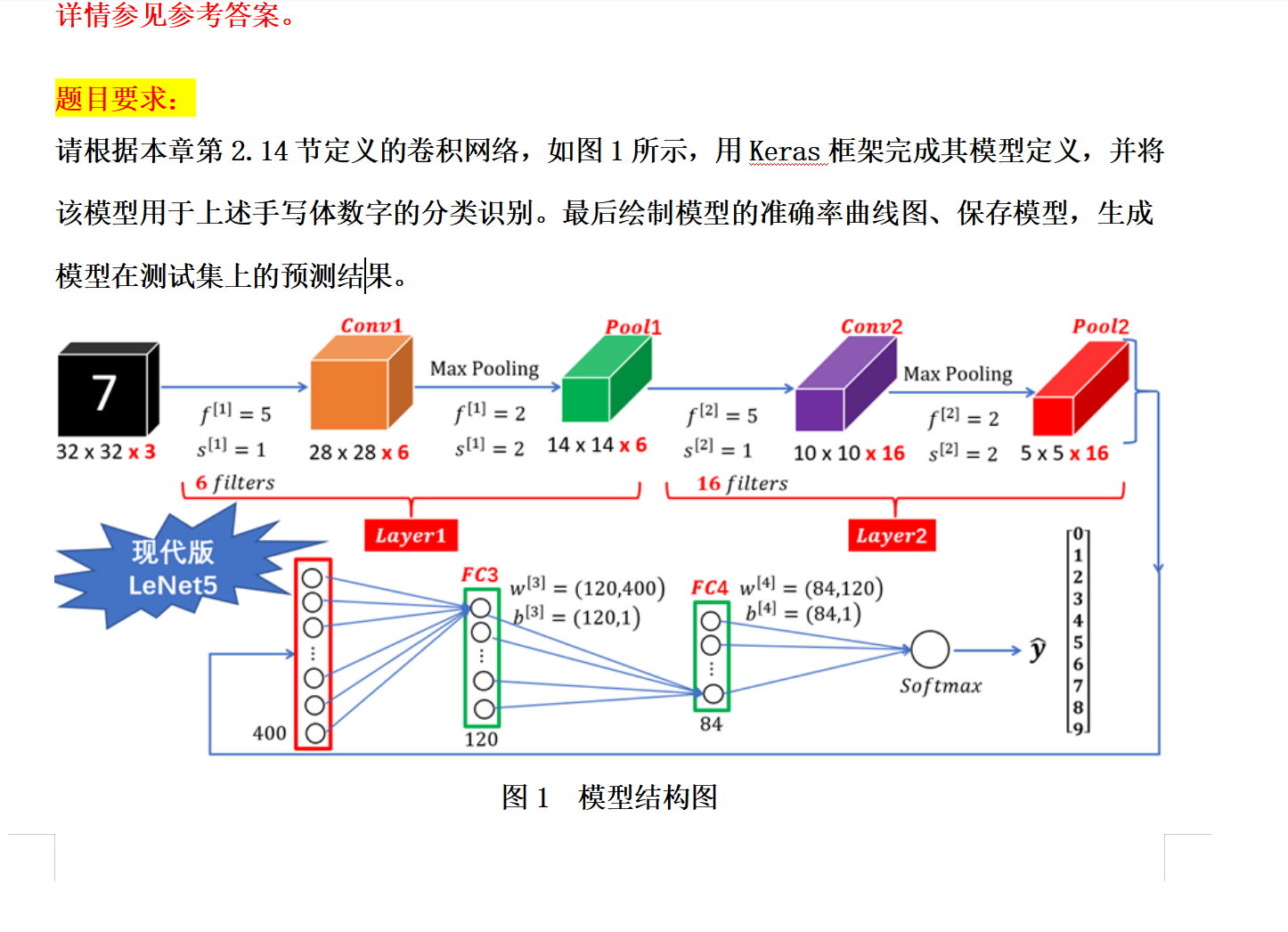
1.手写数字识别

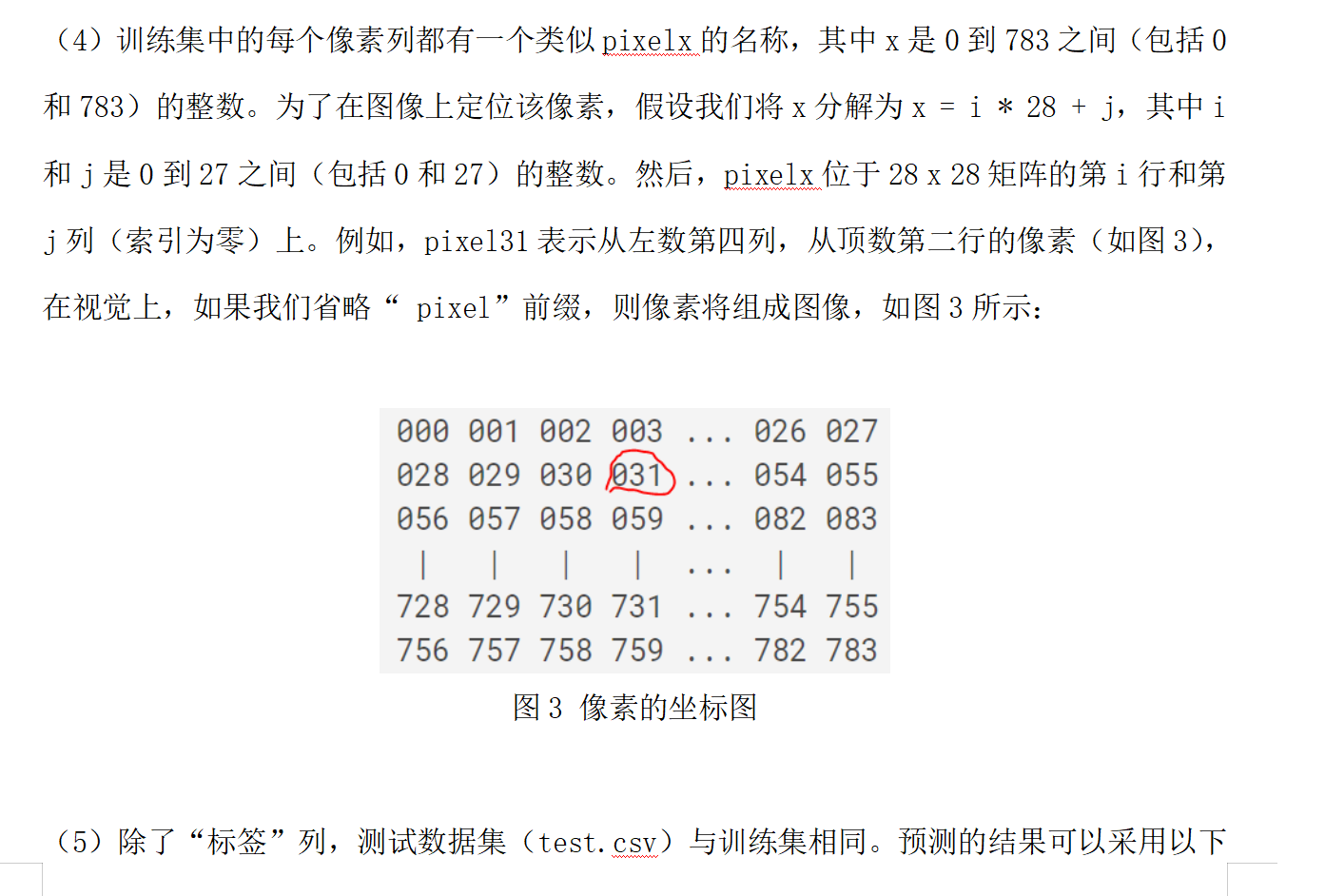

加载数据:
import tensorflow as tf
import pandas as pd
from tensorflow.keras import layers, optimizers, datasets, Sequential
from keras.utils.np_utils import to_categorical
import matplotlib.pyplot as plt
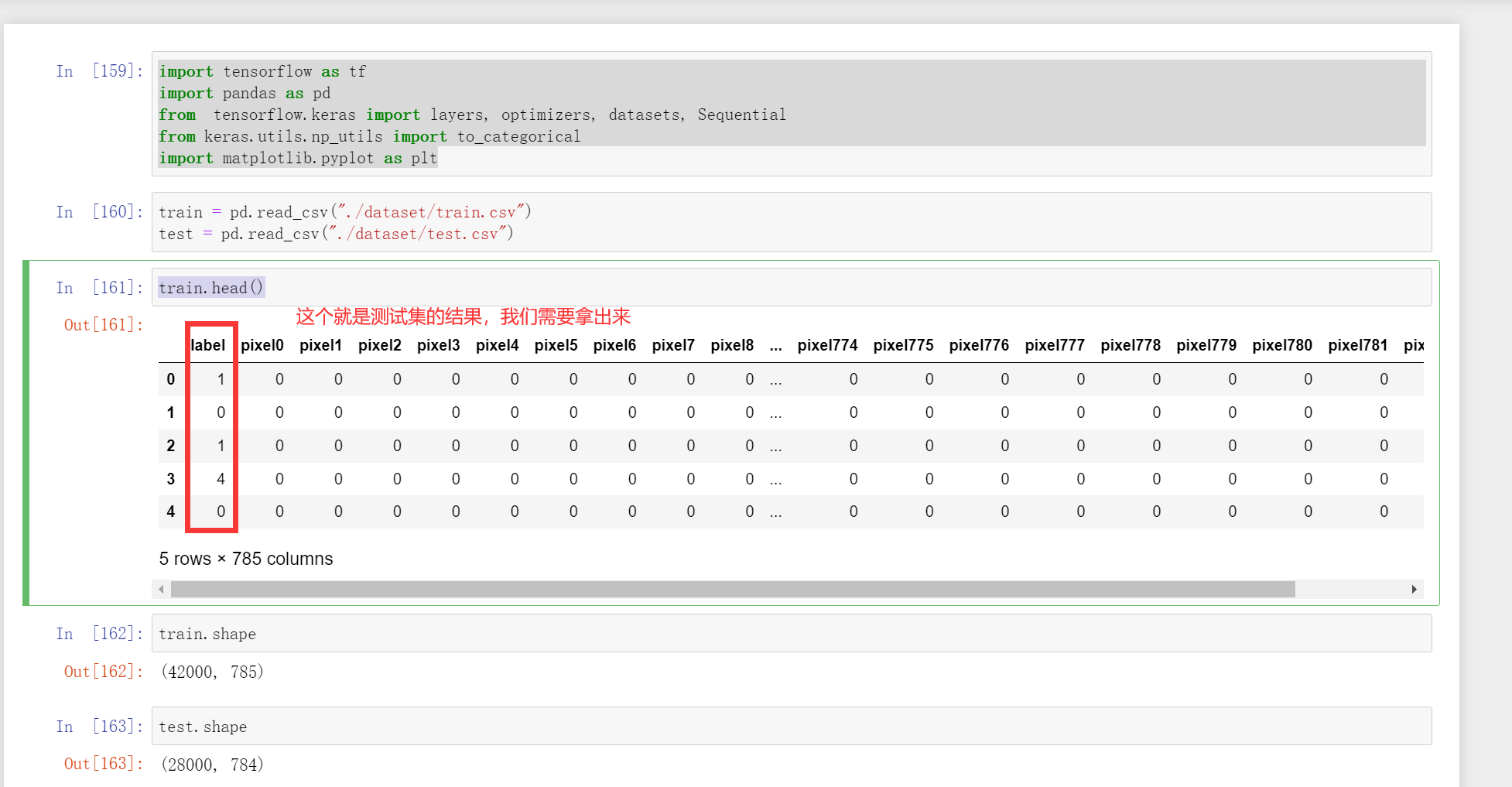
train = pd.read_csv("./dataset/train.csv")
test = pd.read_csv("./dataset/test.csv")
train.head()
train.shape,test.shape
数据处理
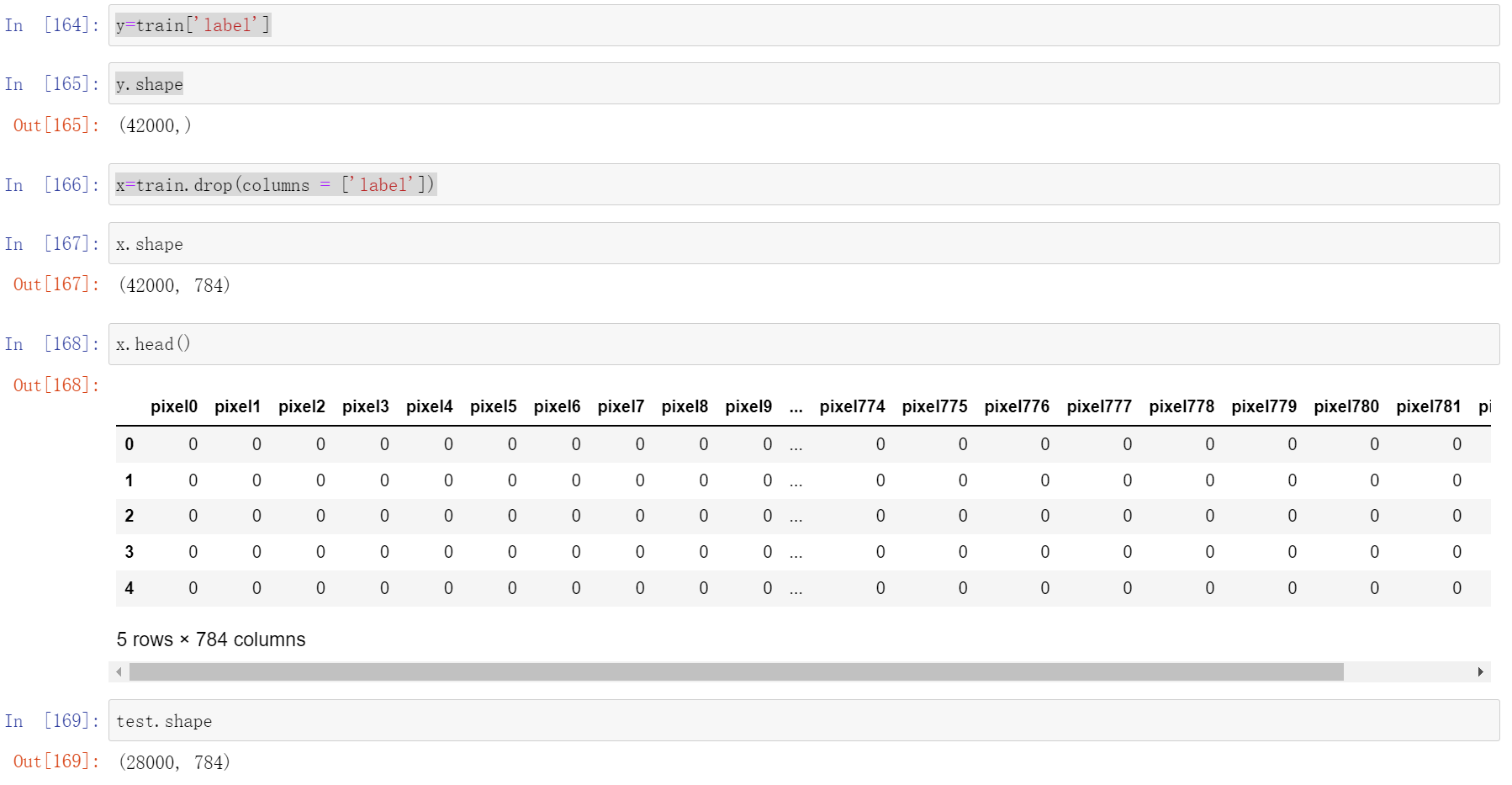
y=train['label']
x=train.drop(columns = ['label'])
y.shape
x.shape
数据归一化
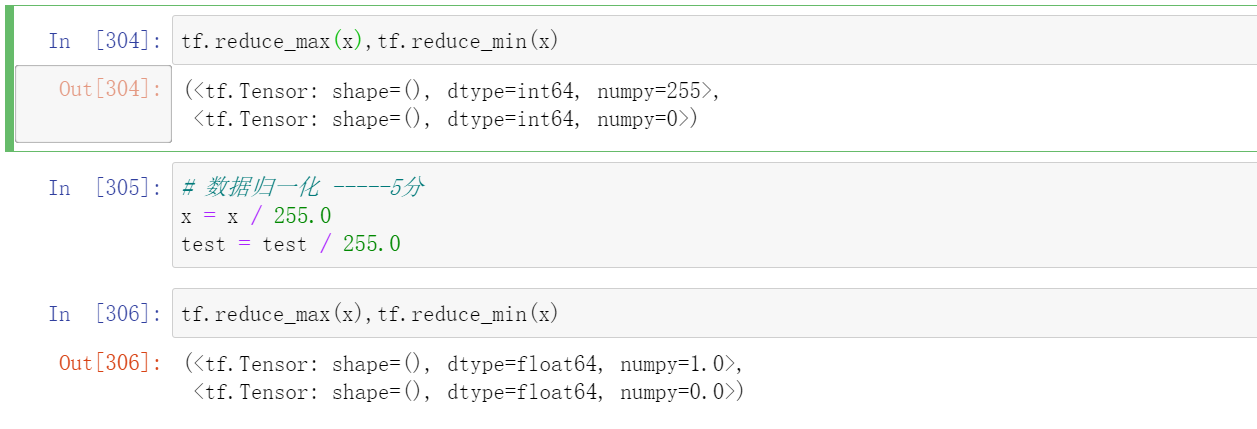
