Learning Transferable Visual Models From Natural Language Supervision
作者:Alec Radford *1 Jong Wook Kim *1 Chris Hallacy 1 Aditya Ramesh 1 Gabriel Goh 1 Sandhini Agarwal 1 Girish Sastry 1 Amanda Askell 1 Pamela Mishkin 1 Jack Clark 1 Gretchen Krueger 1 Ilya Sutskever 1
OpenAI
发表年份:2021
1. Introduction and Conclusion
|
Problems
|
Contributions
|
Motivation
背景:直接从原始文本中学习的预训练方法在过去几年中彻底改变了 NLP,实现了零样本迁移到下游数据。比如gpt-3一类的模型,几乎不需要特定于数据集的训练数据。而当前的计算机视觉(CV)模型通常被训练用于预测有限的物体类别,这样的模型通常还需要额外的标注数据来完成训练时未曾见过的视觉“概念”。在NLP中,预训练的方法目前已经被验证很成功,直接从网络文本中学习的可扩展预训练方法能否在计算机视觉领域带来类似的突破?
使用自然语言学习的方法可以从互联网上大量的文本数据中学习;
与大多数无监督或自监督的学习方法相比,从自然语言中学习不只是学习一个表征,而且还将该表征与语言联系起来,从而实现灵活的zero-shot learning。
2. Method
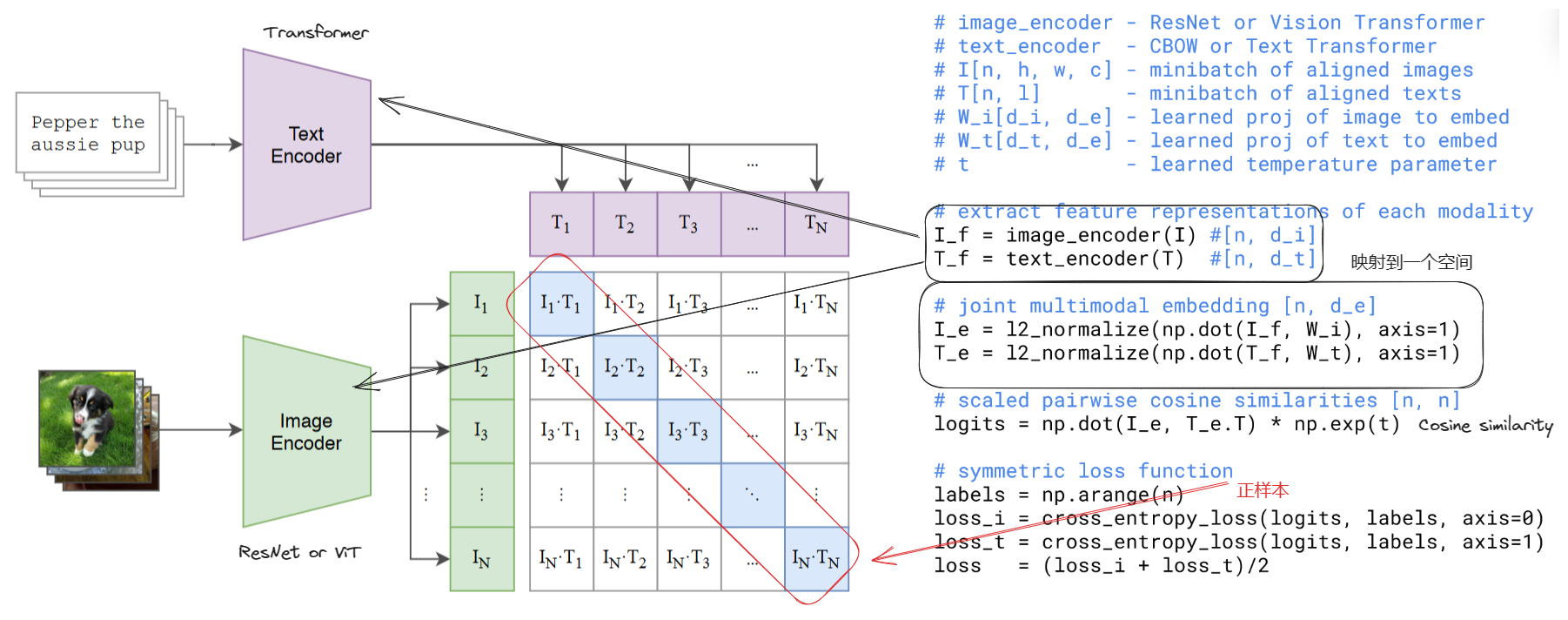
工作的核心是从自然语言与图像配对的监督中学习感知
1. Creating a Sufficiently Large Dataset - 400 million (image, text) pairs
2. Selecting an Efficient Pre-Training Method - contrastive representation learning
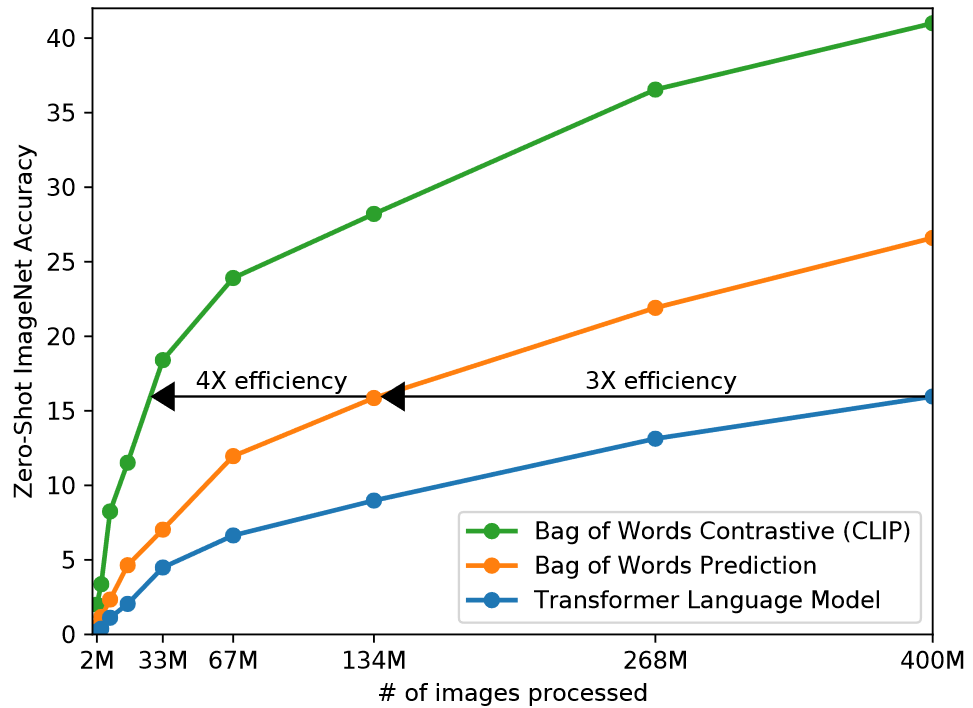
