概述
相对于基于传统 x86架构的处理器来说,Amazon 设计的基于 ARM 架构的 Graviton 处理器为 EC2中运行的云工作负载提供了更佳的性价比。基于 Graviton2 的实例支持广泛的通用型、突发型、计算优化型、内存优化型、存储优化型和加速计算型工作负载,包括应用程序服务器、微服务、高性能计算 (HPC)、基于 CPU 的机器学习 (ML) 推理、视频编码、电子设计自动化、游戏、开源数据库和内存中的缓存等。由 Graviton2 处理器支持的 EC2实例 (M6g、C6g、R6g和T4g) 在中国区已经上线一段时间,本文以土壤微生物宏基因测序为例,来演示如何利用Amazon Batch 服务调用基于 Graviton2处理器的实例用于基因分析,并且验证 Graviton2相对于 x86架构的处理器能够给用户带来的收益。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
先决条件
您需要一个 Amazon 帐户来完成本演练,其它条件包括(本篇不再描述其具体使用方式):
- Amazon CLI v2安装和配置
- 完成 VPC 的设置,包括公有子网、私有子网和 NAT 的配置等
- 熟悉 EC2服务的使用,熟悉 EFS、S3等存储服务的使用
- 熟悉 Batch 服务的使用,包括计算环境、任务队列、任务定义的配置
- 熟悉生信软件(bwa,samtools,coverm)的安装配置
- 熟悉容器的使用
整体架构
本文演示了一个基于 Amazon Batch 服务来进行任务调度的方案, Batch 是 Amazon 托管的一个批量计算服务,用户可以通过它运行任意规模的容器化工作负载,目前已经广泛应用于基因分析、药物研发等高性能计算的场景。本方案整体架构及用到的服务如下:
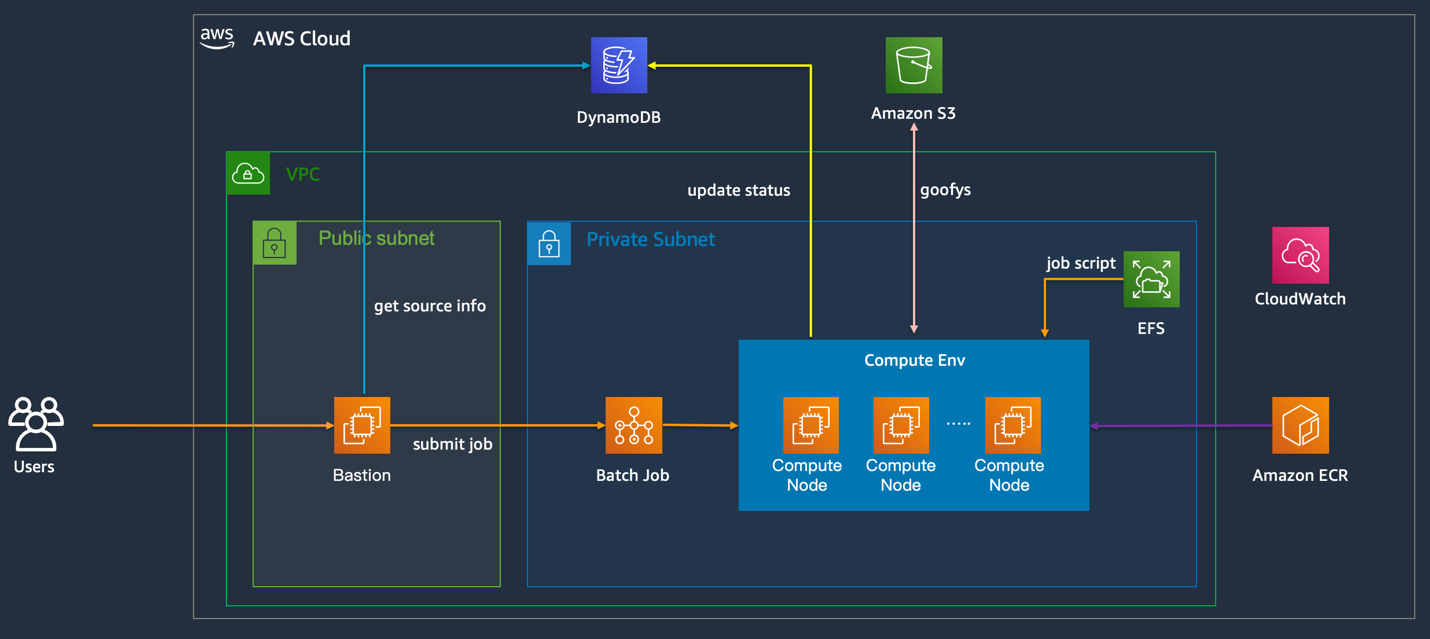
方案描述:
- Batch 批量计算任务调度,启动大量计算节点用于计算
- S3 存储输入和输出数据
- EFS 映射到容器中,用于存放运行脚本
- DynamoDB 保存输入数据的信息及处理状态,运行脚本从中读取需要处理的文件列表并更新处理状态
- ECR 作为容器镜像仓库
- CloudWatch 监控性能指标及查看日志
- 开源软件 goofys,挂载 S3存储桶到容器中,简化 S3上数据读取方式,优化 S3到 EC2的数据读取性能
- 跳板机,用于操作云上资源
软件适配 把原先在 x86架构下的工作负载迁移到 ARM 架构下,首先我们要在 ARM 架构下完成软件的适配。本次演示主要用到 bwa,samtools 和 coverm 三个软件,以下演示如何在 ARM 架构下完成对这些软件的编译并且构建容器镜像。
EC2
启动一台 EC2使用作为开发环境,AMI:Amazon Linux2,实例类型 t4g.medium(必须是 Graviton 机型)。若在中国区编译 coverm 碰到网络问题,可在 Global 区域启动该 EC2,做完容器镜像后直接推送回中国区的 ECR。
安装 Docker
sudo yum update -y sudo amazon-linux-extras install docker -y sudo systemctl start docker sudo systemctl enable docker sudo usermod -a -G docker ec2-user
登录 EC2安装 docker 后,退出,再重新登录以接受新的 docker 组权限
AWSCLI v2
curl "https://awscli.amazonaws.com/awscli-exe-linux-aarch64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
配置好中国区 AK/SK,为了后续推送容器镜像到国内 ECR
基础镜像
docker pull centos
创建一个目录用于保存后续构建容器镜像需要的文件
mkdir docker
cd docker
bwa
wget https://github.com/lh3/bwa/releases/download/v0.7.17/bwa-0.7.17.tar.bz2 wget https://gitlab.com/arm-hpc/packages/uploads/ca862a40906a0012de90ef7b3a98e49d/sse2neon.h
