混合型对话
传统的人机对话研究专注于单一类型的对话,并且往往预设用户一开始就清楚对话目标。但实际应用中,人机对话常常混合了多种类型,例如闲聊、任务导向对话、推荐对话、问答等,并且用户目标是未知的。在这样的混合型对话中,机器人需要主动自然地进行对话推荐。
“混合型对话”这个新颖的任务于2020年ACL由哈工大和百度合作提出,又称为多类型对话中的会话推荐 (conversational recommendation over multi-type dialogs)。区别于以往工作,这个任务的特点在于对话类型的多样性,以及推荐者的主动性 (proactivity)——机器人需要主动规划目标序列将非推荐对话引导到推荐对话。
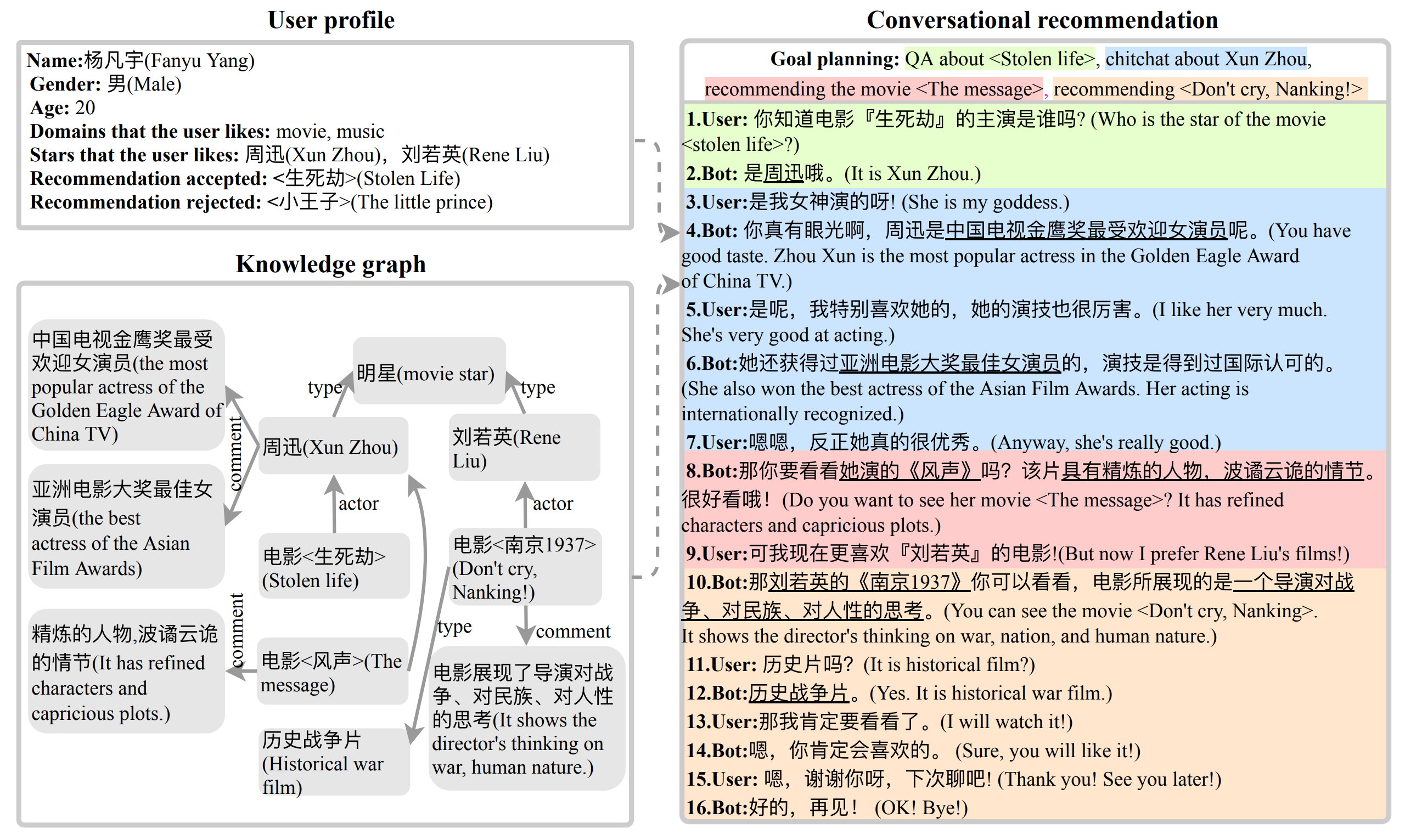
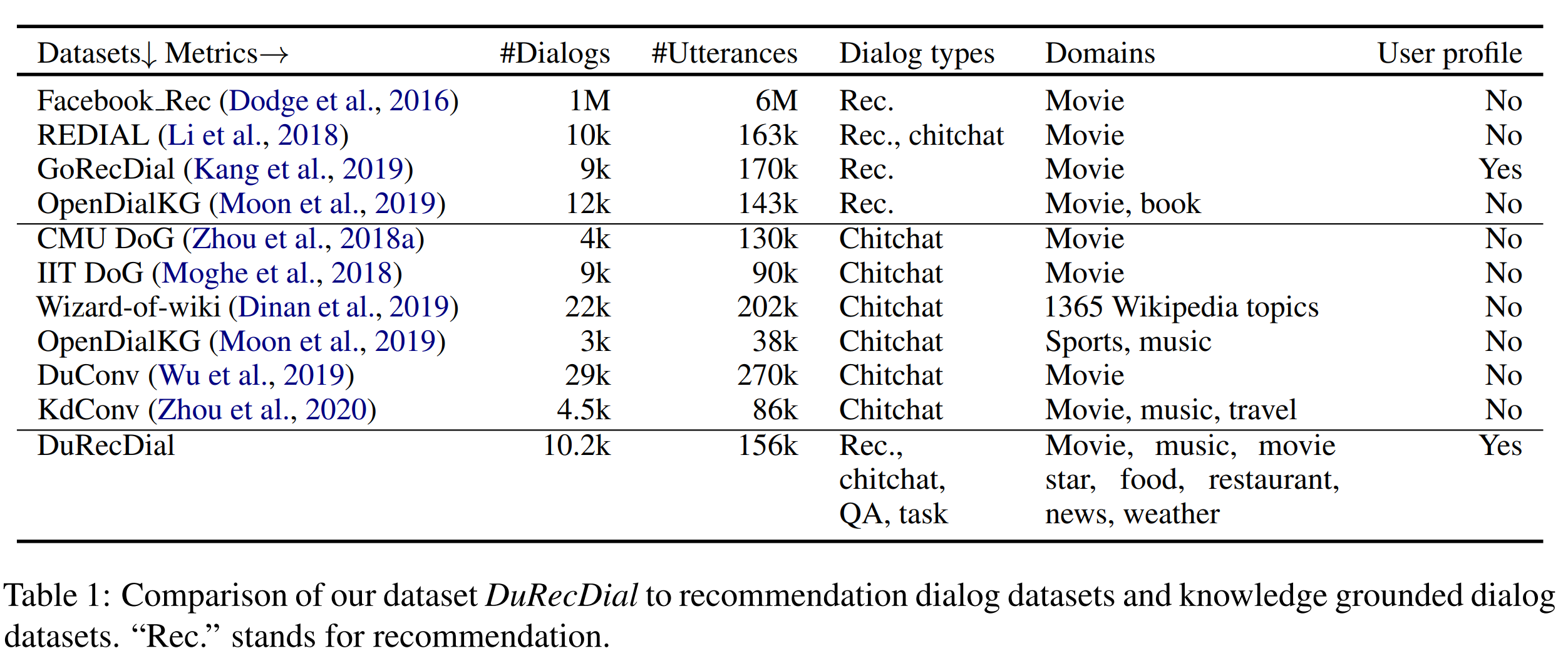
为了便于研究这个任务,作者创建了一个新的对话数据集 DuRecDial (recommendation oriented multi-type Chinese dialog dataset at Baidu)。 DuRecDial 中包含主题转换自然的多类型对话,存在丰富的交互多样性和对话轮次。并且,每个寻求者 (seeker) 都有一个明确的可更新的个人画像,用于模拟真实世界应用场景中的个性化推荐。
针对这个任务,作者提出了一个混合目标驱动的对话生成框架(multi-goal driven conversation generation framework, MGCG),由一个目标规划模块和一个目标引导响应模块组成。
-