tf.reduce_max(x),tf.reduce_min(x)
# 数据归一化,无量纲化
x = x / 255.0
test = test / 255.0
tf.reduce_max(x),tf.reduce_min(x)
分割数据集
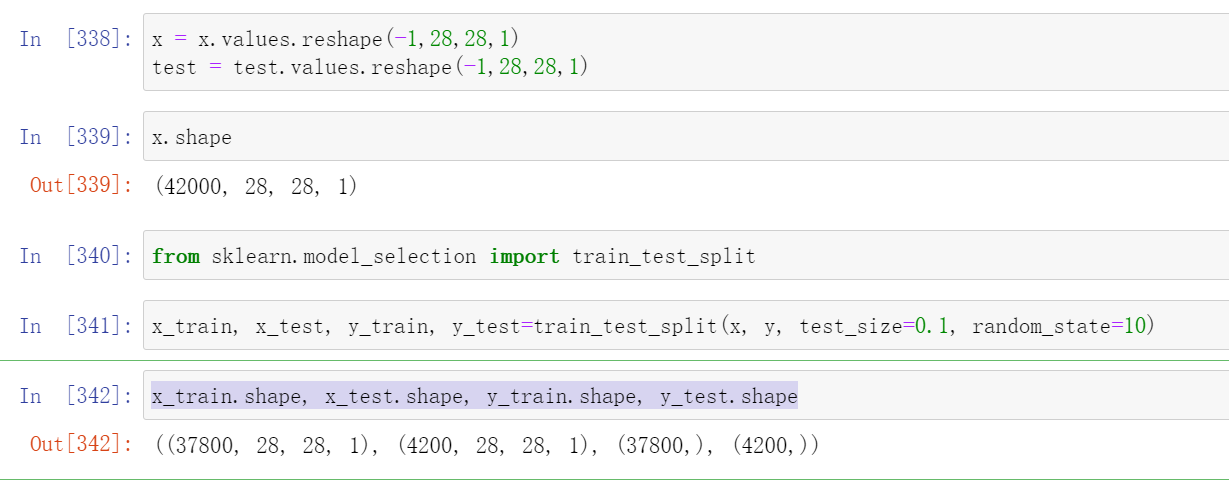
x = x.values.reshape(-1,28,28,1)
test = test.values.reshape(-1,28,28,1)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test=train_test_split(x, y, test_size=0.1, random_state=10)
x_train.shape, x_test.shape, y_train.shape, y_test.shape
转化成onehot编码
这两种方法都行
#y_train = to_categorical(y_train, num_classes = 10)
#y_test = to_categorical(y_test, num_classes = 10)
y_train=tf.one_hot(y_train, depth=10)