samtools
wget https://github.com/samtools/samtools/releases/download/1.15.1/samtools-1.15.1.tar.bz2
coverm
起一个容器编译 coverm
docker run --name coverm -v /home/ec2-user/docker:/data -itd centos
进入容器
docker exec -it coverm bash sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-* sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-* yum install git gcc cmake3 -y curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh source $HOME/.cargo/env git clone https://github.com/wwood/CoverM cd CoverM cargo build --release
复制可执行文件到外部存储
cp target/release/coverm /data/coverm
goofys
goofys 用于将 S3存储桶映射到容器中,简化 S3文件读取,将文件直接从 S3读取到 EC2内存,无需落盘,从而加快文件读取速率
编译
yum install go git clone https://github.com/kahing/goofys.git cd goofys GOOS=linux GOARCH=arm64 go build
复制可执行文件到外部存储
cp goofys /data/goofys
退出容器
exit
镜像构建
确保 bwa-0.7.17.tar.bz2, samtools-1.15.1.tar.bz2, coverm, goofys, awscliv2.zip 和 sse2neon.h 已经保存到之前创建的 docker 目录,编辑如下 Dockerfile:
FROM centos ADD bwa-0.7.17.tar.bz2 samtools-1.15.1.tar.bz2 coverm goofys awscliv2.zip sse2neon.h /opt/ WORKDIR /opt RUN \ sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-* && \ sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-* && \ yum install unzip gcc-c++ make autoconf ncurses-devel bzip2 bzip2-devel xz-devel zlib-devel fuse fuse-devel -y && \ yum clean all && \ #awscli unzip awscliv2.zip && \ ./aws/install && \ rm -rf awscliv2.zip aws && \ #bwa cd bwa-0.7.17 && \ sed -i -e 's/<emmintrin.h>/"sse2neon.h"/' ksw.c && \ mv /opt/sse2neon.h . && \ make && \ cd .. && \ #samtools cd samtools-1.15.1 && \ autoheader && \ autoconf -Wno-syntax && \ ./configure && \ make && \ make install && \ cd .. && \ #coverm mkdir tools && \ mv coverm tools && \ #goofys mv goofys tools WORKDIR /data ENV PATH=$PATH:/opt/bwa-0.7.17:/opt/tools/
构建镜像
docker build -t mapping-graviton .
创建 ECR 镜像仓库 mapping-graviton 并查看推送命令推送镜像到该仓库