目标规划模块:进行对话管理,即根据用户兴趣和在线反馈确定某个推荐对象为最终目标,然后规划合适的短期目标来实现自然的主题转换。这种用于多类型对话建模的目标导向的对话策略机制是前人没有研究过的。
-
响应模块:为达成每个目标进行响应生成,例如围绕某个主题闲聊、或向用户提出推荐。
MGCG 框架
目标规划模块
目标规划模块将上下文 X、目标历史 \(\mathcal{G}^{\prime}=\left\{g_0, \ldots, g_{t-1}\right\}\)、知识图谱 \(\mathcal{K}\) 和更新的 seeker 画像 \(\mathcal{P}^{s_k}_{i-1}\)作为输入,输出目标 \(g_c\)。
目标规划又分为两个子任务:
-
目标完成估计:对于当前子任务,我们使用 CNN 来估计目标完成的概率,公式是:\(P_{GC} (l = 1|X, g_{t−1})\)
-
当前目标预测:如果 \(g_{t−1}\) 没有完成(\(P_{GC}\) < 0.5),则 \(g_c = g_{t−1}\)。否则,我们使用基于 CNN 的多任务分类来预测当前目标,通过最大化以下概率来实现:
\(\begin{gathered}g_t=\arg \max _{g^{t y}, g^{t p}} P_{G P}\left(g^{t y}, g^{t p} \mid X, \mathcal{G}^{\prime}, \mathcal{P}_i^{s_k}, \mathcal{K}\right), \\ g_c=g_t,\end{gathered}\)
其中 \(g^{ty}\) 是候选对话类型,\(g^{tp}\) 是候选对话主题。
响应模块
