1、Conv1d 定义
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)

自然语言处理中一个句子序列,一维的,所以使用Conv1d,此时卷积核(没有batch_size,参数是共享的)除去chanel,也是一维的。
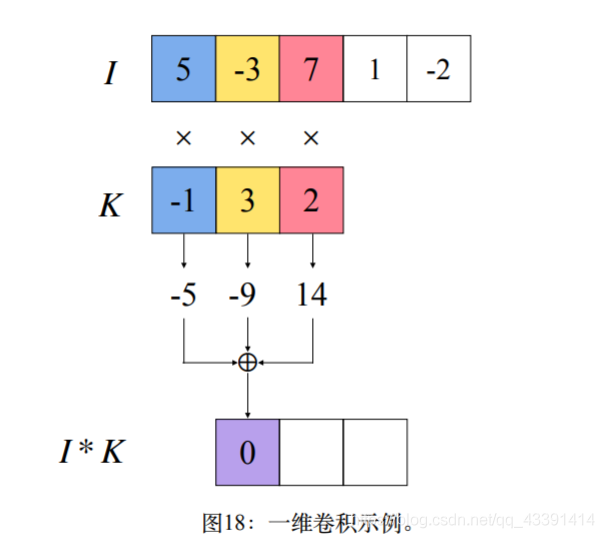
2、参数
in_channels(int) – 输入信号的通道。在文本分类中,即为词向量的维度
out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
dilation(int or tuple, `optional``) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
-
in_channel:输入的通道数,信号一般为一维
-
out_channel:输出的通道数
-
kernel_size:卷积核的大小
-
stride:步长
-
padding:0填充
3、shape:

4、代码例子:
官方例子1:
input1 = torch.randn(20, 16, 50) # torch.Size([20, 16, 50])
m = nn.Conv1d(16, 33, 3, stride=2) # Conv1d(16, 33, kernel_size=(3,), stride=(2,))
output = m(input1) # torch.Size([20, 33, 24])
验证Shape中conv1d 关于输出Lout的公式:Lout =⌊50+2*0 - 1*(3-1) -1⌋/2 + 1 = 24
例子2:
import torch import torch.nn as nn # 卷积大小为kernel_size*in_channels, 此处也即 3 * 4, 每个卷积核产生一维的输出数据,长度与输入数据的长度和stride有关,根据ouotput可知是3,第二个参数2也就卷积核的数量 m = nn.Conv1d(4, 2, 3, stride=2) # 第一个参数理解为batch的大小,输入是4 * 9格式 input = torch.randn(1, 4, 9) print(input) output = m(input) print(output) print(output.size())
输出如下:
tensor([[[-0.2105, -1.0958, 0.7299, 1.1003, 2.3175, 0.8186, -1.7510, -0.1925, 0.8591], [ 1.0991, -0.3016, 1.5633, 0.6162, 0.3150, 1.0413, 1.0571, -0.7014, 0.2239], [-0.0658, 0.4755, -0.6653, -0.0696, 0.3483, -0.0360, -0.4665, 1.2606, 1.3365], [-0.0186, -1.1802, -0.8835, -1.1813, -0.5145, -0.0534, -1.2568, 0.3211, -2.4793]]]) tensor([[[-0.8012, 0.0589, 0.1576, -0.8222], [-0.8231, -0.4233, 0.7178, -0.6621]]], grad_fn=<SqueezeBackward1>) torch.Size([1, 2, 4])
第一个卷积核进行如下操作:

得到输出1*4的输出:
[-0.8012, 0.0589, 0.1576, -0.8222]
第二个卷积核进行类似操作:

