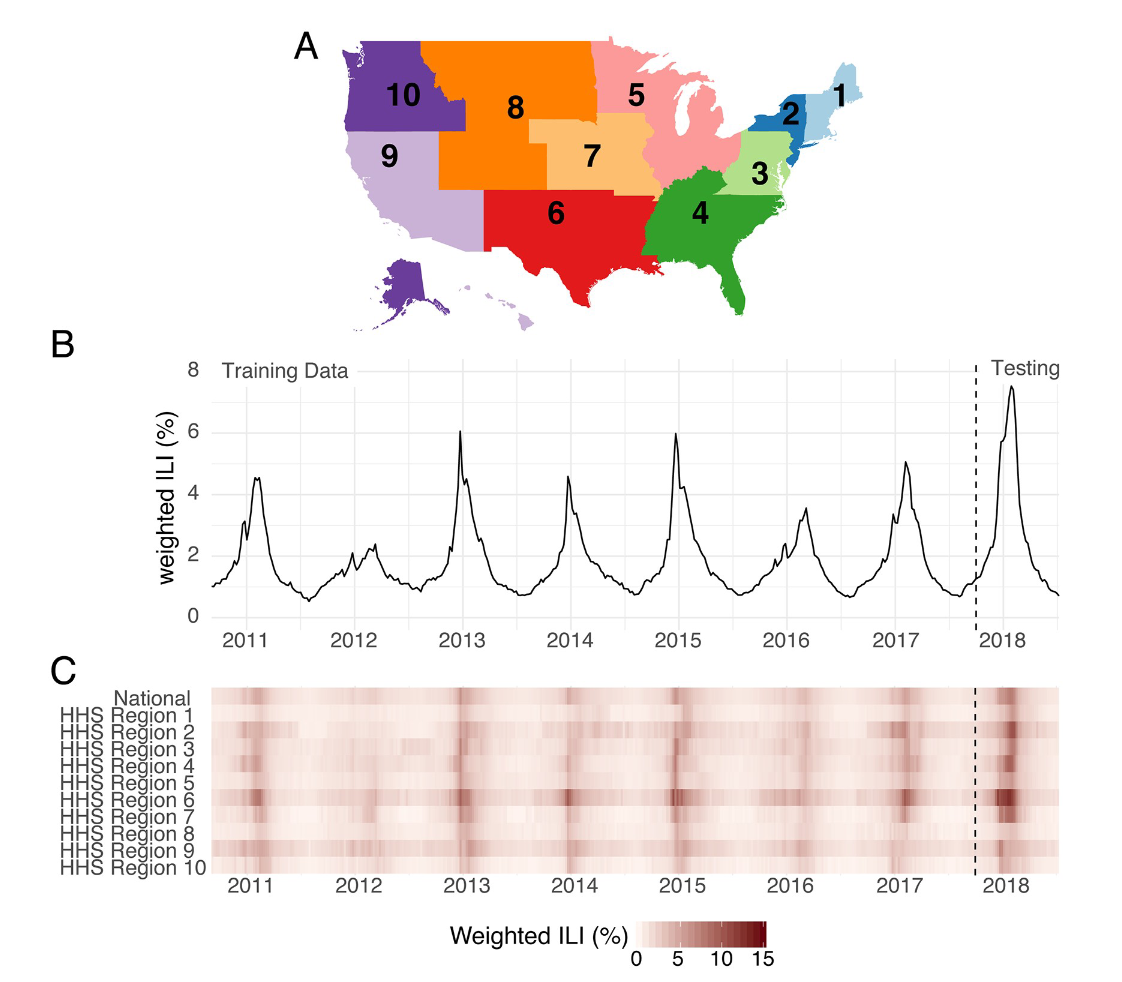
图1.美国区域级流感监测数据概述。(A) 美国10个卫生与公众服务地区的地图。流感预报是在这个地理尺度进行的。(B)来自CDC网站的国家级公开wILI数据。y 轴显示从 2010 年 9 月到 2018 年 7 月期间每周 apatien 出现流感样疾病的医生就诊的估计百分比。垂直虚线表示此处介绍的模型用于分析的训练(回顾)和测试(预期)阶段的数据的分离。(C) 国家一级和10个HHS区域中每个区域的公开可用的wILI数据。颜色越深表示 wILI 越高。
2. 结果
2.1 集成组件摘要
21个单独的组件模型拟合历史数据,并用于在七个训练季节(2010/2011-2016/2017,表A 在S1文本)进行前瞻性预测。他们的预测准确性因地区、季节和目标而异。组件模型预测性能的详细比较分析可以在其他地方找到[27];但是,在这里我们总结了一些关键见解。非季节性基线模型,其对特定目标的预测基于前几个季节的数据,不根据当前季节的数据进行更新,被用作所有组成部分模型的参考点。超过50%的单个组件模型在预测提前1周、2周和3周的发病率以及季节高峰百分比和季节高峰周方面优于季节性基线模型。然而,相对预测表现的季节间差异很大。例如,10 个组件模型在至少一个季节中的整体精度高于所有季节*均性能最佳的模型。为了评估模型的准确性,我们遵循CDC惯例,并使用一个指标,该度量将最终观测值周围分配给小范围的概率的几何*均值。该度量,我们称为“预测分数”,可以解释为给定预测模型分配给CDC认为准确的值的*均概率(参见方法)。因此,在 0 到 1 的范围内,值越高,表示模型越准确。
2.2 基于交叉验证的集成模型选择
在对前几个赛季和2017/2018赛季之前的集成组件表现进行系统评估之前,我们预先指定了五种候选集成方法(表A 在S1文本)[28]。预先指定的集成方法都依赖于使用预测密度堆叠方法获取组件模型的加权*均值,包括两个季节性基线组件(参见方法)。它们的复杂程度从简单(每个组件都分配一个权重)到更复杂的(组件具有不同的权重,具体取决于预测的目标和区域,请参阅方法)。FSNetwork 目标类型权重 (FSNetwork-TTW) 集成模型是一种中等复杂度的方法,在训练阶段的表现优于所有其他多模型集成和组件(图 2)。FSNetwork-TTW模型使用40个估计权重构建加权模型*均值,每个模型一个权重和目标类型(提前一周和季节性)组合(图3)。在训练期间,由2017/2018年之前的七个流感季节组成,该模型获得了0.406的交叉验证*均预测得分,而FSNetwork目标权重(FSNetwork-TW)模型得分为0.404,FSNetwork恒定权重(FSNetwork-CW)模型得分为0.400,FSNetwork目标区域权重(FSNetwork-TRW)模型得分为0.400(图4)。在2017-18 FluSight挑战赛开始之前,我们选择了目标型权重模型作为模型,该模型将在2017/2018赛季实时提交给CDC。这种选择是基于所选模型的预先指定的标准,该模型在交叉验证的训练阶段具有任何方法的最高分[28]。
