论文信息
论文标题:Probabilistic Contrastive Learning for Domain Adaptation
论文作者:Junjie Li, Yixin Zhang, Zilei Wang, Keyu Tu
论文来源:aRxiv 2022
论文地址:download
论文代码:download
1 Abstract
标准的对比学习用于提取特征,然而对于 Domain Adaptation 任务,表现不佳,主要原因是在优化过程中没有涉及类权值优化,这不能保证所产生的特征都围绕着从源数据中学习到的类权值。为解决这一问题,本文中提出一种简单而强大的概率对比学习(PCL),它不仅产生紧凑的特征,而且还使它们分布在类权值周围。
2 Introduction
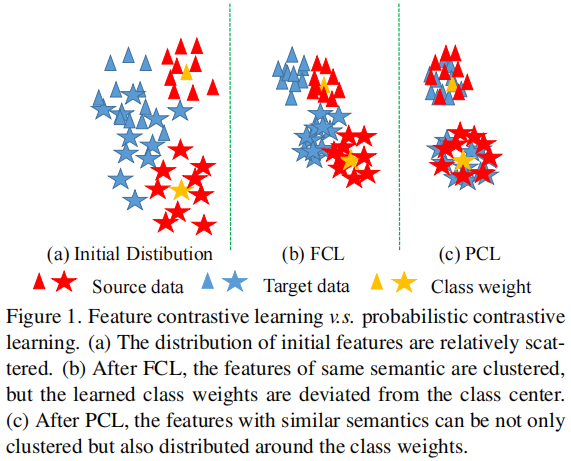
对于分类任务,需要确保特征本身的可区分性,才能获得良好的性能,即:具有相同语义的特性应该尽可能紧凑。然而,在 Domain Adaptation 中,由于目标域缺乏地面真实标签,目标域上学习到的特征通常是分散和难以区分的,如 Figure 1(a) 所示。但是对比学习可以在未标记数据上学习语义上紧凑的特征表示,这倾向于将语义上相似的特征聚在一起。因此,可在目标域上进行特征对比学习(FCL),使目标域的特征更容易区分,如 Figure 1(b) 所示。然而,本文发现 FCL 在 Domain Adaptation 方面带来的改善非常有限(64.3%→64.5%)(见 Figure 2)。这一实证结果自然提出了一个问题:为什么特征对比学习在域自适应方向表现差?

首先,验证对比学习是否确实提高目标域特征的可区分性。具体地说,先冻结特征提取器,并使用地面真实标签来训练分类器。如 Figure 2 所示,在这种设置下,FCL 的准确率提高了6.1%(74.6%→80.7%),但实际的准确率仅提高了 0.2%(64.3%→64.5%)。实验结果表明,FCL 确实可以提高特征的可区分性。此外,在分类的学习过程中可能存在一些问题,导致将对比学习直接应用于领域自适应的表现不佳。
因此,提出了一个很自然的问题:只要引入类权重信息,是否有可能具有接近类权重的特征?为了引入类权重信息,一个简单的思想是直接使用分类器后的特征来计算对比损失。然而,我们发现该方法并不能有效地提高 FCL 的性能,这说明简单地引入类权值并不能有效地减少特征与类权值之间的距离。因此,需要仔细设计一个对比学习损失,可以明确地缩小特征和类权重之间的距离。
为深入理解这个问题,首先考虑了什么样的信息可以表明该特性接近于它的类权重。为方便起见,定义了一组类权值 $W=\left(\mathbf{w}_{1}, \ldots, \mathbf{w}_{C}\right)$,一个特征向量 $\mathbf{f}_{i}$ ,分类概率 $\mathbf{p}_{i}$,$C$ 是类别的数量,概率 $p_{i}$ 的第 $c$ 分量 $p_{i, c}$,由 $p_{i, c}=\frac{\exp \left(\mathbf{w}_{c}^{\top} \mathbf{f}_{i}\right)}{\sum_{j \neq c} \exp \left(\mathbf{w}_{j}^{\top} \mathbf{f}_{i}\right)+\exp \left(\mathbf{w}_{c}^{\top} \mathbf{f}_{i}\right)}$ 定义。假设 $\mathbf{f}_{i}$ 接近 $\mathbf{w}_{c}$,这意味着 $\mathbf{w}_{c}^{\top} \mathbf{f}_{i}$ 变大,$p_{i, c}$ 将接近 $1$。同时,当 $p_{i, c}$ 接近于 1 时, $\left\{p_{i, j}\right\}_{j \neq c}$ 将接近于 0,因为 $\sum_{j} p_{i, j}=1$。也就是说,当 $f_i$ 接近一个类权重时,概率 $p_i$ 将近似 one-hot 形式。