y_test=tf.one_hot(y_test, depth=10)
模型定义
model = Sequential([ # 5 units of conv + max pooling
# unit 1:
layers.Conv2D(6, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(6, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(16, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(16, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Flatten(),
layers.Dense(120, activation=tf.nn.relu),
layers.Dropout(0.25),
layers.Dense(84, activation=tf.nn.relu),
layers.Dropout(0.25),
layers.Dense(10,activation = "softmax"),
#注意最后一层是"softmax"
])
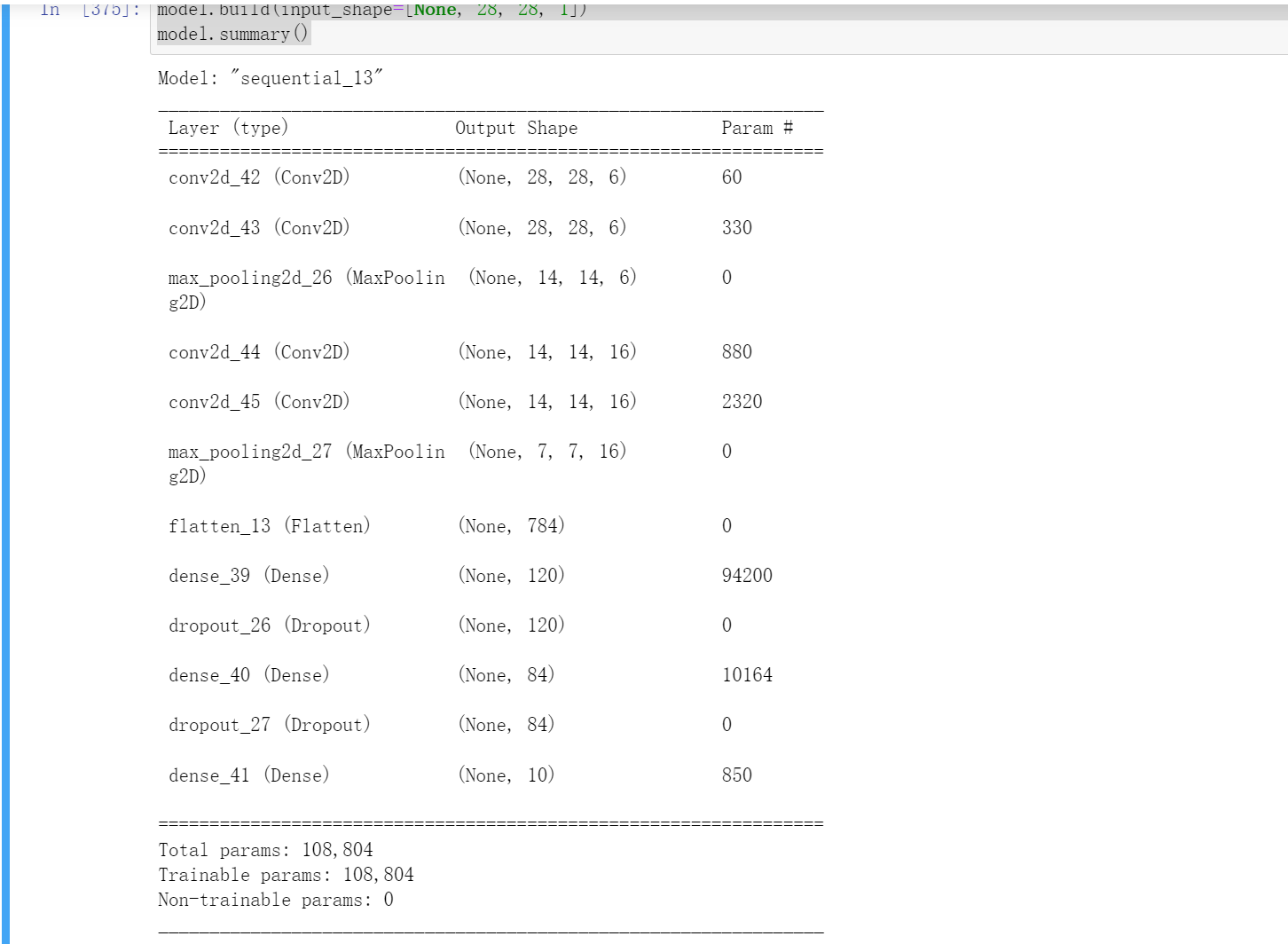
