- Rdd
- 几个基本的转换算子

窍诀 :textfile得到的是按行读取的集合 filter就是一行为对象 split对象也是行,按照空格将行分割“ “1“ '2" ”” ”flat 展平,,将外层的引号去掉
- map就是生成一个键值对的形式,gruopbykey就是生成键+迭代器的形式 ruducebykey是作用于键值对形式的RDD,括号里是函数,作用对象是值,所以可以简写
- spark-shell疑点
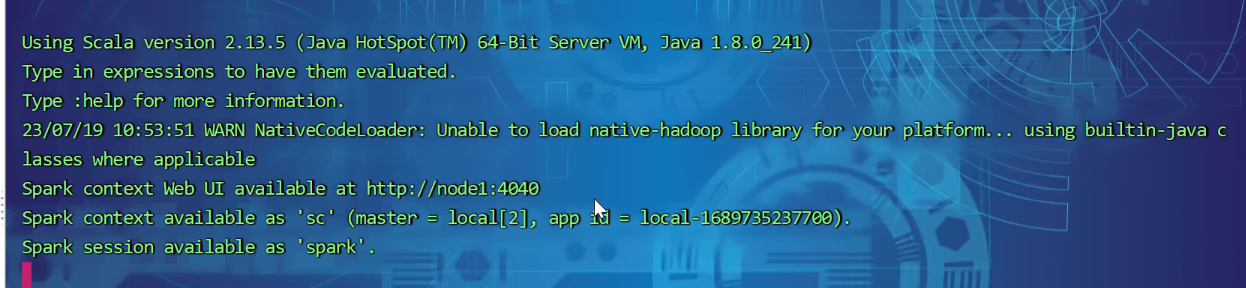