受这种直觉的启发,我们鼓励特征的概率尽可能接近一个 one-hot 形式,以减少特征和类权重之间的距离。在本工作中,我们发现,只要特征被概率取代,并且去除 L2 归一化,对比损失将自动迫使特征的概率接近单热形式,Figure 1(c) 说明了这些结果。
3 Method
我们用特征提取器 $E$ 和分类器 $F$ 定义模型 $M=F \circ E$。这里 $F$ 有参数 $W=\left(\mathbf{w}_{1}, \ldots, \mathbf{w}_{C}\right)$,其中 $C$ 是类的数量,$\mathbf{w}_{k}$ 是第 $k$ 个类的类权重(也称为类原型)。
3.1 Feature Contrastive Learning
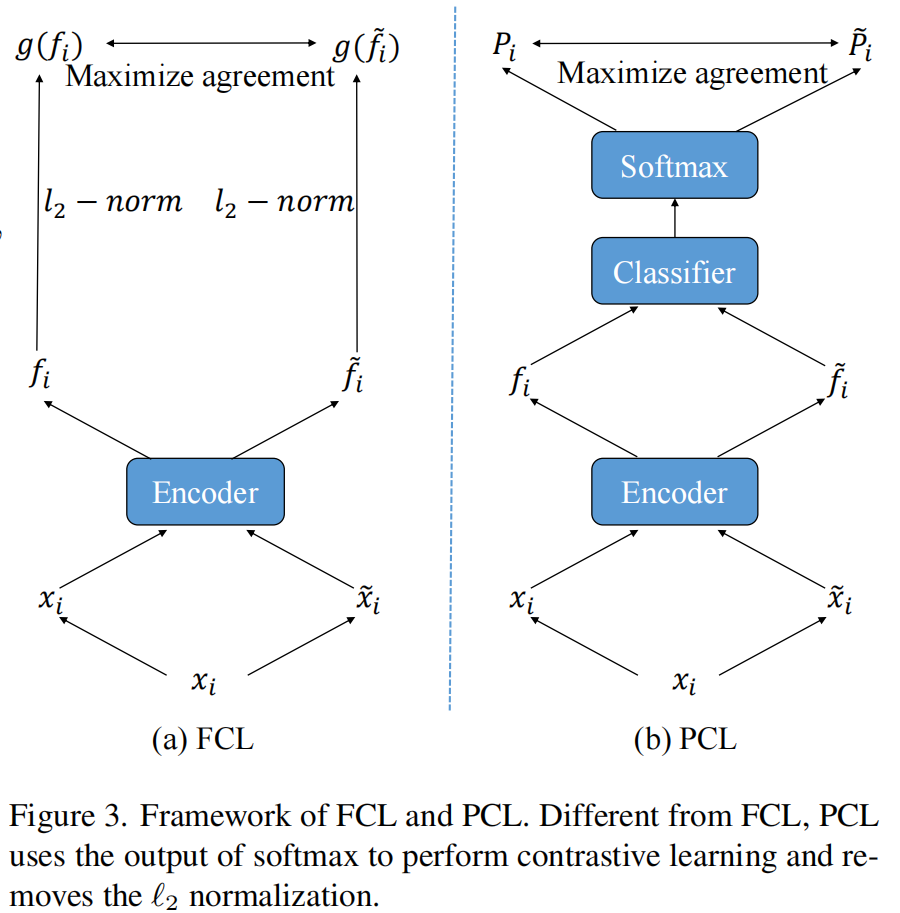
源域图像已有清晰的监督信号,不再需要对比学习。因此,只计算目标域数据的对比学习损失。具体来说,设 $\mathcal{B}=\left\{\left(x_{i}, \tilde{x}_{i}\right)\right\}_{i=1}^{N}$ 是从目标域采样得的批数据,其中 $N$ 是批大小,$x_{i}$ 和 $\tilde{x}_{i}$ 是一个样本的两个随机变换。然后,我们使用 $E$ 来提取特征,并得到 $\mathcal{F}=\left\{\left(\mathbf{f}_{i}, \tilde{\mathbf{f}}_{i}\right)\right\}_{i=1}^{N}$。特征 $\mathbf{f}_{i}$ 和 $\tilde{\mathbf{f}}_{i}$ 是正样本对,其他样本是负样本对。InfoNCE 损失如下:
$\ell_{\mathbf{f}_{i}}=-\log \frac{\exp \left(s g\left(\mathbf{f}_{i}\right)^{\top} g\left(\tilde{\mathbf{f}}_{i}\right)\right)}{\sum_{j \neq i} \exp \left(\operatorname{sg}\left(\mathbf{f}_{i}\right)^{\top} g\left(\mathbf{f}_{j}\right)\right)+\sum_{k} \exp \left(s g\left(\mathbf{f}_{i}\right)^{\top} g\left(\tilde{\mathbf{f}}_{k}\right)\right)} \quad\quad\quad(1)$
其中,$g(\mathbf{f})=\frac{\mathbf{f}}{\|\mathbf{f}\|_{2}}$ 是标准的 L2 标准化,$s $ 是温度可调参。
3.2 Naive Solution
为引入类权重的信息,最直接的方法是利用分类器后的特征来计算对比损失,【即后文的 LCL】。4.1 节显示 LCL 不能提高 FCL 的性能,这是因为 然 LCL 引入了类权值的信息,但 LCL 损失的优化过程并没有直接限制特征和类权值之间的距离。
