Graph Embedding
先从Word Embedding来说,现在的NLP语言取得了巨大突破一大部分原因是将高度离散化的词语符号表示,转换为了低维的连续分布的表示。
eg:
我爱香蕉
我爱苹果
用onehot来表示:
我 0 [1,0,0,0]
爱 1 [0,1,0,0]
苹果 2 [0,0,1,0]
香蕉 3 [0,0,0,1]
但是这种方法不能够表现出相似性的关系,来就有了更聪明的方法,考虑将这些词语用高维空间中的向量表示,如果两个词向量之间的距离近,那么它们对应的词就具有越高的语义相似性,这种思想即word2vec。用word2vec可以变成:
- 我 [1,1,1]
- 爱 [1,-1,1]
- 苹果 [-1,1,0.5]
- 雪梨 [-1,1,0.4]
类比在图上也是一样,在图上,如果两个节点之间的路径短,那么这两个节点的相似性一定很高,也就是向量之间的距离短,考虑图G(V,E),在其基础上添加顶点的类别,则形成标注图(labeled graph)GL=(V,E,X,Y),其中X∈R(|v|*d)为顶点嵌入,Y∈R(|V|×|C|),d为特征维数,Y为标签集。 注意这种写法指X和Y均为矩阵,X一共有|V|行,每行对应一个顶点的特征向量,有d维;并且每个结点可能属于多个类别⊂C。(指multi-label classification,而不是multi-class每个样本只归属一类别)。 目标则是学习得到嵌入表示X,或者说映射Φ:V↦X,使得在低维的嵌入空间中,图结点有很好的分布式连续表达,能够很好保持图的邻接结构,即结点向量间的距离能够衡量原图中的邻接关系强弱。
下图来自deepwalk论文中的空手道数据集的deepwalk的实验结果。
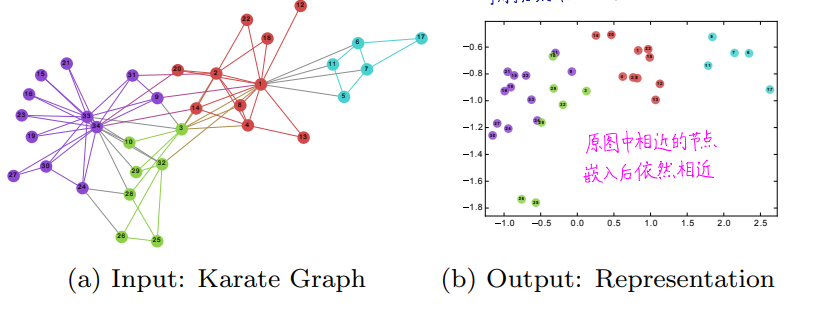
Deep Walk
将图中的节点当作词语,几个节点构成的路径当作句子。
Random walk
随机游走的方式得到节点序列,就是从一个节点除法,走L步,得到的节点序列
,其中从一个节点到相邻的节点之间是随机的饿过程。
w1,w2,......,wL
随机游走的好处:
可以实现并行计算
可以轻松应对动态网络,对于任意新加的点,不用再训练全图。
幂律分布
与文本语言相似,图中,少量的节点拥有大量的连接,严重的分布不均匀。在论文中有说明:
If the degree distribution of a connected graph follows a power law (i.e. scale-free), we observe that the frequency which vertices appear in the short random walks will also follow a power-law distribution.
图是符合幂律分布,他的子序列也符合幂律分布,因此可以尝试用语言模型来解决。
Skip-gram
在word2vec中提到了两种LM,一种CBOW,输入为前后w个词,输出为中间词;而另外一种是skip-gram,输入中间词,输出前后w,skip-gram的计算量更少,deepWalk选择skip-gram;下图是窗口为2的情况;

则最终的优化问题变成了:
$$
minΦ−logPr({vi−w,…,vi−1,vi+1,…,vi+w}∣Φ(vi))
$$
整体的算法流程:
论文中给出的伪代码:


总结一下:
1、每次随机选择一个起始点vi
2、从vi开始,做长为|Wvi|=t的随机游走。
3、依据得到的Wvi,做skip-gram。即对每一vj∈Wvi,每一uk∈Wvi[j−w:j+w],做梯度下降更新参数
$$
J(Φ)=−logPr(uk∣Φ(vj))
,
Φ=Φ−α∂J/∂Φ
$$
其他的就是一些工程上的问题了,这里不再细致讨论。