3. Choosing and Scaling a Model
ResNet50, Vision Transformer(ViT)
Transformer
4. Pre-training
The largest ResNet model, RN50x64, took 18 days to train on 592 V100 GPUs while the largest Vision Transformer took 12 days on 256 V100 GPUs.
由于数据集很大,因此不用担心过拟合问题;
没有加载预训练权重,完全从零开始训练;
没有使用非线性激活函数,而是直接使用一个线性映射;
没有使用文本数据增强(这里主要指从文本中选取一个句子),因为数据集中的文本只有一个句子;
图像数据增强方面只使用了随机裁剪;
温度参数t在训练过程中也被优化。
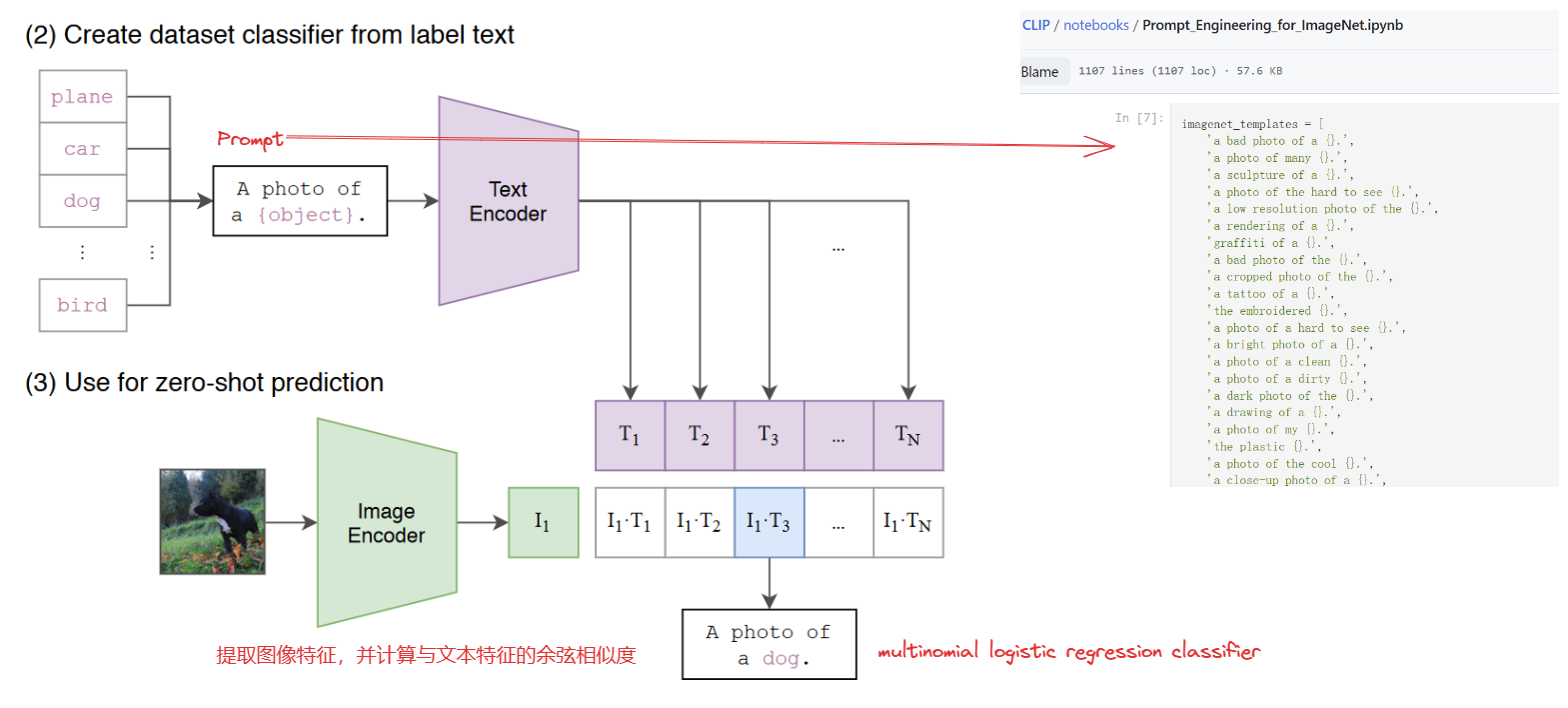
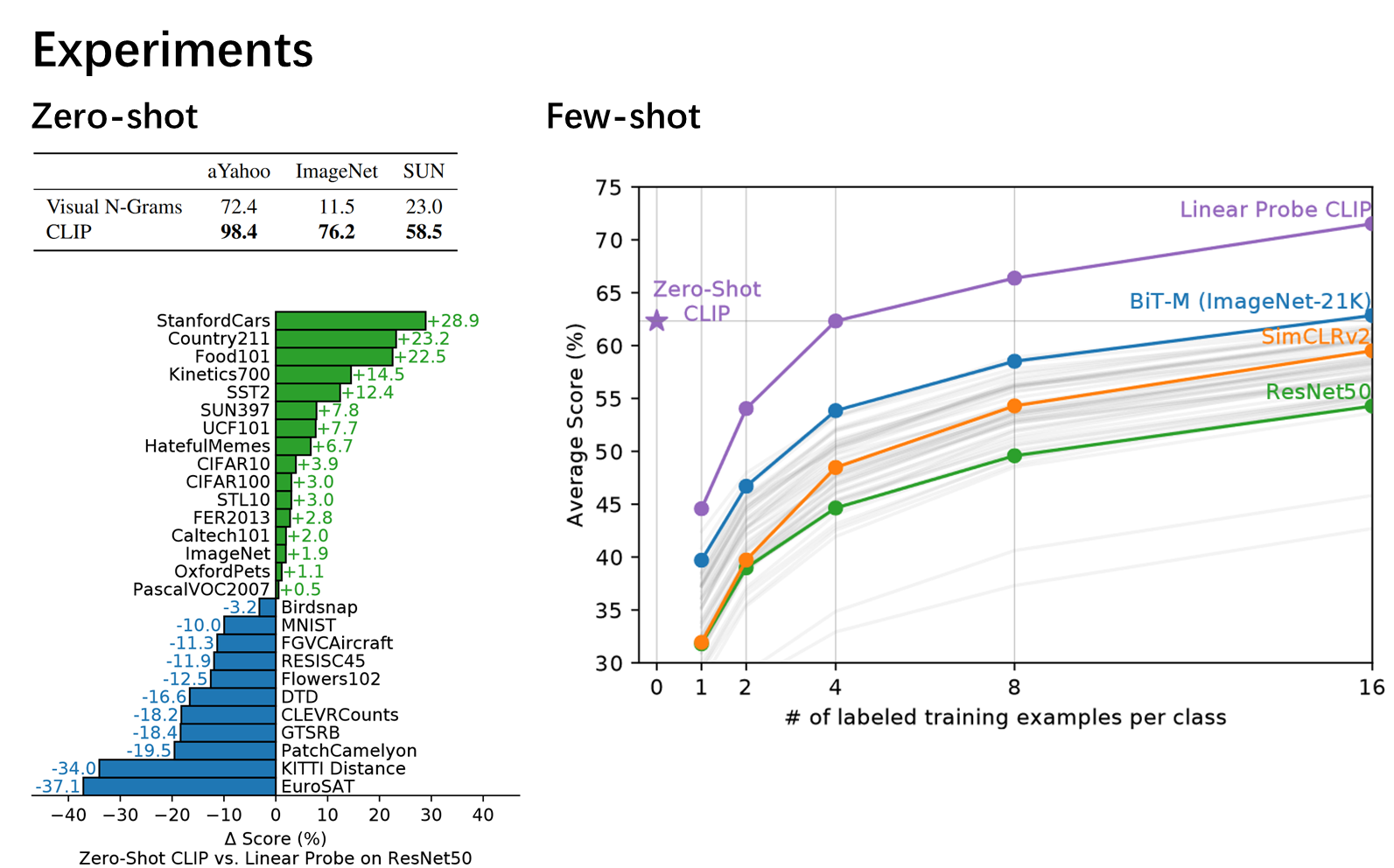