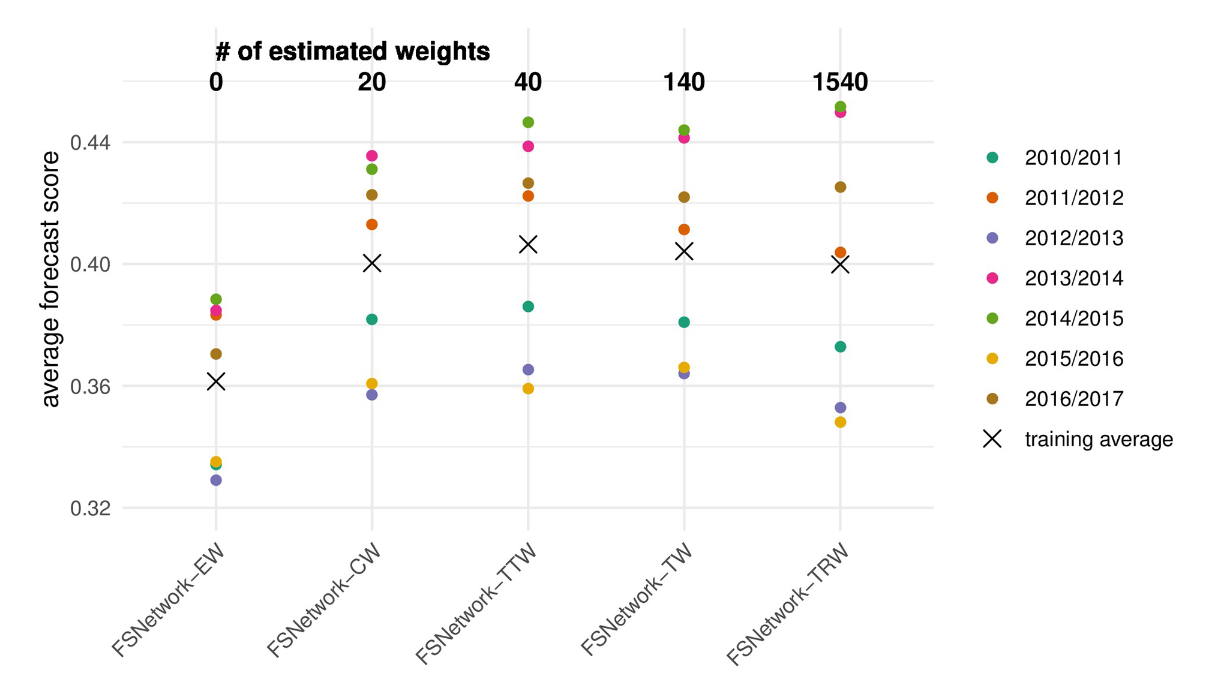
图2.五个预先指定的多模型集成的训练阶段性能。测试的五个集合是相等权重(EW),恒定权重(CW),目标类型权重(TTW),目标权重(TW)和目标区域权重(TRW)。模型从最简单(左)到最复杂(右)排序,每个模型的估计权重数量(参见方法)显示在顶部。每个点代表特定季节的*均预测分数,所有季节的总体*均值由 X 显示。
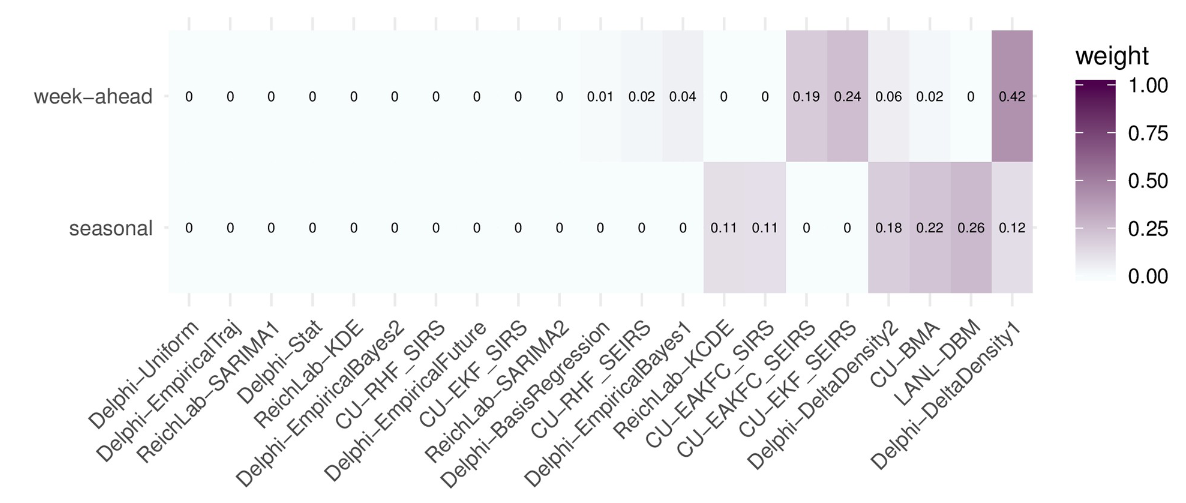
图3.2017/2018赛季FluSight网络目标类型权重(FSNetwork-TTW)集成模型的组件模型权重。权重是使用交叉验证的2010/2011赛季至2016/2017赛季的预测性能估算的。
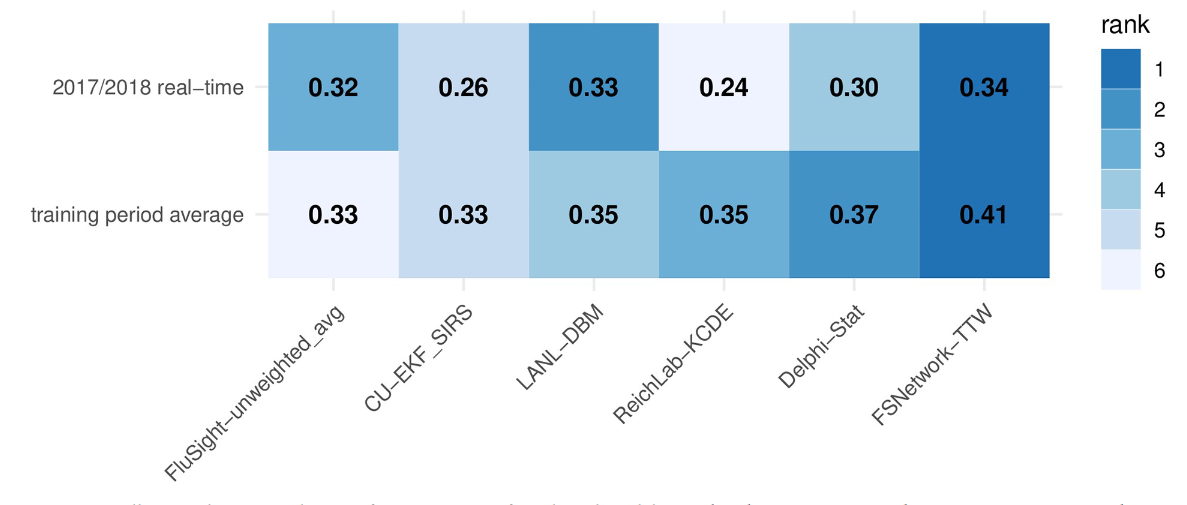
图4.所选模型的总体测试和训练阶段性能分数。显示的分数是跨目标、区域和周的*均值,并针对所选模型单独绘制。显示的模型包括FSNetwork-TTW模型,每个团队在训练阶段表现最好的模型,以及过去两个训练季节和测试季节,CDC收到的所有FluSight模型的未加权*均值。每行中的模型排名由每个单元格的颜色表示(颜色越深表示排名越高,预测越准确),预测分数(四舍五入到小数点后两位)打印在每个单元格中。请注意,acompone nt的独立精度不一定与其对整体集成精度的贡献相关。请参阅方法的“集成组件”子部分中的讨论。
使用训练期的结果,我们估计了所选FSNetwork-TTW集成模型的权重,该模型将用于2017/2018实时预测。FSNetwork-TTW模型为8个模型分配了不可忽略的权重(大于0.001),用于提前一周的目标,为6个模型分配了季节性目标(图3)。对于提前一周的目标,Delphi-DeltaDensity1模型的非零权重最高(0.42)。对于季节性目标,LANL-DBM 模型的权重最高 (0.26)。在季节性目标的权重中,六个样本的权重超过99.9%,六个样本的权重均不低于0.11。所有四个研究团队在所选模型中至少有一个权重不可忽略的模型。
2.3 2017/2018赛季合奏实时表现总结
美国2017/2018年流感季节表现出与过去15年任何季节都不同的特征(图1B和1C)。根据国家层面的wILI百分比衡量,2017/2018季节与1997年以来有记录以来的其他两个高峰相当:2003/2004季节和2009年H1N1流感大流行。在某些地区,例如HHS第2区(纽约和新泽西州)和HHS第4区(东南部各州),2017/2018赛季的wILI峰值比之前观察到的峰值高出20%以上。由于所有预测模型在某种程度上都依赖于模仿过去观察到的模式的未来趋势,因此2017/2018年的异常动态对所有模型(包括新集合)都构成了具有挑战性的“测试季节”。