上下文环境已经给你创建好了,不用你再import 名字都给你起好了sc
- DataFrame

多行一列的字符串
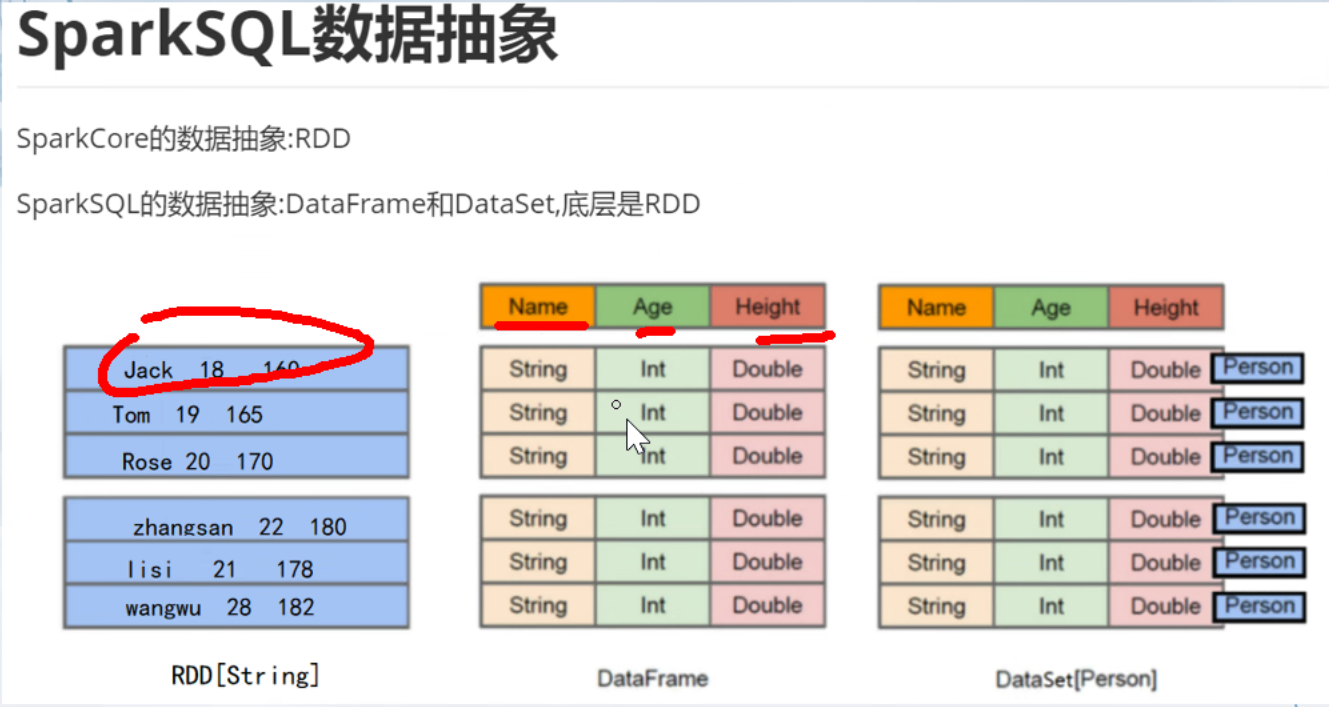
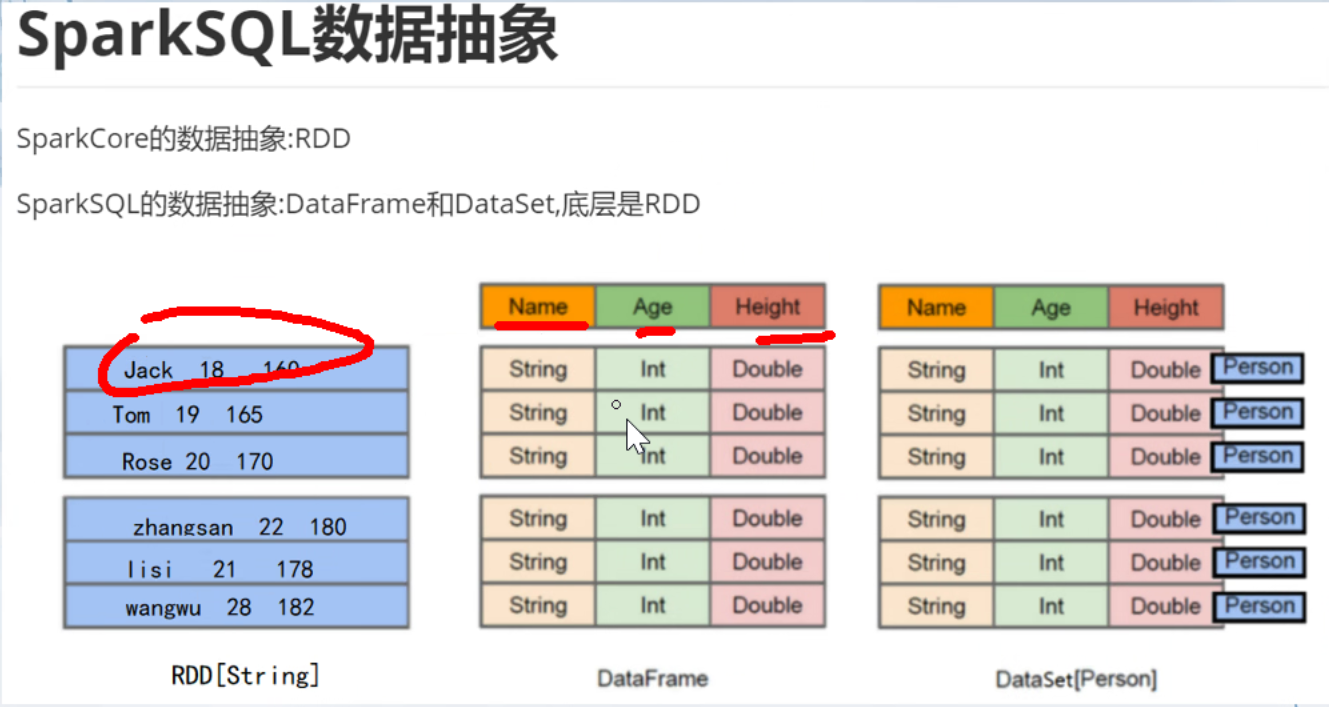
- DataSet 约束更强 将每一行都看做一个person对象 在frame的基础上
- 这玩意就不是new出来的,和不建立session的节奏不一样,通过session建立context