交叉熵损失函数回顾:
$\operatorname{loss}(\mathrm{x}, \text { class })=-\log \left(\frac{\exp (\mathrm{x}[\text { class }])}{\sum_{\mathrm{j}} \exp (\mathrm{x}[\mathrm{j}])}\right)=-\mathrm{x}[\operatorname{class}]+\log \left(\sum_{\mathrm{j}} \exp (\mathrm{x}[\mathrm{j}])\right)$
https://blog.csdn.net/yyhaohaoxuexi/article/details/113824125
3.3 Probabilistic Contrastive Learning
本文不是设计一种新的信息损失形式,而是关注如何通过构造一个新的输入 $\mathbf{f}_{i}^{\prime}$ 来计算对比损失,使特征 $f_i$ 接近类权重。也就是说,关于 $\mathbf{f}_{i}^{\prime}$ 的损失仍然是由
${\large \ell_{\mathbf{f}_{i}^{\prime}}=-\log \frac{\exp \left(s \mathbf{f}_{i}^{\prime} \tilde{\mathbf{f}}^{\prime}{ }_{i}\right)}{\sum_{j \neq i} \exp \left(s \mathbf{f}_{i}^{\prime} \mathbf{f}_{j}^{\prime}\right)+\sum_{k} \exp \left(s \mathbf{f}_{i}^{\prime \top} \tilde{\mathbf{f}}_{k}^{\prime}\right)} .} \quad\quad\quad(2)$
然后我们的目标是设计一个合适的 $\mathbf{f}_{i}^{\prime}$,这样 $\ell_{\mathbf{f}_{i}^{\prime}}$ 越小,$f_i$ 就越接近类的权重。
$\mathbf{p}_{i}=(0, . ., 1, . ., 0) \quad\quad\quad(3)$
因此,我们的目标可以重新表述为如何设计一个合适的 $\mathbf{f}_{i}^{\prime}$,使 $\mathbf{f}_{i}^{\prime} \tilde{\mathbf{f}}^{\prime}{ }_{i}$ 越大,$\mathbf{p}_{i}$ 越接近Eq.3 中的 one-hot 形式。
$0 \leq p_{i, c} \leq 1,\quad 0 \leq \tilde{p}_{i, c} \leq 1,\quad \forall c \in\{1, \ldots, C\}\quad\quad\quad(4)$
此外,$\mathbf{p}_{i}$ 和 $\tilde{\mathbf{p}}_{i}$ 的 $\ell_{1}$-norm 等于 $1$ ,即:$\left\|\mathbf{p}_{i}\right\|_{1}=\sum_{c} p_{i, c}=1$ 、$\left\|\tilde{\mathbf{p}}_{i}\right\|_{1}=\sum_{c} \tilde{p}_{i, c}=1$。显然,我们有