尽管存在这些不寻常的动态,但所选的FSNetwork-TTW合奏在2017/2018赛季在所有组件和合奏模型中表现出最佳性能。特别是,我们在训练阶段从每个团队中选择了单个最佳组件模型和FluSight-unweighted_avg模型(提交给CDC的所有模型的未加权*均值)与FSNetwork-TTW模型进行比较(图4)。2017/2018年的结果与训练期间得出的结论一致并得到证实,其中FSNetwork-TTW模型优于所有其他集成模型和组件。FSNetwork-TTW模型在训练期间的*均得分最高(0.406),在2017/2018测试季节的*均得分最高(0.337)。所选的FSNetwork-TTW集成模型的强劲而一致的表现值得注意,因为我们的团队在赛季开始前就预见了该模型,基本上押注该集成模型将在2017/2018赛季具有任何模型的最佳性能。FSNetwork-TTW模型在2017/2018赛季的所有周内始终优于更简单的集成模型和季节性*均模型(图鳍S1文本)。
FSNetwork-TTW模型在训练和测试阶段都显示出比CDC基线集成模型FluSight-unweighted_avg更高的性能。这个多模型集合包含2017/2018年提交给FluSight竞赛的28个模型的预测。虽然提交给CDC的28个模型中有一些是我们基于性能的FluSight Network多模型集合中21个模型的版本,但提交给CDC的模型中有三分之二以上没有出现在FluSight Network组件中。在2017/2018年,FSNetwork-TTW模型的*均预测得分为0.337,而FluSight-unweighted_avg模型的*均预测得分为0.321(图4)。
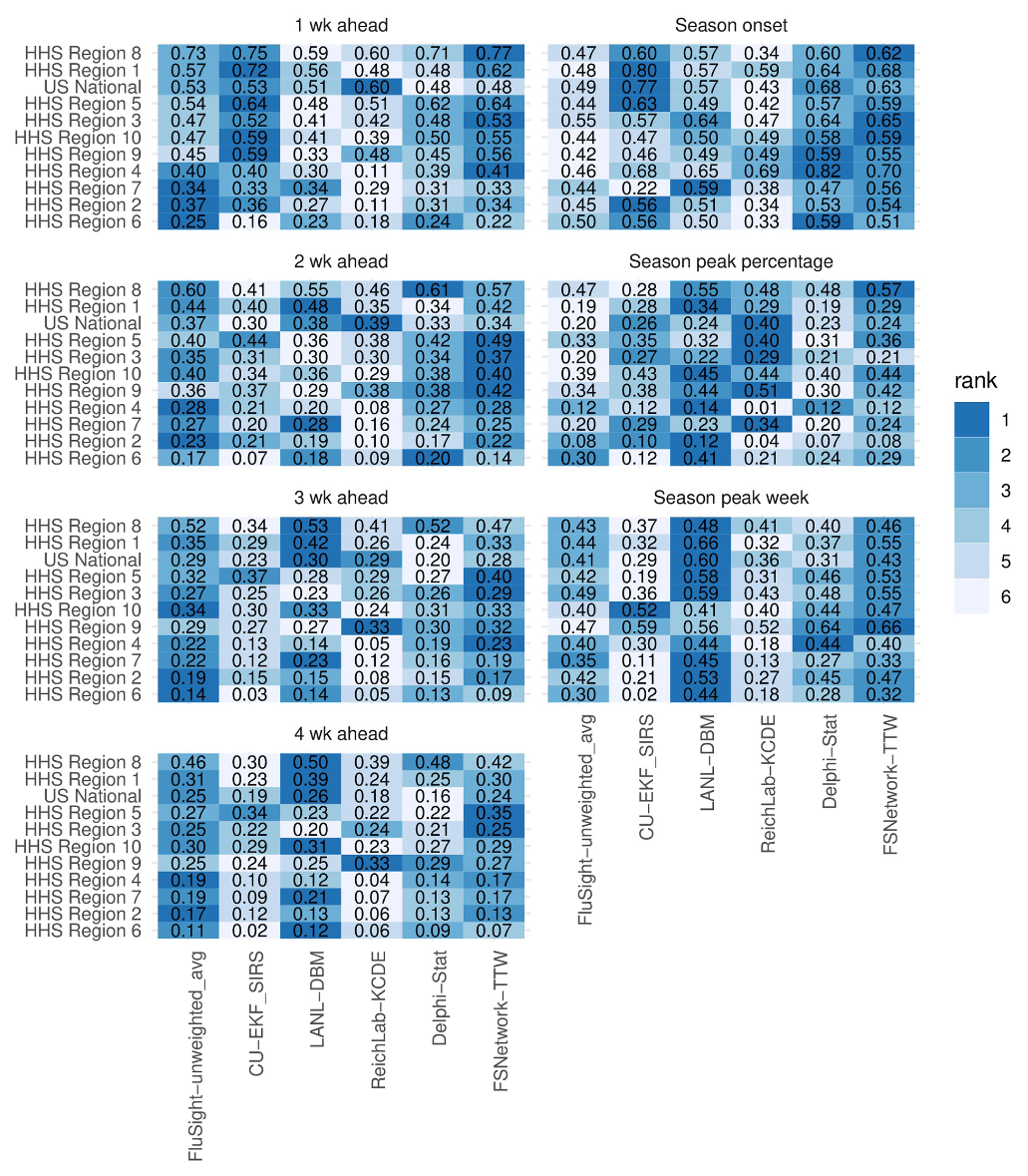
图5.2017/2018年按目标和地区划分的*均预测得分和排名。显示的模型包括FSNetwork-TTW模型,每个团队在训练阶段表现最好的模型以及CDC收到的所有FluSight模型的未加权*均值。颜色表示 2017/2018 赛季的模型排名(颜色越深表示排名越高,预测更准确),每个单元格中都印有预测分数(四舍五入到小数点后两位)。区域按总体上最可预测的区域(即最高预测分数)在顶部进行排序。
在2017/2018赛季,每个贡献研究团队的顶级模型在不同的预测目标和地区表现出相当大的性能差异(图5)。然而,FSNetwork-TTW模型在性能上的可变性低于其他方法。在所有77对目标和区域中,FSNetwork-TTW模型是六个选定模型中唯一一个预测得分没有得过最低的模型。此外,它只有两次得分第二低。虽然我们的集成模型并不总是在每个目标区域对中得分最高,但其在所有组合中的一致性和低变异性确保了它的最高*均分。
尽管FSNetwork-TTW针对高预测分数值进行了优化,但在2017/2018赛季,在衡量预测校准和准确性的其他性能指标中表现出强劲的表现。总体而言,FSNetwork-TTW模型在RMSE和*均偏差方面在选定的模型中排名第二,仅次于LANL-DBM模型(S1文本中的图A)。例如,在2017/2018赛季所有地区感兴趣的评分期间,FSNetwork-TTW模型对季节开始的点估计*均比真实值晚不到半周(*均偏差=0.38周),对于提前1周的ILI,估计值被低估了不到四分之一个百分点(*均偏差=-0.23 ILI%)。