云上环境设置
S3
S3存储桶包含3个目录

source 目录存放输入序列,results 存放结果数据

ref_data 目录存放参考基因组的索引库

DynamoDB
创建一张表用于保存 S3上的输入序列信息,投递任务的脚本从表中读取需要处理的基因序列列表,循环投递任务。在任务运行的时候,根据不同的处理阶段,更新表中对应序列的状态值。
参照以下命令向表中插入数据:
aws ddb put reads_graviton '{sample: 'SRR11676645', r1: 'source/SRR11676645_1.fastq.gz', r2: 'source/SRR11676645_2.fastq.gz', status: '0'}'

EFS
创建一个 EFS 文件系统(fs-0a8685ad57ce63a3f),开发环境挂载 EFS 文件系统,在文件系统中创建 mapping 目录,保存 mapping.sh 到该目录下(放在容器外面主要是为了调试及修改方便,不用每次都重新构建镜像)

EC2启动模板
修改根卷为 gp3,200G(根据实际需要调整大小),设备名称指定自定义值/dev/xvda

在测试阶段,若需要监控内存使用率,可在高级详细信息→用户数据,输入以下 CloudWatch Agent 配置
在生产阶段,如果有大量任务运行,建议不要配置 CloudWatch Agent,因为有可能产生指标数量过多的费用
MIME-Version: 1.0 Content-Type: multipart/mixed; boundary="==MYBOUNDARY==" --==MYBOUNDARY== Content-Type: text/x-shellscript; charset="us-ascii" #!/bin/bash yum install amazon-cloudwatch-agent -y cat << EOF > /opt/aws/amazon-cloudwatch-agent/bin/config.json { "agent": { "metrics_collection_interval": 30, "run_as_user": "root" }, "metrics": { "append_dimensions": { "InstanceId": "\${aws:InstanceId}", "InstanceType": "\${aws:InstanceType}" }, "metrics_collected": { "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 30 }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 30 } } } } EOF /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json --==MYBOUNDARY==--
IAM 角色
Batch 需要的两个角色,附加合适的权限