响应模块基于上下文 \(X\)、目标 \(g_c\) 和知识图谱 \(\mathcal{K}\), 产生响应来完成每个目标。响应模块的实现改进自Wu et al. (2019)提出的两种模型:检索和生成模型。
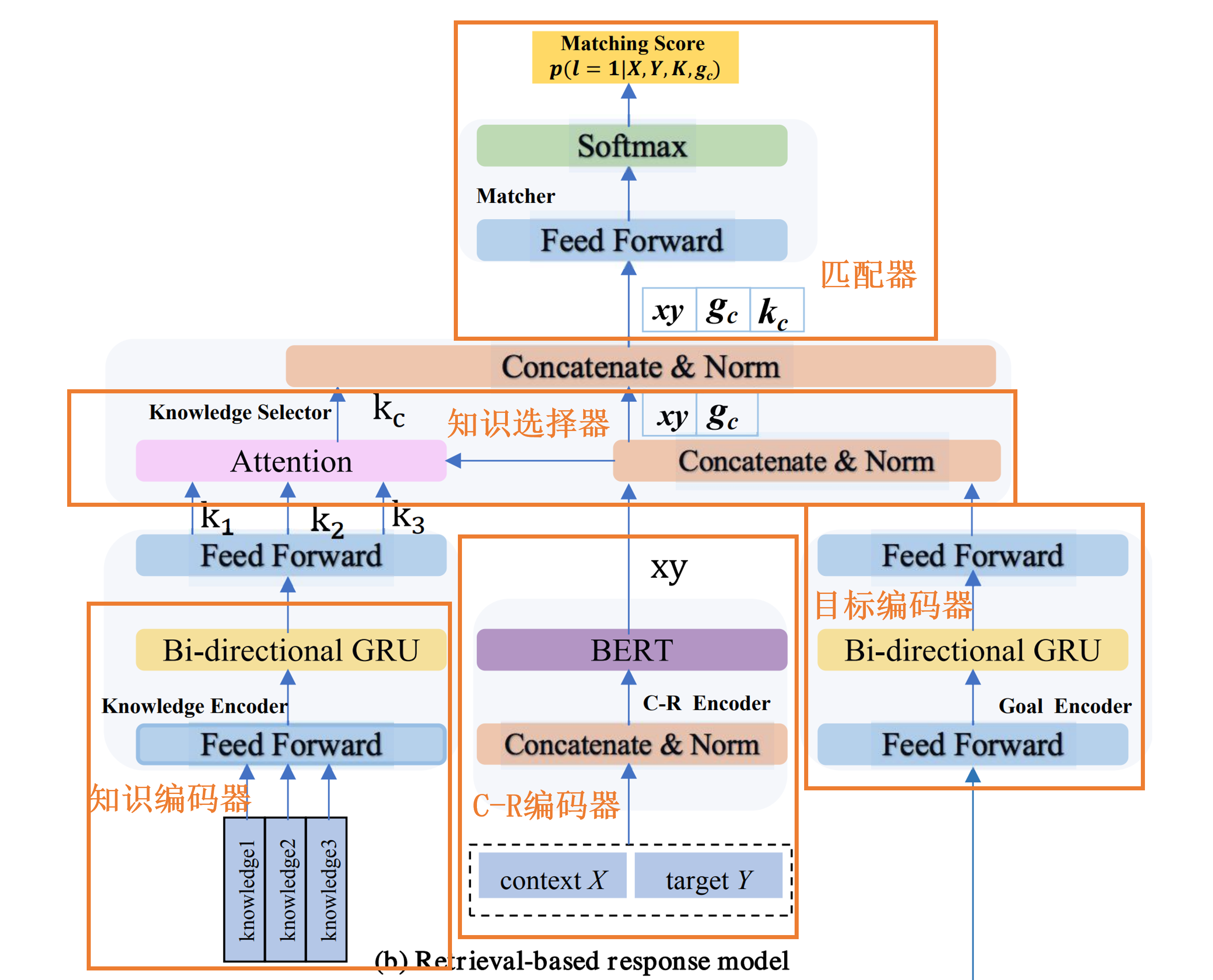
基于检索的响应模型
检索模型通过从数据库中检索候选响应、并排序筛选出最佳响应Y来回应上下文,如图(b)所示,响应排序器由五个组件组成:上下文-响应表示模块(C-R编码器)、知识表示模块(知识编码器)、目标表示模块(目标编码器)、知识选择模块(知识选择器)和匹配模块(匹配器)。
C-R编码器与BERT具有相同的架构,它将上下文X和候选响应Y作为BERT中的segment_a和segment_b,并利用堆叠的自注意力来生成X和Y的联合表示,记为 \(xy\)。
知识编码器将每个相关知识 \(knowledge_i\) 使用双向GRU编码为向量,记为 \(k_i=\left[\overrightarrow{h_{T_k}} ; \overleftarrow{h_0}\right]\)。
目标编码器使用双向GRU编码对话类型和对话主题作为目标表示,记为\(g_c\)。
知识选择器用上下文-响应表示xy对所有知识向量 \(k_i\) 进行注意力分配,并得到注意力分布:
\(p\left(k_i \mid x, y, g_c\right)=\frac{\exp \left(\mathbf{M L P}\left(\left[x y ; g_c\right]\right) \cdot k_i\right)}{\sum_j \exp \left(\mathbf{M L P}\left(\left[x y ; g_c\right]\right) \cdot k_j\right)}\)