根据概率积分变换度量[29,30],FSNetwork-TTW模型针对所有四周目标进行了良好的校准(图Bin S1文本)。它针对峰值性能的校准略差,并且显示出2017/2018赛季预测分布太窄的迹象。在2017/2018赛季之前的整个训练期间,FSNetwork-TTW模型校准结果表明,总的来说,该模型是保守的,预测分布通常太宽(图Cin S1文本)。
使用相同的组件但考虑到它们在2017/2018赛季的表现的新合奏将具有不同的权重。在原始集成中获得大量权重但在 2017/2018 赛季表现特别差的组件的重量下降幅度最大(S1 文本中的图 D)。总体而言,三个组件被添加到六个现有组件的列表中,这些组件的季节性目标权重超过 0.001:CU-EAKFC_SEIRS、CU-EKF_SEIRS 和 ReichLab-SARIMA2。一个组件(ReichLab-SARIMA2)被添加到八个现有组件的列表中,这些组件在一周前的目标中获得了超过0.001的权重。
2.4 峰值预测的集成精度
发病率高峰前后的预测准确性是衡量给定模型对公共卫生决策者实时有用程度的重要指标。为此,我们评估了以高峰周为中心的13周内每个地区的FSNetwork-TTW集成模型的得分(图6)。高峰周前6周、5周和4周的预测得分低于过去季节,最终观测值的概率分别为0.05、0.06和0.05。然而,在高峰周和之后,这个概率超过了0.70,远高于过去季节的*均准确率。
同样,对于高峰周,随着高峰周的临*,*均预测得分有所提高。除了峰值发生后HHS区域7的精度大幅下降(由于在峰值前后几周对观测到的wILI数据的修订)之外,峰值周的预测得分在峰值之后的几周内往往很高。超过一半的地区在高峰期后的所有星期的*均得分都大于0.75。
3. 讨论
4. 材料和方法
4.1 流感数据
4.2 预测目标和结构
由于目标是向CDC FluSight预测挑战赛实时提交我们的集合预报,因此我们在确定预测格式时坚持了挑战赛规定的指南和格式。Aseason 通常由每周生成的预测文件组成,持续 33 周,从一个日历年的流行病第 43 周 (EW43) 开始,到下一年的 EW18 结束。一年中的每一周都使用国家应报告疾病监测系统制定的标准定义被划分为“MMWR周”(范围从1到52或53,取决于年份)[38-40]。CDC FluSight挑战的预测包括七个目标:三个季节性目标和四个短期或“未来一周”目标。季节目标包括季节开始(定义为wILI处于或高于基线并连续三周保持在基线之上的第一个MMWR周)、季节高峰周(定义为最大wILI的MMWR周)和季节高峰百分比(定义为季节的最大wILI值)。短期目标包括对最*公布的数据提前 1、2、3 和 4 周的 wILI 值预测。由于ILINet发布报告延迟两周,这些短期预测是针对预测前一周、本周和预测后两周发生的wILI水*。为整个美国和10个HHS地区中的每一个的所有目标创建预测(图1A-1C)。
