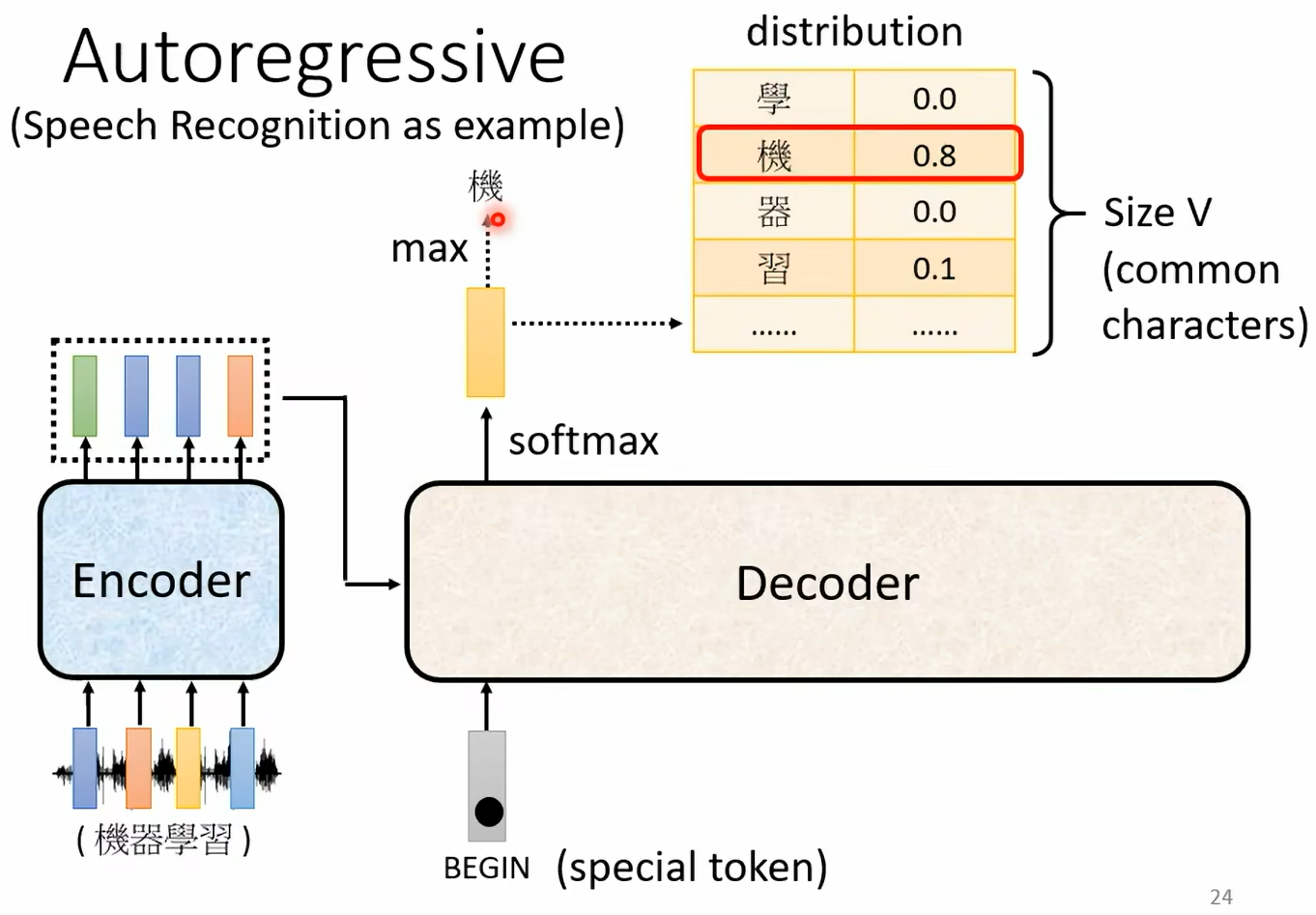
1. 今天开始看Vision Transformer(ViT):
看之前需要一些基础:
(1)RNN(Recurrent NN,循环神经网络):
一段连续的信息,前后信息之间是有关系地,必须将不同时刻的信息放在一起理解。如果是普通的神经网络,每个输入之间是相互独立的,如果是RNN,则可以接收上一个输入传递的信息。如下图所示:
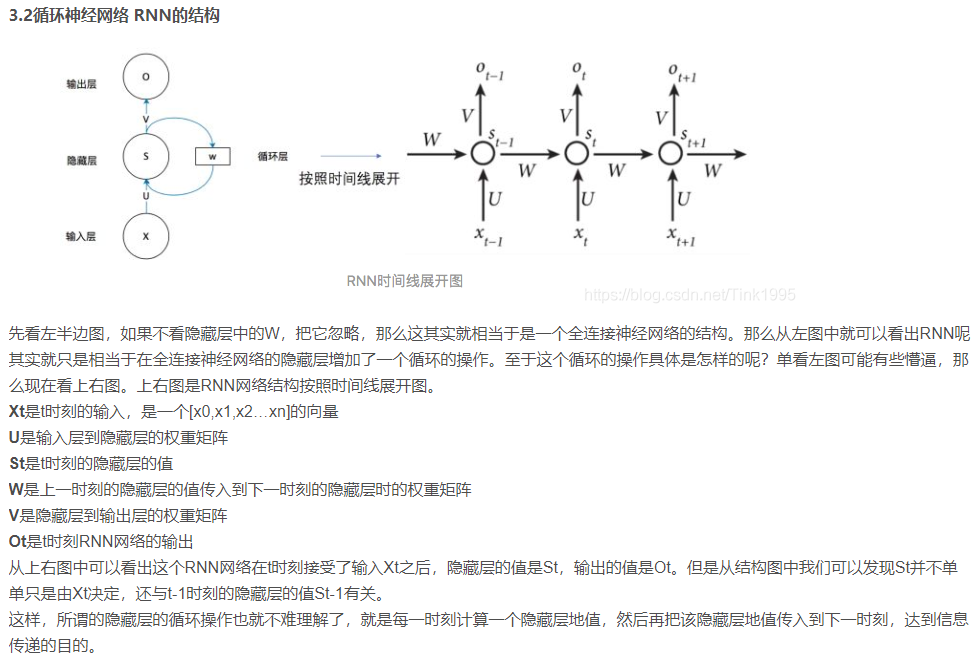
缺点:RNN无法处理长距离依赖问题,通俗点就是不能处理一些较长的序列数据
