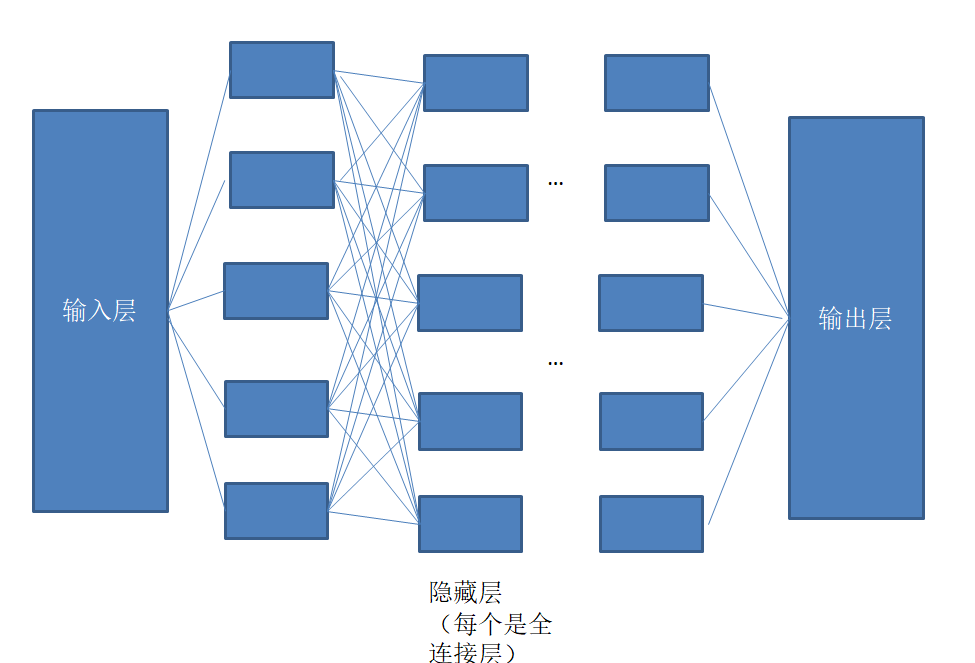
1.前馈神经网络
前馈神经网络就是上次提到的网络模型的基础上它仅可以向前传播,往前传播应该有的权值w,不断提取特征
2.损失函数
损失函数是什么?
- 它是输入之后在隐藏层的传播过程中每一次数据传入对它预测结束之后都有一个预测值,这个预测值和真实得出来的结果有一定的误差,对这个误差进行拟合,需要用一些函数,这些函数就是损失函数
常见的有: -
C(w)=0.5*Σ(td-od)^2;
-
C(w)=-1/n*Σ∑|tdln(od)|;
td,od分别为预测值和真实值;
然后解释一下这里为啥要乘0.5,因为后面要反向传播进行调整超参数进行模型的优化,方法就是不断反向的求偏导,求导的过程消除平方项,所以加0.5,这个0.5对于结果是几乎没影响的。
从中也可看出差值越大,C(w)就越大,损失函数的值就越大,所以应该不断调整,最后使得C(w)很小,这个模型才算完成。
3.梯度下降
我们应该如何去找这个C(w)损失函数的最小值呢,就是找他的极小值,极小值就要求导,导数为0的点,而梯度就是导数绝对值最大的那个点,沿着梯度下降的方向去找,就能找到导数绝对值最大的点,因为是极小值,所以绝对值加负号,就是梯度不断下降,所以简称梯度下降算法。
但是可能会存在局部的一个极值,也就是局部最小点,局部梯度很大,所以这就是梯度下降算法存在的一个缺陷,例如下图(我画了二维平面的一个曲线的梯度下降算法,因为三位也是,只不过把曲线换成曲面而已):
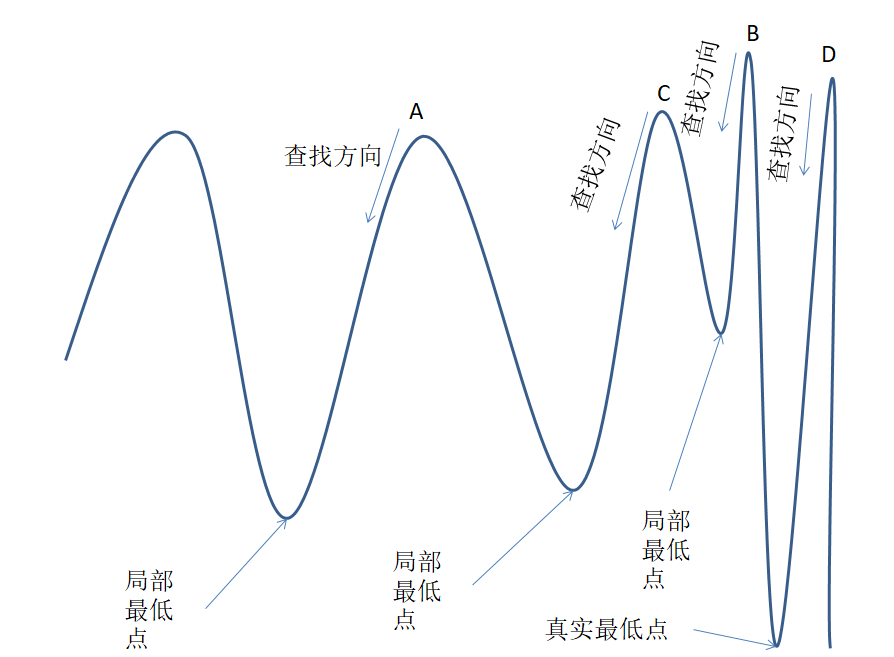
其中ABCD为我们近四次预测的损失值,然后不断向下的方向去找,很明显每个都会找到极值点,但是不同,找到一个极值就停止,就容易走到局部的一个点。
4.梯度下降的算法
- 全局梯度下降算法(BGD)
就是每次把全部数据放进去计算得到所有的损失函数的值,然后求平均 - 随机梯度下降算法(SGD)
每次随机取一个作为代表来求差值 - 小批量梯度下降算法(MBGD)
这种上述两种,即每次取一部分作为代表然后求他们的平均值
5.最后,总结
-
前馈神经网络,只能向前传播,然后不断提取特征直到输出;
-
损失函数是输入之后在隐藏层的传播过程中,预测值和真实得出来的结果的误差进行拟合的函数
-
C(w)=0.5*Σ(td-od)^2;要乘0.5,因为后面要反向传播进行调整超参数进行模型的优化不断反向的求偏导,求导的过程消除平方项,所以加0.5,不影响结果;
-
沿着梯度下降的方向去找,就能找到导数绝对值最大的点,梯度不断下降,所以简称梯度下降算法。
-
反向传播,就是反向求偏导,梯度爆炸就是很多个偏导相乘趋近于∞,反之,趋近于0就是梯度消失。
-
三种梯度下降算法:BGD,SGD,MBGD,最好的是MBGD(结合前面两种)。