对于所有目标,预测由目标可能值的箱的概率分布组成。对于季节开始和高峰周,预报箱由流感季节内的个别周组成,还有一个额外的箱用于发病周,对应于无发病的预报。对于短期目标和峰值强度,预测箱包括观察到的wILI水*,四舍五入到最接*的0.1%(CDC公开报告的ILINet分辨率水*)至13%。形式上,箱定义为 [0.00, 0.05), [0.05, 0.15), ...,[12.85, 12.95), [12.95, 100]。
CDC已经为每周流感预测制定了非结构化格式。该项目的所有预测都使用这些数据标准进行所有预测,这促进了团队之间的协作。
4.2 预测评估
提交的预测使用CDC在其预测挑战中使用的修改日志分数进行评估,该分数同时提供了预测准确性和精度的测量。非概率预测 m 的对数分数定义为对数 $ f_m(z^*|x) $,其中$f_m(z|x)$是模型 m 对某些目标 Z 的预测密度函数,条件是某些数据 x,z 是目标 Z 的观测值。
虽然适当的对数分数仅评估分配给精确观测值 z 的概率,但 CDC 使用修改后的对数分数将附加值分类为“准确”。对于季节开始周和高峰周的预测,分配给观测周前后一周的概率被包括在内,因此修改后的对数分数变为$log \int_{z*-1}{z^+1}f_m(z|x)dz$。对于季节高峰百分比和短期预测,分配给观测值 0.5 个单位内的 wILI 值的概率被包括在内,因此修改后的对数分数变为$log \int_{z*-5}{z^+5}f_m(z|x)dz$ 实践,并且遵循 CDC 评分惯例,我们将修改后的对数分数截断为不低于 -10。我们将这些修改后的日志分数称为下文中的简单日志分数。
单个日志分数可以在预测区域、目标、周或季节的不同组合中取*均值。每个模型 m 对于区域 (r)、目标 (t)、季节 (s) 和周 (w) 的每个组合都有一个相关的预测密度。这些密度中的每一个都有一个伴随的标量对数分数,可以表示为$log f_{m,r,t,s,w}(z^*_{r,t,s,w}|x)dz$。这些单独的日志分数可以跨区域、目标、季节和周的组合取*均值,以比较模型性能。
按照FluSight挑战赛惯例,为了将模型评估重点放在与公共卫生决策更相关的时间段上,在计算每个目标的*均对数分数时只包括某些周。包括每个地区在该地区观察到的发病周后最多六周的季节开始预测。包括区域季节所有周的峰值周和峰值强度的预测,直到wILI测量值最终降至区域基线水*以下的一周。包括每个区域季节的提前一周预测,从发病前四周开始,到wILI最后一次低于区域基线后的三周。所有周都包括在发病率不足以定义季节开始周的区域季节。
为了增强可解释性,我们报告了指数*均对数分数,这是分配给最终认为准确的值的模型概率的几何*均值。在本手稿中,我们将这些称为“*均预测分数”。例如,模型 m 在季节 s 中的*均预测得分(如图 2 所示)计算为
$$
S_{m,,,s}=exp(\frac{1}{N}\sum_{r,t,w}log f_{m,r,t,s,w}(z*_{r,t,s,w}|x))=(\prod_{r,t,w}f_{m,r,t,s,w}(z{r,t,s,w}|x))^{1/N}\tag{1}