ecsInstanceRoleBatchJobRole

计算环境
创建配置文件 ce.json:
subnets:配置了 NAT 网关路由的私有子网
securityGroupIds:默认安全组 id
instanceTypes:使用的 r6g 实例类型 tags:EC2标签
123456789012:换成您自己的12位 Amazon 账户 id
{ "computeEnvironmentName": "env-mapping-graviton", "type": "MANAGED", "state": "ENABLED", "computeResources": { "type": "EC2", "allocationStrategy": "BEST_FIT", "minvCpus": 0, "maxvCpus": 2560, "desiredvCpus": 0, "instanceTypes": [ "r6g" ], "subnets": [ "subnet-03388bca5b37db2b9", "subnet-0fafc120e429ec25d" ], "securityGroupIds": [ "sg-0468dd9696811b7b8" ], "instanceRole": "arn:aws-cn:iam::123456789012:instance-profile/ecsInstanceRole", "tags": { "Name": "batch-mapping-graviton" }, "launchTemplate": { "launchTemplateName": "lt-batch-zju", "version": "9" } }, "serviceRole": "arn:aws-cn:iam::123456789012:role/aws-service-role/batch.amazonaws.com/AWSServiceRoleForBatch" }
创建计算环境
aws batch create-compute-environment --cli-input-json file://ce.json
任务队列
创建配置文件 jq.json:
computeEnvironment:上一步创建的计算环境的 arn
{ "jobQueueName": "q-mapping-graviton", "state": "ENABLED", "priority": 1, "computeEnvironmentOrder": [ { "order": 1, "computeEnvironment": "arn:aws-cn:batch:cn-northwest-1:123456789012:compute-environment/env-mapping-graviton" } ] }
创建任务队列
aws batch create-job-queue --cli-input-json file://jq.json
任务定义
创建配置文件 jd.json:
privileged: 容器中运行 goofys 需要开启特权模式,设为 true
{ "jobDefinitionName": "jd-mapping-graviton", "type": "container", "parameters": { "r2": "source/SRR11676645_2.fastq.gz", "dbtable": "reads_graviton", "sample": "SRR11676645", "script": "mapping.sh", "r1": "source/SRR11676645_1.fastq.gz" }, "containerProperties": { "image": "123456789012.dkr.ecr.cn-northwest-1.amazonaws.com.cn/mapping-graviton:latest", "command": [ "sh", "Ref::script", "Ref::sample", "Ref::r1", "Ref::r2", "Ref::dbtable" ], "jobRoleArn": "arn:aws-cn:iam::123456789012:role/BatchJobRole", "volumes": [ { "name": "efs", "efsVolumeConfiguration": { "fileSystemId": "fs-0a8685ad57ce63a3f", "rootDirectory": "mapping" } } ], "environment": [ { "name": "S3_MOUNT_POINT", "value": "/s3" } ], "mountPoints": [ { "containerPath": "/data", "sourceVolume": "efs" } ], "privileged": true, "resourceRequirements": [ { "value": "64", "type": "VCPU" }, { "value": "500000", "type": "MEMORY" } ] }, "platformCapabilities": [ "EC2" ] }
注册任务定义
aws batch register-job-definition --cli-input-json file://jd.json
任务脚本 mapping.sh
实际任务运行所调用的脚本(保存到 EFS 的 mapping 目录下)
sample=$1 r1=$2 r2=$3 dbtable=$4 echo 'sample: '$sample', r1: '$r1', r2: '$r2', dbtable: '$dbtable echo 'mount s3 bucket' mkdir -p $S3_MOUNT_POINT goofys --region cn-northwest-1 sun-test $S3_MOUNT_POINT base_dir=$S3_MOUNT_POINT ls -lh $base_dir echo 'job done set status to 1' aws dynamodb execute-statement --statement "UPDATE $dbtable SET status=1 WHERE sample='$sample'" echo 'bwa start' mkdir /result bwa mem -t 64 $base_dir/ref_data/derep_all.fa $base_dir/$r1 $base_dir/$r2 > /result/$sample.sam echo 'samtools start' samtools sort /result/$sample.sam -@ 64 -o /result/$sample.bam echo 'rm sample' rm /result/$sample.sam echo 'job done set status to 2' aws dynamodb execute-statement --statement "UPDATE $dbtable SET status=2 WHERE sample='$sample'" echo 'coverm filter start' coverm filter --min-read-percent-identity 0.95 --min-read-aligned-percent 0.75 -b /result/$sample.bam -o /result/${sample}_filter.bam -t 64 echo 'copy '${sample}_filter.bam' to s3' mkdir -p $base_dir/results/$dbtable cp /result/${sample}_filter.bam $base_dir/results/$dbtable/ echo 'job done set status to 3' aws dynamodb execute-statement --statement "UPDATE $dbtable SET status=3 WHERE sample='$sample'" echo 'rm result '$sample.bam' from local disk' rm /result/$sample.bam echo 'coverm contig start' coverm contig --trim-max 90 --trim-min 10 --min-read-aligned-percent 70 -t 64 --bam-files /result/${sample}_filter.bam > /result/${sample}_coverage.csv echo 'copy to s3' cp /result/${sample}_coverage.csv $base_dir/results/$dbtable echo 'job done set status to 4' aws dynamodb execute-statement --statement "UPDATE $dbtable SET status=4 WHERE sample='$sample'" echo 'rm result '${sample}_filter.bam' from local disk' rm /result/${sample}_filter.bam
run_mapping.sh
通过 run_mapping.sh 来读取数据库中序列信息并循环提交多个 Batch 任务,该脚本可在跳板机或本地执行
dbtable='reads_graviton' item=`aws ddb select $dbtable --filter 'status = 0' ` count=`echo $item | awk '{print $2}'` echo 'count: '$count if [ $count -eq 0 ] then echo 'end' break fi info=`echo $item | awk '{for(i=10;i<=NF;i=i+9){print $i}}'` fastq_1=`echo $item | awk '{for(i=6;i<=NF;i=i+9){print $i}}'` fastq_2=`echo $item | awk '{for(i=8;i<=NF;i=i+9){print $i}}'` for ((i=1;i<=$count;i++)) do sample=`echo $info|awk '{print $'$i'}'` echo 'sample= '$sample r1=`echo $fastq_1|awk '{print $'$i'}'` echo 'r1= '$r1 r2=`echo $fastq_2|awk '{print $'$i'}'` echo 'r2= '$r2 jobname=${dbtable}_${sample%.*} echo 'jobnane= '$jobname aws batch submit-job --job-name $jobname --job-queue q-mapping-graviton --job-definition jd-mapping-graviton:1 --parameters script=mapping.sh,sample=$sample,r1=$r1,r2=$r2,dbtable=$dbtable done
测试
按照类似的方法再创建一套基于 x86架构的 Batch 计算环境、任务队列、任务定义(不再赘述创建方法),相同的任务分别投递到 arm 和 x86环境,进行对比测试。
单个序列比对任务需要用到的内存为300G+,故使用类型为r6g.16xlarge 和 r5.16xlarge 的 EC2实例进行对比测试, 测试结果如下:
CPU/MEM 监控-CloudWatch
SRR11676645