将所有相关的知识信息融合成一个向量 \(k_c=\sum_i p\left(k_i \mid x, y, g_c\right) * k_i\)。
将 \(k_c\) 、\(g_c\) 和 \(xy\) 视为来自知识源、目标源和对话源的信息,将这三个信息源拼接成一个向量。最后,计算每个Y的匹配概率:
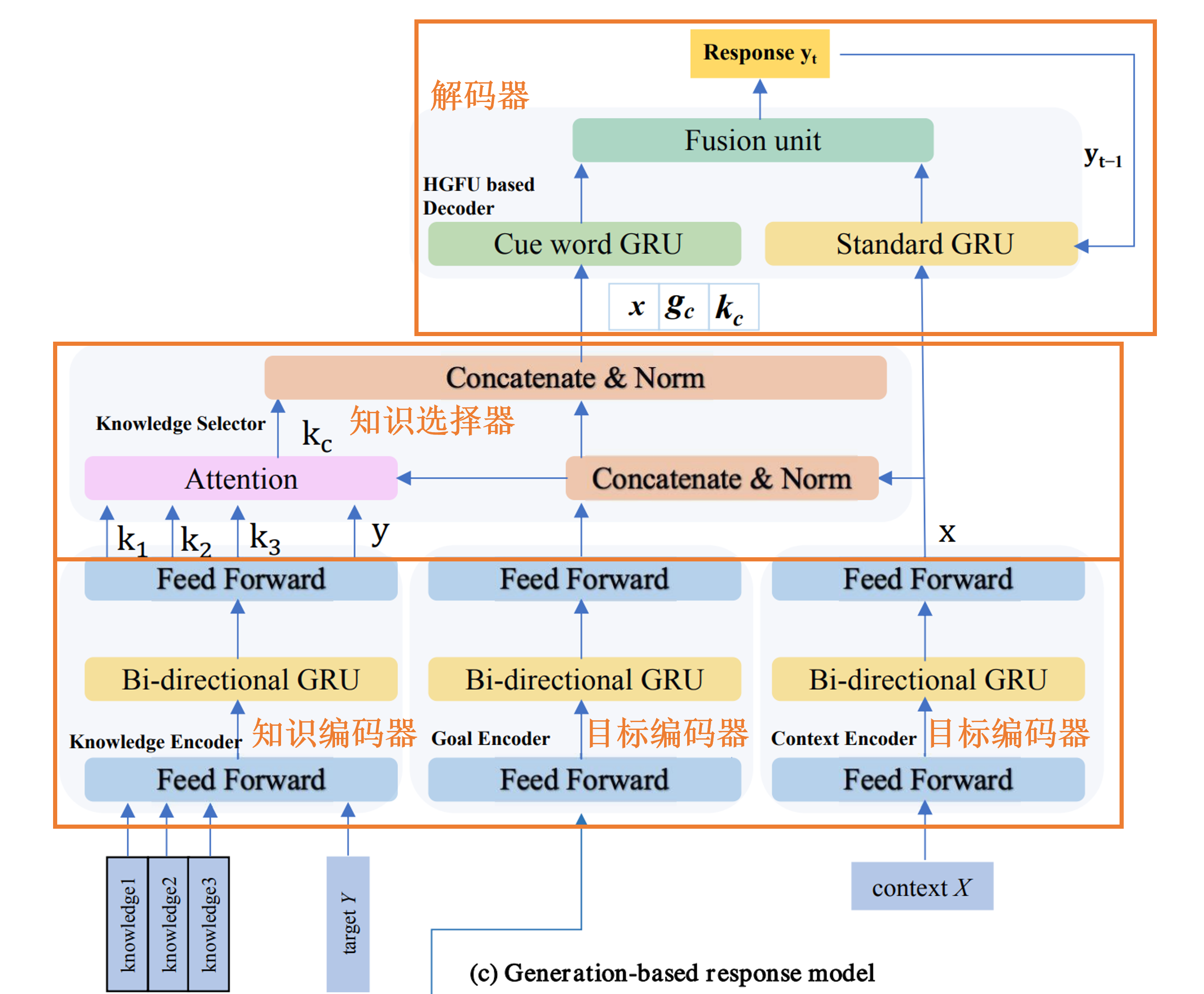
基于生成的响应模型
如图3(c)所示,生成器由五个组件组成:上下文编码器、知识编码器、目标编码器、知识选择器和解码器。
前三个组件和基于检索的响应模型几乎一样:给定上下文 X、对话目标 \(g_c\) 和知识图谱 \(K\),生成器使用基于双向 GRUs 的编码器将它们编码为向量。
知识选择器通过最小化先验分布 \(p\left(k_i \mid x, g_c\right)\) 和后验分布 \(p\left(k_i \mid x, y, g_c\right)\) 之间的KLDivLoss,来学习知识选择策略。这个方法基于一个假设,即使用正确的响应将有助于知识选择,因此预测阶段的知识选择应该接近于使用正确响应的知识选择的效果。
在训练过程中,与基于检索的方法相同,将所有相关的知识信息融合成一个向量 \(k_c = \sum_{i} p(k_i|x, y, g_c) ∗ k_i\),然后将其喂给解码器进行响应生成。在测试过程中,没有真实响应,融合的知识由 \(k_c = \sum_{i} p(k_i|x, g_c) ∗ k_i\) 估计。
解码器采用Yao et al. (2017)提出的分层门控融合单元 (Hierarchical Gated Fusion Unit)实现,这是一个标准的用外部知识门增强的GRU解码器。
除了\(L_{KL}(\theta)\)损失外,生成器还用到两个损失。
NLL损失:计算真实响应的负对数似然\(\left(L_{NLL}(\theta)\right)\)。
BOW (bag-of-words)损失:使用Zhao et al.(2017)提出的 BOW 损失,通过强调知识和真实响应之间的相关性来确保融合知识\(k_c\)的准确性。具体而言,令\(w=\mathbf{MLP}\left(k_c\right) \in \mathcal{R}^{|V|}\),其中\(|V|\)是词汇表大小。我们定义:
然后,BOW 损失被定义为最小化:
最后,作者最小化以下损失函数:
其中\(\alpha\)是可训练参数。
作者用MGCG_R表示具有自动目标规划和基于检索的响应模型的系统,MGCG_G表示具有自动目标规划和基于生成的响应模型的系统。
- 混合性 Conversational Recommendation Multi-Type Towards混合性conversational recommendation multi-type learning conversational recommendation reinforcement multi-type towards conversational adversarial resistant learning towards reasoning language towards models conversational automated program reading 混合性 综合性