$$
由于其他预测工作使用点预测的均方误差(MSE)或均方根误差(RMSE)作为评估方法,因此我们还使用RMSE评估了2017-2018赛季收到的预期预测。提交的点预测用于对每个组件进行评分,并通过获取预测分布的中位数为每个FSNetwork模型生成点预测。对于每个模型 m,我们计算了目标 t 的 RMSEm,t,在 s =2017/2018 季节和所有区域 r 的所有周 w 的*均值,$RMSE=\sqrt{\frac{\sum_{r,w}(\hat{z}{m,r,t,w}-z*)2}{N}}$,其中$\hat{z}{m,r,t,w}$ 是模型 m 对观测值$z*$的点预测。*均偏差计算为$bias_{m,t}={\frac{\sum_{r,w}(\hat{z}_{m,r,t,w}-z_{r,t,w})^2}{N}}$。
4.3 集成组件
为了提供合奏的训练数据,四个团队分别提交了 1 到 9 个组件,总共 21 个集成组件。团队提交了2010/2011年至2016/2017年流感季节的样本外预测。这些模型及其性能在单独的工作中进行评估[27]。团队以前瞻性的方式构建他们的预测,仅使用预测时可用的数据。对于某些数据来源(例如,2014/2015年流感季节之前的wILI),当时公布的数据不可用。在这种情况下,团队仍然可以使用这些数据源,同时尽最大努力仅使用预测时可用的数据。
对于每个流感季节,团队使用CDC对流行周的标准定义,提交了从第一年第40周(EW40)到次年EW20的每周预测[38-40]。Ifaseason包含EW53,该周的预测也已提交。团队总共提交了233份单独的预报文件,代表了七个流感季节的预报。提交后,预测文件不会更新,除非有四种情况,即显式编程错误导致预测中的数字问题。明确不鼓励团队重新调整或调整之前不同赛季的模型,以避免过度拟合的问题。
团队在构建组件模型提交时使用了各种方法和建模方法(表 A 在 S1 文本)。其中七个组分使用区室结构(即易感-传染-恢复)来模拟疾病传播过程,而其他组分使用更多的统计方法来直接模拟观察到的wILI曲线。其中六个组件明确纳入了以前的wILI数据之外的其他数据源,包括天气数据和Google搜索数据。构建了两个分量来仅基于历史数据表示非季节性基线。
此外,我们从CDC创建的“未加权*均值”模型中获得了预测分布。该集合结合了CDC在2015/2016(14个模型)、2016/2017(28个模型)和2017/2018(28个模型)季节实时收到的所有预测模型[26]。这些模型不属于本手稿中描述的协作集成工作的一部分,尽管此处介绍的组件的一些变体也提交给了CDC。包括这个模型使我们能够将我们的集成精度与CDC在这三个季节中实时使用的模型进行比较。