(https://blog.csdn.net/Tink1995/article/details/104868903?spm=1001.2014.3001.5502)
(2)与之相对比,LSTM和GRU可以更好地处理长序列,具体的有时间再写。
(3)Encoder-Decoder与Attention

如果是普通的Encoder-Decoder,则如上所说,将最后一个隐藏层状态值h4作为语义编码c。
如果是Attention机制的Encoder-Decoder,则会将所有隐藏层状态值存为语义编码c,并且每个隐藏层状态值是带有一个权重值的,代表着其重要程度。

Transformer:
以下是Transformer的具体情况:
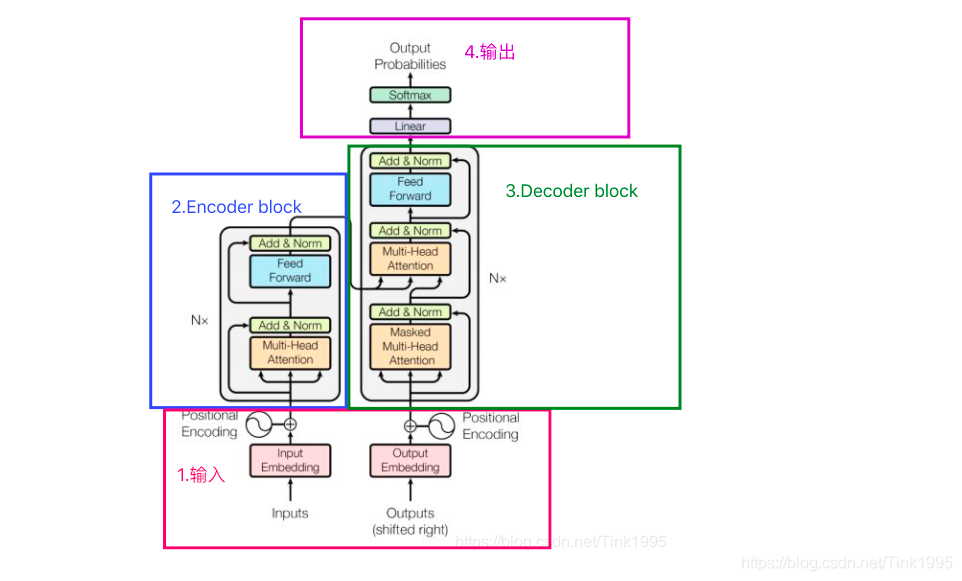
关于Encoder:

更细节的是下图:
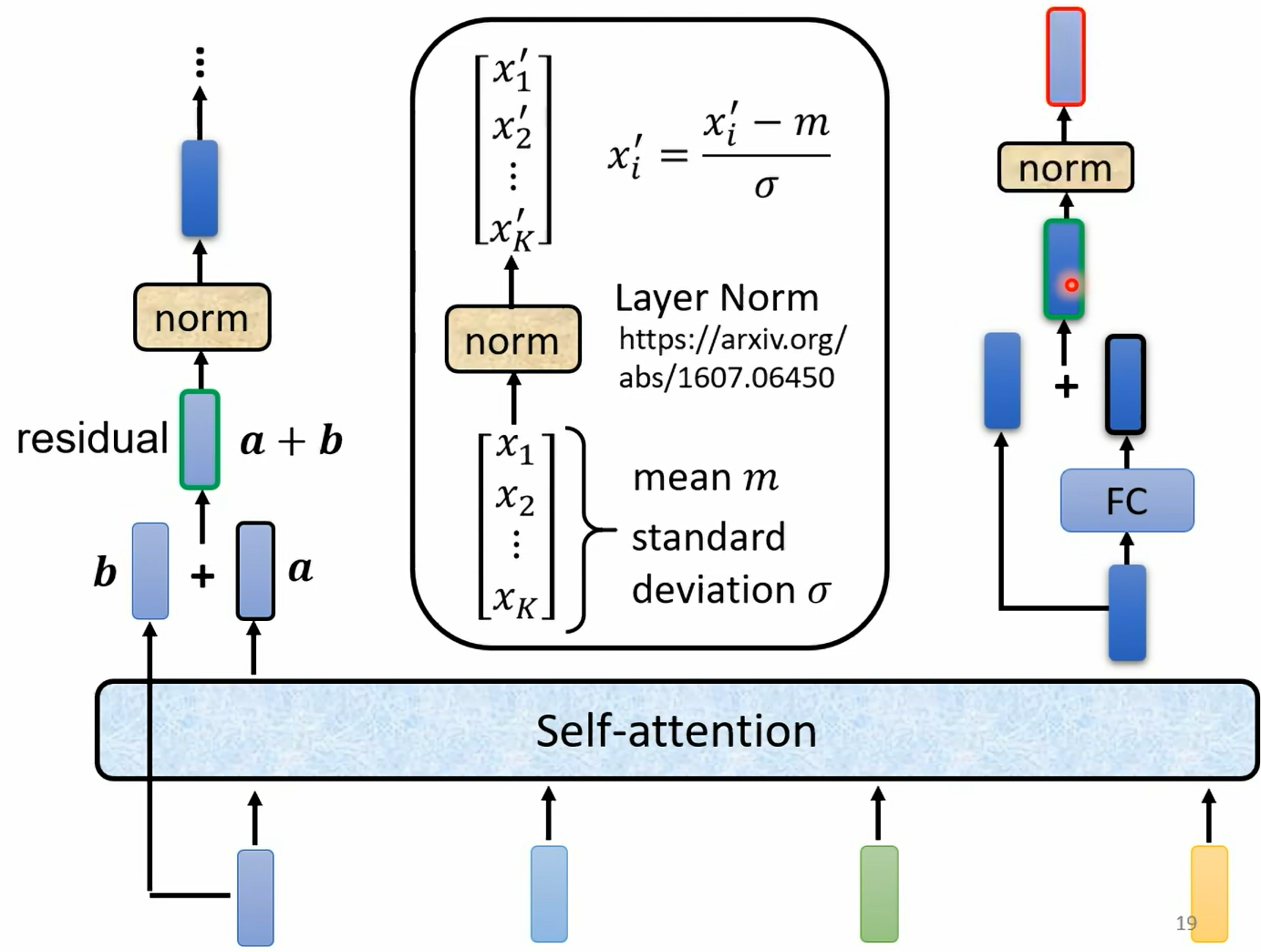
这三张图非常清楚地写出了Self-Attention层的具体情况:
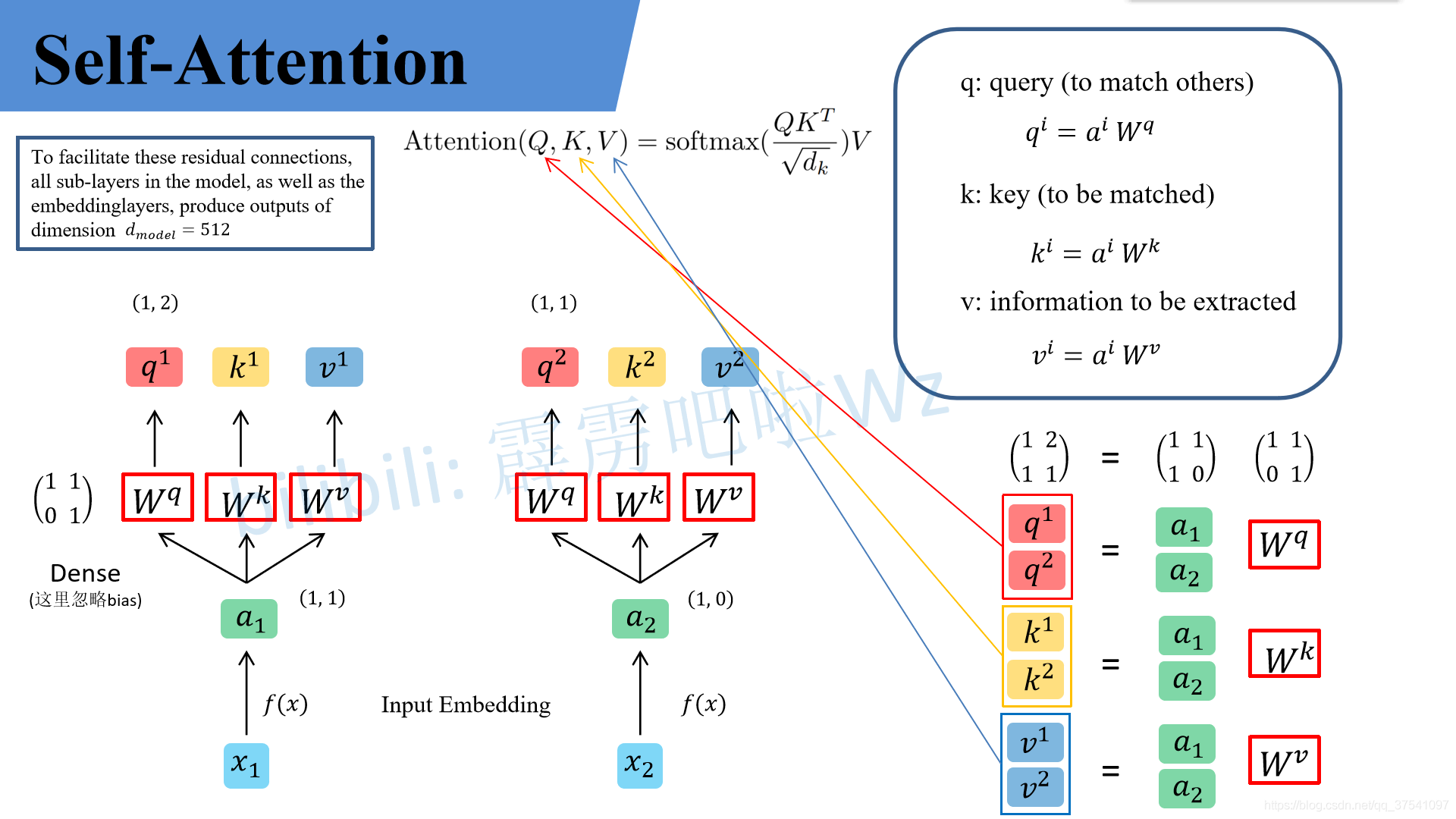
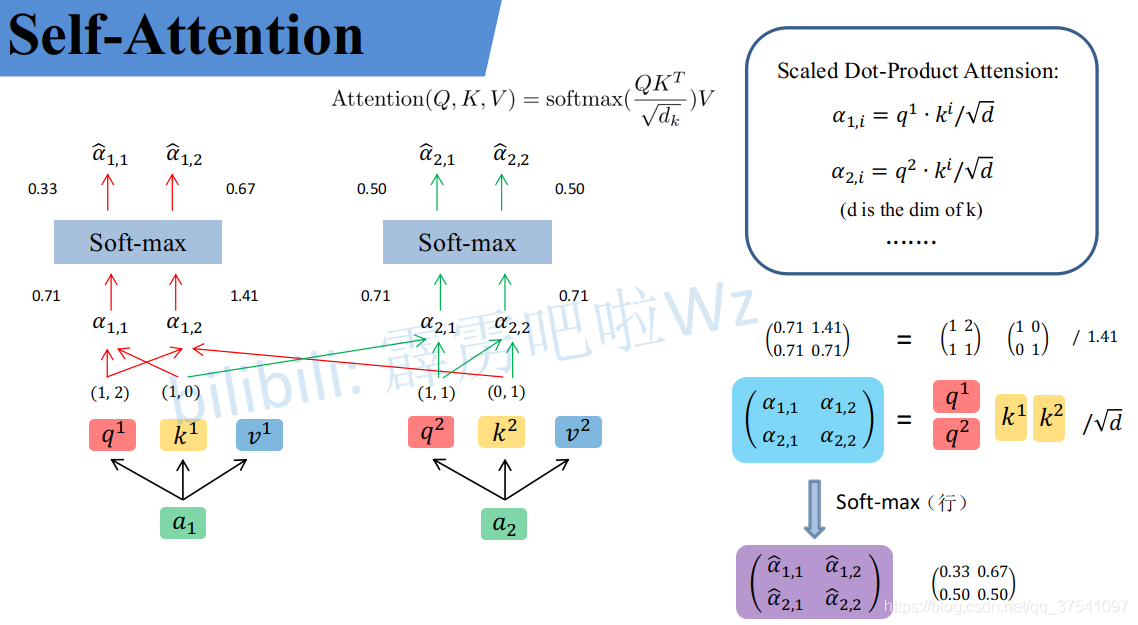

(https://blog.csdn.net/qq_37541097/article/details/117691873)