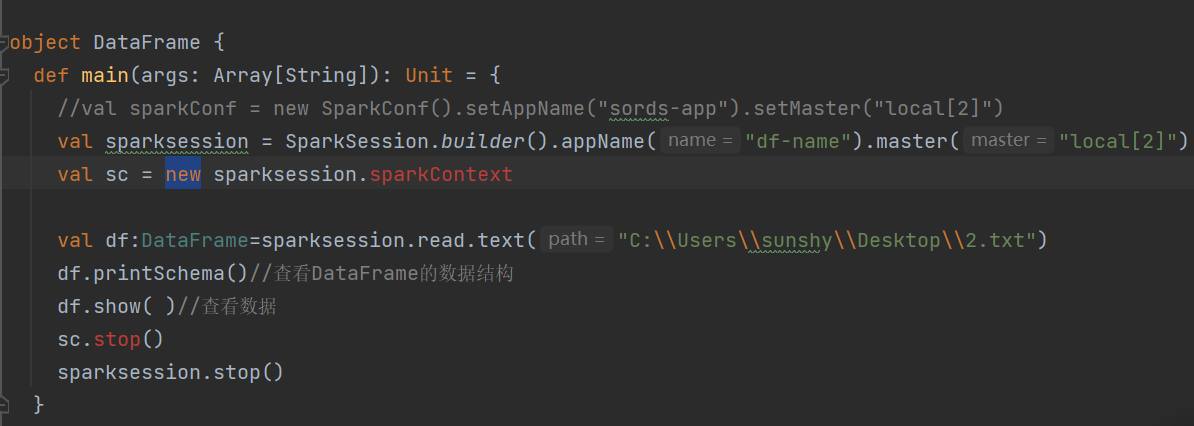
- 出现scala/Serializablescala/Serializable 序列化错误的原因就是导入的包spark版本不对
- import不仅仅是包还有上下文
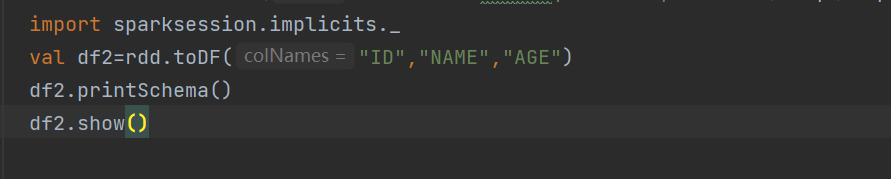
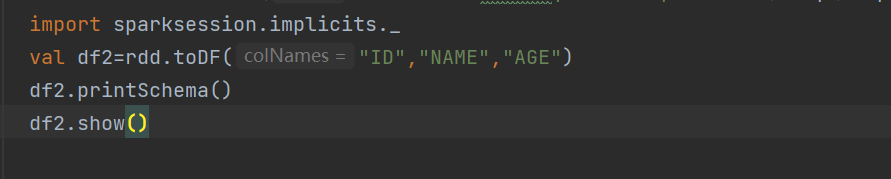
这里其实就是导入的session,我被spark名字误导了,还有一定要删除多余的core依赖
