DQNViz: A Visual Analytics Approach to Understand Deep Q-Networks
论文/强化学习可视化
摘要
打算研究深度强化学习方向,整理最近的一篇 2019 年的论文,作为总结思考!
论文介绍
该论文是一篇 2019 年,有关基于可视化进行强化学习可解释的文章。一作是 Junpeng Wang ,作者主要研究领域就是:visualization, visual analytics, explainable AI。作者主页:https://junpengw.github.io/#/
主要工作
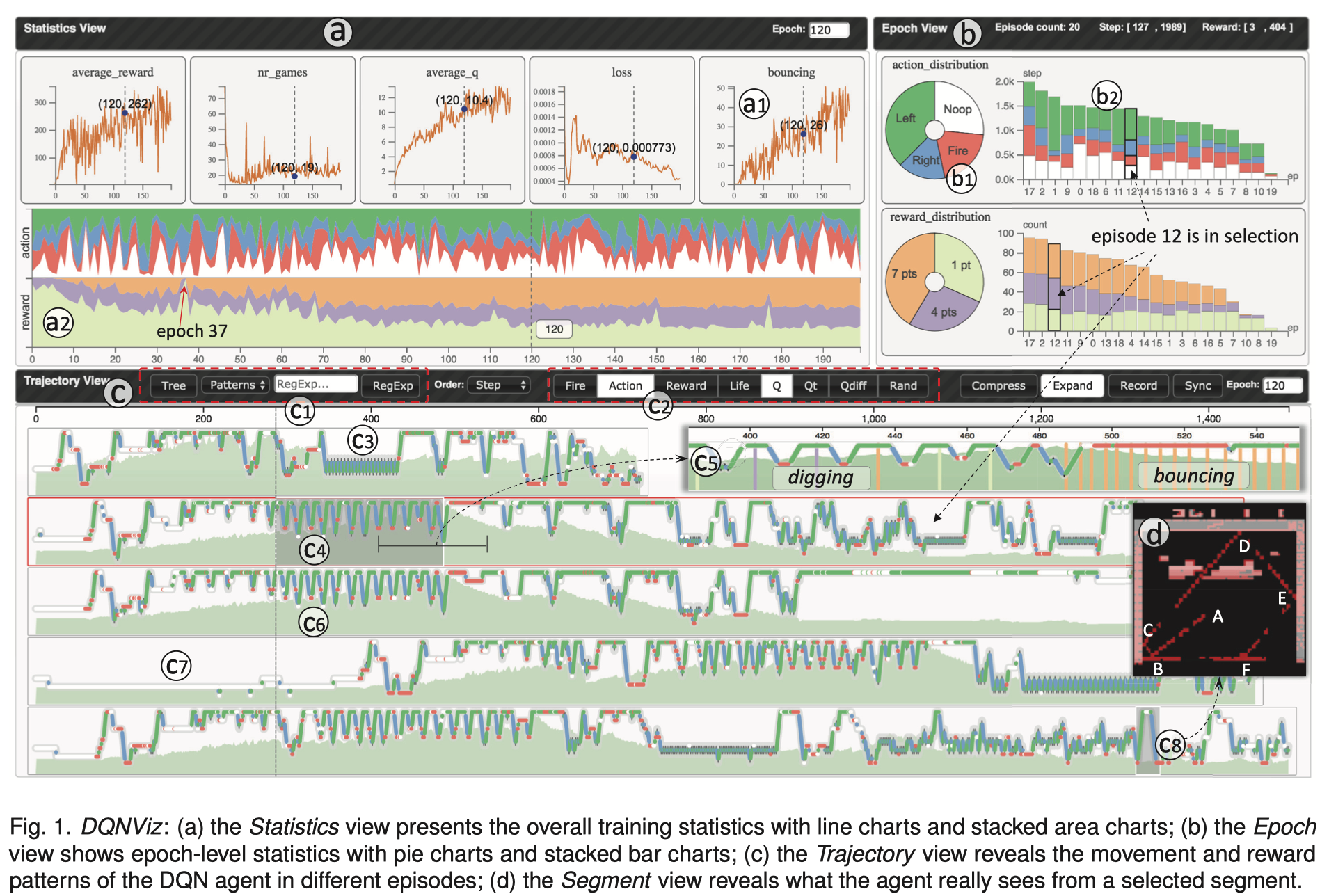
该论文主要工作是构建一个可视化系统 DQNViz ,DQNViz 系统通过四个层面分析了 DQN 模型的训练过程。
四个层面分别是:整体训练水平、训练轮次/时代(Epoch)、剧集层次(Episode)、片段层次。step ⊆ segment ⊆ episode ⊆ epoch.