区分集成组件和独立预测模型非常重要。独立模型经过优化,通过适当的*滑等方式,使其自身尽可能准确。集成组件可能被设计为本身是准确的,或者它们可能只是为了补充其他组件中的弱点,即减少集成的方差。因为我们有足够的交叉验证数据来估计几十个分量的集合权重,所以一些小组为此目的贡献了非*滑的“互补”分量(表Ain S1文本)。这些组件本身可能表现不佳,但它们对整体集成精度的贡献可能仍然很大。
应该注意的是,集成权重不是集成组件独立精度的度量,也不是测量特定模型对集成精度的总体贡献。例如,考虑设置,其中与具有权重$π^$的现有集成组件相同(或高度相似)的组件添加到给定集成中。可以通过多种方式保持原始融合的准确性,包括 (a) 为每个副本分配$π^/2$ 的权重,或 (b) 将第一个副本权重分配为 $π^*$,将第二个副本权重分配为 0。在这两个权重中,由于存在另一个相同或相似的分量,至少一个高精度集成分量的权重会明显降低。事实上,我们在结果中看到了这一点,因为德尔福-统计模型是性能最好的组件模型,但它是其他德尔菲模型的线性组合。它在我们所有的集成中都获得了零权重。此外,包含权重较小的组件会对融合的预测精度产生很大影响。
4.4 集成命名
术语“集成”在实践中有几种不同的使用方式。在本文中,我们交替使用短语“多模型集成”或“集成模型”来指代表示单独组件模型混合的模型。但是,集成建模的清晰分类法可能会区分集成模型的三个不同层。首先,可以使用单模型集成方法拟合模型并进行预测。这些方法的例子包括哥伦比亚大学的组件模型,例如使用集成*均卡尔曼滤波来获取模型实现的加权*均值以形成预测分布(Table Ain S1 Text)。其次,多模型集成通过模型堆叠等技术组合组件模型(参见方法)。在这项工作中描述的模型中,一个组件模型(Delphi-Stat)是多模型集合,所有FluSight网络模型也是多模型集合(Table A 在 S1 Text)。第三,术语“superensemble”已用于组合本身是集成的组件(多模型或单模型)的模型[16,41]。由于并非我们方法中的所有组件本身都是集成,因此我们选择了术语多模型集成来指代我们的方法。
4.5 集成构建
所有集成模型都是使用一种方法构建的,该方法使用加权*均值组合成分预测分布或密度。在文献中,这种方法被称为堆叠[13]或加权密度集合[23],类似于贝叶斯模型*均中使用的方法[18]。设 $f_c(z_{t,r,w})$表示目标 $Z_{t,r,w}$,值的集成组件 c 的预测密度,其中 t 索引特定目标,r 索引区域,w 索引周。我们将这些组件组合在一起,形成预测密度$f(z_{t,r,w})$的多模型集合,如下所示:
$$
f(z_{t,r,w})=\sum_{c=1}^{C}\pi_{c,t,r}f_c(z_{t,r,w})\tag{2}
$$
其中$π_{c,t,r}$是分配给模型c的权重,用于预测区域r中的目标t。我们需要$\sum_{c=1}^C\pi_{c,t,r}=1$,从而确保$f(z_{t,r,w})$保持有效的概率分布。
总共考虑了五种集合加权方案,其复杂性和估计权重的数量各不相同(表A 在 S1文本)。
- 相等权重 (FSNetwork-EW):该模型包括为所有组件分配相同的权重,而不考虑性能,并且等效于组件的等权概率密度混合:$π_{c,t,r}=1/C$。