3. Experiments
zero-shot transfer
zero-shot分类

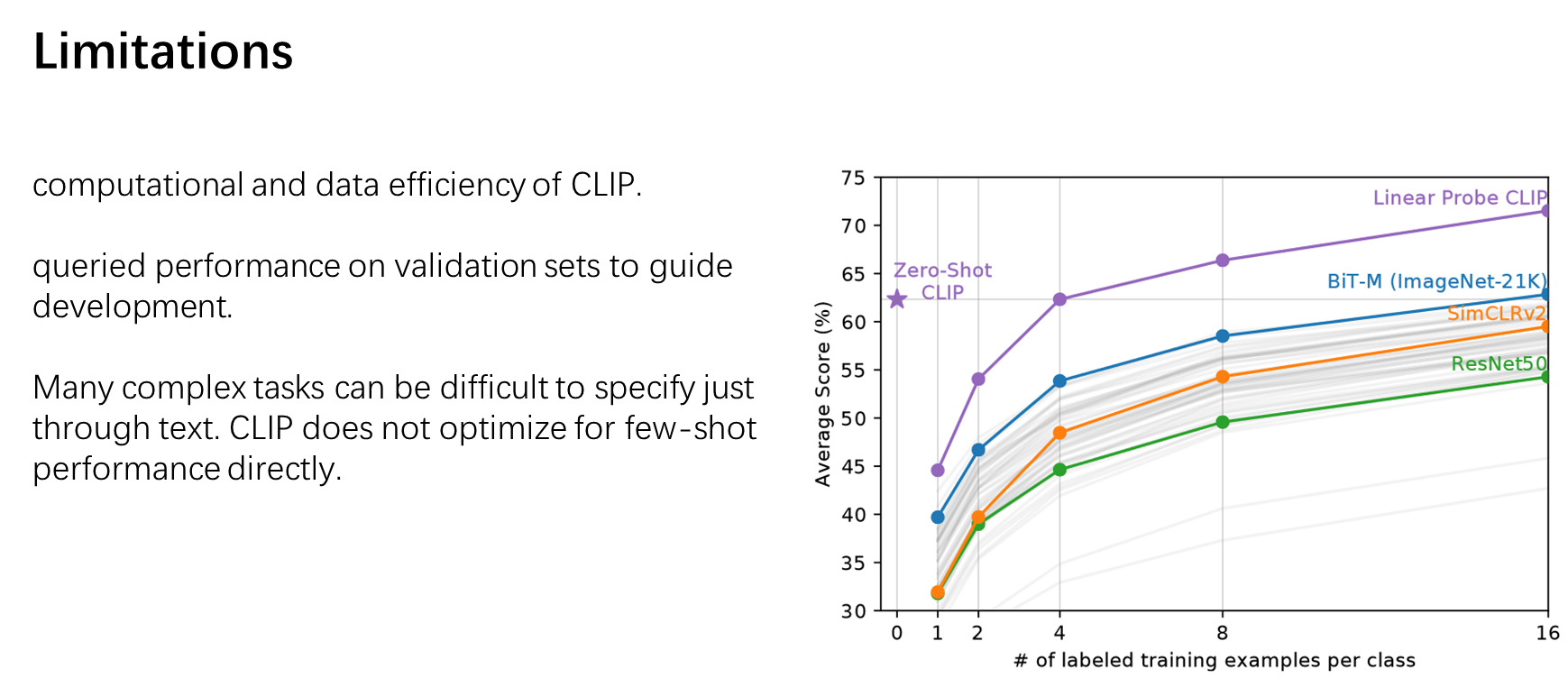
4. Limitations
- Transferable Supervision Learning Language Naturaltransferable supervision learning language transferable adversarial universal language reconstruction learning natural survey 自然语言processing language natural 自然语言 工具包language natural supervision transferable natural transferable adversarial classifiers adapting pre-trained cdeepfuzz natural reading