model.build(input_shape=[None, 28, 28, 1])
model.summary()
compile和fit
model.compile(optimizer="Adamax",
loss="categorical_crossentropy", metrics=["accuracy"])
optimizer可以选择
SGD#
RMSprop
Adam
Adadelta
Adagrad
Adamax
Nadam
Ftrl
这个具体用法可以看这个中文官网
其中这个loss='categorical_crossentropy'这个是分类交叉熵函数
mean_squared_error:均方误差
categorical_crossentropy:分类交叉熵
binary_crossentropy:二元交叉熵
sparse_categorical_crossentropy:稀疏分类交叉熵
mean_absolute_error:平均绝对误差
hinge:hinge损失函数
squared_hinge:平方hinge损失函数
cosine_proximity:余弦相似度损失函数
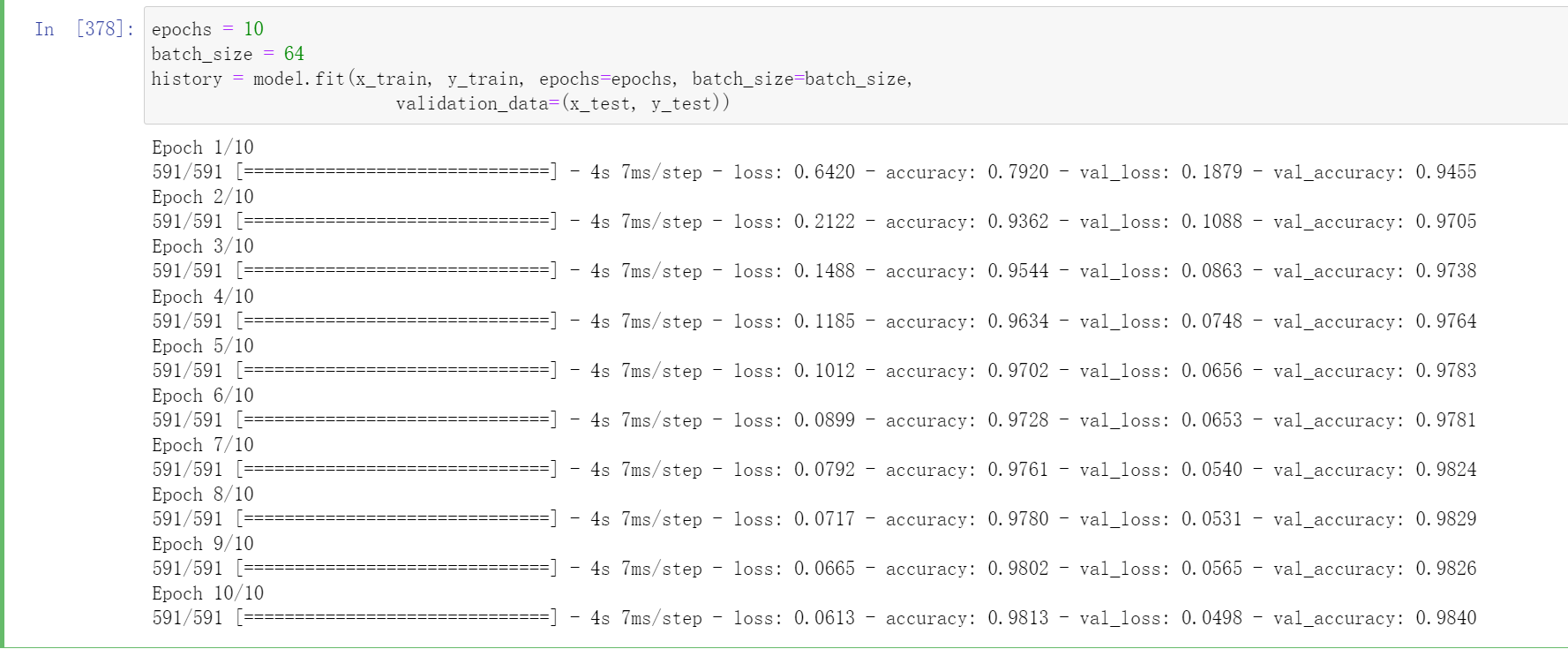
epochs = 10
batch_size = 64
history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