- 为甚莫需要把数据结构变来变去,目的是为了更符合二维表格结构,RDD转换称为二维表格之后就可以使用SQL语句去操作
- 如何使用样例类创建DataFrame
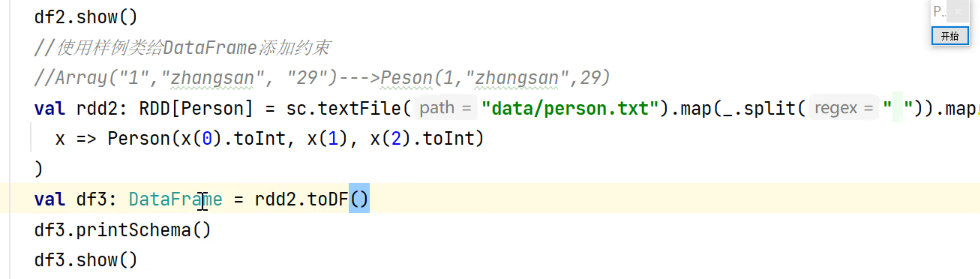
。var
- 日志级别设置要在seesion上下文环境设置,现在什么都归session管了,苦恼
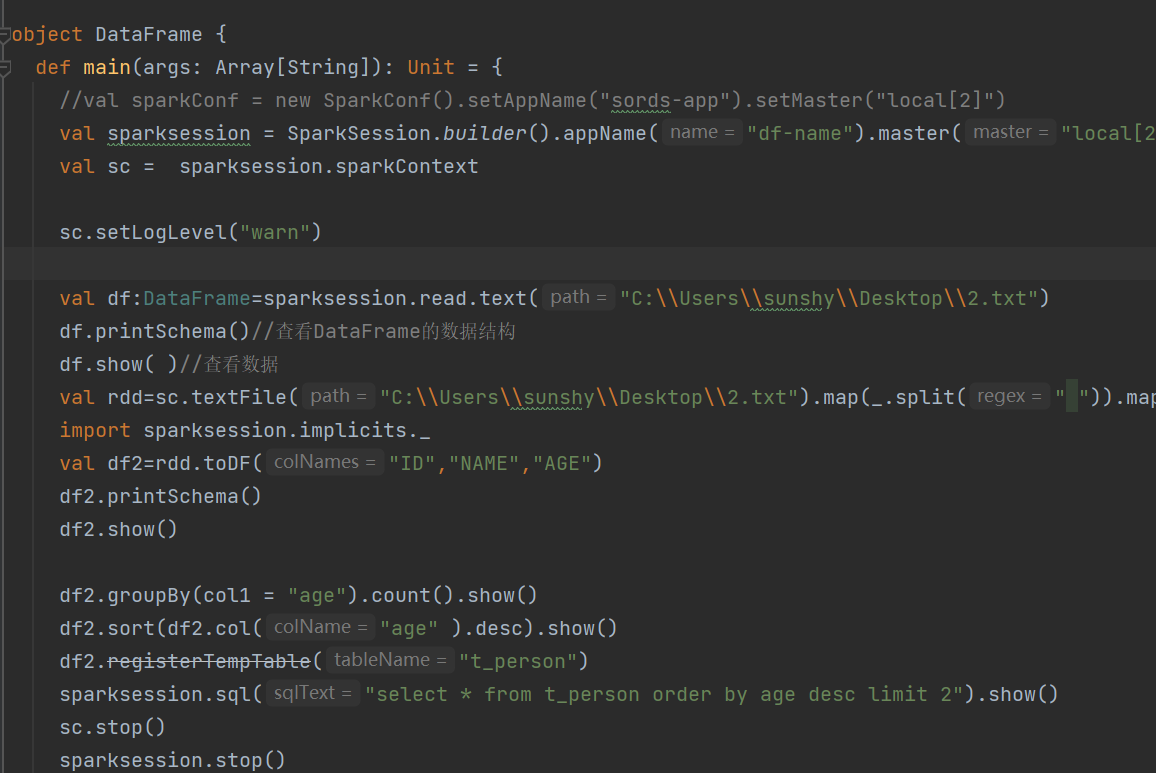
spark2
发布时间 2023-07-20 11:24:25作者: SunShine789