得到输出1*4的输出:
[-0.8231, -0.4233, 0.7178, -0.6621]
合并得到最后的2*4的结果:
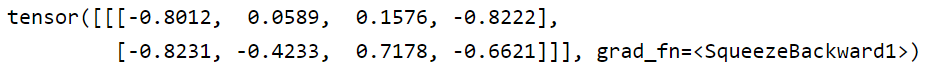
输入的input为 4 * 9 ,输出为 2 * 4。
验证Shape中conv1d 关于输出Lout的公式:Lout =⌊ 9+2*0 - 1*(3-1) -1⌋/2 + 1 = 4
参考:
1、pytorch之nn.Conv1d详解_若之辰的博客-CSDN博客_conv1d
2、简要解释什么是Conv1d,Conv2d,Conv3d_音程的博客-CSDN博客_conv1d
3、torch.nn.Conv1d及一维卷积举例说明_拉轰小郑郑的博客-CSDN博客_torch一维卷积
————————————————
版权声明:本文为CSDN博主「三世」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qimo601/article/details/125834066
conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2) input = torch.randn(32,35,256) # batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len input = input.permute(0,2,1) out = conv1(input) print(out.size()) #这里32为batch_size,35为句子最大长度,256为词向量
3.在哪个维度移动的

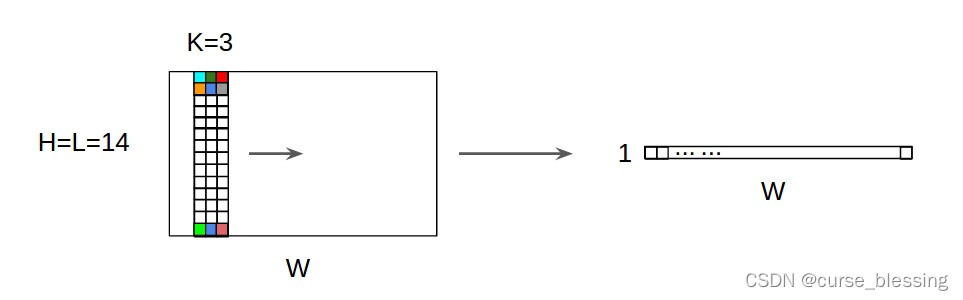
定义输入的大小为(batch_size,channel,length)
可以肯定的是卷积核是在最后一个维度移动的,例如上图的一维信号是卷积核从左往右进行卷积的。
然而卷积核的大小为多少呢?右上下图可知,卷积核大小为(channel*kernel_size),一般一维信号的卷积核大小就为(1*kernel_size)
一维卷积不是指卷积核是一维的,而是在一个维度进行卷积。
原文链接:https://blog.csdn.net/qq_36134168/article/details/126910772
4.out_channel
从输入到输出的过程中,通道数经常在发生改变,而out_channel是什么呢?
out_channel就是同时用多少个卷积核去卷同一个区域。
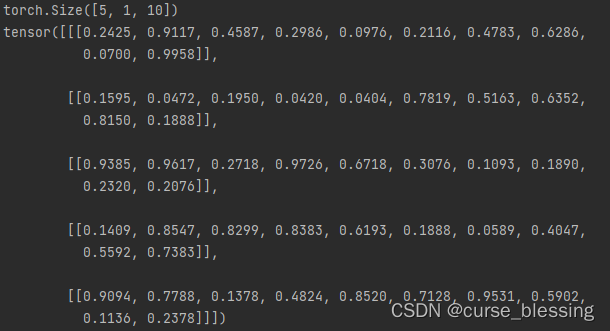
import time import torch import torch.nn as nn ''' Description: torch.nn.Conv1d input:(batch_size,in_channel,length) output:(batch_size,out_channel,length) shape of kernel:(channel*kernel_size) out_channel :the num of kernel--> how much kernel do you need? ''' #(batch_size,in_channel,length) input =torch.rand(5,1,10) print(input.shape) print(input) model =nn.Conv1d(in_channels=1, out_channels=3, kernel_size=5, padding=2) # (batch_size,out_channel,length) output =model(input) print(output.shape) print(output)
input的输出:
output的输出:

6.分析
-
可以看到除了channel变化以外其他的并没有改变,因为根据length的变化公式,正好length不变。
-
输入看起来直观上是5条1乘以10的一维信号,输出看起来就是5条3乘以10的3通道一维信号。
in_channels(int) – 通道,在文本分类中,即为词向量的维度
out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
dilation(int or tuple, `optional``) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
————————————————
原文链接:https://blog.csdn.net/leitouguan8655/article/details/120266403