validation_data=(x_test, y_test))
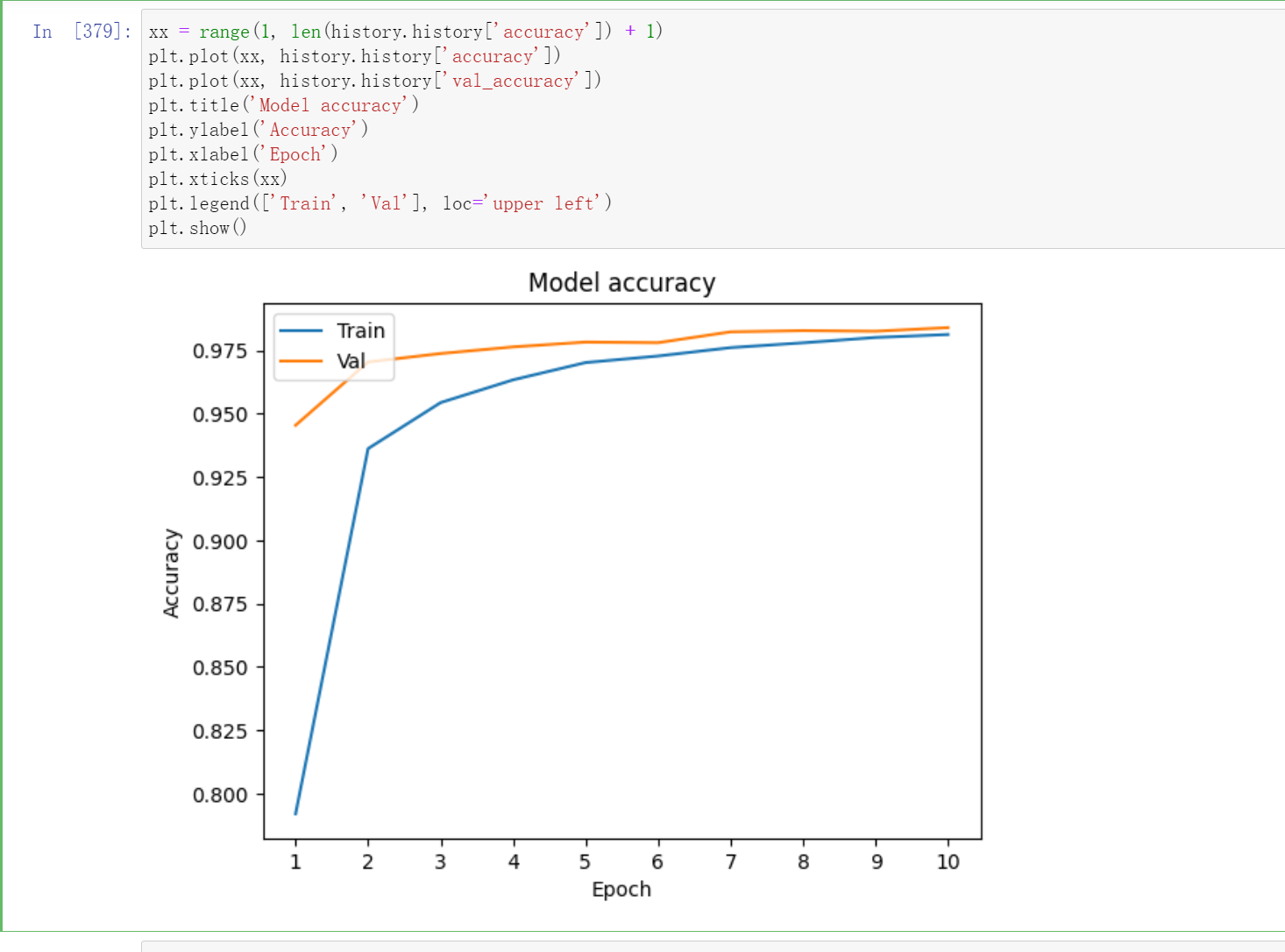
作图
xx = range(1, len(history.history['accuracy']) + 1)
plt.plot(xx, history.history['accuracy'])
plt.plot(xx, history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.xticks(xx)
plt.legend(['Train', 'Val'], loc='upper left')
plt.show()
预测结果保存
import numpy as np
#模型预测并保存预测结果到predict_result.csv ----5分
results = model.predict(test)
results = np.argmax(results,axis = 1)
results = pd.Series(results,name="Label")
submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1)