同时,论文基于 DQNViz 系统提出了一种有关序列型数据新的可视设计。强化学习领域专家通过利用DQNViz 系统分析并提出了一种模型改进方法,这种方法主要是针对于模型中控制随机动作的问题。
思考
时间序列类型数据可视化问题
问题描述
对于 DQN 模型训练过程中的时间序列类型数据有什么更加有效直观的视觉设计?比如如何以有效的方式显示智能体在事件序列中的运动模式,可能包括其行为轨迹、决策路径等?如何展示不同类型的事件序列,使得观察者能够更全面地理解智能体的行为和决策?
相关资料
- S. Guo, K. Xu, R. Zhao, D. Gotz, H. Zha, and N. Cao. Eventthread: Visual summarization and stage analysis of event sequence data. IEEE transactions on visualization and computer graphics, 24(1):56–65, 2018.
- LifeLines [38], LifeFlow [53], CloudLines [25], EventFlow [34], DecisionFlow [15] MatrixFlow [36] and MatrixWave [55] EgoLines [54], EventThread [16]
解决方法
-
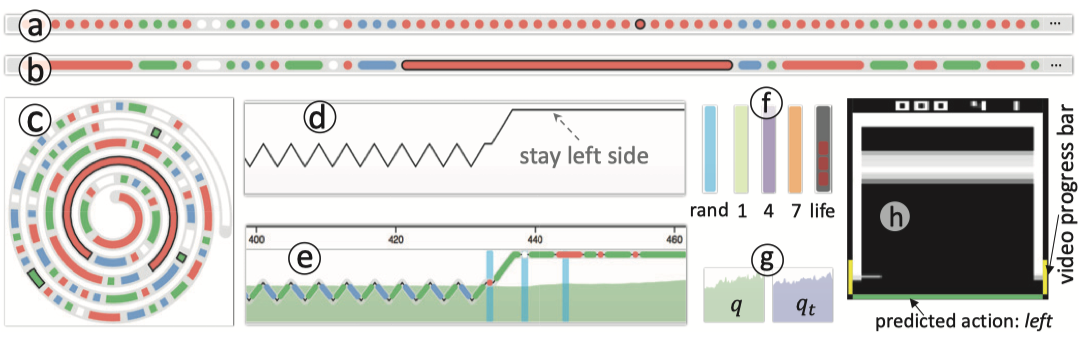
不同背景颜色的圆表示不同动作,圆加黑色边框表示该动作获得奖励,连续相同的动作行为表示的圆可以连在一起用线表示。
-
使用水平线条移动轨迹表示游戏中挡板的移动轨迹,比如水平图中,线往上方走表示挡板在向左移动,同时线是由连续圆组成,这种也是也便于扩展,因为水平线图是可以压缩的
-
同时也可展示其他数据,比如高亮的青色背景条表示此时为随机动作,绿色、紫色和橘色背景条则分别表示获得奖励值(1、4、7),灰色表示游戏终止。半透明绿色和紫色则代表 q 值和 qt 值
-
通过刷选一段区域可重放其游戏画面,重放画面两侧黄色条则表示训练进程,画面下方的颜色条表示智能体预测动作
智能体模式挖掘问题
问题描述
如何在一个训练轮次产生的大量数据中挖掘出智能体执行的模式?
相关资料
- S. Salvador and P. Chan. Toward accurate dynamic time warping in linear time and space. Intelligent Data Analysis, 11(5):561–580, 2007.
- K. Thompson. Programming techniques: Regular expression search algorithm. Communications of the ACM, 11(6):419–422, 1968.
- A. V. Aho and J. D. Ullman. Foundations of Computer Science (Chapter 10: Patterns, Automata, and Regular Expressions). Computer Science Press, Inc., New York, NY, USA, 1992.
- J. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller. Striving for simplicity: The all convolutional net. In ICLR (workshop track), 2015.
解决方法
片段聚类
- 将一个训练轮次中的不同剧集分类成不同片段集合,片段采用数值序列表示,从而采用dynamic time warping algorithm (DTW)量化不同片段间的相似程度,比较同一训练轮次中的全部片段,生成一个相似度矩阵
- 将上一步的相似度矩阵作为聚类算法的输入,通过生成层次树图选取同一训练轮次中相同的训练片段
模式挖掘
- 将动作采用数值表示,提前预定义模式规律,比如动作模式,重复 0{30, },表示重复动作 0 (noop)连续至少 30 次即为动作重复模式。 同样定义奖励模式,比如弹跳模式 (70+){5}, 表示小球击打最上层砖块连续至少 5 次,即视为弹跳模式
生成特征显著图
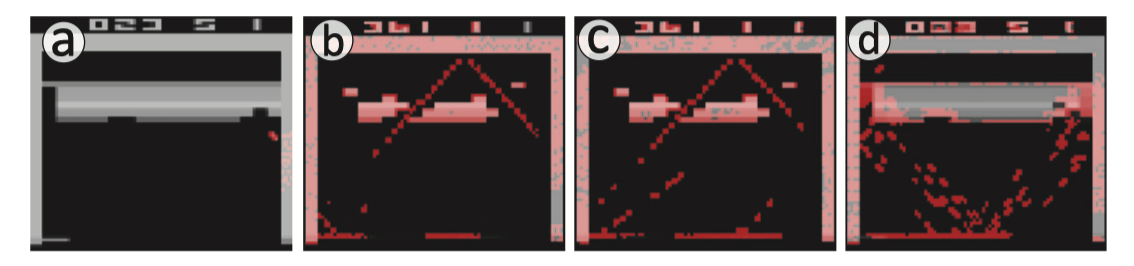
- 定于算法,从一个片段(屏幕)中挑选出最大激活状态(最大状态),并为每个卷积层的每个卷积滤波器生成该状态的相应显著性图(映射)。总体来说,找到卷积滤波器最大激活的状态意味着确定在输入数据中,该滤波器最强烈地响应的位置,从而揭示了输入数据中与该滤波器所学到的特定特征最相关的部分。从而有效理解和解释智能体网络预测结果。通过前向传播获得最大激活的状态的激活值,再通过反向传播获得该最大激活状态片段的特征显著图。

控制随机动作问题
问题描述
如何利用可视化优化强化学习研究中的控制随机动作问题?
控制随机动作问题: 控制随机动作问题意味着在训练过程中,需要找到一种方法来平衡随机探索和利用已知信息的过程,以便更有效地学习。如果随机动作的影响过大,可能导致模型无法收敛或收敛到次优解。
相关资料
- V. Franc¸ois-Lavet, R. Fonteneau, and D. Ernst. How to discount deep reinforcement learning: Towards new dynamic strategies. NIPS Deep Reinforcement Learning Workshop, arXiv preprint arXiv:1512.02011, 2015.
解决办法
-
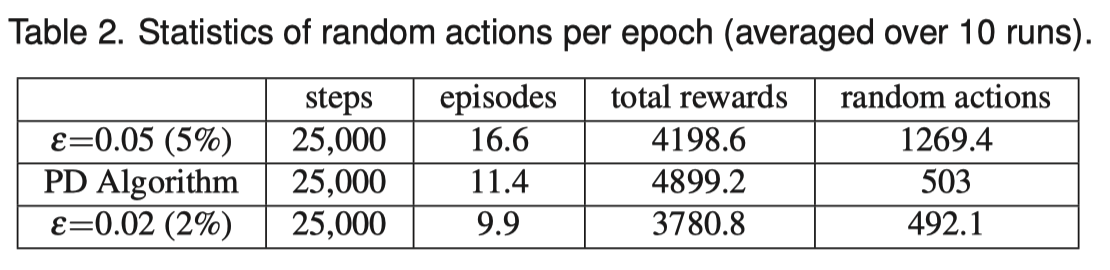
配合使用 DQNViz 系统,分别设计三个实验:随机率为 0.05 、使用pattern detection (PD) algorithm 算法、随机率 0.02 观察实验结果。
-
PD 算法,模式探索算法,首先维护一个缓存最后 20 步的缓冲区,如果这 20 步中获得奖励,则无需进行随机动作,否则,要是长时间未获得奖励或者探索到了重复 0{30, }的动作模式则进行随机动作。