- 固定权重模型 (FSNetwork-CW):权重因组件而异,但所有目标和区域的值相同,总共 21 个权重:$π_{c,t,r}=\pi_c$。出于统计估计的目的,我们说自由度 (df) 是(21 − 1) =20。对于每组权重,一旦估计了 20 个权重,就确定了第 21 个权重,因为它们的总和必须为 1。
- 目标类型权重模型(FSNetwork-TTW):我们的两种目标类型(tt)、短期和季节性目标的权重是单独估算的,不同地区之间没有变化。这导致总共 42 个权重 (df = 40):$π_{c,t,r}=\pi_{c,tt}$。
- 目标权重模型(FSNetwork-TW):分别估计每个组分的七个目标中的每一个的权重,不同区域之间没有变化,得到147个权重(df = 140):$π_{c,t,r}=\pi_{c,t}$。
- 目标-区域权重模型(FSNetwork-TRW):考虑的最复杂的模型,该模型分别估算每个组件-目标-区域组合的权重,得到1617个唯一权重(df =1540):$π_{c,t,r}=\pi_{c,t,r}$。
使用EM算法估计权重(S1文本中的第6节)[34]。组件的权重使用一个季节的交叉验证方法对2010/2011赛季至2016/2017赛季的组件预测进行训练。鉴于可用于交叉验证的季节数量有限,我们使用所有其他季节的组件模型预测分数作为训练数据来估计给定测试季节的权重,即使训练季节按时间顺序发生在感兴趣的测试季节之后。
4.6 集成评价
根据交叉验证研究的结果,我们选择了一个集成模型作为CDC2017/2018流感预测挑战赛的官方FluSight网络条目。在进行交叉验证实验之前,该选择的标准是在2017年9月预先指定的[28]。FSNetwork-TTW模型的组件权重是使用所有七个季节的组件模型预测来估计的。在2017/2018流感季节期间,参与团队实时提交了每个组件的每周预测,这些预测使用估计的权重合并到FluSight网络模型中并提交给CDC。提交的模型的组件重量在整个赛季中保持不变。
4.7 可重复性和数据可用性
为了最大限度地提高该项目的可重复性和数据可用性,整个项目的数据和代码都是公开可用的。该项目可在GitHub [42]上找到,永久存储库存储在Zenodo [43]上。特定模型的代码要么公开可用,要么应建模团队的要求提供,相关引文中提供了更多特定于模型的详细信息(表 Ain S1 文本)。来自FluSight网络的回顾性和实时预报可以在网站 http://flusightnetwork.io 上以交互方式浏览。此外,本手稿是使用 Rversion 3.6.0 (2019-04-26)、编织、编织和制作动态生成的。这些工具可以将手稿文本与运行中心分析的Rcode混合在一起,自动重新生成已更改的分析部分,并最大限度地减少转录或翻译结果时出错的机会[44,45]。
阅读总结
- 提出了一种FluSight Network集成模型框架
- 在2017/2018美国流感数据上对比了多个参赛团队流感预测模型