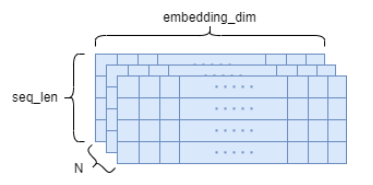
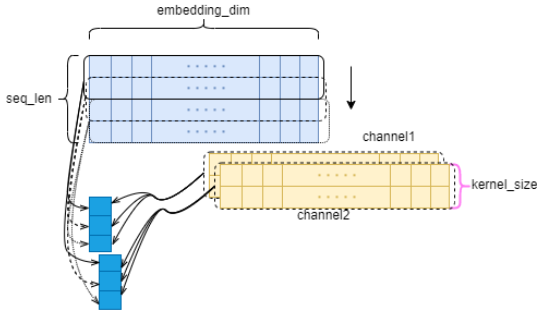
in_channels = 100 out_channels = 2 kernel_size = 2 batch_size = 4 seq_len = 10 conv1 = torch.nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size) # 文本处理形式 input_data = torch.randn(batch_size, seq_len, in_channels) # conv1d输入形式, (batch_size, channels, seq_len) input_data = input_data.permute(0, 2, 1) # torch.Size([4, 100, 10]) print(input_data.size()) conv_out = conv1(input_data) print(conv_out.size()) # torch.Size([4, 2, 9])
下边首先看一个简单的一维卷积的例子(batchsize是1,也只有一个kernel):
输入:
一个长度为35的序列,序列中的每个元素有256维特征,故输入可以看作(35,256)
卷积核: size = (k,) , (k = 2)
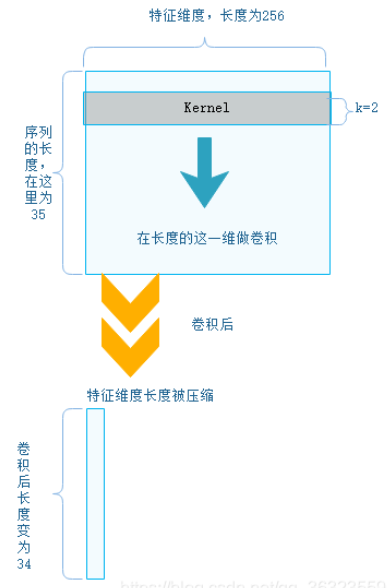
conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2) input = torch.randn(32,35,256) # batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len input = input.permute(0,2,1) out = conv1(input)
这里给出了一个简单的例子,我们随机初始化了一个维度为(32,35,256)的tensor矩阵,32表示batch_size,35表示句子最大长度,256表示词向量长度。我们将其送到卷积层之前需要进行维度转换,根据pytorch的官方文档,输入的维度应该为(样本数,通道数,句子长度),所以要将矩阵从(32,35,256)转换为(32,256,32)。
这里输出通道设置为100,表明有100个卷积核。卷积核的大小为2,卷积核的通道数要和输入的通道数一致,所以单个卷积核的维度为(256,2)。单个样本计算过程如下:
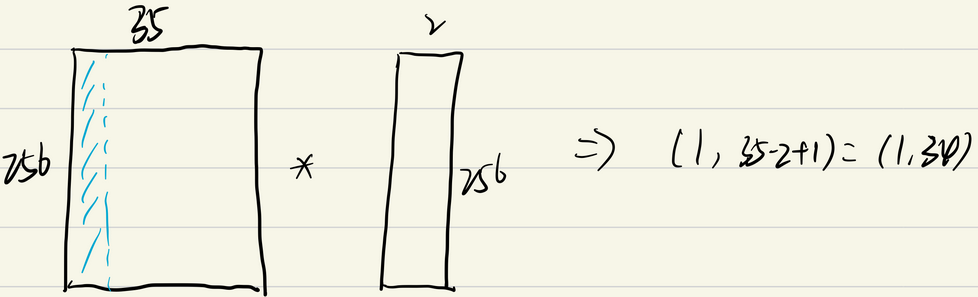
所以单个样本经过卷积操作后,维度变为(1,34),一共有100个卷积核则单个样本的输出为(100,34),批处理操作时一次处理32个样本,所以最终的输出维度为(32,100,34)。
膨胀(int或tuple,可选)–内核元素之间的间距。默认值:1
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md