准确率,精准率,召回率
分类问题中的混淆矩阵如下
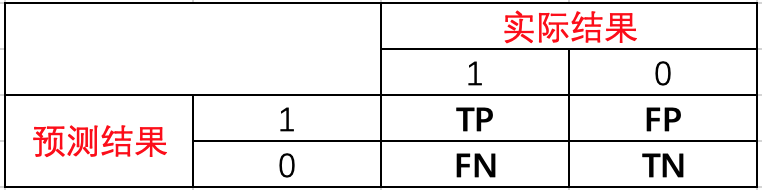
TP: 预测为1,预测正确,即实际1
FP: 预测为1,预测错误,即实际0
FN: 预测为0,预测错确,即实际1
TN: 预测为0,预测正确即,实际0
准确率 accuracy
准确率 accuracy
准确率的定义是预测正确的结果占总样本的百分比,其公式如下:
准确率=(TP+TN)/(TP+TN+FP+FN)
虽然准确率可以判断总的正确率,但是在样本不平衡 的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占90%,负样本占10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到90%的高准确率,但实际上我们并没有很用心的分类,只是随便无脑一分而已。这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
精准率 Precision
精准率(Precision)又叫查准率,它是针对预测结果 而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下:
精准率=TP/(TP+FP)
精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
召回率 Recall
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,其公式如下:
精准率=TP/(TP+FN)
召回率的应用场景: 比如拿网贷违约率为例,相对好用户,我们更关心坏用户,不能错放过任何一个坏用户。因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重偿失。召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
F1值
我们希望精准率和召回率同时都非常高。 但实际上这两个指标是一对矛盾体,无法做到双高。如果其中一个非常高,另一个肯定会非常低。选取合适的阈值点要根据实际需求,比如我们想要高的查全率,那么我们就会牺牲一些查准率,在保证查全率最高的情况下,查准率也不那么低。
在实际情况中,不会有分类器仅仅以精确度(Precision)或者召回率(Recall)作为单一的度量标准,而是使用这两者的调和平均,于是就有了F值(F-Score),F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。
F1分数的公式为 = 2精准率 * 召回率 / (精准率 + 召回率)。
ROC曲线 AUC值
ROC曲线
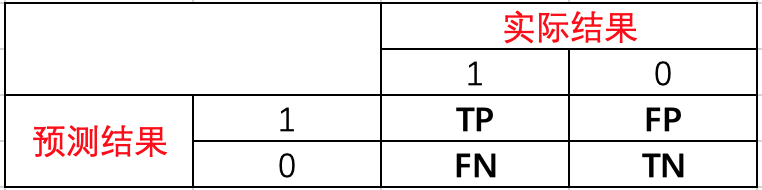
首先我们需要定义下面两个变量:FPR、TPR(即为我们常说的召回recall)。
FPR表示,在所有的恶性肿瘤中,被预测成良性的比例。称为伪阳性率。伪阳性率告诉我们,随机拿一个恶性的肿瘤样本,有多大概率会将其预测成良性肿瘤。显然我们会希望FPR越小越好。
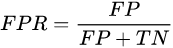
TPR表示,在所有良性肿瘤中,被预测为良性的比例。称为真阳性率。真阳性率告诉我们,随机拿一个良性的肿瘤样本时,有多大的概率会将其预测为良性肿瘤。显然我们会希望TPR越大越好。
如果以FPR为横坐标,TPR为纵坐标,就可以得到下面的坐标系:
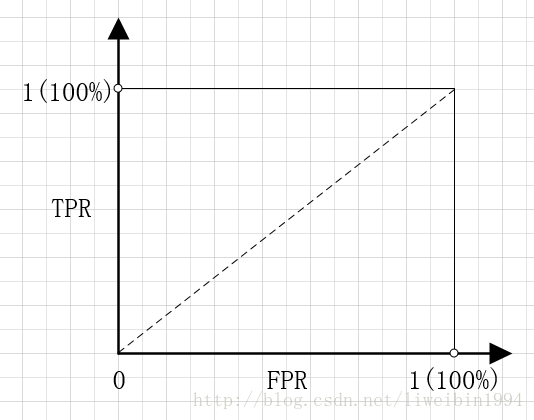
点(0,1),即FPR=0,TPR=1。FPR=0说明FP=0,也就是说,没有假正例。TPR=1说明,FN=0,也就是说没有假反例。这不就是最完美的情况吗?所有的预测都正确了。良性的肿瘤都预测为良性,恶性肿瘤都预测为恶性,分类百分之百正确。这也体现了FPR 与TPR的意义。就像前面说的我们本来就希望FPR越小越好,TPR越大越好。
点(1,0),即FPR=1,TPR=0。这个点与上面那个点形成对比,刚好相反。所以这是最糟糕的情况。所有的预测都预测错了。
点(0,0),即FPR=0,TPR=0。也就是FP=0,TP=0。所以这个点的意义是所有的样本都预测为恶性肿瘤。也就是说,无论给什么样本给我,我都无脑预测成恶性肿瘤就是了。
点(1,1),即FPR=1,TPR=1。显然,这个点跟点(0,0)是相反的,这个点的意义是将所有的样本都预测为良性肿瘤。
好啦,现在我们知道了在这个坐标系上的某个点所代表的意义了。那么问题就来了,当一个分类器已经训练好了之后,那它的FPR,TPR应该是一个固定的值呀。那对应到上面的ROC坐标系上应该就是一个点了啊,那ROC曲线又是个什么意思呢?曲线下的面积又是个什么意思呢?
我们知道,在二分类(0,1)的模型中,一般我们最后的输出是一个概率值,表示结果是1的概率。那么我们最后怎么决定输入的x是属于0或1呢?我们需要一个阈值,超过这个阈值则归类为1,低于这个阈值就归类为0。所以,不同的阈值会导致分类的结果不同,也就是混淆矩阵不一样了,FPR和TPR也就不一样了。所以当阈值从0开始慢慢移动到1的过程,就会形成很多对(FPR, TPR)的值,将它们画在坐标系上,就是所谓的ROC曲线了。
AUC值
AUC值了:得到了ROC曲线,我们就可以计算曲线下方的面积,计算出来的面积就是。
结论:AUC表示,随机抽取一个正样本和一个负样本,分类器正确给出正样本的score高于负样本的概率。
AUC值的计算
方法一
在有M个正样本,N个负样本的数据集里。一共有MN对样本(一对样本即,一个正样本与一个负样本)。统计这MN对样本里,正样本的预测概率大于负样本的预测概率的个数。
这样说可能有点抽象,我举一个例子便能够明白。
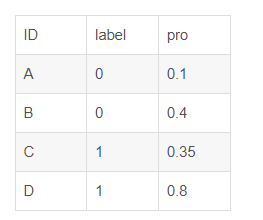
假设有4条样本。2个正样本,2个负样本,那么M*N=4。即总共有4个样本对。分别是:
(D,B),(D,A),(C,B),(C,A)。
在(D,B)样本对中,正样本D预测的概率大于负样本B预测的概率(也就是D的得分比B高),记为1
同理,对于(C,B)。正样本C预测的概率小于负样本C预测的概率,记为0.
最后可以算得,总共有3个符合正样本得分高于负样本得分,故最后的AUC为
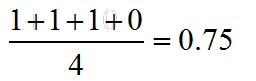
参考: https://blog.csdn.net/weixin_42127358/article/details/122561911