关于Decoder:

从上图可以看出:
结构实际上就比Encoder多了中间一小部分:
其他不同的是"Masked Multi-Head Attention",这里的Masked可以理解成同时输入与顺序输入,前者是a1a2a3a4都会影响b1b2b3b4,后者是b1只受a1影响,b2只受a1a2影响,以此类推。
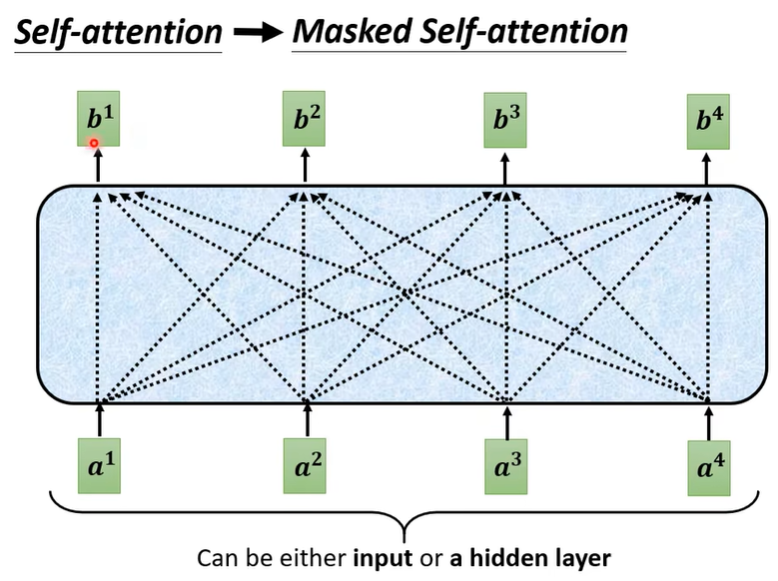


(https://blog.csdn.net/Tink1995/article/details/105080033?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168773679216800213089771%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168773679216800213089771&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-105080033-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=transformer&spm=1018.2226.3001.4187)