本文首发于公众号:机器感知
根据语音全身姿态;基于变分贝叶斯框架的VAE模型;CFG是一种隐式的Perceptual Loss!
Diffusion Model with Perceptual Loss

本文研究了扩散模型在生成样本时的质量问题,作者发现使用均方误差损失训练的模型生成的样本往往不真实。当前最先进的模型依赖于CFG来提高样本质量,但其有效性尚未完全搞清楚,本文提出CFG的有效性部分源于其作为隐式感知指导的一种形式,即可以直接将感知损失纳入扩散模型训练中以提高样本质量。本文提出了一种新的自我感知目标函数,使扩散模型能够生成更真实的样本。对于条件生成,该方法仅提高样本质量,不会牺牲样本多样性;该方法还可以提高无条件生成样本的质量,这是在使用CFG时是不可能实现的。
EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Masked Audio Gesture Modeling

EMAGE是一个根据音频和带掩码的手势生成全身人类姿态的框架,涵盖面部、局部身体、手部和全局运动。为了实现这一目标,本文首先引入BEATX(BEAT-SMPLX-FLAME)数据集。BEATX结合了MoShed SMPLX身体和FLAME头部参数,并进一步改进了头部、颈部和手指运动的建模,提供了社区标准化的高质量3D运动捕捉数据集。EMAGE自适应地合并了音频节奏和内容的语音特征,并利用四个组合VQ-VAEs来增强结果的保真度和多样性。实验表明,EMAGE在生成全身姿态上具有最先进的性能,并且可以灵活地接受预定义的时空手势输入,生成完整的、音频同步的结果。
SVFAP: Self-supervised Video Facial Affect Perceiver
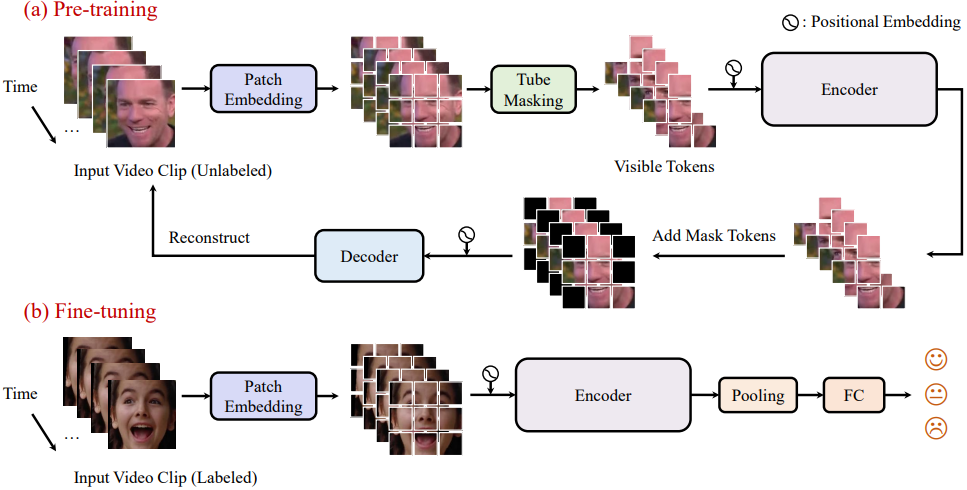
本文提出了一种名为Self-supervised Video Facial Affect Perceiver (SVFAP)的自我监督方法,旨在解决监督学习方法面临的数据标记不足的问题。该方法利用面部视频的掩码自编码进行大规模无标签面部视频的自监督预训练,考虑到面部视频中存在大量的时空冗余,作者提出了一种新颖的时空金字塔和空间bottleneck Transformer作为SVFAP的编码器,既降低了计算成本,又取得了优秀的性能。在九个数据集上进行了涵盖三个下游任务的实验,包括动态面部表情识别、情感识别和个性识别。实验结果表明,SVFAP通过大规模自监督预训练可以学习强大的情感相关表示,并在所有数据集上显著优于之前的方法。
HQ-VAE: Hierarchical Discrete Representation Learning with Variational Bayes
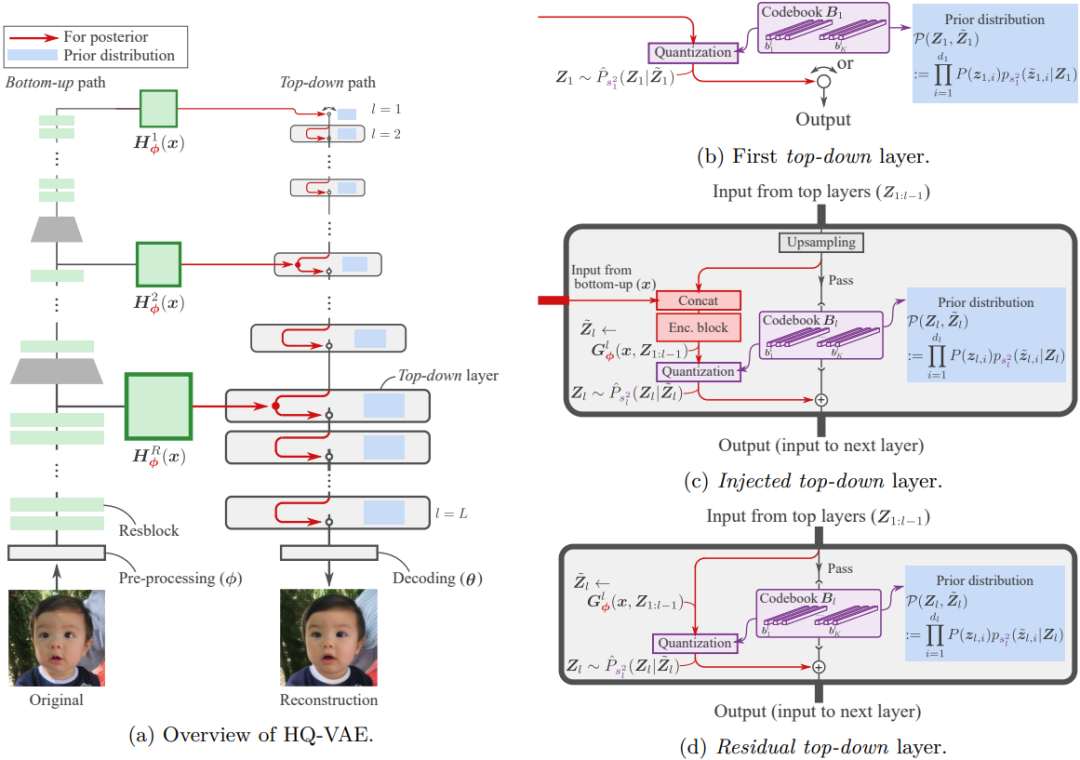
Vector quantization (VQ) 是用离散的码本表示进行确定性学习的特征技术,常与 VQ-VAE 这样的变分自编码模型一起使用。VQ-VAE 可以进一步扩展到层次结构以实现高保真度的重建。然而VQ-VAE 的这种层次扩展经常面临collapse问题。为了缓解这个问题,作者提出了一种基于变分贝叶斯框架的随机学习层级离散表示的统一框架,称为分层量化变分自编码器(HQ-VAE)。HQ-VAE 自然地推广了 VQ-VAE 的层级变体,如 VQ-VAE-2 和残差量化 VAE(RQ-VAE),并为它们提供了一个贝叶斯训练方案。