submission.to_csv("predict_result.csv",index=False)
2 cifar100
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
from keras.utils.np_utils import to_categorical
import matplotlib.pyplot as plt
tf.random.set_seed(2345)
# 设置采用GPU训练程序
gpus = tf.config.list_physical_devices("GPU") # 获取电脑GPU列表
if gpus: # gpus不为空
gpu0 = gpus[0] # 选取GPU列表中的第一个
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显卡按需使用
tf.config.set_visible_devices([gpu0], "GPU") # 设置GPU可见的设备清单,默认是都可见,这里只设置了gpu0可见
model = Sequential([ # 5 units of conv + max pooling
# unit 1:32
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2:16
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3:8
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4:4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5:2
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Flatten(),
layers.Dense(256, activation=tf.nn.relu),
layers.Dropout(0.5),
layers.Dense(128, activation=tf.nn.relu),
layers.Dropout(0.5),
layers.Dense(100, activation='softmax'),
])
def preprocess(x, y):
# [0~1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
y = to_categorical(y, num_classes = 100)
y_test = to_categorical(y_test, num_classes = 100)
print(x.shape, y.shape, x_test.shape, y_test.shape)
def main():
# # 这里一定不要忘了
model.build(input_shape=[None, 32, 32, 3])
model.summary()
model.compile(optimizer="Adamax",
loss="categorical_crossentropy", metrics=["accuracy"])
epochs = 10
batch_size = 64
history = model.fit(x, y, epochs=epochs, batch_size=batch_size,
validation_data=(x_test, y_test))
xx = range(1, len(history.history['accuracy']) + 1)
plt.plot(xx, history.history['accuracy'])
plt.plot(xx, history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.xticks(xx)
plt.legend(['Train', 'Val'], loc='upper left')
plt.show()
if __name__ == '__main__':
main()