$\mathbf{p}_{i}^{\top} \tilde{\mathbf{p}}_{i}=\sum_{c} p_{i, c} \tilde{p}_{i, c} \leq 1\quad\quad\quad(5)$
等式成立的条件是 $\mathbf{p}_{i}= \tilde{\mathbf{p}}_{i}$,且 $\mathbf{p}_{i}$ 和 $\tilde{\mathbf{p}}_{i}$ 是 one-hot 形式。
从推导过程中,我们可以看到原型的概率的 1-范数等于 1 的性质是非常重要的。这一性质保证了只有当 $\mathbf{p}_{i}$ 和 $\tilde{\mathbf{p}}_{i}$ 同时满足 one-hot 形式时,才能达到 $\mathbf{p}_{i}^{\top} \tilde{\mathbf{p}}_{i}$的最大值。显然不能像 FCL 一样在概率上使用 L2 范数了,最后,我们新的对比损失定义为
$\ell_{\mathbf{p}_{i}}=-\log \frac{\exp \left(s \mathbf{p}_{i}^{\top} \tilde{\mathbf{p}}_{i}\right)}{\sum_{j \neq i} \exp \left(s \mathbf{p}_{i}^{\top} \mathbf{p}_{j}\right)+\sum_{k} \exp \left(s \mathbf{p}_{i}^{\top} \tilde{\mathbf{p}}_{k}\right)}\quad\quad\quad(6)$
下图给出 FCL 和 PCL 框架的对比:
4 Discussing: Is PCL a trick?
PCL非常简单,看起来像是一个技巧。然而,这种简单操作背后的原理是本文的核心价值。
1.目前的方法[51,52,82]通常将对比学习作为一种提高特征一致性的一般技术,并经常关注假阴性样本问题。很少有作品从减少特征距离和类权重距离的角度来考虑对比学习。因此,我们有理由相信,这不是一个微不足道的观点。
2.基于以上观点,我们通过深入的分析,推导出一个简明的PCL。请注意,尽管PCL有点类似于投影头,但它与投影头有完全不同的动机。我们稍后还将证明,它不能从投影头的角度自然地扩展到PCL。
3.如果没有分析,我们就很难回答:为什么PCL中涉及的两个简单操作如此重要?为什么 logits+L2 normalization 不好?为什么 probability + L2 normalization 的效果不好?
接下来,我们将证明一些常见的对比学习改进策略或自然泛化不能取代PCL在领域适应任务中的作用。
4.1 PCL v.s.FCL
先放一个结果:

实验发现:1) 传统的 FCL 对比 Baseline 在结果上能有一定的提升,2) PCL 对比 FCL 能有 5% 的提升。
4.2 PCL v.s. FCL with Projection Head
① 在特征上先使用一个非线性变换(nonlinear transformation,NT),然后使用 L2 normalization;【NT-Based Contrastive Learning (NTCL)】
② 直接使用分类器的输出作为投影头【 logits contrastive learning (LCL)】
③ 投影头为 Classifier+softmax 【 PCL-L2】
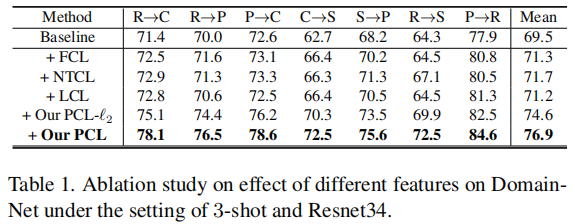
Table1 说明:
-