SRR11676933

FDMS190655335

在计算阶段,r6g.16xlarge 和 r5.16xlarge 的资源利用率几乎一致,CPU 利用率都能到100%,内存利用率都为60%左右
用时

r6g.16xlarge 相对 r5.16xlarge 所需时间大约减少16%左右
EC2价格对比

r6g.16xlarge相对r5.16xlargeEC2价格大约下降20%左右
结论
基于 Batch 的任务调度,在计算任务完成之后,Batch 会自动终止不再运行任务的 EC2实例,所以时间的节约也能带来 EC2和 EBS 的成本节约。根据以上测试结果,在基因测序序列比对这个场景下,使用 ARM 架构的 Graviton 实例,相对于5代 x86实例,能有:
- 16%左右时间节约
- 16%左右 EBS 成本节约
- 1 – (1-16%) x (1-20%) = 32.8%左右 EC2成本节约
在这篇文章中,我们演示了如何基于 Graviton2处理器所支持的 EC2实例,在 Amazon 上使用 Batch 服务来运行基因测序的工作负载。并且根据测试的结果,使用 Graviton2处理器用于基因测序的序列比对场景,能够很好的满足用户对于性能和成本的需求。只要您的工作负载所用的操作系统和软件能够适配 ARM 架构,在 Amazon 上就可以利用 Graviton 处理器高性价比的特点来达到降本增效的目的。
参考文档
Amazon Batch 用户指南:
https://docs.aws.amazon.com/zh_cn/batch/latest/userguide/what-is-batch.html?trk=cndc-detail
利用 Amazon Batch 来为容器化负载调用海量云端算力:
在云中对基因组学工作负载进行基准测试的通用方法:在 Graviton2 上运行 BWA 读取对齐器:
本篇作者

孙亮
Amazon 解决方案架构师,硕士毕业于浙江大学计算机系。在加入 Amazon 之前,拥有多年软件行业开发经验。目前在 Public Sector 部门主要服务于生命科学和医疗健康相关的行业客户,致力于提供有关 HPC、容器、无服务器、数据安全等各类云计算解决方案的咨询与架构设计。

刘光
Amazon 资深解决方案架构师,目前负责基于 Amazon 云计算方案架构的咨询和设计,同时致力于 Amazon 云服务在政企、教育和医疗行业客户的推广。在加入 Amazon 之前就职于 Citrix,具有多年企业虚拟化、VDI 架构设计和支持经验。
文章来源: