背景
这是Facebook应用在社交搜索召回上的一篇论文,与传统搜索场景(google,bing)不同的是,fb这边通常需要更加考虑用户的一些画像,比如位置,社交关系等。举个例子:fb上有很多John Smith,但用户使用查询“John Smith”搜索的实际目标人很可能是他们的朋友或熟人。 或者 一个cs专业的学生,搜索John Smith,很可能是John Smith是领域知名学者。因此fb场景不但要关注文本相关性,还要关注context以及用户画像。
模型结构
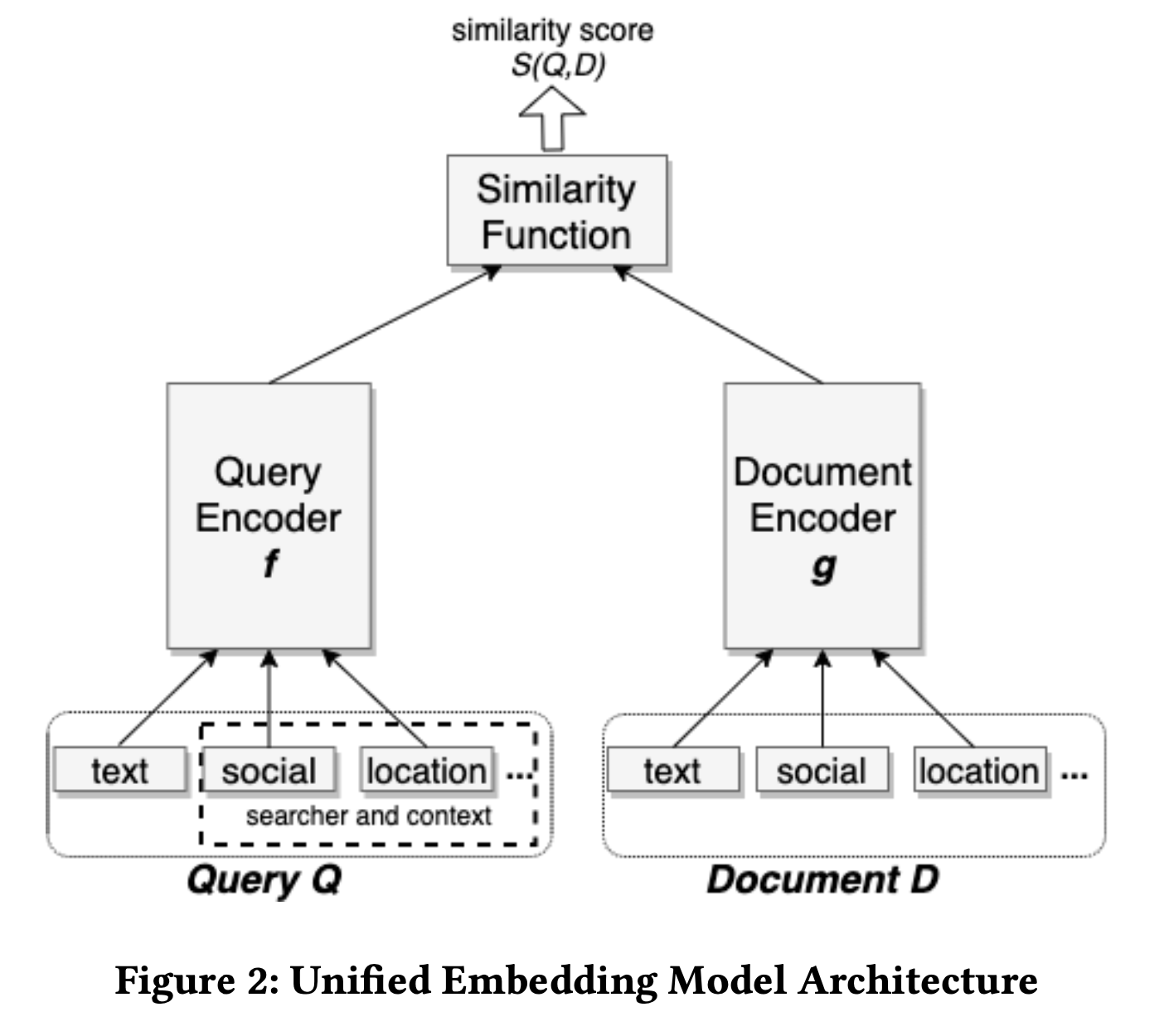
本文的模型就是经典的双塔模型,query与doc分开,同时特征也不只有文本,还有用户与doc的特征。
评测指标
论文为了离线快速验证模型有效性,fb采用了top k召回率作为评价指标:

这里的N就是实际正样本数目,di 可以是点击或其它label
特征
本文主要介绍了三大类特征,当然实际上线应该还是有更多的特征,作者指出相对于只使用text feature,使用提到的所有特征可以再不同搜索场景有16%-18%的提升,证明了个性化搜索在Facebook搜索场景上的必要性。
- Text features
- 这里的文本特征,对比了character n-gram和word n-gram,发现character n-gram的结果好更好,主要有两方面的原因: 一方面是character的vocabulary size小一点,所以emb可以学的更充分一点,另一方面对比如拼写错误,单词形式等情况鲁棒性更强一点。
- 同时作者给出了一个实验现象,他们发现在character n-gram的基础上使用word n-gram,依然可以有+1.5% recall。考虑到word的vocabulary size很大很大,作者减少了hash size,依然有一定的提升。
- 同时作者指出,把text feature进行emb化相对于之前Boolean term matching的做法,在模糊文本匹配,以及不规则输入上有比较明显的优势。
- Location features
- 这里就比较好理解了,在query增加搜索者的city, region, country, and language等信息,在doc侧也增加相应的信息。
- 单纯增加location feature大约有2%的提升
- Social embedding features
- 文章没有具体说细节,应该是使用GNN或者GCN的变种编码Facebook的社交网络作为预训练的emb
- 加上这个特征有1.77%的离线提升
损失函数
损失函数是从pair-wise的角度建模,采用的是triplet loss:
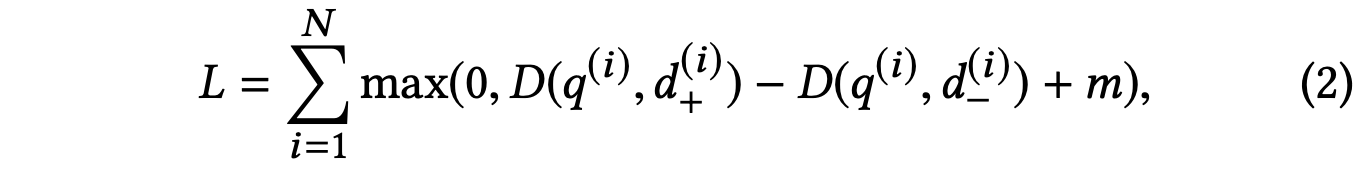
这里,q是query,d+是正样本,d-是负样本,D指向量距离,m表示margin,是一个超参数,论文中提到个margin超参数很敏感也很重要,有5%-10%的误差浮动
作者提出负例采样数n应该满足top-K=N/n,因为对于一个正样本我们会采样n个负样本,也就是让正样本在这n个负样本的相似度最大, 所以候选池有N个doc,我们要选k个,自然就是n = N/k.
补充知乎上的一个回答:

样本构造
正样本的选择
对于正样本有可以有2种集合:
- 用户点击的样本: 也就是说直接拿用户正反馈的样本当做正样本,因为用户点击过的样本大概率是满足用户意图的。
- 用户的曝光样本: 也就是说直接学习排序的输出,也就是经过复杂排序模型的结果可能更相关,因此把最后曝光给用户的当本当做正样本。
把用户曝光当做正样本在不少团队是为了解决粗排精排目标一致性的,在推荐场景中,召回去学习精排的做法比较少,但是也有团队这样做。具体是保证全链路一致性重要,还是在召回阶段尽可能多的获取与query相关的doc重要应该要具体场景具体分析了。
在本文,作者发现这两种形式的正样本效果几乎一样,同时也发现这两种叠加使用并没有新的增益。也就是说,增加曝光数据并不能提供额外价值,增加训练数据量也不能使模型受益。
负样本的选择
与精排不同,召回的负样本并不是曝光未点击,如果使用曝光未点击则造成了机器学习一个很严重的问题,就是训练-测试的数据分布不一致。召回阶段面对的是所有的候选集,有上千万甚至上亿的,而曝光未点击已经是与query强相关的集合了,只在这个集合反而学习不到全局的分布。
因此,最简单的做法就是: 数据库里随机采样一些样本作为 easy sample, 来提高模型对easy sample的辨别能力,同时一个关键的点是需要制作一些困难样本,比如 模型可能比较容易分辨出我不喜欢裙子,女装之类的,猜到我喜欢足球,更为关键的能不能分辨出我喜欢英超还是西甲,皇马还是巴萨,对用户有更加精准细腻的判断。
因此本文提出了两种hard negative mining,同时有online以及offline两种形式
- online:在线一般是batch内其他用户的正例当作负例池随机采,本文提到选相似度最高的作为hard样本,同时强调了最多不能超过两个hard样本。
- 作者发现这样可以再3个场景上有5%-8%的提升,但是也提到这样会有一些潜在的问题,从随机样本中得到一个比较好的hard negative的概率可能很低,因此不能产生足够的hard negative。
- 作者发现这样可以再3个场景上有5%-8%的提升,但是也提到这样会有一些潜在的问题,从随机样本中得到一个比较好的hard negative的概率可能很低,因此不能产生足够的hard negative。
- offline:在线batch内池子太小了不一定能选出来很好的hard样本,离线则可以从全量候选里选。即对每个query的top-k结果利用hard selection strategy找到hard样本加入训练,然后重复整个过程。
- 这里有几个结论,一个是仅仅使用hard negative sample训练的模型不能胜过使用random negative sample训练的模型。作者分析发现,“hard”模型更重视非文本特征,但在文本匹配方面不如“easy”模型。
- 因此作者使用了与query最相关的101-500中采样,太靠前的也许根本不是hard负例,压根就是个正例。同时作者给出了2个业务经验,第一个是样本easy:hard=100:1,第二个是先训练easy再训练hard效果 比 先hard后easy的形式要好(从迁移学习的视角思考的)
参考资料
https://zhuanlan.zhihu.com/p/438047408
https://zhuanlan.zhihu.com/p/165064102
- Facebook Embedding-based Embedding Retrieval Searchfacebook embedding-based embedding retrieval embedding-based embedding-based recommender perspective multi-task 时序 图谱 增量embedding-based introduction embedding retrieval简介 retrieval retrieval-augmented why_retrieval_beats_cramming_ facebook clip-retrieval