- 上述三个投影头的性能都低于PCL,说明 PCL 增益的关键原因不是使用投影头;
- LCL 和 PCL-L2 都不如 PCL,这说明简单地引入类权重信息并不能有效地强制执行类权重周围的特征定位;
- 实验结果验证了 PCL 的动机。目前的对比学习方法都遵循 Feature+L2 normalization 的标准范式,且没有理由采用概率的形式和移除 L2 normalization ;
4.3 PCL v.s. SFCL
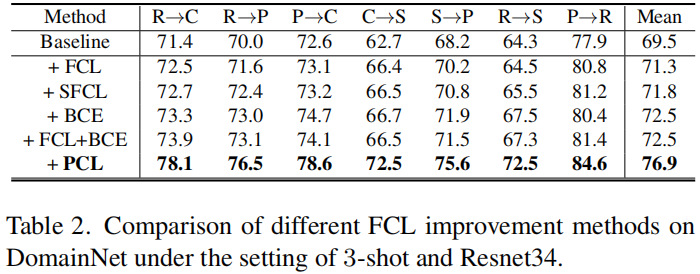
Table 2显示了结果。可以看出,SFCL 确实可以提高 FCL 的性能。然而,与 PCL 相比,SFCL 比 FCL 的改进非常有限。具体来说,SFCL 可以通过减轻假阴性问题来学习更好的特征表示,但它不能解决特征偏离类权值的问题,如FCL。实验结果表明,特征偏离类权值比负样本问题对域自适应更为重要。
4.4 The Importance of InfoNCE Loss
在本节中,将探讨是否有必要使用基于 InfoNC E损失的函数形式来近似的概率得到 one-hot 形式。特别地,考虑了二值交叉熵损失(BCE)。
为方便起见,记 $\mathbf{p}_{i}$ 和 $\tilde{\mathbf{p}}_{i}$ 分别为 $\mathbf{p}_{i}^{0}$、$\mathbf{p}_{i}^{1}$。
其中 $n, m \in\{0,1\}$,$p_{i, j}^{n, m}=\mathbf{p}_{i}^{n \top} \mathbf{p}_{j}^{m}$ ,$\hat{y}_{i, j}^{n, m}= \mathbb{1}\left [ p_{i, j}^{n, m} \geq t \quad \text{ or } \quad (i=j)\right] $,本文设置 $t=0.95$。
BCE loss 会 最大化 $p_{i, j}^{n, m}=\mathbf{p}_{i}^{n \top} \mathbf{p}_{j}^{m}$ ,当 $\hat{y}_{i, j}^{n, m}=1$。$p_{i, j}^{n, m}$ 取最大当且仅当 $\mathbf{p}_{i}^{n}$、$\mathbf{p}_{j}^{m}$ 相等,且有 one-hot 形式。
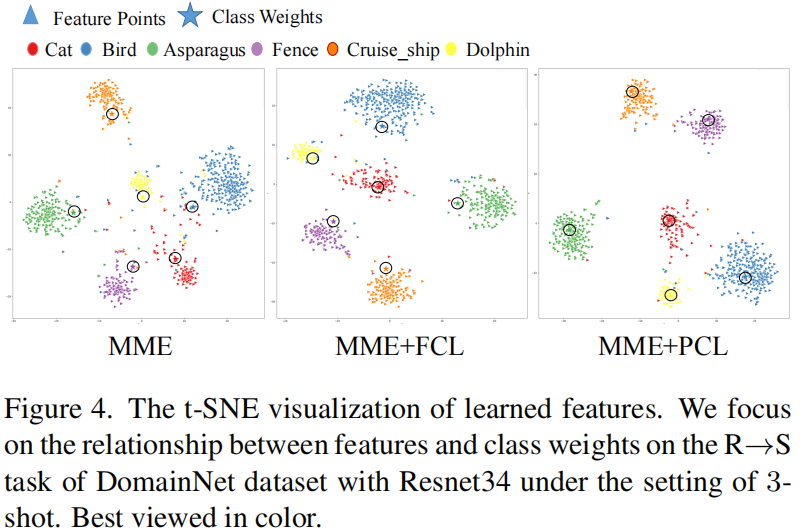
4.5 T-SNE Visualization
- Probabilistic Contrastive Adaptation Learning Domainprobabilistic contrastive adaptation learning domain unsupervised contrastive adaptation clda semi-supervised contrastive adaptation adaptation unsupervised contrastive network domain unsupervised adversarial contrastive adaptation领域domain self-training adaptation training domain adaptation domain moka adversarial domain discriminative unsupervised adaptation backpropagation unsupervised adaptation domain