SuperGlue: Learning Feature Matching with Graph Neural Networks
源码:
github.com/magicleap/SuperGluePretrainedNetwork
背景:
主要解决图像中点之间的对应关系。
主要方法:
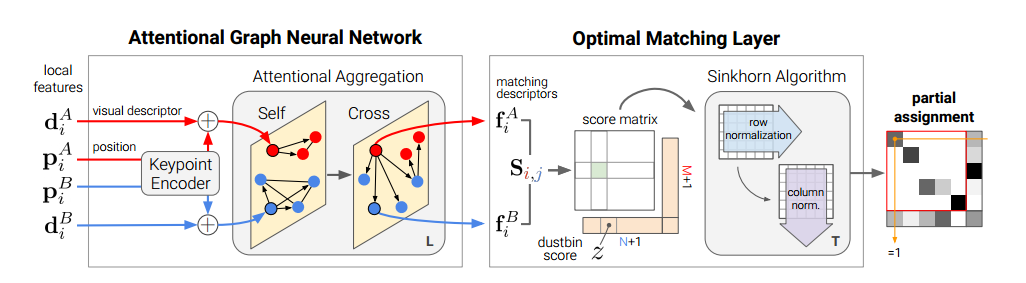
上图为该方法的主要框架。模型大致分为两个部分:注意图神经网络和最优匹配层。其中第i个局部特征由di(描述子)和pi(二维点位置)构成。
输入:两幅图A和B所有局部特征的描述子与相对应的关键点位置。
注意图神经网络:
关键点编码:即得到每个局部特征的状态xi。xi = di + MLPenc (pi),其中MLPenc (pi)是位置编码,采用绝对位置编码。
多路图神经网络:相当于每层都是一个自注意单元和一个交叉注意单元。用图的表现方式,同一幅图片的关键点之间的边表示自注意力系数,不同图片关键点之间的边表示交叉注意系数。下面每一层的状态迭代公式:

其中在 L为奇数时进行自注意力特征聚合,在 L为偶数时进行交叉注意力特征聚合。

![]()
其中qi,ki,vi由以下的方式计算而来:
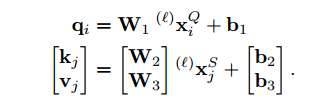
最后输出的匹配描述符是线性投影:(图像B同理)

最优匹配层:
预测分数:对于通过图神经网络得到的输出fiA,fiB。通过其内积获得每个局部特征与另一幅图其余局部特征的分数。S(i,j) =<fiA ;fjB >;
垃圾箱操作:由于图像遮挡等原因,部分关键点是没有匹配对象的,所以对分数矩阵S做了相应处理。通过添加一个新的行和列,即点到箱和箱到箱的分数,将分数S扩展到¯S,并填充一个可学习的参数。(要注意匹配的点和进入垃圾箱的点的总数要等于关键点的个数)
Sinkhorn算法:使用Sinkhorn算法,它包含沿行和列迭代规范化exp(¯S),类似于行和列Softmax。经过T次迭代后,得到得分矩阵¯P。去掉最后一列与最后一行变为最终的得分矩阵P。
损失函数:

其中,M是真实匹配,I∈A,J∈B,且对于一些关键点没有对应点的情况下,标注为不匹配。
实验细节:
SuperGlue可以与任何局部特征检测器和描述符结合使用,但与SuperPoint结合使用效果特别好。SuperPoint描述符具有相同的维度D = 256。使用L = 9层交替的多头自注意和交叉注意,每层4个头,并进行T = 100次Sinkhorn迭代。
- SuperGlue Learning Matching Networks Featuresuperglue learning matching networks correspondence learning outliers feature learning networks neural hello pre-train learning networks neural computation exploiting learning networks quot demonstrated networks learning sequence learning networks neural networks learning neural comp convolutional importance learning networks superglue